 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining Data Selection with Gradient Orthogonality for Efficient Domain Adaptation
Feb 06, 2026Fine-tuning large language models (LLMs) for specialized domains often necessitates a trade-off between acquiring domain expertise and retaining general reasoning capabilities, a phenomenon known as catastrophic forgetting. Existing remedies face a dichotomy: gradient surgery methods offer geometric safety but incur prohibitive computational costs via online projections, while efficient data selection approaches reduce overhead but remain blind to conflict-inducing gradient directions. In this paper, we propose Orthogonal Gradient Selection (OGS), a data-centric method that harmonizes domain performance, general capability retention, and training efficiency. OGS shifts the geometric insights of gradient projection from the optimizer to the data selection stage by treating data selection as a constrained decision-making process. By leveraging a lightweight Navigator model and reinforcement learning techniques, OGS dynamically identifies training samples whose gradients are orthogonal to a general-knowledge anchor. This approach ensures naturally safe updates for target models without modifying the optimizer or incurring runtime projection costs. Experiments across medical, legal, and financial domains demonstrate that OGS achieves excellent results, significantly improving domain performance and training efficiency while maintaining or even enhancing performance on general tasks such as GSM8K.
Nearly Optimal Bayesian Inference for Structural Missingness
Jan 27, 2026Structural missingness breaks 'just impute and train': values can be undefined by causal or logical constraints, and the mask may depend on observed variables, unobserved variables (MNAR), and other missingness indicators. It simultaneously brings (i) a catch-22 situation with causal loop, prediction needs the missing features, yet inferring them depends on the missingness mechanism, (ii) under MNAR, the unseen are different, the missing part can come from a shifted distribution, and (iii) plug-in imputation, a single fill-in can lock in uncertainty and yield overconfident, biased decisions. In the Bayesian view, prediction via the posterior predictive distribution integrates over the full model posterior uncertainty, rather than relying on a single point estimate. This framework decouples (i) learning an in-model missing-value posterior from (ii) label prediction by optimizing the predictive posterior distribution, enabling posterior integration. This decoupling yields an in-model almost-free-lunch: once the posterior is learned, prediction is plug-and-play while preserving uncertainty propagation. It achieves SOTA on 43 classification and 15 imputation benchmarks, with finite-sample near Bayes-optimality guarantees under our SCM prior.
YH-MINER: Multimodal Intelligent System for Natural Ecological Reef Metric Extraction
May 29, 2025



Coral reefs, crucial for sustaining marine biodiversity and ecological processes (e.g., nutrient cycling, habitat provision), face escalating threats, underscoring the need for efficient monitoring. Coral reef ecological monitoring faces dual challenges of low efficiency in manual analysis and insufficient segmentation accuracy in complex underwater scenarios. This study develops the YH-MINER system, establishing an intelligent framework centered on the Multimodal Large Model (MLLM) for "object detection-semantic segmentation-prior input". The system uses the object detection module (mAP@0.5=0.78) to generate spatial prior boxes for coral instances, driving the segment module to complete pixel-level segmentation in low-light and densely occluded scenarios. The segmentation masks and finetuned classification instructions are fed into the Qwen2-VL-based multimodal model as prior inputs, achieving a genus-level classification accuracy of 88% and simultaneously extracting core ecological metrics. Meanwhile, the system retains the scalability of the multimodal model through standardized interfaces, laying a foundation for future integration into multimodal agent-based underwater robots and supporting the full-process automation of "image acquisition-prior generation-real-time analysis".
Unsupervised Multi-modal Feature Alignment for Time Series Representation Learning
Dec 09, 2023



In recent times, the field of unsupervised representation learning (URL) for time series data has garnered significant interest due to its remarkable adaptability across diverse downstream applications. Unsupervised learning goals differ from downstream tasks, making it tricky to ensure downstream task utility by focusing only on temporal feature characterization. Researchers have proposed multiple transformations to extract discriminative patterns implied in informative time series, trying to fill the gap. Despite the introduction of a variety of feature engineering techniques, e.g. spectral domain, wavelet transformed features, features in image form and symbolic features etc. the utilization of intricate feature fusion methods and dependence on heterogeneous features during inference hampers the scalability of the solutions. To address this, our study introduces an innovative approach that focuses on aligning and binding time series representations encoded from different modalities, inspired by spectral graph theory, thereby guiding the neural encoder to uncover latent pattern associations among these multi-modal features. In contrast to conventional methods that fuse features from multiple modalities, our proposed approach simplifies the neural architecture by retaining a single time series encoder, consequently leading to preserved scalability. We further demonstrate and prove mechanisms for the encoder to maintain better inductive bias. In our experimental evaluation, we validated the proposed method on a diverse set of time series datasets from various domains. Our approach outperforms existing state-of-the-art URL methods across diverse downstream tasks.
Salience-Aware Event Chain Modeling for Narrative Understanding
Sep 22, 2021
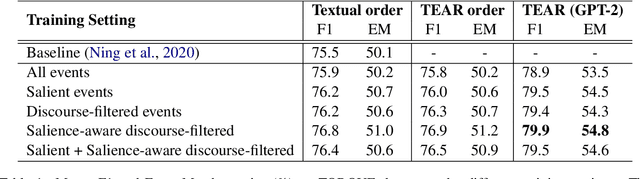
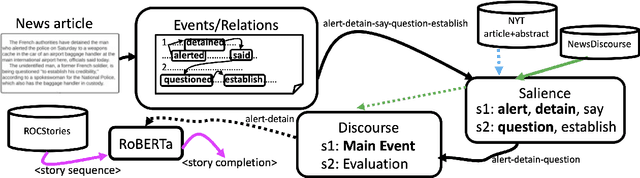
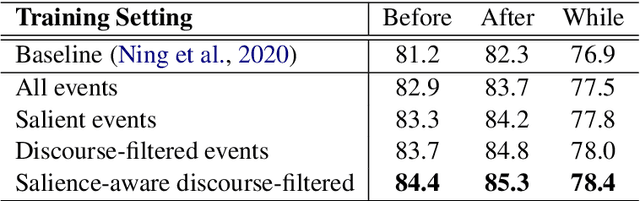
Storytelling, whether via fables, news reports, documentaries, or memoirs, can be thought of as the communication of interesting and related events that, taken together, form a concrete process. It is desirable to extract the event chains that represent such processes. However, this extraction remains a challenging problem. We posit that this is due to the nature of the texts from which chains are discovered. Natural language text interleaves a narrative of concrete, salient events with background information, contextualization, opinion, and other elements that are important for a variety of necessary discourse and pragmatics acts but are not part of the principal chain of events being communicated. We introduce methods for extracting this principal chain from natural language text, by filtering away non-salient events and supportive sentences. We demonstrate the effectiveness of our methods at isolating critical event chains by comparing their effect on downstream tasks. We show that by pre-training large language models on our extracted chains, we obtain improvements in two tasks that benefit from a clear understanding of event chains: narrative prediction and event-based temporal question answering. The demonstrated improvements and ablative studies confirm that our extraction method isolates critical event chains.