 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReducing Representation Drift in Online Continual Learning
Apr 11, 2021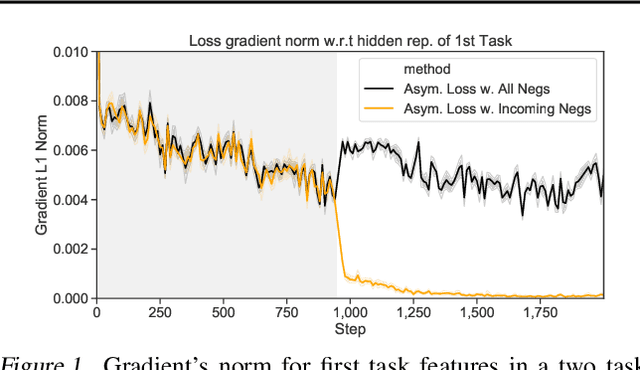
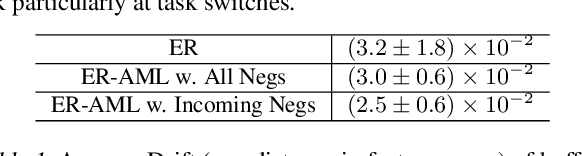
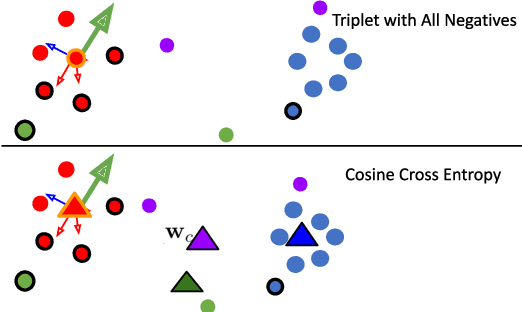
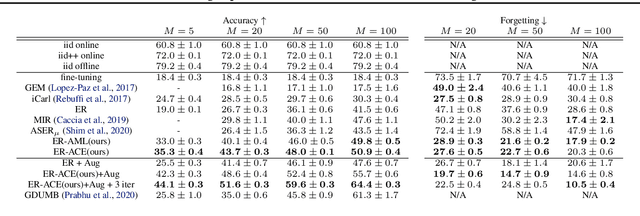
We study the online continual learning paradigm, where agents must learn from a changing distribution with constrained memory and compute. Previous work often tackle catastrophic forgetting by overcoming changes in the space of model parameters. In this work we instead focus on the change in representations of previously observed data due to the introduction of previously unobserved class samples in the incoming data stream. We highlight the issues that arise in the practical setting where new classes must be distinguished between all previous classes. Starting from a popular approach, experience replay, we consider a metric learning based loss function, the triplet loss, which allows us to more explicitly constrain the behavior of representations. We hypothesize and empirically confirm that the selection of negatives used in the triplet loss plays a major role in the representation change, or drift, of previously observed data and can be greatly reduced by appropriate negative selection. Motivated by this we further introduce a simple adjustment to the standard cross entropy loss used in prior experience replay that achieves similar effect. Our approach greatly improves the performance of experience replay and obtains state-of-the-art on several existing benchmarks in online continual learning, while remaining efficient in both memory and compute.
Quasi-Equivalence Discovery for Zero-Shot Emergent Communication
Mar 14, 2021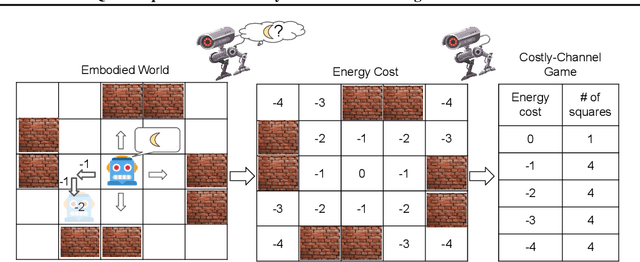
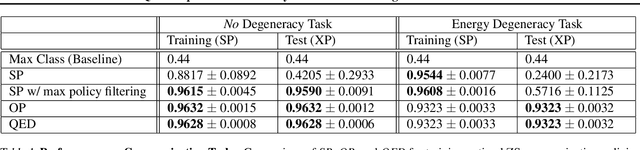

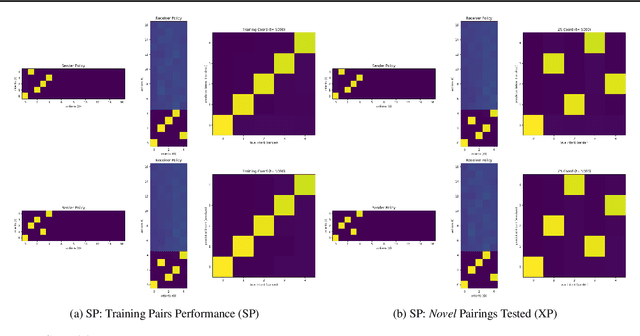
Effective communication is an important skill for enabling information exchange in multi-agent settings and emergent communication is now a vibrant field of research, with common settings involving discrete cheap-talk channels. Since, by definition, these settings involve arbitrary encoding of information, typically they do not allow for the learned protocols to generalize beyond training partners. In contrast, in this work, we present a novel problem setting and the Quasi-Equivalence Discovery (QED) algorithm that allows for zero-shot coordination (ZSC), i.e., discovering protocols that can generalize to independently trained agents. Real world problem settings often contain costly communication channels, e.g., robots have to physically move their limbs, and a non-uniform distribution over intents. We show that these two factors lead to unique optimal ZSC policies in referential games, where agents use the energy cost of the messages to communicate intent. Other-Play was recently introduced for learning optimal ZSC policies, but requires prior access to the symmetries of the problem. Instead, QED can iteratively discovers the symmetries in this setting and converges to the optimal ZSC policy.
Model-Invariant State Abstractions for Model-Based Reinforcement Learning
Feb 19, 2021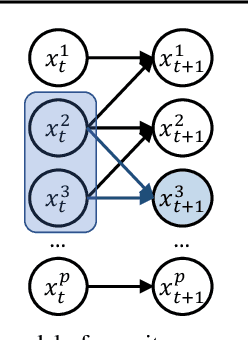
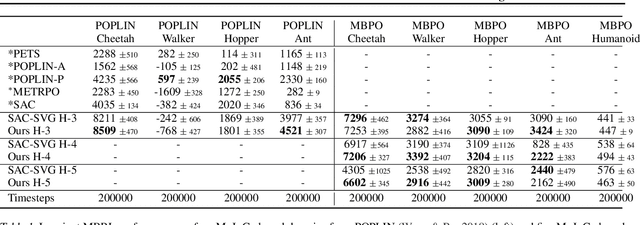

Accuracy and generalization of dynamics models is key to the success of model-based reinforcement learning (MBRL). As the complexity of tasks increases, learning dynamics models becomes increasingly sample inefficient for MBRL methods. However, many tasks also exhibit sparsity in the dynamics, i.e., actions have only a local effect on the system dynamics. In this paper, we exploit this property with a causal invariance perspective in the single-task setting, introducing a new type of state abstraction called \textit{model-invariance}. Unlike previous forms of state abstractions, a model-invariance state abstraction leverages causal sparsity over state variables. This allows for generalization to novel combinations of unseen values of state variables, something that non-factored forms of state abstractions cannot do. We prove that an optimal policy can be learned over this model-invariance state abstraction. Next, we propose a practical method to approximately learn a model-invariant representation for complex domains. We validate our approach by showing improved modeling performance over standard maximum likelihood approaches on challenging tasks, such as the MuJoCo-based Humanoid. Furthermore, within the MBRL setting we show strong performance gains w.r.t. sample efficiency across a host of other continuous control tasks.
Domain Adversarial Reinforcement Learning
Feb 14, 2021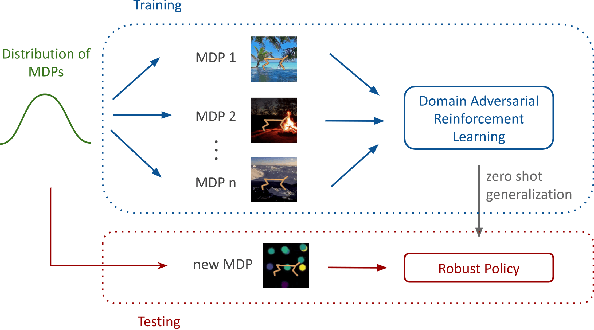

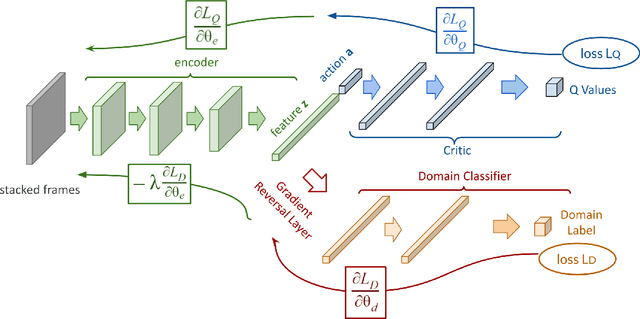
We consider the problem of generalization in reinforcement learning where visual aspects of the observations might differ, e.g. when there are different backgrounds or change in contrast, brightness, etc. We assume that our agent has access to only a few of the MDPs from the MDP distribution during training. The performance of the agent is then reported on new unknown test domains drawn from the distribution (e.g. unseen backgrounds). For this "zero-shot RL" task, we enforce invariance of the learned representations to visual domains via a domain adversarial optimization process. We empirically show that this approach allows achieving a significant generalization improvement to new unseen domains.
Multi-Task Reinforcement Learning with Context-based Representations
Feb 11, 2021
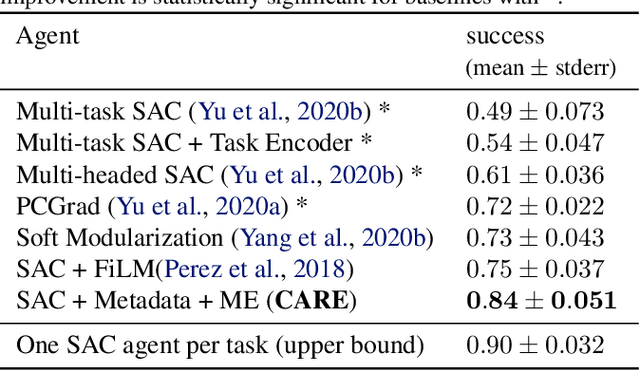
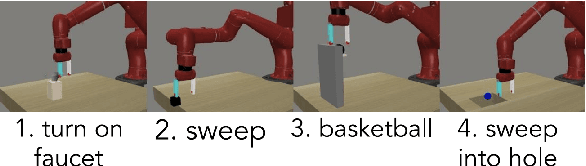
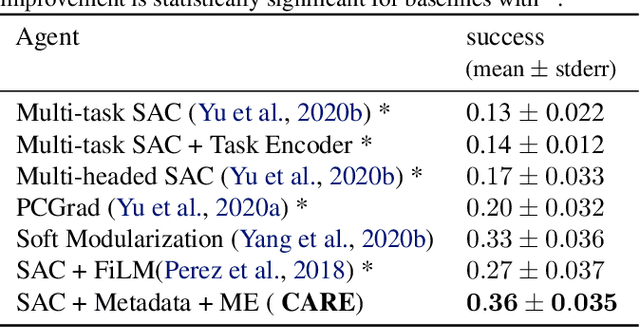
The benefit of multi-task learning over single-task learning relies on the ability to use relations across tasks to improve performance on any single task. While sharing representations is an important mechanism to share information across tasks, its success depends on how well the structure underlying the tasks is captured. In some real-world situations, we have access to metadata, or additional information about a task, that may not provide any new insight in the context of a single task setup alone but inform relations across multiple tasks. While this metadata can be useful for improving multi-task learning performance, effectively incorporating it can be an additional challenge. We posit that an efficient approach to knowledge transfer is through the use of multiple context-dependent, composable representations shared across a family of tasks. In this framework, metadata can help to learn interpretable representations and provide the context to inform which representations to compose and how to compose them. We use the proposed approach to obtain state-of-the-art results in Meta-World, a challenging multi-task benchmark consisting of 50 distinct robotic manipulation tasks.
Exploring the Limits of Few-Shot Link Prediction in Knowledge Graphs
Feb 05, 2021

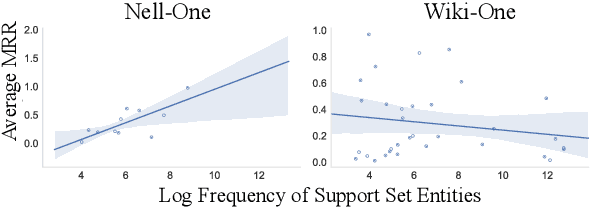
Real-world knowledge graphs are often characterized by low-frequency relations - a challenge that has prompted an increasing interest in few-shot link prediction methods. These methods perform link prediction for a set of new relations, unseen during training, given only a few example facts of each relation at test time. In this work, we perform a systematic study on a spectrum of models derived by generalizing the current state of the art for few-shot link prediction, with the goal of probing the limits of learning in this few-shot setting. We find that a simple zero-shot baseline - which ignores any relation-specific information - achieves surprisingly strong performance. Moreover, experiments on carefully crafted synthetic datasets show that having only a few examples of a relation fundamentally limits models from using fine-grained structural information and only allows for exploiting the coarse-grained positional information of entities. Together, our findings challenge the implicit assumptions and inductive biases of prior work and highlight new directions for research in this area.
* code available at https://github.com/dorajam/few-shot-link-prediction-paper
COVID-19 Prognosis via Self-Supervised Representation Learning and Multi-Image Prediction
Jan 25, 2021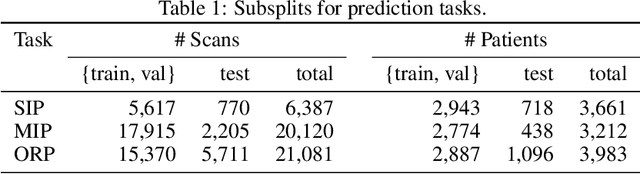
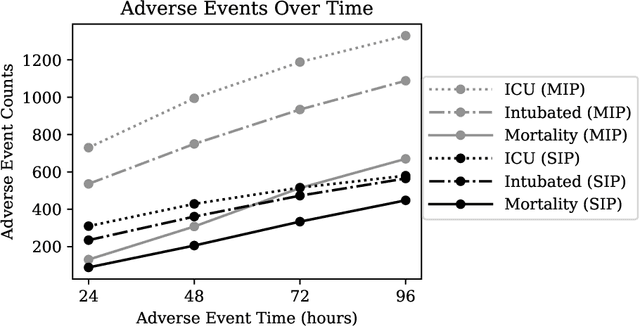
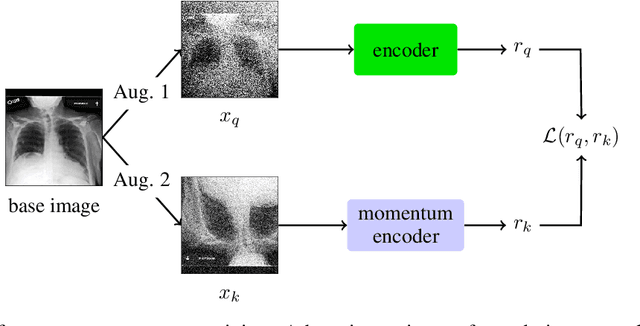
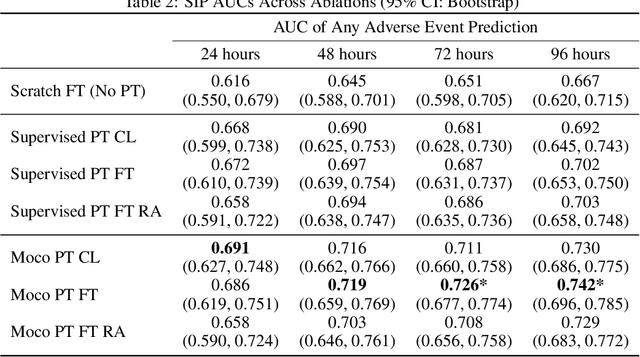
The rapid spread of COVID-19 cases in recent months has strained hospital resources, making rapid and accurate triage of patients presenting to emergency departments a necessity. Machine learning techniques using clinical data such as chest X-rays have been used to predict which patients are most at risk of deterioration. We consider the task of predicting two types of patient deterioration based on chest X-rays: adverse event deterioration (i.e., transfer to the intensive care unit, intubation, or mortality) and increased oxygen requirements beyond 6 L per day. Due to the relative scarcity of COVID-19 patient data, existing solutions leverage supervised pretraining on related non-COVID images, but this is limited by the differences between the pretraining data and the target COVID-19 patient data. In this paper, we use self-supervised learning based on the momentum contrast (MoCo) method in the pretraining phase to learn more general image representations to use for downstream tasks. We present three results. The first is deterioration prediction from a single image, where our model achieves an area under receiver operating characteristic curve (AUC) of 0.742 for predicting an adverse event within 96 hours (compared to 0.703 with supervised pretraining) and an AUC of 0.765 for predicting oxygen requirements greater than 6 L a day at 24 hours (compared to 0.749 with supervised pretraining). We then propose a new transformer-based architecture that can process sequences of multiple images for prediction and show that this model can achieve an improved AUC of 0.786 for predicting an adverse event at 96 hours and an AUC of 0.848 for predicting mortalities at 96 hours. A small pilot clinical study suggested that the prediction accuracy of our model is comparable to that of experienced radiologists analyzing the same information.
Unnatural Language Inference
Dec 30, 2020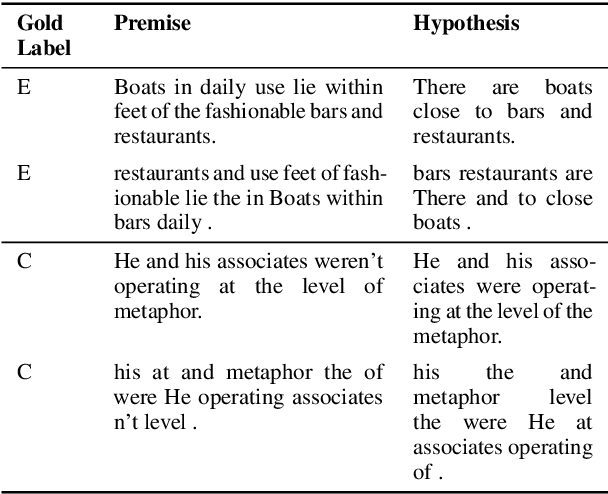
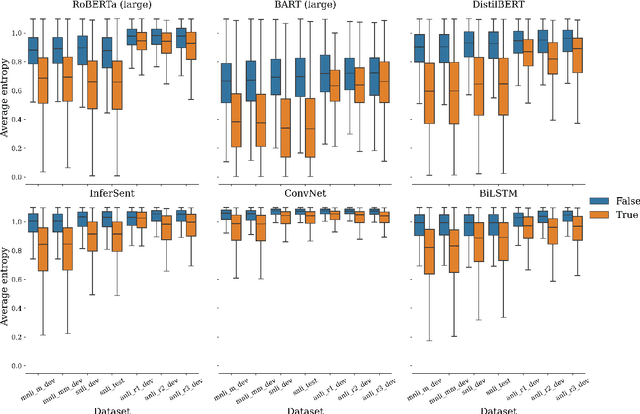
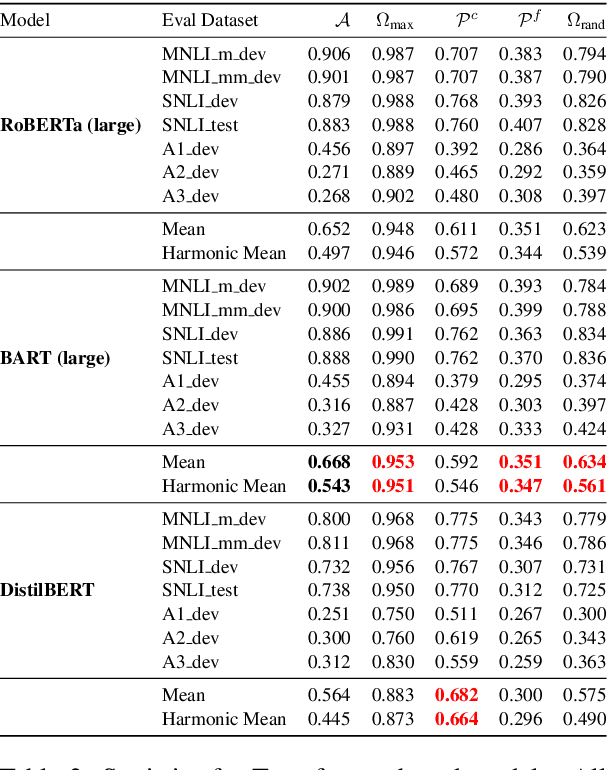
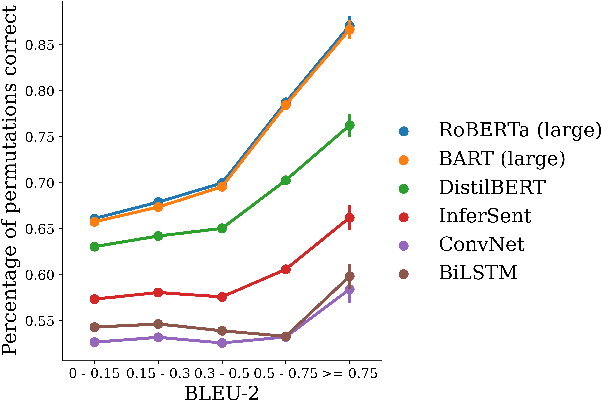
Natural Language Understanding has witnessed a watershed moment with the introduction of large pre-trained Transformer networks. These models achieve state-of-the-art on various tasks, notably including Natural Language Inference (NLI). Many studies have shown that the large representation space imbibed by the models encodes some syntactic and semantic information. However, to really "know syntax", a model must recognize when its input violates syntactic rules and calculate inferences accordingly. In this work, we find that state-of-the-art NLI models, such as RoBERTa and BART are invariant to, and sometimes even perform better on, examples with randomly reordered words. With iterative search, we are able to construct randomized versions of NLI test sets, which contain permuted hypothesis-premise pairs with the same words as the original, yet are classified with perfect accuracy by large pre-trained models, as well as pre-Transformer state-of-the-art encoders. We find the issue to be language and model invariant, and hence investigate the root cause. To partially alleviate this effect, we propose a simple training methodology. Our findings call into question the idea that our natural language understanding models, and the tasks used for measuring their progress, genuinely require a human-like understanding of syntax.
Intervention Design for Effective Sim2Real Transfer
Dec 03, 2020
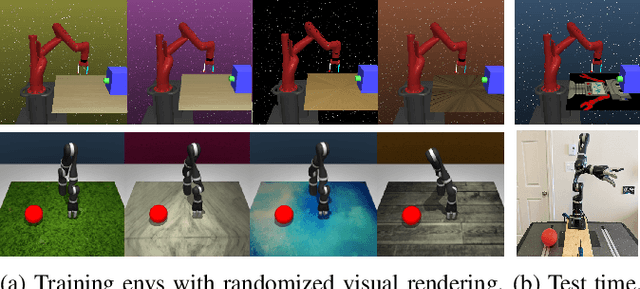
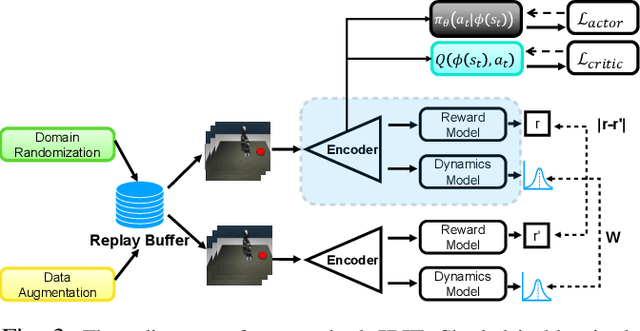
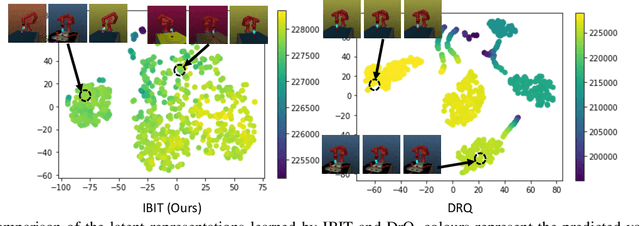
The goal of this work is to address the recent success of domain randomization and data augmentation for the sim2real setting. We explain this success through the lens of causal inference, positioning domain randomization and data augmentation as interventions on the environment which encourage invariance to irrelevant features. Such interventions include visual perturbations that have no effect on reward and dynamics. This encourages the learning algorithm to be robust to these types of variations and learn to attend to the true causal mechanisms for solving the task. This connection leads to two key findings: (1) perturbations to the environment do not have to be realistic, but merely show variation along dimensions that also vary in the real world, and (2) use of an explicit invariance-inducing objective improves generalization in sim2sim and sim2real transfer settings over just data augmentation or domain randomization alone. We demonstrate the capability of our method by performing zero-shot transfer of a robot arm reach task on a 7DoF Jaco arm learning from pixel observations.
Exploring Zero-Shot Emergent Communication in Embodied Multi-Agent Populations
Oct 29, 2020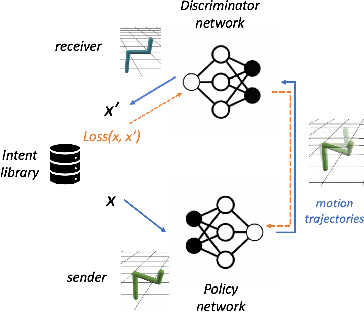

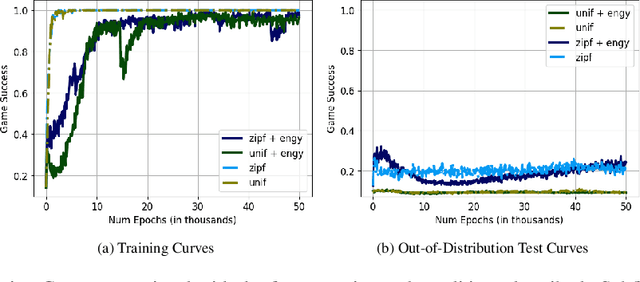

Effective communication is an important skill for enabling information exchange and cooperation in multi-agent settings. Indeed, emergent communication is now a vibrant field of research, with common settings involving discrete cheap-talk channels. One limitation of this setting is that it does not allow for the emergent protocols to generalize beyond the training partners. Furthermore, so far emergent communication has primarily focused on the use of symbolic channels. In this work, we extend this line of work to a new modality, by studying agents that learn to communicate via actuating their joints in a 3D environment. We show that under realistic assumptions, a non-uniform distribution of intents and a common-knowledge energy cost, these agents can find protocols that generalize to novel partners. We also explore and analyze specific difficulties associated with finding these solutions in practice. Finally, we propose and evaluate initial training improvements to address these challenges, involving both specific training curricula and providing the latent feature that can be coordinated on during training.