 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLAGr: Label Aligned Graphs for Better Systematic Generalization in Semantic Parsing
Jun 01, 2022
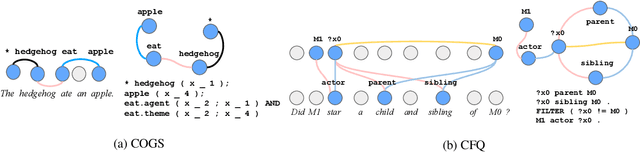
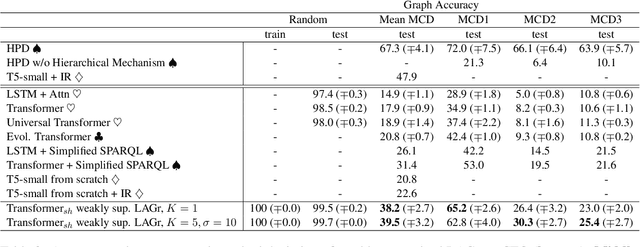
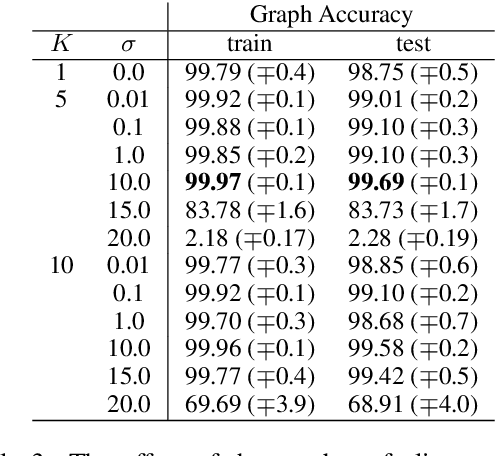
Semantic parsing is the task of producing structured meaning representations for natural language sentences. Recent research has pointed out that the commonly-used sequence-to-sequence (seq2seq) semantic parsers struggle to generalize systematically, i.e. to handle examples that require recombining known knowledge in novel settings. In this work, we show that better systematic generalization can be achieved by producing the meaning representation directly as a graph and not as a sequence. To this end we propose LAGr (Label Aligned Graphs), a general framework to produce semantic parses by independently predicting node and edge labels for a complete multi-layer input-aligned graph. The strongly-supervised LAGr algorithm requires aligned graphs as inputs, whereas weakly-supervised LAGr infers alignments for originally unaligned target graphs using approximate maximum-a-posteriori inference. Experiments demonstrate that LAGr achieves significant improvements in systematic generalization upon the baseline seq2seq parsers in both strongly- and weakly-supervised settings.
LAGr: Labeling Aligned Graphs for Improving Systematic Generalization in Semantic Parsing
Oct 14, 2021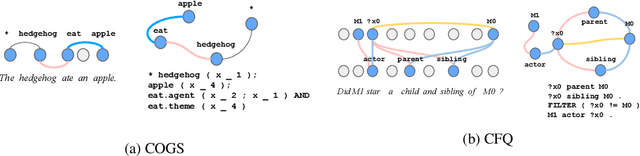
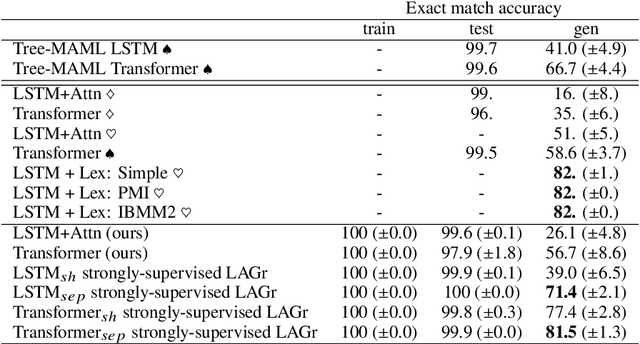
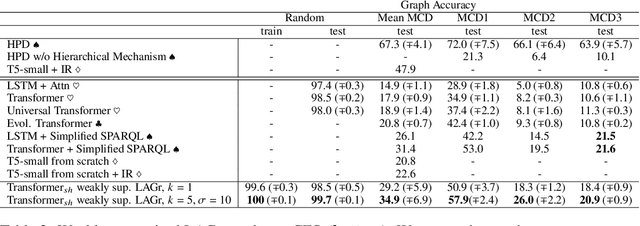
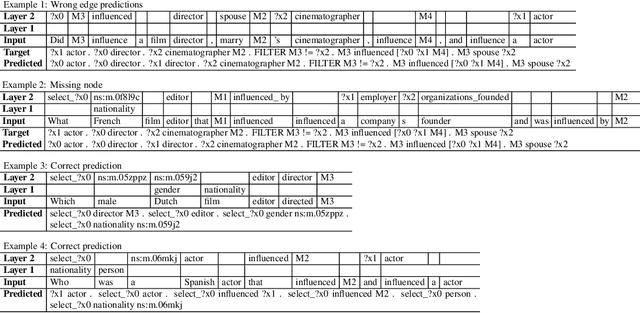
Semantic parsing is the task of producing a structured meaning representation for natural language utterances or questions. Recent research has pointed out that the commonly-used sequence-to-sequence (seq2seq) semantic parsers struggle to generalize systematically, i.e. to handle examples that require recombining known knowledge in novel settings. In this work, we show that better systematic generalization can be achieved by producing the meaning representation (MR) directly as a graph and not as a sequence. To this end we propose LAGr, the Labeling Aligned Graphs algorithm that produces semantic parses by predicting node and edge labels for a complete multi-layer input-aligned graph. The strongly-supervised LAGr algorithm requires aligned graphs as inputs, whereas weakly-supervised LAGr infers alignments for originally unaligned target graphs using an approximate MAP inference procedure. On the COGS and CFQ compositional generalization benchmarks the strongly- and weakly- supervised LAGr algorithms achieve significant improvements upon the baseline seq2seq parsers.
Exploring the Limits of Few-Shot Link Prediction in Knowledge Graphs
Feb 05, 2021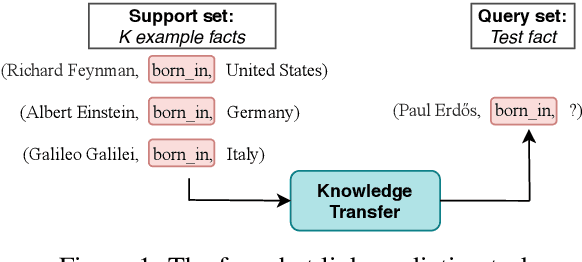
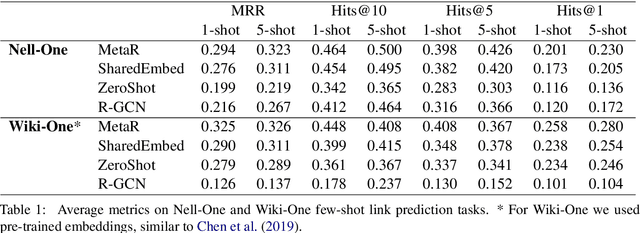

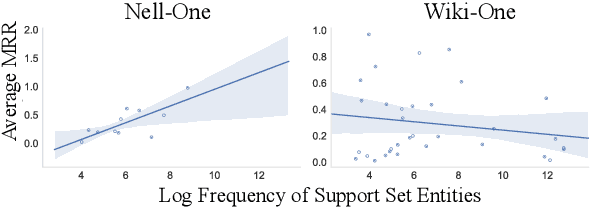
Real-world knowledge graphs are often characterized by low-frequency relations - a challenge that has prompted an increasing interest in few-shot link prediction methods. These methods perform link prediction for a set of new relations, unseen during training, given only a few example facts of each relation at test time. In this work, we perform a systematic study on a spectrum of models derived by generalizing the current state of the art for few-shot link prediction, with the goal of probing the limits of learning in this few-shot setting. We find that a simple zero-shot baseline - which ignores any relation-specific information - achieves surprisingly strong performance. Moreover, experiments on carefully crafted synthetic datasets show that having only a few examples of a relation fundamentally limits models from using fine-grained structural information and only allows for exploiting the coarse-grained positional information of entities. Together, our findings challenge the implicit assumptions and inductive biases of prior work and highlight new directions for research in this area.
* code available at https://github.com/dorajam/few-shot-link-prediction-paper
On a scalable problem transformation method for multi-label learning
May 27, 2019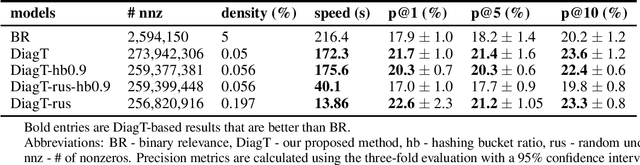
Binary relevance is a simple approach to solve multi-label learning problems where an independent binary classifier is built per each label. A common challenge with this in real-world applications is that the label space can be very large, making it difficult to use binary relevance to larger scale problems. In this paper, we propose a scalable alternative to this, via transforming the multi-label problem into a single binary classification. We experiment with a few variations of our method and show that our method achieves higher precision than binary relevance and faster execution times on a top-K recommender system task.