 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCustomize your NeRF: Adaptive Source Driven 3D Scene Editing via Local-Global Iterative Training
Dec 04, 2023



In this paper, we target the adaptive source driven 3D scene editing task by proposing a CustomNeRF model that unifies a text description or a reference image as the editing prompt. However, obtaining desired editing results conformed with the editing prompt is nontrivial since there exist two significant challenges, including accurate editing of only foreground regions and multi-view consistency given a single-view reference image. To tackle the first challenge, we propose a Local-Global Iterative Editing (LGIE) training scheme that alternates between foreground region editing and full-image editing, aimed at foreground-only manipulation while preserving the background. For the second challenge, we also design a class-guided regularization that exploits class priors within the generation model to alleviate the inconsistency problem among different views in image-driven editing. Extensive experiments show that our CustomNeRF produces precise editing results under various real scenes for both text- and image-driven settings.
Enriching Phrases with Coupled Pixel and Object Contexts for Panoptic Narrative Grounding
Nov 02, 2023Panoptic narrative grounding (PNG) aims to segment things and stuff objects in an image described by noun phrases of a narrative caption. As a multimodal task, an essential aspect of PNG is the visual-linguistic interaction between image and caption. The previous two-stage method aggregates visual contexts from offline-generated mask proposals to phrase features, which tend to be noisy and fragmentary. The recent one-stage method aggregates only pixel contexts from image features to phrase features, which may incur semantic misalignment due to lacking object priors. To realize more comprehensive visual-linguistic interaction, we propose to enrich phrases with coupled pixel and object contexts by designing a Phrase-Pixel-Object Transformer Decoder (PPO-TD), where both fine-grained part details and coarse-grained entity clues are aggregated to phrase features. In addition, we also propose a PhraseObject Contrastive Loss (POCL) to pull closer the matched phrase-object pairs and push away unmatched ones for aggregating more precise object contexts from more phrase-relevant object tokens. Extensive experiments on the PNG benchmark show our method achieves new state-of-the-art performance with large margins.
OSM-Net: One-to-Many One-shot Talking Head Generation with Spontaneous Head Motions
Sep 28, 2023



One-shot talking head generation has no explicit head movement reference, thus it is difficult to generate talking heads with head motions. Some existing works only edit the mouth area and generate still talking heads, leading to unreal talking head performance. Other works construct one-to-one mapping between audio signal and head motion sequences, introducing ambiguity correspondences into the mapping since people can behave differently in head motions when speaking the same content. This unreasonable mapping form fails to model the diversity and produces either nearly static or even exaggerated head motions, which are unnatural and strange. Therefore, the one-shot talking head generation task is actually a one-to-many ill-posed problem and people present diverse head motions when speaking. Based on the above observation, we propose OSM-Net, a \textit{one-to-many} one-shot talking head generation network with natural head motions. OSM-Net constructs a motion space that contains rich and various clip-level head motion features. Each basis of the space represents a feature of meaningful head motion in a clip rather than just a frame, thus providing more coherent and natural motion changes in talking heads. The driving audio is mapped into the motion space, around which various motion features can be sampled within a reasonable range to achieve the one-to-many mapping. Besides, the landmark constraint and time window feature input improve the accurate expression feature extraction and video generation. Extensive experiments show that OSM-Net generates more natural realistic head motions under reasonable one-to-many mapping paradigm compared with other methods.
Discovering Sounding Objects by Audio Queries for Audio Visual Segmentation
Sep 18, 2023



Audio visual segmentation (AVS) aims to segment the sounding objects for each frame of a given video. To distinguish the sounding objects from silent ones, both audio-visual semantic correspondence and temporal interaction are required. The previous method applies multi-frame cross-modal attention to conduct pixel-level interactions between audio features and visual features of multiple frames simultaneously, which is both redundant and implicit. In this paper, we propose an Audio-Queried Transformer architecture, AQFormer, where we define a set of object queries conditioned on audio information and associate each of them to particular sounding objects. Explicit object-level semantic correspondence between audio and visual modalities is established by gathering object information from visual features with predefined audio queries. Besides, an Audio-Bridged Temporal Interaction module is proposed to exchange sounding object-relevant information among multiple frames with the bridge of audio features. Extensive experiments are conducted on two AVS benchmarks to show that our method achieves state-of-the-art performances, especially 7.1% M_J and 7.6% M_F gains on the MS3 setting.
MFR-Net: Multi-faceted Responsive Listening Head Generation via Denoising Diffusion Model
Aug 31, 2023



Face-to-face communication is a common scenario including roles of speakers and listeners. Most existing research methods focus on producing speaker videos, while the generation of listener heads remains largely overlooked. Responsive listening head generation is an important task that aims to model face-to-face communication scenarios by generating a listener head video given a speaker video and a listener head image. An ideal generated responsive listening video should respond to the speaker with attitude or viewpoint expressing while maintaining diversity in interaction patterns and accuracy in listener identity information. To achieve this goal, we propose the \textbf{M}ulti-\textbf{F}aceted \textbf{R}esponsive Listening Head Generation Network (MFR-Net). Specifically, MFR-Net employs the probabilistic denoising diffusion model to predict diverse head pose and expression features. In order to perform multi-faceted response to the speaker video, while maintaining accurate listener identity preservation, we design the Feature Aggregation Module to boost listener identity features and fuse them with other speaker-related features. Finally, a renderer finetuned with identity consistency loss produces the final listening head videos. Our extensive experiments demonstrate that MFR-Net not only achieves multi-faceted responses in diversity and speaker identity information but also in attitude and viewpoint expression.
Modality-Agnostic Audio-Visual Deepfake Detection
Jul 26, 2023



As AI-generated content (AIGC) thrives, Deepfakes have expanded from single-modality falsification to cross-modal fake content creation, where either audio or visual components can be manipulated. While using two unimodal detectors can detect audio-visual deepfakes, cross-modal forgery clues could be overlooked. Existing multimodal deepfake detection methods typically establish correspondence between the audio and visual modalities for binary real/fake classification, and require the co-occurrence of both modalities. However, in real-world multi-modal applications, missing modality scenarios may occur where either modality is unavailable. In such cases, audio-visual detection methods are less practical than two independent unimodal methods. Consequently, the detector can not always obtain the number or type of manipulated modalities beforehand, necessitating a fake-modality-agnostic audio-visual detector. In this work, we propose a unified fake-modality-agnostic scenarios framework that enables the detection of multimodal deepfakes and handles missing modalities cases, no matter the manipulation hidden in audio, video, or even cross-modal forms. To enhance the modeling of cross-modal forgery clues, we choose audio-visual speech recognition (AVSR) as a preceding task, which effectively extracts speech correlation across modalities, which is difficult for deepfakes to reproduce. Additionally, we propose a dual-label detection approach that follows the structure of AVSR to support the independent detection of each modality. Extensive experiments show that our scheme not only outperforms other state-of-the-art binary detection methods across all three audio-visual datasets but also achieves satisfying performance on detection modality-agnostic audio/video fakes. Moreover, it even surpasses the joint use of two unimodal methods in the presence of missing modality cases.
FONT: Flow-guided One-shot Talking Head Generation with Natural Head Motions
Mar 31, 2023



One-shot talking head generation has received growing attention in recent years, with various creative and practical applications. An ideal natural and vivid generated talking head video should contain natural head pose changes. However, it is challenging to map head pose sequences from driving audio since there exists a natural gap between audio-visual modalities. In this work, we propose a Flow-guided One-shot model that achieves NaTural head motions(FONT) over generated talking heads. Specifically, the head pose prediction module is designed to generate head pose sequences from the source face and driving audio. We add the random sampling operation and the structural similarity constraint to model the diversity in the one-to-many mapping between audio-visual modality, thus predicting natural head poses. Then we develop a keypoint predictor that produces unsupervised keypoints from the source face, driving audio and pose sequences to describe the facial structure information. Finally, a flow-guided occlusion-aware generator is employed to produce photo-realistic talking head videos from the estimated keypoints and source face. Extensive experimental results prove that FONT generates talking heads with natural head poses and synchronized mouth shapes, outperforming other compared methods.
OPT: One-shot Pose-Controllable Talking Head Generation
Feb 16, 2023



One-shot talking head generation produces lip-sync talking heads based on arbitrary audio and one source face. To guarantee the naturalness and realness, recent methods propose to achieve free pose control instead of simply editing mouth areas. However, existing methods do not preserve accurate identity of source face when generating head motions. To solve the identity mismatch problem and achieve high-quality free pose control, we present One-shot Pose-controllable Talking head generation network (OPT). Specifically, the Audio Feature Disentanglement Module separates content features from audios, eliminating the influence of speaker-specific information contained in arbitrary driving audios. Later, the mouth expression feature is extracted from the content feature and source face, during which the landmark loss is designed to enhance the accuracy of facial structure and identity preserving quality. Finally, to achieve free pose control, controllable head pose features from reference videos are fed into the Video Generator along with the expression feature and source face to generate new talking heads. Extensive quantitative and qualitative experimental results verify that OPT generates high-quality pose-controllable talking heads with no identity mismatch problem, outperforming previous SOTA methods.
Anchor3DLane: Learning to Regress 3D Anchors for Monocular 3D Lane Detection
Jan 06, 2023



Monocular 3D lane detection is a challenging task due to its lack of depth information. A popular solution to 3D lane detection is to first transform the front-viewed (FV) images or features into the bird-eye-view (BEV) space with inverse perspective mapping (IPM) and detect lanes from BEV features. However, the reliance of IPM on flat ground assumption and loss of context information makes it inaccurate to restore 3D information from BEV representations. An attempt has been made to get rid of BEV and predict 3D lanes from FV representations directly, while it still underperforms other BEV-based methods given its lack of structured representation for 3D lanes. In this paper, we define 3D lane anchors in the 3D space and propose a BEV-free method named Anchor3DLane to predict 3D lanes directly from FV representations. 3D lane anchors are projected to the FV features to extract their features which contain both good structural and context information to make accurate predictions. We further extend Anchor3DLane to the multi-frame setting to incorporate temporal information for performance improvement. In addition, we also develop a global optimization method that makes use of the equal-width property between lanes to reduce the lateral error of predictions. Extensive experiments on three popular 3D lane detection benchmarks show that our Anchor3DLane outperforms previous BEV-based methods and achieves state-of-the-art performances.
RaP: Redundancy-aware Video-language Pre-training for Text-Video Retrieval
Oct 13, 2022
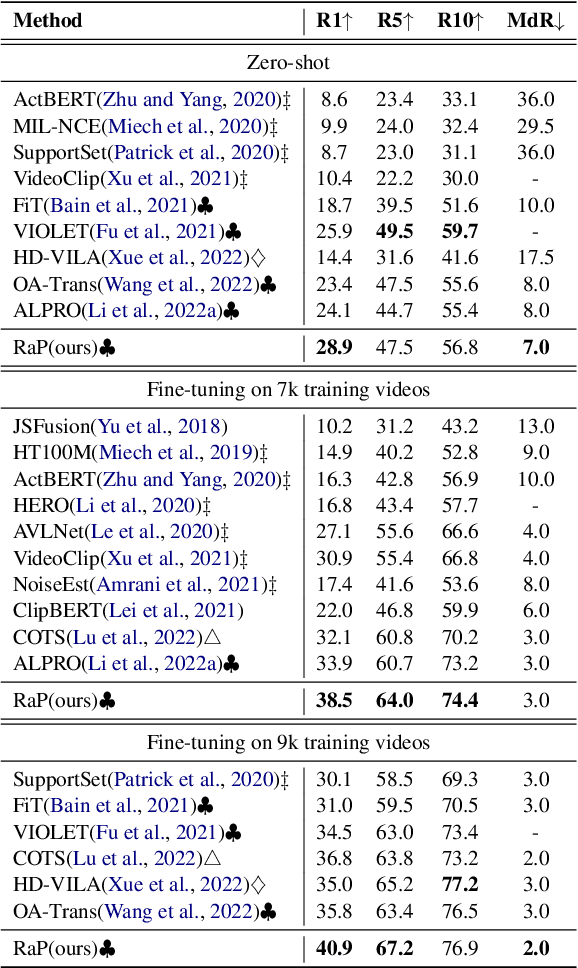
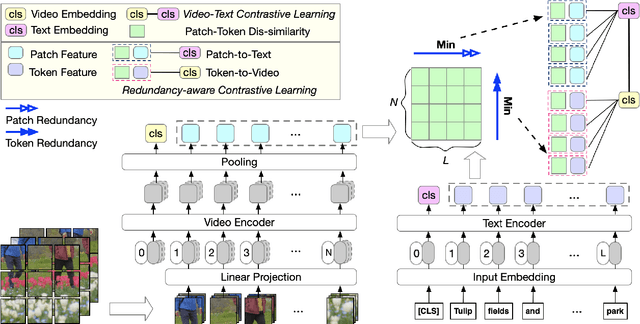
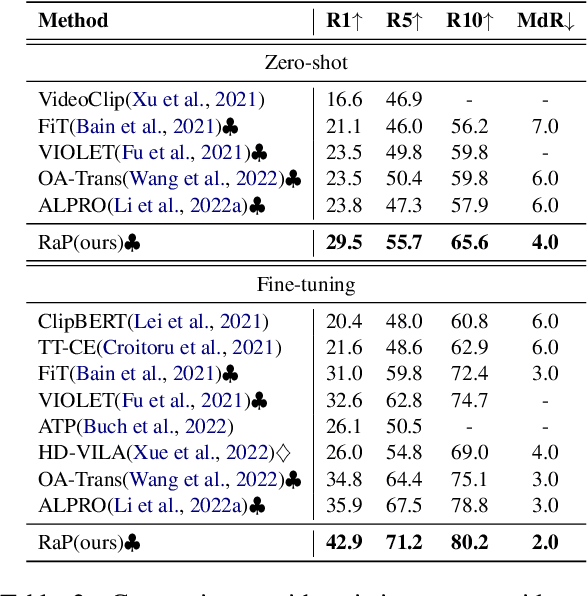
Video language pre-training methods have mainly adopted sparse sampling techniques to alleviate the temporal redundancy of videos. Though effective, sparse sampling still suffers inter-modal redundancy: visual redundancy and textual redundancy. Compared with highly generalized text, sparsely sampled frames usually contain text-independent portions, called visual redundancy. Sparse sampling is also likely to miss important frames corresponding to some text portions, resulting in textual redundancy. Inter-modal redundancy leads to a mismatch of video and text information, hindering the model from better learning the shared semantics across modalities. To alleviate it, we propose Redundancy-aware Video-language Pre-training. We design a redundancy measurement of video patches and text tokens by calculating the cross-modal minimum dis-similarity. Then, we penalize the highredundant video patches and text tokens through a proposed redundancy-aware contrastive learning. We evaluate our method on four benchmark datasets, MSRVTT, MSVD, DiDeMo, and LSMDC, achieving a significant improvement over the previous stateof-the-art results. Our code are available at https://github.com/caskcsg/VLP/tree/main/RaP.