 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTime Is MattEr: Temporal Self-supervision for Video Transformers
Jul 19, 2022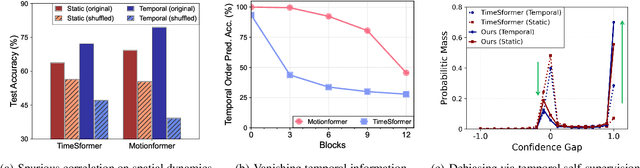
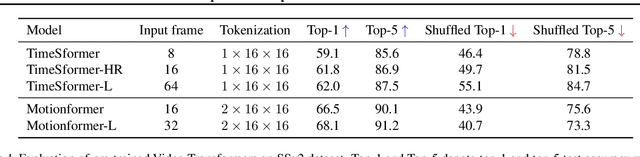
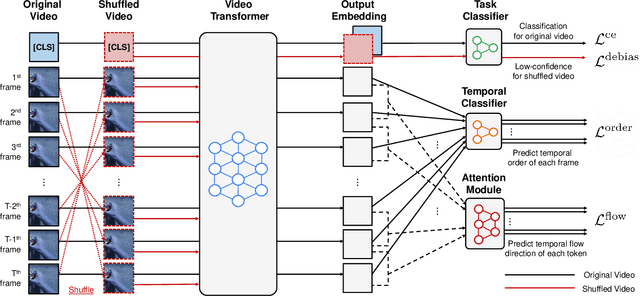
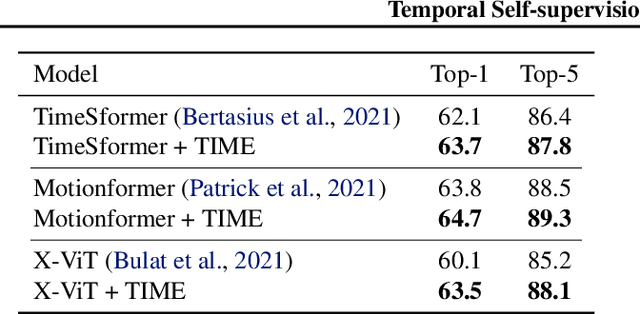
Understanding temporal dynamics of video is an essential aspect of learning better video representations. Recently, transformer-based architectural designs have been extensively explored for video tasks due to their capability to capture long-term dependency of input sequences. However, we found that these Video Transformers are still biased to learn spatial dynamics rather than temporal ones, and debiasing the spurious correlation is critical for their performance. Based on the observations, we design simple yet effective self-supervised tasks for video models to learn temporal dynamics better. Specifically, for debiasing the spatial bias, our method learns the temporal order of video frames as extra self-supervision and enforces the randomly shuffled frames to have low-confidence outputs. Also, our method learns the temporal flow direction of video tokens among consecutive frames for enhancing the correlation toward temporal dynamics. Under various video action recognition tasks, we demonstrate the effectiveness of our method and its compatibility with state-of-the-art Video Transformers.
Patch-level Representation Learning for Self-supervised Vision Transformers
Jun 17, 2022
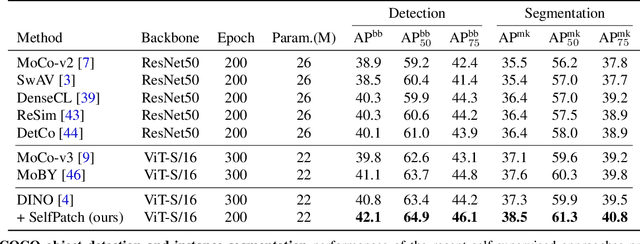
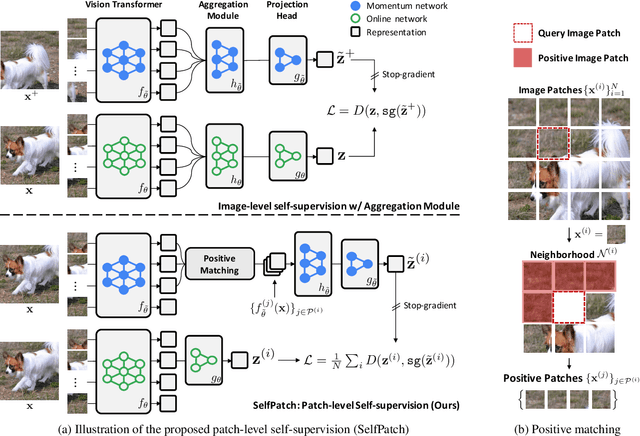
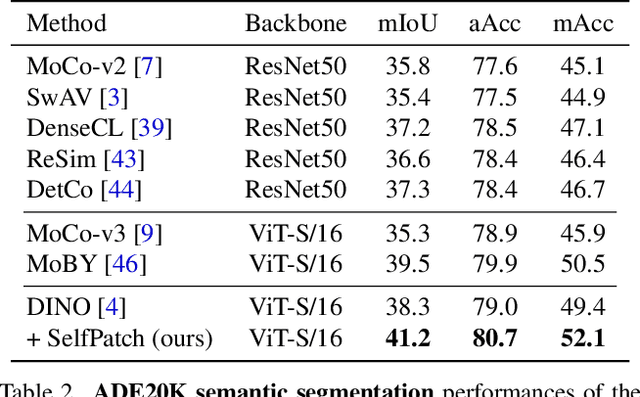
Recent self-supervised learning (SSL) methods have shown impressive results in learning visual representations from unlabeled images. This paper aims to improve their performance further by utilizing the architectural advantages of the underlying neural network, as the current state-of-the-art visual pretext tasks for SSL do not enjoy the benefit, i.e., they are architecture-agnostic. In particular, we focus on Vision Transformers (ViTs), which have gained much attention recently as a better architectural choice, often outperforming convolutional networks for various visual tasks. The unique characteristic of ViT is that it takes a sequence of disjoint patches from an image and processes patch-level representations internally. Inspired by this, we design a simple yet effective visual pretext task, coined SelfPatch, for learning better patch-level representations. To be specific, we enforce invariance against each patch and its neighbors, i.e., each patch treats similar neighboring patches as positive samples. Consequently, training ViTs with SelfPatch learns more semantically meaningful relations among patches (without using human-annotated labels), which can be beneficial, in particular, to downstream tasks of a dense prediction type. Despite its simplicity, we demonstrate that it can significantly improve the performance of existing SSL methods for various visual tasks, including object detection and semantic segmentation. Specifically, SelfPatch significantly improves the recent self-supervised ViT, DINO, by achieving +1.3 AP on COCO object detection, +1.2 AP on COCO instance segmentation, and +2.9 mIoU on ADE20K semantic segmentation.
Zero-shot Blind Image Denoising via Implicit Neural Representations
Apr 05, 2022
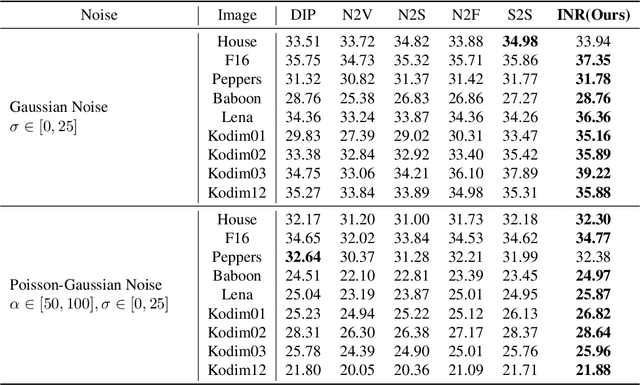
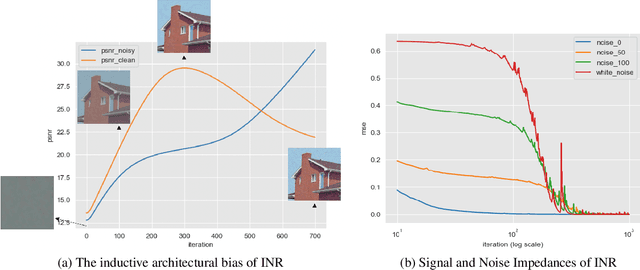
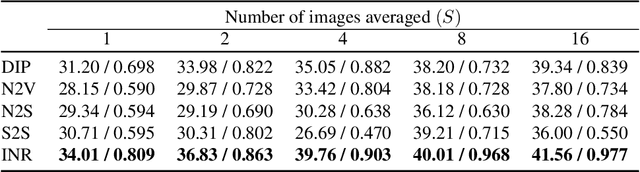
Recent denoising algorithms based on the "blind-spot" strategy show impressive blind image denoising performances, without utilizing any external dataset. While the methods excel in recovering highly contaminated images, we observe that such algorithms are often less effective under a low-noise or real noise regime. To address this gap, we propose an alternative denoising strategy that leverages the architectural inductive bias of implicit neural representations (INRs), based on our two findings: (1) INR tends to fit the low-frequency clean image signal faster than the high-frequency noise, and (2) INR layers that are closer to the output play more critical roles in fitting higher-frequency parts. Building on these observations, we propose a denoising algorithm that maximizes the innate denoising capability of INRs by penalizing the growth of deeper layer weights. We show that our method outperforms existing zero-shot denoising methods under an extensive set of low-noise or real-noise scenarios.
Spread Spurious Attribute: Improving Worst-group Accuracy with Spurious Attribute Estimation
Apr 05, 2022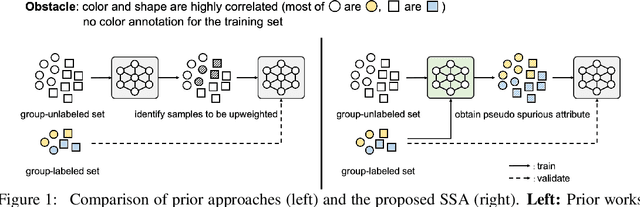
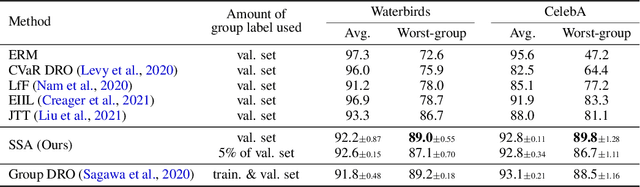
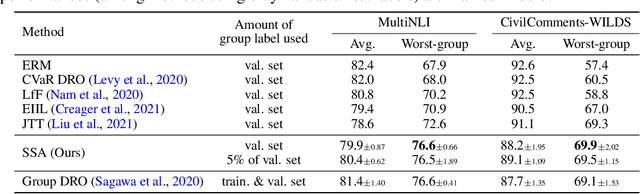

The paradigm of worst-group loss minimization has shown its promise in avoiding to learn spurious correlations, but requires costly additional supervision on spurious attributes. To resolve this, recent works focus on developing weaker forms of supervision -- e.g., hyperparameters discovered with a small number of validation samples with spurious attribute annotation -- but none of the methods retain comparable performance to methods using full supervision on the spurious attribute. In this paper, instead of searching for weaker supervisions, we ask: Given access to a fixed number of samples with spurious attribute annotations, what is the best achievable worst-group loss if we "fully exploit" them? To this end, we propose a pseudo-attribute-based algorithm, coined Spread Spurious Attribute (SSA), for improving the worst-group accuracy. In particular, we leverage samples both with and without spurious attribute annotations to train a model to predict the spurious attribute, then use the pseudo-attribute predicted by the trained model as supervision on the spurious attribute to train a new robust model having minimal worst-group loss. Our experiments on various benchmark datasets show that our algorithm consistently outperforms the baseline methods using the same number of validation samples with spurious attribute annotations. We also demonstrate that the proposed SSA can achieve comparable performances to methods using full (100%) spurious attribute supervision, by using a much smaller number of annotated samples -- from 0.6% and up to 1.5%, depending on the dataset.
SURF: Semi-supervised Reward Learning with Data Augmentation for Feedback-efficient Preference-based Reinforcement Learning
Mar 18, 2022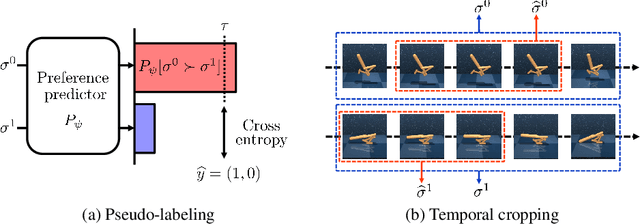

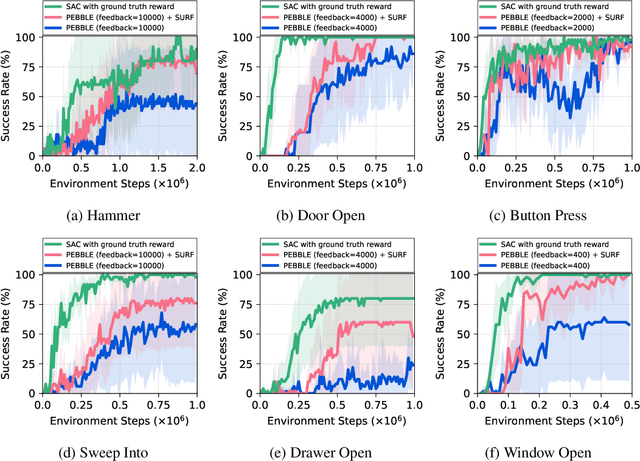

Preference-based reinforcement learning (RL) has shown potential for teaching agents to perform the target tasks without a costly, pre-defined reward function by learning the reward with a supervisor's preference between the two agent behaviors. However, preference-based learning often requires a large amount of human feedback, making it difficult to apply this approach to various applications. This data-efficiency problem, on the other hand, has been typically addressed by using unlabeled samples or data augmentation techniques in the context of supervised learning. Motivated by the recent success of these approaches, we present SURF, a semi-supervised reward learning framework that utilizes a large amount of unlabeled samples with data augmentation. In order to leverage unlabeled samples for reward learning, we infer pseudo-labels of the unlabeled samples based on the confidence of the preference predictor. To further improve the label-efficiency of reward learning, we introduce a new data augmentation that temporally crops consecutive subsequences from the original behaviors. Our experiments demonstrate that our approach significantly improves the feedback-efficiency of the state-of-the-art preference-based method on a variety of locomotion and robotic manipulation tasks.
Generating Videos with Dynamics-aware Implicit Generative Adversarial Networks
Feb 21, 2022
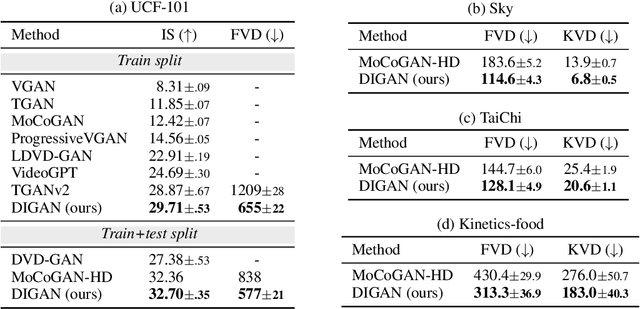
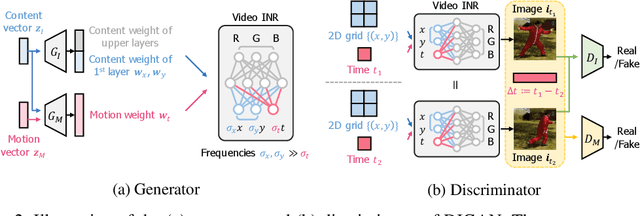
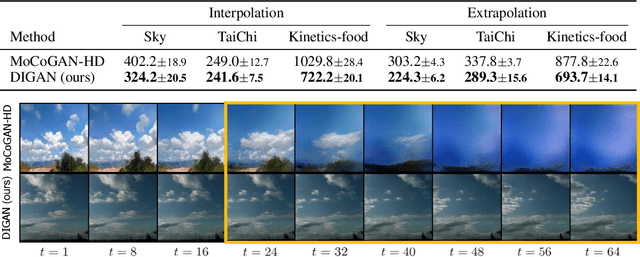
In the deep learning era, long video generation of high-quality still remains challenging due to the spatio-temporal complexity and continuity of videos. Existing prior works have attempted to model video distribution by representing videos as 3D grids of RGB values, which impedes the scale of generated videos and neglects continuous dynamics. In this paper, we found that the recent emerging paradigm of implicit neural representations (INRs) that encodes a continuous signal into a parameterized neural network effectively mitigates the issue. By utilizing INRs of video, we propose dynamics-aware implicit generative adversarial network (DIGAN), a novel generative adversarial network for video generation. Specifically, we introduce (a) an INR-based video generator that improves the motion dynamics by manipulating the space and time coordinates differently and (b) a motion discriminator that efficiently identifies the unnatural motions without observing the entire long frame sequences. We demonstrate the superiority of DIGAN under various datasets, along with multiple intriguing properties, e.g., long video synthesis, video extrapolation, and non-autoregressive video generation. For example, DIGAN improves the previous state-of-the-art FVD score on UCF-101 by 30.7% and can be trained on 128 frame videos of 128x128 resolution, 80 frames longer than the 48 frames of the previous state-of-the-art method.
Saliency Grafting: Innocuous Attribution-Guided Mixup with Calibrated Label Mixing
Dec 16, 2021
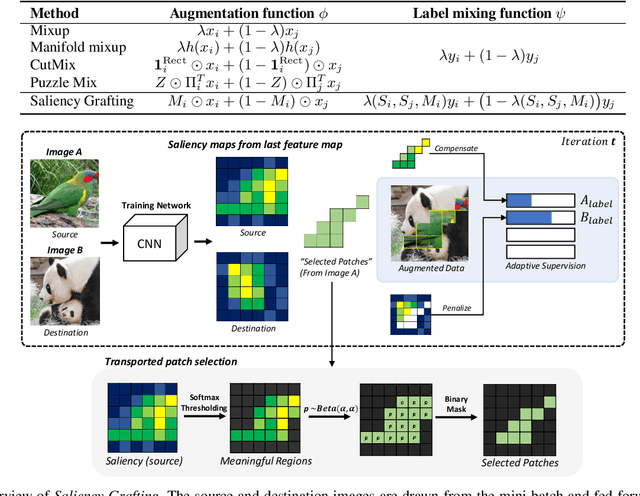
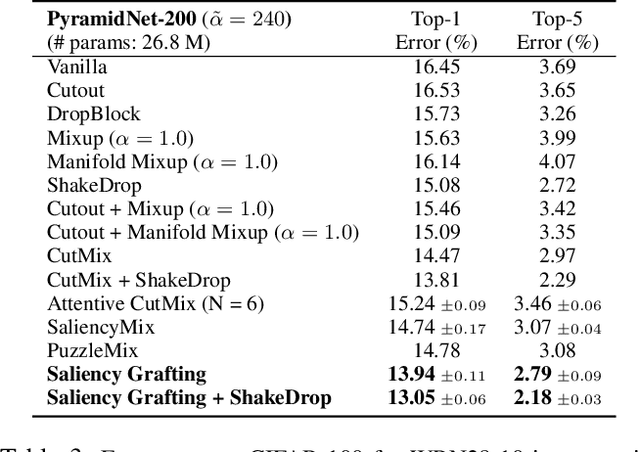

The Mixup scheme suggests mixing a pair of samples to create an augmented training sample and has gained considerable attention recently for improving the generalizability of neural networks. A straightforward and widely used extension of Mixup is to combine with regional dropout-like methods: removing random patches from a sample and replacing it with the features from another sample. Albeit their simplicity and effectiveness, these methods are prone to create harmful samples due to their randomness. To address this issue, 'maximum saliency' strategies were recently proposed: they select only the most informative features to prevent such a phenomenon. However, they now suffer from lack of sample diversification as they always deterministically select regions with maximum saliency, injecting bias into the augmented data. In this paper, we present, a novel, yet simple Mixup-variant that captures the best of both worlds. Our idea is two-fold. By stochastically sampling the features and 'grafting' them onto another sample, our method effectively generates diverse yet meaningful samples. Its second ingredient is to produce the label of the grafted sample by mixing the labels in a saliency-calibrated fashion, which rectifies supervision misguidance introduced by the random sampling procedure. Our experiments under CIFAR, Tiny-ImageNet, and ImageNet datasets show that our scheme outperforms the current state-of-the-art augmentation strategies not only in terms of classification accuracy, but is also superior in coping under stress conditions such as data corruption and object occlusion.
DAPPER: Performance Estimation of Domain Adaptation in Mobile Sensing
Nov 22, 2021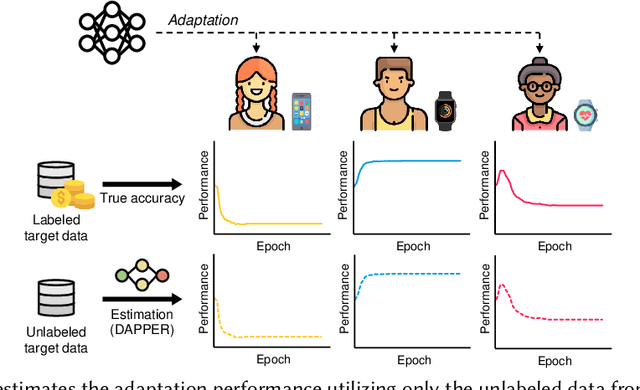

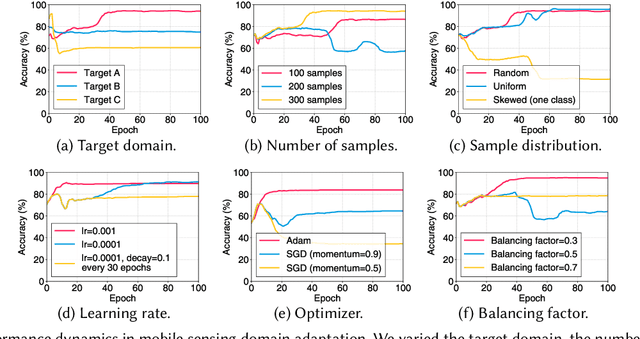
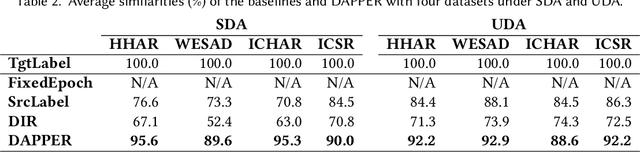
Many applications that utilize sensors in mobile devices and apply machine learning to provide novel services have emerged. However, various factors such as different users, devices, environments, and hyperparameters, affect the performance for such applications, thus making the domain shift (i.e., distribution shift of a target user from the training source dataset) an important problem. Although recent domain adaptation techniques attempt to solve this problem, the complex interplay between the diverse factors often limits their effectiveness. We argue that accurately estimating the performance in untrained domains could significantly reduce performance uncertainty. We present DAPPER (Domain AdaPtation Performance EstimatoR) that estimates the adaptation performance in a target domain with only unlabeled target data. Our intuition is that the outputs of a model on the target data provide clues for the model's actual performance in the target domain. DAPPER does not require expensive labeling costs nor involve additional training after deployment. Our evaluation with four real-world sensing datasets compared against four baselines shows that DAPPER outperforms the baselines by on average 17% in estimation accuracy. Moreover, our on-device experiment shows that DAPPER achieves up to 216X less computation overhead compared with the baselines.
Improving Transferability of Representations via Augmentation-Aware Self-Supervision
Nov 18, 2021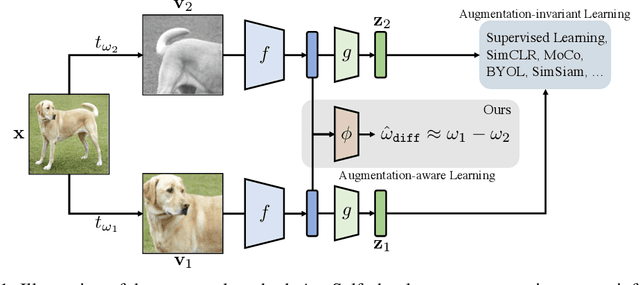
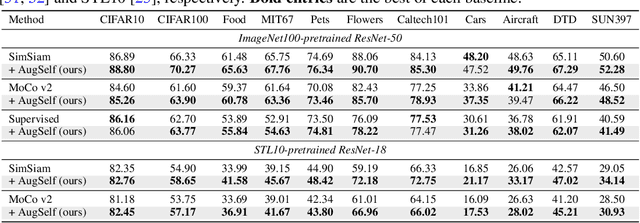
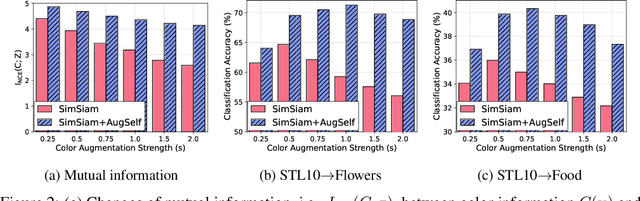
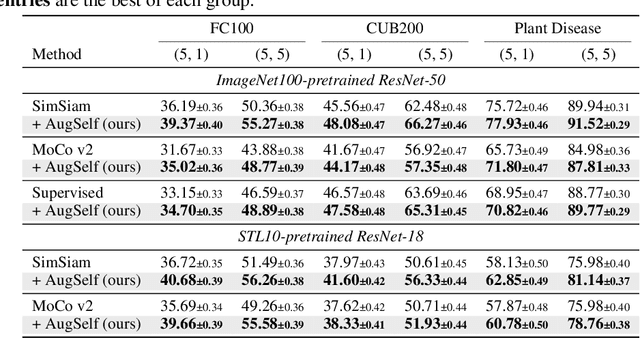
Recent unsupervised representation learning methods have shown to be effective in a range of vision tasks by learning representations invariant to data augmentations such as random cropping and color jittering. However, such invariance could be harmful to downstream tasks if they rely on the characteristics of the data augmentations, e.g., location- or color-sensitive. This is not an issue just for unsupervised learning; we found that this occurs even in supervised learning because it also learns to predict the same label for all augmented samples of an instance. To avoid such failures and obtain more generalizable representations, we suggest to optimize an auxiliary self-supervised loss, coined AugSelf, that learns the difference of augmentation parameters (e.g., cropping positions, color adjustment intensities) between two randomly augmented samples. Our intuition is that AugSelf encourages to preserve augmentation-aware information in learned representations, which could be beneficial for their transferability. Furthermore, AugSelf can easily be incorporated into recent state-of-the-art representation learning methods with a negligible additional training cost. Extensive experiments demonstrate that our simple idea consistently improves the transferability of representations learned by supervised and unsupervised methods in various transfer learning scenarios. The code is available at https://github.com/hankook/AugSelf.
SmoothMix: Training Confidence-calibrated Smoothed Classifiers for Certified Robustness
Nov 17, 2021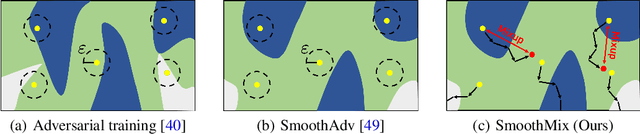

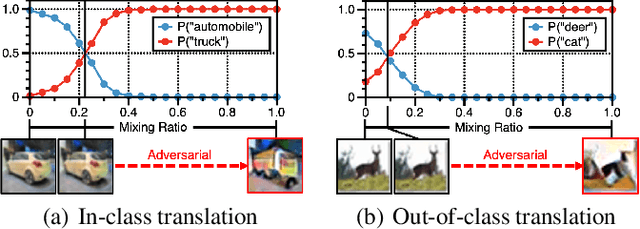
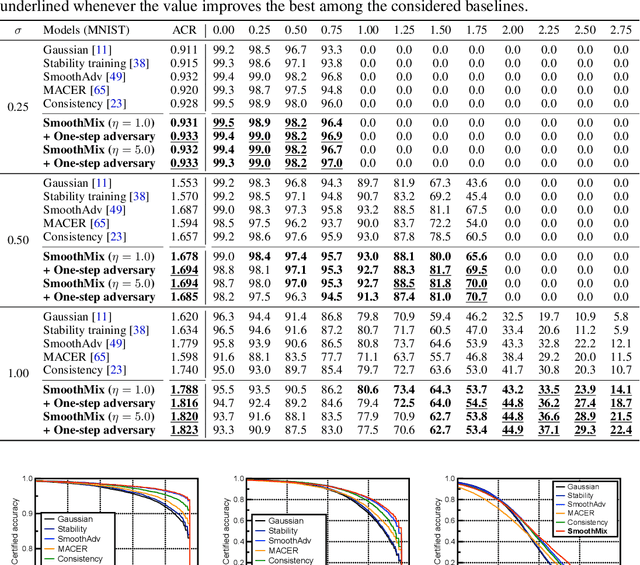
Randomized smoothing is currently a state-of-the-art method to construct a certifiably robust classifier from neural networks against $\ell_2$-adversarial perturbations. Under the paradigm, the robustness of a classifier is aligned with the prediction confidence, i.e., the higher confidence from a smoothed classifier implies the better robustness. This motivates us to rethink the fundamental trade-off between accuracy and robustness in terms of calibrating confidences of a smoothed classifier. In this paper, we propose a simple training scheme, coined SmoothMix, to control the robustness of smoothed classifiers via self-mixup: it trains on convex combinations of samples along the direction of adversarial perturbation for each input. The proposed procedure effectively identifies over-confident, near off-class samples as a cause of limited robustness in case of smoothed classifiers, and offers an intuitive way to adaptively set a new decision boundary between these samples for better robustness. Our experimental results demonstrate that the proposed method can significantly improve the certified $\ell_2$-robustness of smoothed classifiers compared to existing state-of-the-art robust training methods.