 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBreak-for-Make: Modular Low-Rank Adaptations for Composable Content-Style Customization
Mar 31, 2024



Personalized generation paradigms empower designers to customize visual intellectual properties with the help of textual descriptions by tuning or adapting pre-trained text-to-image models on a few images. Recent works explore approaches for concurrently customizing both content and detailed visual style appearance. However, these existing approaches often generate images where the content and style are entangled. In this study, we reconsider the customization of content and style concepts from the perspective of parameter space construction. Unlike existing methods that utilize a shared parameter space for content and style, we propose a learning framework that separates the parameter space to facilitate individual learning of content and style, thereby enabling disentangled content and style. To achieve this goal, we introduce "partly learnable projection" (PLP) matrices to separate the original adapters into divided sub-parameter spaces. We propose "break-for-make" customization learning pipeline based on PLP, which is simple yet effective. We break the original adapters into "up projection" and "down projection", train content and style PLPs individually with the guidance of corresponding textual prompts in the separate adapters, and maintain generalization by employing a multi-correspondence projection learning strategy. Based on the adapters broken apart for separate training content and style, we then make the entity parameter space by reconstructing the content and style PLPs matrices, followed by fine-tuning the combined adapter to generate the target object with the desired appearance. Experiments on various styles, including textures, materials, and artistic style, show that our method outperforms state-of-the-art single/multiple concept learning pipelines in terms of content-style-prompt alignment.
U-VAP: User-specified Visual Appearance Personalization via Decoupled Self Augmentation
Mar 29, 2024



Concept personalization methods enable large text-to-image models to learn specific subjects (e.g., objects/poses/3D models) and synthesize renditions in new contexts. Given that the image references are highly biased towards visual attributes, state-of-the-art personalization models tend to overfit the whole subject and cannot disentangle visual characteristics in pixel space. In this study, we proposed a more challenging setting, namely fine-grained visual appearance personalization. Different from existing methods, we allow users to provide a sentence describing the desired attributes. A novel decoupled self-augmentation strategy is proposed to generate target-related and non-target samples to learn user-specified visual attributes. These augmented data allow for refining the model's understanding of the target attribute while mitigating the impact of unrelated attributes. At the inference stage, adjustments are conducted on semantic space through the learned target and non-target embeddings to further enhance the disentanglement of target attributes. Extensive experiments on various kinds of visual attributes with SOTA personalization methods show the ability of the proposed method to mimic target visual appearance in novel contexts, thus improving the controllability and flexibility of personalization.
Make-Your-Anchor: A Diffusion-based 2D Avatar Generation Framework
Mar 25, 2024



Despite the remarkable process of talking-head-based avatar-creating solutions, directly generating anchor-style videos with full-body motions remains challenging. In this study, we propose Make-Your-Anchor, a novel system necessitating only a one-minute video clip of an individual for training, subsequently enabling the automatic generation of anchor-style videos with precise torso and hand movements. Specifically, we finetune a proposed structure-guided diffusion model on input video to render 3D mesh conditions into human appearances. We adopt a two-stage training strategy for the diffusion model, effectively binding movements with specific appearances. To produce arbitrary long temporal video, we extend the 2D U-Net in the frame-wise diffusion model to a 3D style without additional training cost, and a simple yet effective batch-overlapped temporal denoising module is proposed to bypass the constraints on video length during inference. Finally, a novel identity-specific face enhancement module is introduced to improve the visual quality of facial regions in the output videos. Comparative experiments demonstrate the effectiveness and superiority of the system in terms of visual quality, temporal coherence, and identity preservation, outperforming SOTA diffusion/non-diffusion methods. Project page: \url{https://github.com/ICTMCG/Make-Your-Anchor}.
FlightLLM: Efficient Large Language Model Inference with a Complete Mapping Flow on FPGAs
Jan 09, 2024



Transformer-based Large Language Models (LLMs) have made a significant impact on various domains. However, LLMs' efficiency suffers from both heavy computation and memory overheads. Compression techniques like sparsification and quantization are commonly used to mitigate the gap between LLM's computation/memory overheads and hardware capacity. However, existing GPU and transformer-based accelerators cannot efficiently process compressed LLMs, due to the following unresolved challenges: low computational efficiency, underutilized memory bandwidth, and large compilation overheads. This paper proposes FlightLLM, enabling efficient LLMs inference with a complete mapping flow on FPGAs. In FlightLLM, we highlight an innovative solution that the computation and memory overhead of LLMs can be solved by utilizing FPGA-specific resources (e.g., DSP48 and heterogeneous memory hierarchy). We propose a configurable sparse DSP chain to support different sparsity patterns with high computation efficiency. Second, we propose an always-on-chip decode scheme to boost memory bandwidth with mixed-precision support. Finally, to make FlightLLM available for real-world LLMs, we propose a length adaptive compilation method to reduce the compilation overhead. Implemented on the Xilinx Alveo U280 FPGA, FlightLLM achieves 6.0$\times$ higher energy efficiency and 1.8$\times$ better cost efficiency against commercial GPUs (e.g., NVIDIA V100S) on modern LLMs (e.g., LLaMA2-7B) using vLLM and SmoothQuant under the batch size of one. FlightLLM beats NVIDIA A100 GPU with 1.2$\times$ higher throughput using the latest Versal VHK158 FPGA.
Exploiting User Comments for Early Detection of Fake News Prior to Users' Commenting
Oct 16, 2023



Both accuracy and timeliness are key factors in detecting fake news on social media. However, most existing methods encounter an accuracy-timeliness dilemma: Content-only methods guarantee timeliness but perform moderately because of limited available information, while social context-based ones generally perform better but inevitably lead to latency because of social context accumulation needs. To break such a dilemma, a feasible but not well-studied solution is to leverage social contexts (e.g., comments) from historical news for training a detection model and apply it to newly emerging news without social contexts. This requires the model to (1) sufficiently learn helpful knowledge from social contexts, and (2) be well compatible with situations that social contexts are available or not. To achieve this goal, we propose to absorb and parameterize useful knowledge from comments in historical news and then inject it into a content-only detection model. Specifically, we design the Comments Assisted Fake News Detection method (CAS-FEND), which transfers useful knowledge from a comments-aware teacher model to a content-only student model during training. The student model is further used to detect newly emerging fake news. Experiments show that the CAS-FEND student model outperforms all content-only methods and even those with 1/4 comments as inputs, demonstrating its superiority for early detection.
Online Misinformation Video Detection: A Survey
Feb 07, 2023



With information consumption via online video streaming becoming increasingly popular, misinformation video poses a new threat to the health of the online information ecosystem. Though previous studies have made much progress in detecting misinformation in text and image formats, video-based misinformation brings new and unique challenges to automatic detection systems: 1) high information heterogeneity brought by various modalities, 2) blurred distinction between misleading video manipulation and ubiquitous artistic video editing, and 3) new patterns of misinformation propagation due to the dominant role of recommendation systems on online video platforms. To facilitate research on this challenging task, we conduct this survey to present advances in misinformation video detection research. We first analyze and characterize the misinformation video from three levels including signals, semantics, and intents. Based on the characterization, we systematically review existing works for detection from features of various modalities to techniques for clue integration. We also introduce existing resources including representative datasets and widely used tools. Besides summarizing existing studies, we discuss related areas and outline open issues and future directions to encourage and guide more research on misinformation video detection. Our corresponding public repository is available at https://github.com/ICTMCG/Awesome-Misinfo-Video-Detection.
Improving Fake News Detection of Influential Domain via Domain- and Instance-Level Transfer
Oct 09, 2022
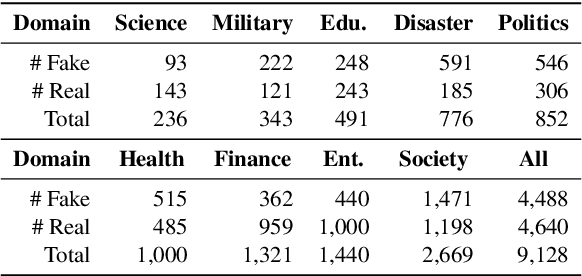
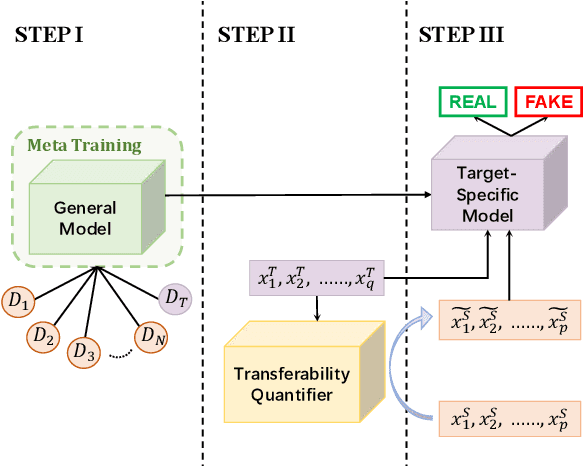
Both real and fake news in various domains, such as politics, health, and entertainment are spread via online social media every day, necessitating fake news detection for multiple domains. Among them, fake news in specific domains like politics and health has more serious potential negative impacts on the real world (e.g., the infodemic led by COVID-19 misinformation). Previous studies focus on multi-domain fake news detection, by equally mining and modeling the correlation between domains. However, these multi-domain methods suffer from a seesaw problem: the performance of some domains is often improved at the cost of hurting the performance of other domains, which could lead to an unsatisfying performance in specific domains. To address this issue, we propose a Domain- and Instance-level Transfer Framework for Fake News Detection (DITFEND), which could improve the performance of specific target domains. To transfer coarse-grained domain-level knowledge, we train a general model with data of all domains from the meta-learning perspective. To transfer fine-grained instance-level knowledge and adapt the general model to a target domain, we train a language model on the target domain to evaluate the transferability of each data instance in source domains and re-weigh each instance's contribution. Offline experiments on two datasets demonstrate the effectiveness of DITFEND. Online experiments show that DITFEND brings additional improvements over the base models in a real-world scenario.
Characterizing Multi-Domain False News and Underlying User Effects on Chinese Weibo
May 06, 2022
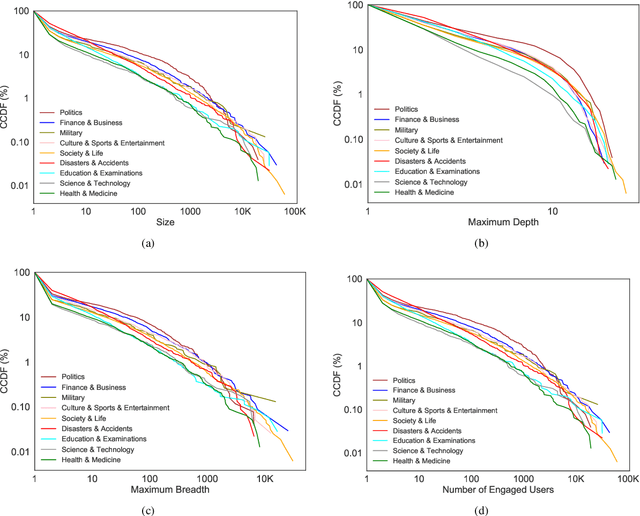
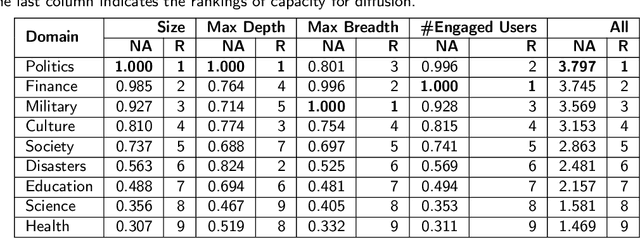
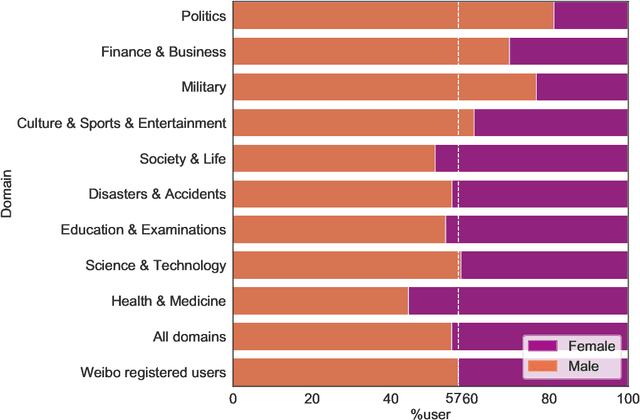
False news that spreads on social media has proliferated over the past years and has led to multi-aspect threats in the real world. While there are studies of false news on specific domains (like politics or health care), little work is found comparing false news across domains. In this article, we investigate false news across nine domains on Weibo, the largest Twitter-like social media platform in China, from 2009 to 2019. The newly collected data comprise 44,728 posts in the nine domains, published by 40,215 users, and reposted over 3.4 million times. Based on the distributions and spreads of the multi-domain dataset, we observe that false news in domains that are close to daily life like health and medicine generated more posts but diffused less effectively than those in other domains like politics, and that political false news had the most effective capacity for diffusion. The widely diffused false news posts on Weibo were associated strongly with certain types of users -- by gender, age, etc. Further, these posts provoked strong emotions in the reposts and diffused further with the active engagement of false-news starters. Our findings have the potential to help design false news detection systems in suspicious news discovery, veracity prediction, and display and explanation. The comparison of the findings on Weibo with those of existing work demonstrates nuanced patterns, suggesting the need for more research on data from diverse platforms, countries, or languages to tackle the global issue of false news. The code and new anonymized dataset are available at https://github.com/ICTMCG/Characterizing-Weibo-Multi-Domain-False-News.
A Prompting-based Approach for Adversarial Example Generation and Robustness Enhancement
Mar 21, 2022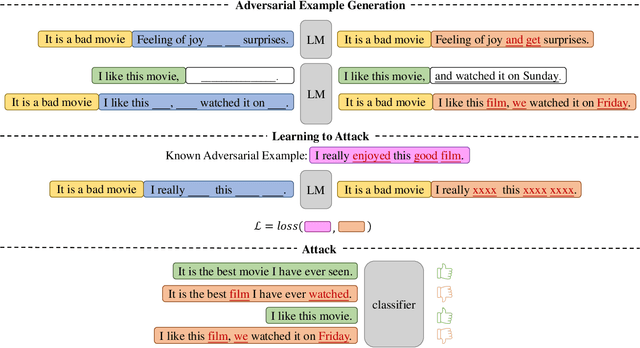



Recent years have seen the wide application of NLP models in crucial areas such as finance, medical treatment, and news media, raising concerns of the model robustness and vulnerabilities. In this paper, we propose a novel prompt-based adversarial attack to compromise NLP models and robustness enhancement technique. We first construct malicious prompts for each instance and generate adversarial examples via mask-and-filling under the effect of a malicious purpose. Our attack technique targets the inherent vulnerabilities of NLP models, allowing us to generate samples even without interacting with the victim NLP model, as long as it is based on pre-trained language models (PLMs). Furthermore, we design a prompt-based adversarial training method to improve the robustness of PLMs. As our training method does not actually generate adversarial samples, it can be applied to large-scale training sets efficiently. The experimental results show that our attack method can achieve a high attack success rate with more diverse, fluent and natural adversarial examples. In addition, our robustness enhancement method can significantly improve the robustness of models to resist adversarial attacks. Our work indicates that prompting paradigm has great potential in probing some fundamental flaws of PLMs and fine-tuning them for downstream tasks.
DRAG: Dynamic Region-Aware GCN for Privacy-Leaking Image Detection
Mar 17, 2022
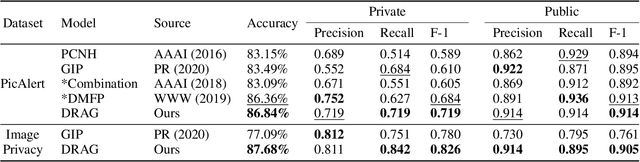
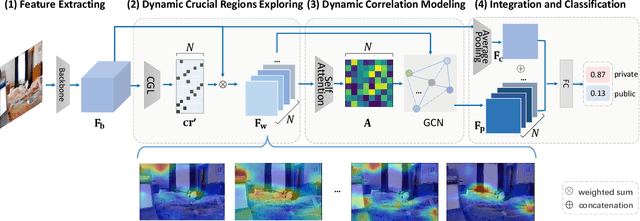
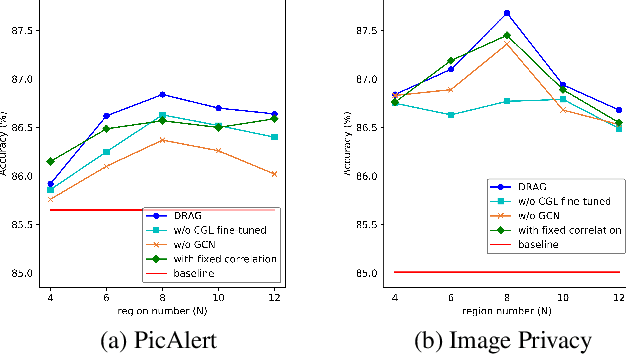
The daily practice of sharing images on social media raises a severe issue about privacy leakage. To address the issue, privacy-leaking image detection is studied recently, with the goal to automatically identify images that may leak privacy. Recent advance on this task benefits from focusing on crucial objects via pretrained object detectors and modeling their correlation. However, these methods have two limitations: 1) they neglect other important elements like scenes, textures, and objects beyond the capacity of pretrained object detectors; 2) the correlation among objects is fixed, but a fixed correlation is not appropriate for all the images. To overcome the limitations, we propose the Dynamic Region-Aware Graph Convolutional Network (DRAG) that dynamically finds out crucial regions including objects and other important elements, and models their correlation adaptively for each input image. To find out crucial regions, we cluster spatially-correlated feature channels into several region-aware feature maps. Further, we dynamically model the correlation with the self-attention mechanism and explore the interaction among the regions with a graph convolutional network. The DRAG achieved an accuracy of 87% on the largest dataset for privacy-leaking image detection, which is 10 percentage points higher than the state of the art. The further case study demonstrates that it found out crucial regions containing not only objects but other important elements like textures.