 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Waveform Robustness: Robust Feature-Vocoder Adversarial Attacks on Automatic Speech Recognition
Jun 04, 2026Automatic speech recognition (ASR) systems have become widely used for multilingual speech-to-text transcription. Their robustness to adversarial attacks has become an important topic for the community. Existing adversarial attacks directly add adversarial noise to the speech audio. However, prior work has shown that existing adversarial attacks face two limitations: they often transfer poorly to black-box ASR systems and are increasingly mitigated by defenses tailored to input-space perturbations. In this work, we propose a Clean-Referenced Feature-Vocoder Attack, a surrogate-based black-box attack that moves the adversarial search space from raw waveforms to self-supervised learning (SSL) representations. To address the transferability limitation, we perturb more generalizable acoustic-phonetic representations rather than low-level waveform samples, reducing dependence on surrogate-specific waveform gradients and encouraging adversarial perturbations that generalize across ASR systems. To bypass different defenses, we shift the adversarial signal from explicit additive waveform noise to SSL feature-space perturbations and reconstruct them through a vocoder into speech-like waveform adversarial signals, making the resulting samples less aligned with waveform-bounded defenses. Extensive experiments show that, when optimized only on raw Whisper-small as a public surrogate model, our attack transfers effectively to black-box ASR models with a +26.6 WER improvement over the SOTA baseline, while also remaining effective against multiple training defenses with a +36.2 WER improvement. These results reveal a blind spot in current ASR robustness evaluation.
PC2P: Multi-Agent Path Finding via Personalized-Enhanced Communication and Crowd Perception
Jan 06, 2026Distributed Multi-Agent Path Finding (MAPF) integrated with Multi-Agent Reinforcement Learning (MARL) has emerged as a prominent research focus, enabling real-time cooperative decision-making in partially observable environments through inter-agent communication. However, due to insufficient collaborative and perceptual capabilities, existing methods are inadequate for scaling across diverse environmental conditions. To address these challenges, we propose PC2P, a novel distributed MAPF method derived from a Q-learning-based MARL framework. Initially, we introduce a personalized-enhanced communication mechanism based on dynamic graph topology, which ascertains the core aspects of ``who" and ``what" in interactive process through three-stage operations: selection, generation, and aggregation. Concurrently, we incorporate local crowd perception to enrich agents' heuristic observation, thereby strengthening the model's guidance for effective actions via the integration of static spatial constraints and dynamic occupancy changes. To resolve extreme deadlock issues, we propose a region-based deadlock-breaking strategy that leverages expert guidance to implement efficient coordination within confined areas. Experimental results demonstrate that PC2P achieves superior performance compared to state-of-the-art distributed MAPF methods in varied environments. Ablation studies further confirm the effectiveness of each module for overall performance.
Multi-Preference Lambda-weighted Listwise DPO for Dynamic Preference Alignment
Jun 24, 2025While large-scale unsupervised language models (LMs) capture broad world knowledge and reasoning capabilities, steering their behavior toward desired objectives remains challenging due to the lack of explicit supervision. Existing alignment techniques, such as reinforcement learning from human feedback (RLHF), rely on training a reward model and performing reinforcement learning to align with human preferences. However, RLHF is often computationally intensive, unstable, and sensitive to hyperparameters. To address these limitations, Direct Preference Optimization (DPO) was introduced as a lightweight and stable alternative, enabling direct alignment of language models with pairwise preference data via classification loss. However, DPO and its extensions generally assume a single static preference distribution, limiting flexibility in multi-objective or dynamic alignment settings. In this paper, we propose a novel framework: Multi-Preference Lambda-weighted Listwise DPO, which extends DPO to incorporate multiple human preference dimensions (e.g., helpfulness, harmlessness, informativeness) and enables dynamic interpolation through a controllable simplex-weighted formulation. Our method supports both listwise preference feedback and flexible alignment across varying user intents without re-training. Empirical and theoretical analysis demonstrates that our method is as effective as traditional DPO on static objectives while offering greater generality and adaptability for real-world deployment.
Modeling Homophone Noise for Robust Neural Machine Translation
Dec 15, 2020
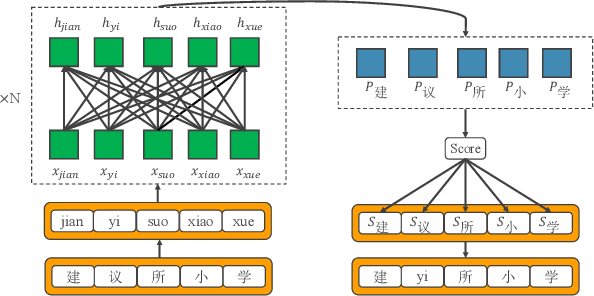
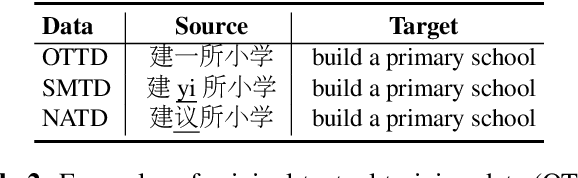
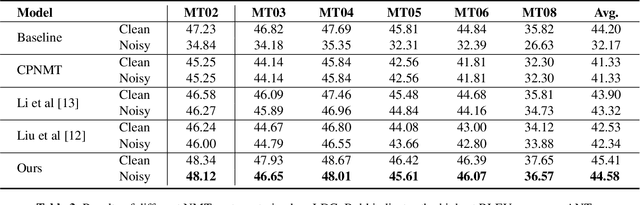
In this paper, we propose a robust neural machine translation (NMT) framework. The framework consists of a homophone noise detector and a syllable-aware NMT model to homophone errors. The detector identifies potential homophone errors in a textual sentence and converts them into syllables to form a mixed sequence that is then fed into the syllable-aware NMT. Extensive experiments on Chinese->English translation demonstrate that our proposed method not only significantly outperforms baselines on noisy test sets with homophone noise, but also achieves a substantial improvement on clean text.