 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModeling Task Interactions in Document-Level Joint Entity and Relation Extraction
May 04, 2022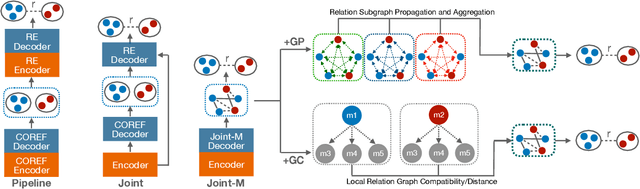
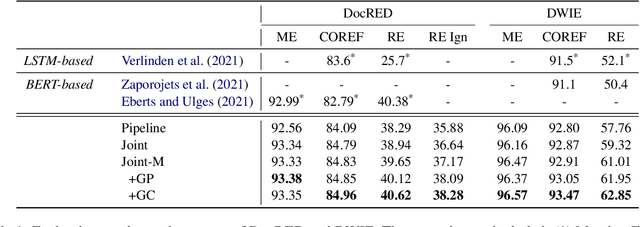


We target on the document-level relation extraction in an end-to-end setting, where the model needs to jointly perform mention extraction, coreference resolution (COREF) and relation extraction (RE) at once, and gets evaluated in an entity-centric way. Especially, we address the two-way interaction between COREF and RE that has not been the focus by previous work, and propose to introduce explicit interaction namely Graph Compatibility (GC) that is specifically designed to leverage task characteristics, bridging decisions of two tasks for direct task interference. Our experiments are conducted on DocRED and DWIE; in addition to GC, we implement and compare different multi-task settings commonly adopted in previous work, including pipeline, shared encoders, graph propagation, to examine the effectiveness of different interactions. The result shows that GC achieves the best performance by up to 2.3/5.1 F1 improvement over the baseline.
Zero-Shot Cross-Lingual Machine Reading Comprehension via Inter-Sentence Dependency Graph
Dec 09, 2021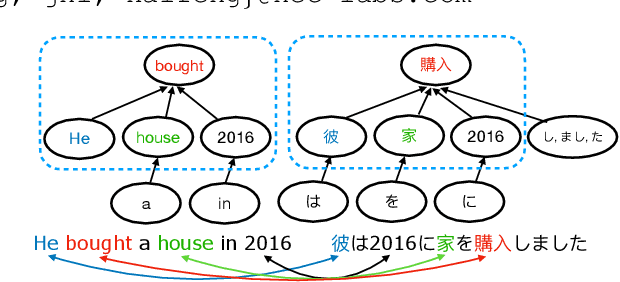
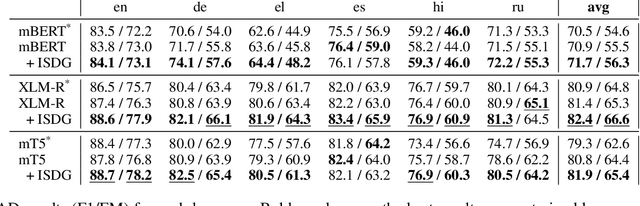
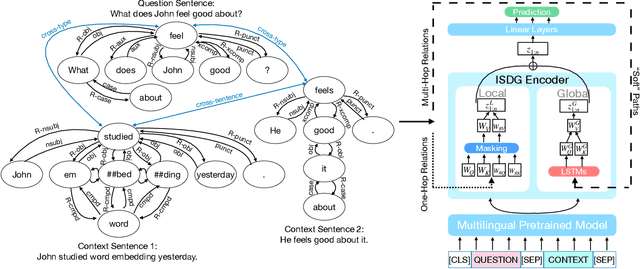
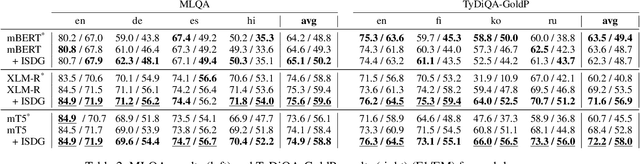
We target the task of cross-lingual Machine Reading Comprehension (MRC) in the direct zero-shot setting, by incorporating syntactic features from Universal Dependencies (UD), and the key features we use are the syntactic relations within each sentence. While previous work has demonstrated effective syntax-guided MRC models, we propose to adopt the inter-sentence syntactic relations, in addition to the rudimentary intra-sentence relations, to further utilize the syntactic dependencies in the multi-sentence input of the MRC task. In our approach, we build the Inter-Sentence Dependency Graph (ISDG) connecting dependency trees to form global syntactic relations across sentences. We then propose the ISDG encoder that encodes the global dependency graph, addressing the inter-sentence relations via both one-hop and multi-hop dependency paths explicitly. Experiments on three multilingual MRC datasets (XQuAD, MLQA, TyDiQA-GoldP) show that our encoder that is only trained on English is able to improve the zero-shot performance on all 14 test sets covering 8 languages, with up to 3.8 F1 / 5.2 EM improvement on-average, and 5.2 F1 / 11.2 EM on certain languages. Further analysis shows the improvement can be attributed to the attention on the cross-linguistically consistent syntactic path.
NL-Augmenter: A Framework for Task-Sensitive Natural Language Augmentation
Dec 06, 2021



Data augmentation is an important component in the robustness evaluation of models in natural language processing (NLP) and in enhancing the diversity of the data they are trained on. In this paper, we present NL-Augmenter, a new participatory Python-based natural language augmentation framework which supports the creation of both transformations (modifications to the data) and filters (data splits according to specific features). We describe the framework and an initial set of 117 transformations and 23 filters for a variety of natural language tasks. We demonstrate the efficacy of NL-Augmenter by using several of its transformations to analyze the robustness of popular natural language models. The infrastructure, datacards and robustness analysis results are available publicly on the NL-Augmenter repository (\url{https://github.com/GEM-benchmark/NL-Augmenter}).
What Went Wrong? Explaining Overall Dialogue Quality through Utterance-Level Impacts
Oct 31, 2021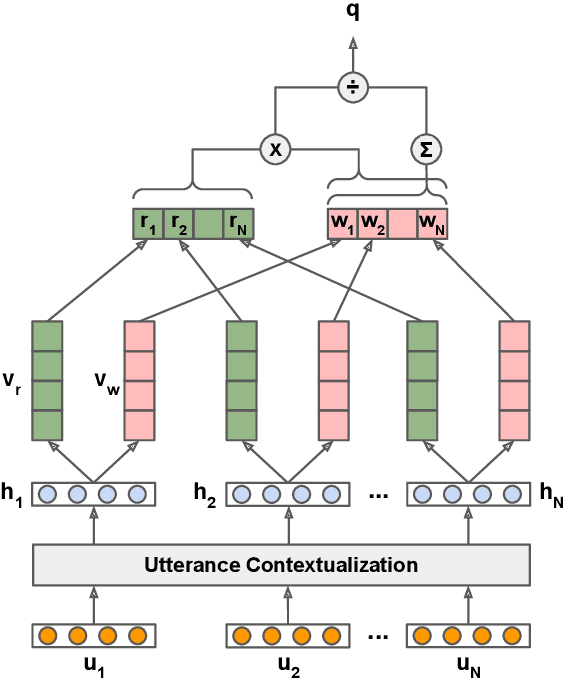
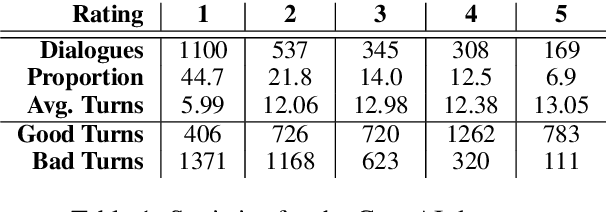

Improving user experience of a dialogue system often requires intensive developer effort to read conversation logs, run statistical analyses, and intuit the relative importance of system shortcomings. This paper presents a novel approach to automated analysis of conversation logs that learns the relationship between user-system interactions and overall dialogue quality. Unlike prior work on utterance-level quality prediction, our approach learns the impact of each interaction from the overall user rating without utterance-level annotation, allowing resultant model conclusions to be derived on the basis of empirical evidence and at low cost. Our model identifies interactions that have a strong correlation with the overall dialogue quality in a chatbot setting. Experiments show that the automated analysis from our model agrees with expert judgments, making this work the first to show that such weakly-supervised learning of utterance-level quality prediction is highly achievable.
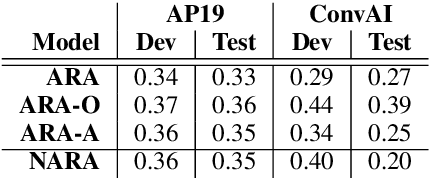
An Approach to Inference-Driven Dialogue Management within a Social Chatbot
Oct 31, 2021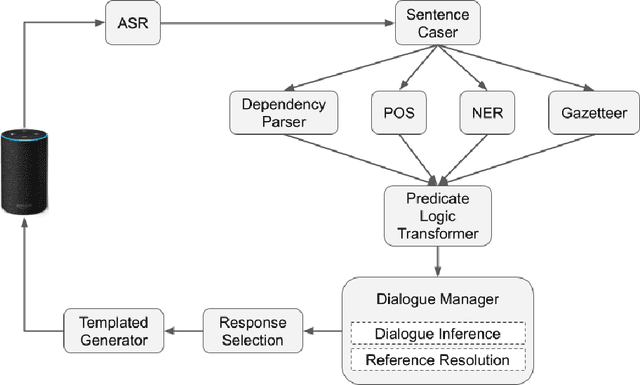
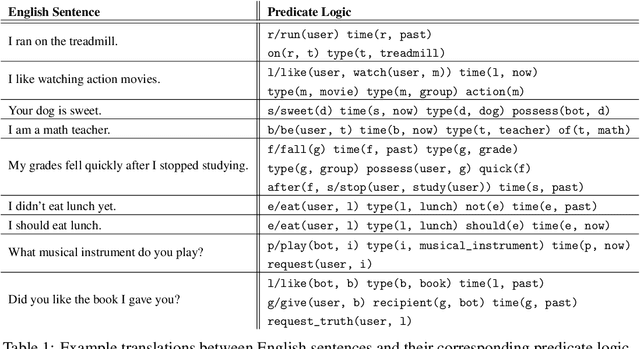
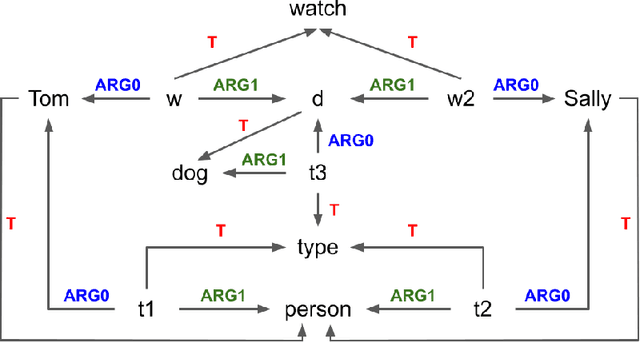
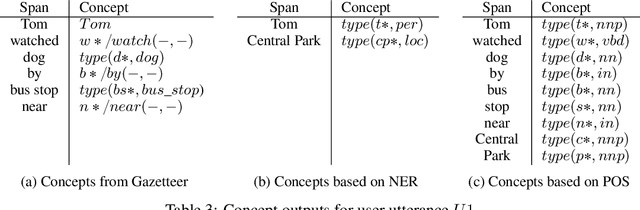
We present a chatbot implementing a novel dialogue management approach based on logical inference. Instead of framing conversation a sequence of response generation tasks, we model conversation as a collaborative inference process in which speakers share information to synthesize new knowledge in real time. Our chatbot pipeline accomplishes this modelling in three broad stages. The first stage translates user utterances into a symbolic predicate representation. The second stage then uses this structured representation in conjunction with a larger knowledge base to synthesize new predicates using efficient graph matching. In the third and final stage, our bot selects a small subset of predicates and translates them into an English response. This approach lends itself to understanding latent semantics of user inputs, flexible initiative taking, and responses that are novel and coherent with the dialogue context.
Intensionalizing Abstract Meaning Representations: Non-Veridicality and Scope
Sep 20, 2021Abstract Meaning Representation (AMR) is a graphical meaning representation language designed to represent propositional information about argument structure. However, at present it is unable to satisfyingly represent non-veridical intensional contexts, often licensing inappropriate inferences. In this paper, we show how to resolve the problem of non-veridicality without appealing to layered graphs through a mapping from AMRs into Simply-Typed Lambda Calculus (STLC). At least for some cases, this requires the introduction of a new role :content which functions as an intensional operator. The translation proposed is inspired by the formal linguistics literature on the event semantics of attitude reports. Next, we address the interaction of quantifier scope and intensional operators in so-called de re/de dicto ambiguities. We adopt a scope node from the literature and provide an explicit multidimensional semantics utilizing Cooper storage which allows us to derive the de re and de dicto scope readings as well as intermediate scope readings which prove difficult for accounts without a scope node.
StreamSide: A Fully-Customizable Open-Source Toolkit for Efficient Annotation of Meaning Representations
Sep 20, 2021
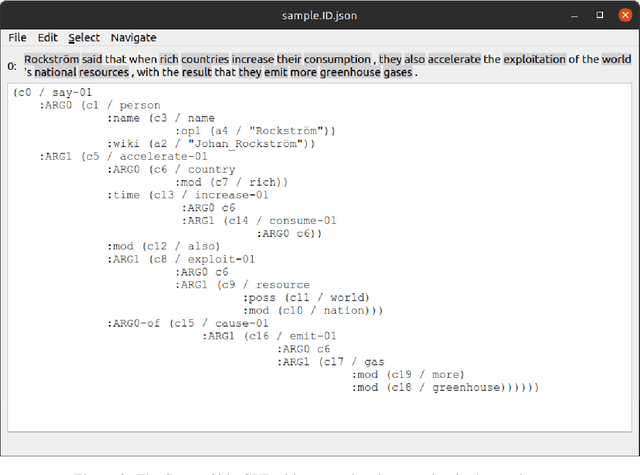
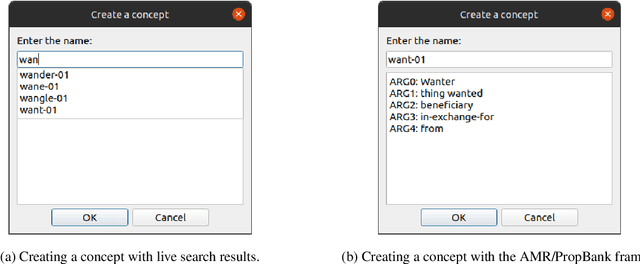
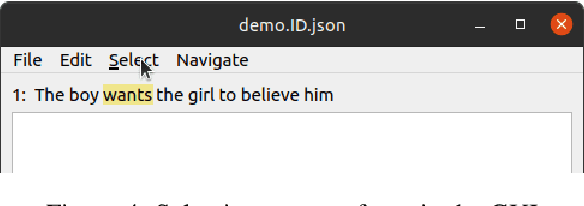
This demonstration paper presents StreamSide, an open-source toolkit for annotating multiple kinds of meaning representations. StreamSide supports frame-based annotation schemes e.g., Abstract Meaning Representation (AMR) and frameless annotation schemes e.g., Widely Interpretable Semantic Representation (WISeR). Moreover, it supports both sentence-level and document-level annotation by allowing annotators to create multi-rooted graphs for input text. It can open and automatically convert between several types of input formats including plain text, Penman notation, and its own JSON format enabling richer annotation. It features reference frames for AMR predicate argument structures, and also concept-to-text alignment. StreamSide is released under the Apache 2.0 license, and is completely open-source so that it can be customized to annotate enriched meaning representations in different languages (e.g., Uniform Meaning Representations). All StreamSide resources are publicly distributed through our open source project at: https://github.com/emorynlp/StreamSide.
The Stem Cell Hypothesis: Dilemma behind Multi-Task Learning with Transformer Encoders
Sep 14, 2021
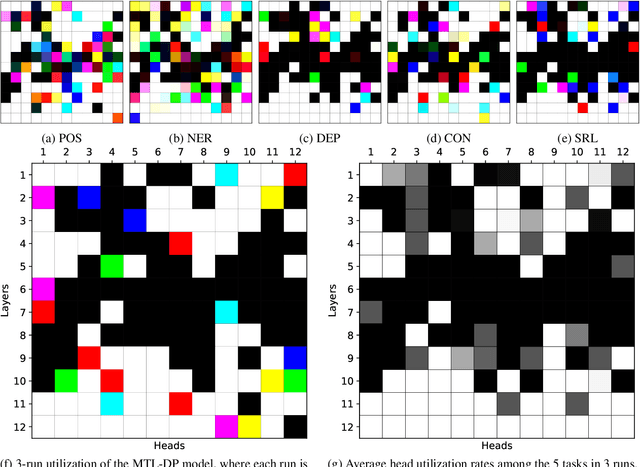

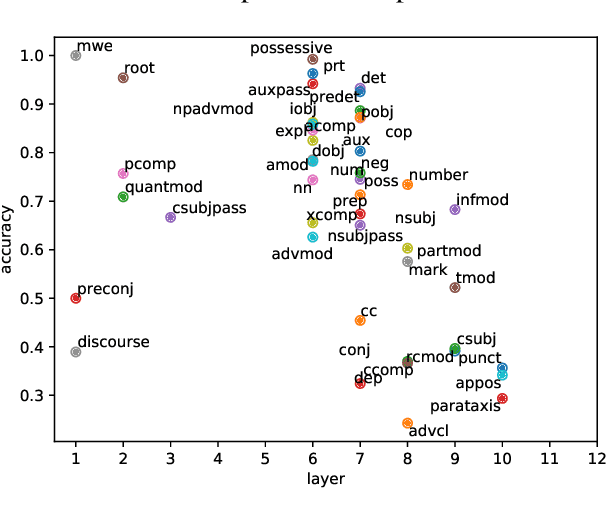
Multi-task learning with transformer encoders (MTL) has emerged as a powerful technique to improve performance on closely-related tasks for both accuracy and efficiency while a question still remains whether or not it would perform as well on tasks that are distinct in nature. We first present MTL results on five NLP tasks, POS, NER, DEP, CON, and SRL, and depict its deficiency over single-task learning. We then conduct an extensive pruning analysis to show that a certain set of attention heads get claimed by most tasks during MTL, who interfere with one another to fine-tune those heads for their own objectives. Based on this finding, we propose the Stem Cell Hypothesis to reveal the existence of attention heads naturally talented for many tasks that cannot be jointly trained to create adequate embeddings for all of those tasks. Finally, we design novel parameter-free probes to justify our hypothesis and demonstrate how attention heads are transformed across the five tasks during MTL through label analysis.
ELIT: Emory Language and Information Toolkit
Sep 08, 2021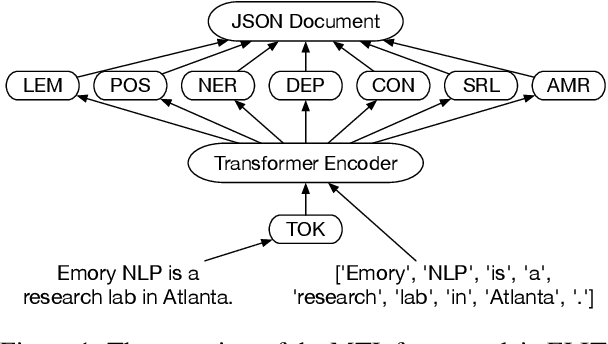
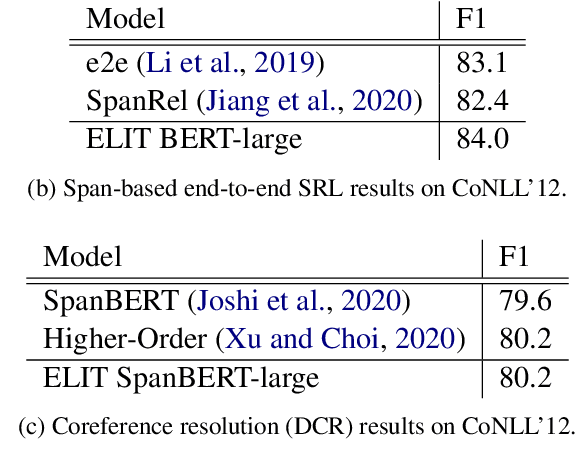

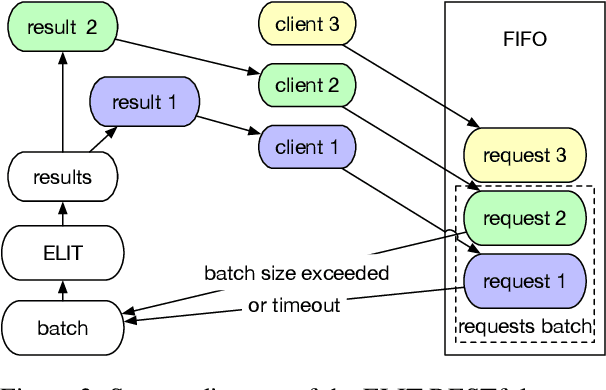
We introduce ELIT, the Emory Language and Information Toolkit, which is a comprehensive NLP framework providing transformer-based end-to-end models for core tasks with a special focus on memory efficiency while maintaining state-of-the-art accuracy and speed. Compared to existing toolkits, ELIT features an efficient Multi-Task Learning (MTL) model with many downstream tasks that include lemmatization, part-of-speech tagging, named entity recognition, dependency parsing, constituency parsing, semantic role labeling, and AMR parsing. The backbone of ELIT's MTL framework is a pre-trained transformer encoder that is shared across tasks to speed up their inference. ELIT provides pre-trained models developed on a remix of eight datasets. To scale up its service, ELIT also integrates a RESTful Client/Server combination. On the server side, ELIT extends its functionality to cover other tasks such as tokenization and coreference resolution, providing an end user with agile research experience. All resources including the source codes, documentation, and pre-trained models are publicly available at https://github.com/emorynlp/elit.
Boosting Cross-Lingual Transfer via Self-Learning with Uncertainty Estimation
Sep 01, 2021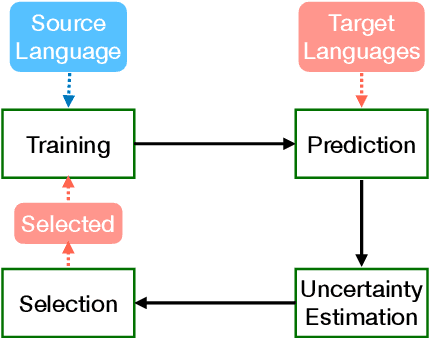
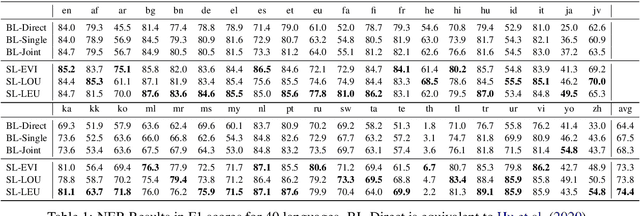
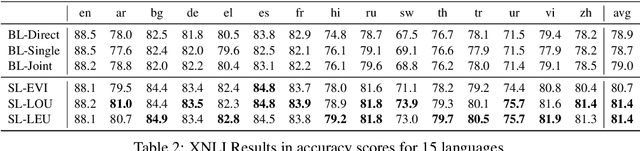
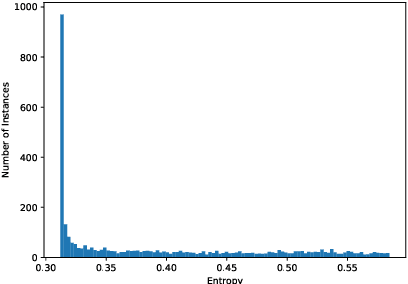
Recent multilingual pre-trained language models have achieved remarkable zero-shot performance, where the model is only finetuned on one source language and directly evaluated on target languages. In this work, we propose a self-learning framework that further utilizes unlabeled data of target languages, combined with uncertainty estimation in the process to select high-quality silver labels. Three different uncertainties are adapted and analyzed specifically for the cross lingual transfer: Language Heteroscedastic/Homoscedastic Uncertainty (LEU/LOU), Evidential Uncertainty (EVI). We evaluate our framework with uncertainties on two cross-lingual tasks including Named Entity Recognition (NER) and Natural Language Inference (NLI) covering 40 languages in total, which outperforms the baselines significantly by 10 F1 on average for NER and 2.5 accuracy score for NLI.