 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEF-Train: Enable Efficient On-device CNN Training on FPGA Through Data Reshaping for Online Adaptation or Personalization
Feb 18, 2022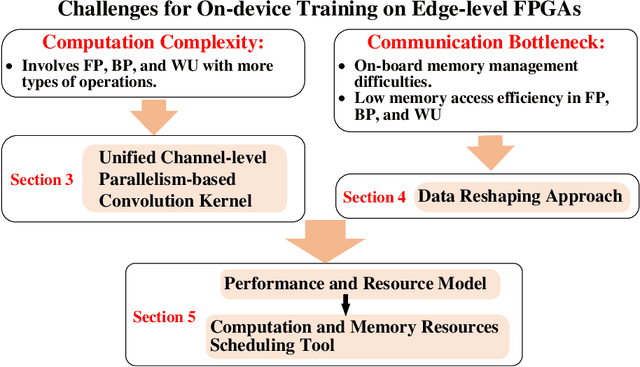
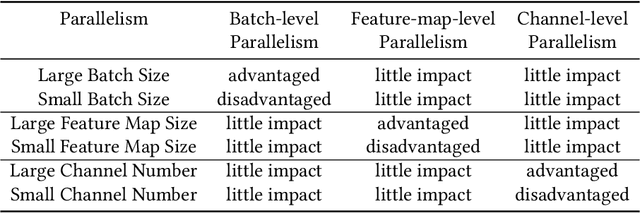
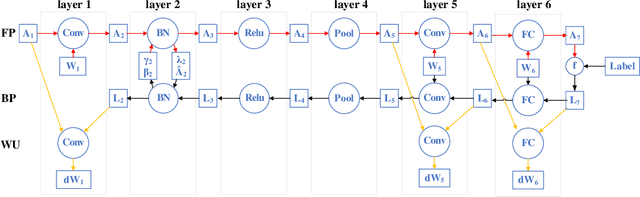
Conventionally, DNN models are trained once in the cloud and deployed in edge devices such as cars, robots, or unmanned aerial vehicles (UAVs) for real-time inference. However, there are many cases that require the models to adapt to new environments, domains, or new users. In order to realize such domain adaption or personalization, the models on devices need to be continuously trained on the device. In this work, we design EF-Train, an efficient DNN training accelerator with a unified channel-level parallelism-based convolution kernel that can achieve end-to-end training on resource-limited low-power edge-level FPGAs. It is challenging to implement on-device training on resource-limited FPGAs due to the low efficiency caused by different memory access patterns among forward, backward propagation, and weight update. Therefore, we developed a data reshaping approach with intra-tile continuous memory allocation and weight reuse. An analytical model is established to automatically schedule computation and memory resources to achieve high energy efficiency on edge FPGAs. The experimental results show that our design achieves 46.99 GFLOPS and 6.09GFLOPS/W in terms of throughput and energy efficiency, respectively.
Learn by Challenging Yourself: Contrastive Visual Representation Learning with Hard Sample Generation
Feb 14, 2022Contrastive learning (CL), a self-supervised learning approach, can effectively learn visual representations from unlabeled data. However, CL requires learning on vast quantities of diverse data to achieve good performance, without which the performance of CL will greatly degrade. To tackle this problem, we propose a framework with two approaches to improve the data efficiency of CL training by generating beneficial samples and joint learning. The first approach generates hard samples for the main model. The generator is jointly learned with the main model to dynamically customize hard samples based on the training state of the main model. With the progressively growing knowledge of the main model, the generated samples also become harder to constantly encourage the main model to learn better representations. Besides, a pair of data generators are proposed to generate similar but distinct samples as positive pairs. In joint learning, the hardness of a positive pair is progressively increased by decreasing their similarity. In this way, the main model learns to cluster hard positives by pulling the representations of similar yet distinct samples together, by which the representations of similar samples are well-clustered and better representations can be learned. Comprehensive experiments show superior accuracy and data efficiency of the proposed methods over the state-of-the-art on multiple datasets. For example, about 5% accuracy improvement on ImageNet-100 and CIFAR-10, and more than 6% accuracy improvement on CIFAR-100 are achieved for linear classification. Besides, up to 2x data efficiency for linear classification and up to 5x data efficiency for transfer learning are achieved.
Federated Contrastive Learning for Dermatological Disease Diagnosis via On-device Learning
Feb 14, 2022



Deep learning models have been deployed in an increasing number of edge and mobile devices to provide healthcare. These models rely on training with a tremendous amount of labeled data to achieve high accuracy. However, for medical applications such as dermatological disease diagnosis, the private data collected by mobile dermatology assistants exist on distributed mobile devices of patients, and each device only has a limited amount of data. Directly learning from limited data greatly deteriorates the performance of learned models. Federated learning (FL) can train models by using data distributed on devices while keeping the data local for privacy. Existing works on FL assume all the data have ground-truth labels. However, medical data often comes without any accompanying labels since labeling requires expertise and results in prohibitively high labor costs. The recently developed self-supervised learning approach, contrastive learning (CL), can leverage the unlabeled data to pre-train a model, after which the model is fine-tuned on limited labeled data for dermatological disease diagnosis. However, simply combining CL with FL as federated contrastive learning (FCL) will result in ineffective learning since CL requires diverse data for learning but each device only has limited data. In this work, we propose an on-device FCL framework for dermatological disease diagnosis with limited labels. Features are shared in the FCL pre-training process to provide diverse and accurate contrastive information. After that, the pre-trained model is fine-tuned with local labeled data independently on each device or collaboratively with supervised federated learning on all devices. Experiments on dermatological disease datasets show that the proposed framework effectively improves the recall and precision of dermatological disease diagnosis compared with state-of-the-art methods.
Distributed Unsupervised Visual Representation Learning with Fused Features
Nov 21, 2021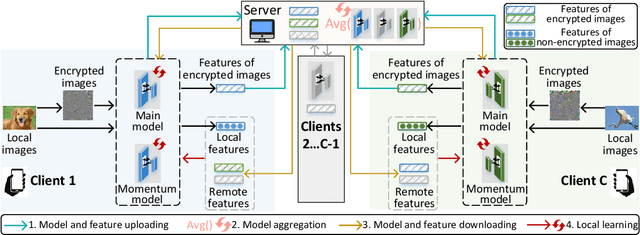
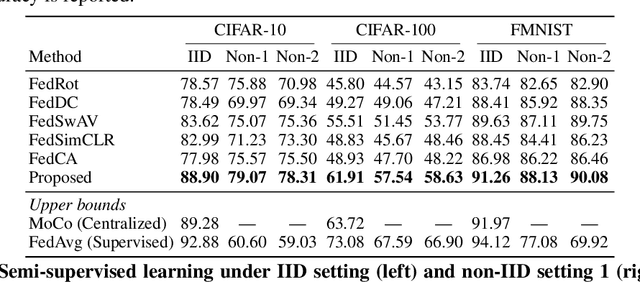
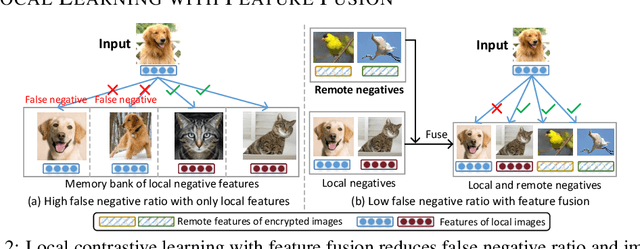
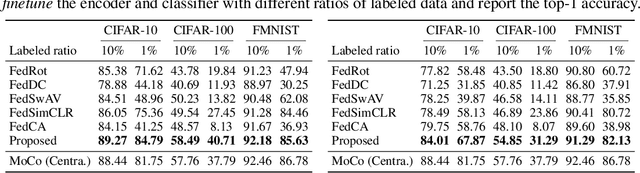
Federated learning (FL) enables distributed clients to learn a shared model for prediction while keeping the training data local on each client. However, existing FL requires fully-labeled data for training, which is inconvenient or sometimes infeasible to obtain due to the high labeling cost and the requirement of expertise. The lack of labels makes FL impractical in many realistic settings. Self-supervised learning can address this challenge by learning from unlabeled data such that FL can be widely used. Contrastive learning (CL), a self-supervised learning approach, can effectively learn data representations from unlabeled data. However, the distributed data collected on clients are usually not independent and identically distributed (non-IID) among clients, and each client may only have few classes of data, which degrades the performance of CL and learned representations. To tackle this problem, we propose a federated contrastive learning framework consisting of two approaches: feature fusion and neighborhood matching, by which a unified feature space among clients is learned for better data representations. Feature fusion provides remote features as accurate contrastive information to each client for better local learning. Neighborhood matching further aligns each client's local features to the remote features such that well-clustered features among clients can be learned. Extensive experiments show the effectiveness of the proposed framework. It outperforms other methods by 11\% on IID data and matches the performance of centralized learning.
Hardware-aware Real-time Myocardial Segmentation Quality Control in Contrast Echocardiography
Sep 14, 2021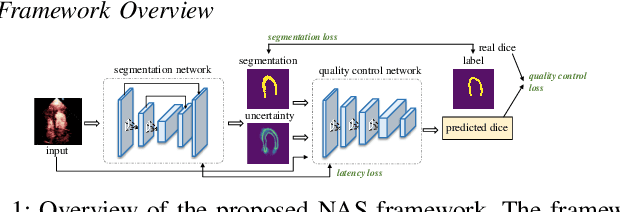
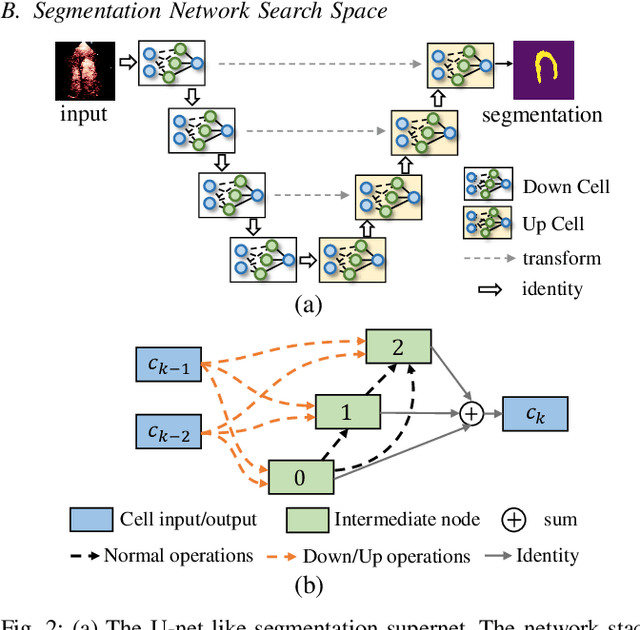
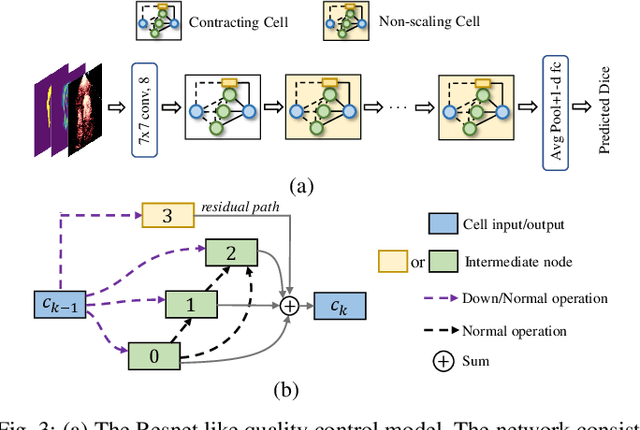
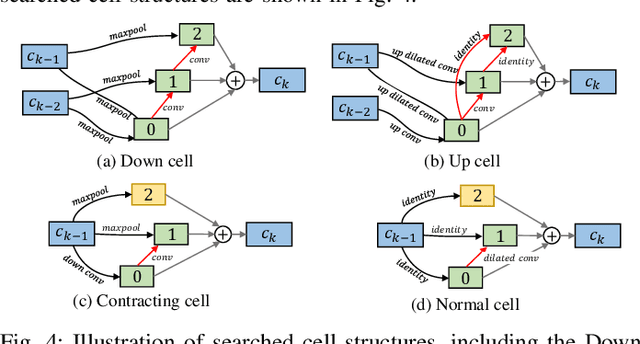
Automatic myocardial segmentation of contrast echocardiography has shown great potential in the quantification of myocardial perfusion parameters. Segmentation quality control is an important step to ensure the accuracy of segmentation results for quality research as well as its clinical application. Usually, the segmentation quality control happens after the data acquisition. At the data acquisition time, the operator could not know the quality of the segmentation results. On-the-fly segmentation quality control could help the operator to adjust the ultrasound probe or retake data if the quality is unsatisfied, which can greatly reduce the effort of time-consuming manual correction. However, it is infeasible to deploy state-of-the-art DNN-based models because the segmentation module and quality control module must fit in the limited hardware resource on the ultrasound machine while satisfying strict latency constraints. In this paper, we propose a hardware-aware neural architecture search framework for automatic myocardial segmentation and quality control of contrast echocardiography. We explicitly incorporate the hardware latency as a regularization term into the loss function during training. The proposed method searches the best neural network architecture for the segmentation module and quality prediction module with strict latency.
Positional Contrastive Learning for Volumetric Medical Image Segmentation
Jun 18, 2021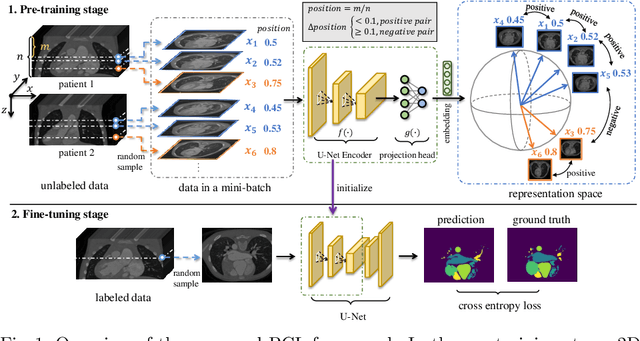
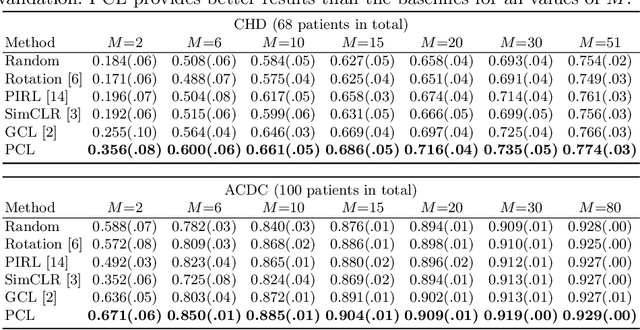
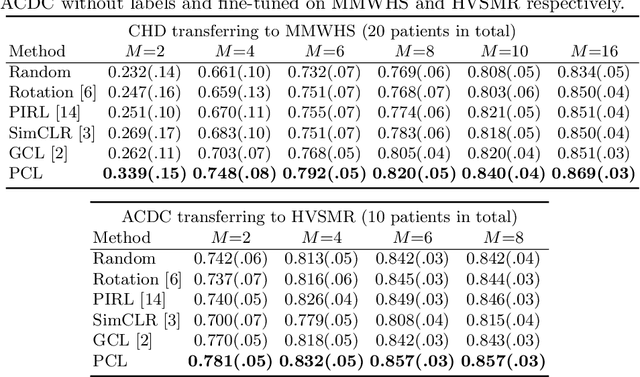
The success of deep learning heavily depends on the availability of large labeled training sets. However, it is hard to get large labeled datasets in medical image domain because of the strict privacy concern and costly labeling efforts. Contrastive learning, an unsupervised learning technique, has been proved powerful in learning image-level representations from unlabeled data. The learned encoder can then be transferred or fine-tuned to improve the performance of downstream tasks with limited labels. A critical step in contrastive learning is the generation of contrastive data pairs, which is relatively simple for natural image classification but quite challenging for medical image segmentation due to the existence of the same tissue or organ across the dataset. As a result, when applied to medical image segmentation, most state-of-the-art contrastive learning frameworks inevitably introduce a lot of false-negative pairs and result in degraded segmentation quality. To address this issue, we propose a novel positional contrastive learning (PCL) framework to generate contrastive data pairs by leveraging the position information in volumetric medical images. Experimental results on CT and MRI datasets demonstrate that the proposed PCL method can substantially improve the segmentation performance compared to existing methods in both semi-supervised setting and transfer learning setting.
Enabling On-Device Self-Supervised Contrastive Learning With Selective Data Contrast
Jun 07, 2021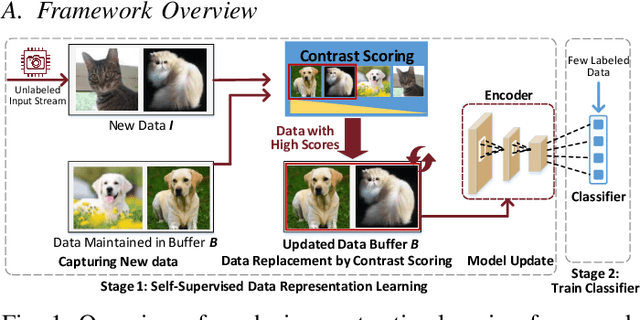
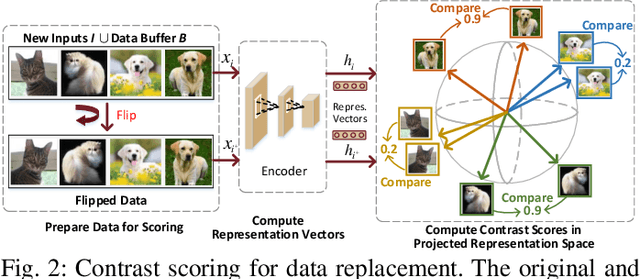
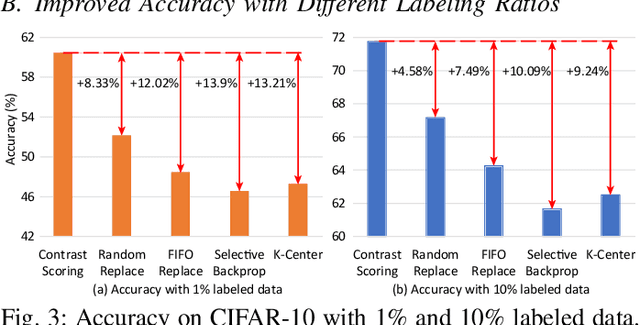
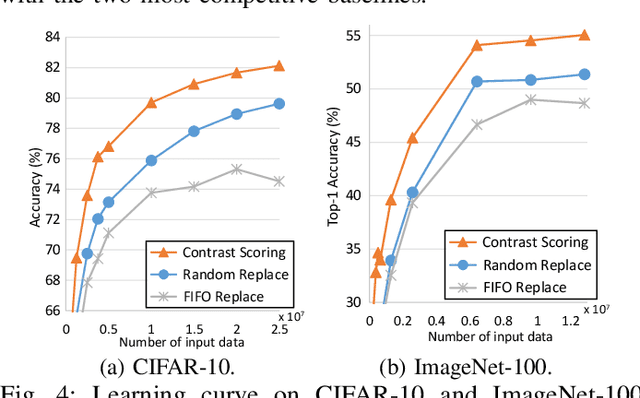
After a model is deployed on edge devices, it is desirable for these devices to learn from unlabeled data to continuously improve accuracy. Contrastive learning has demonstrated its great potential in learning from unlabeled data. However, the online input data are usually none independent and identically distributed (non-iid) and storages of edge devices are usually too limited to store enough representative data from different data classes. We propose a framework to automatically select the most representative data from the unlabeled input stream, which only requires a small data buffer for dynamic learning. Experiments show that accuracy and learning speed are greatly improved.
Personalized Deep Learning for Ventricular Arrhythmias Detection on Medical IoT Systems
Aug 18, 2020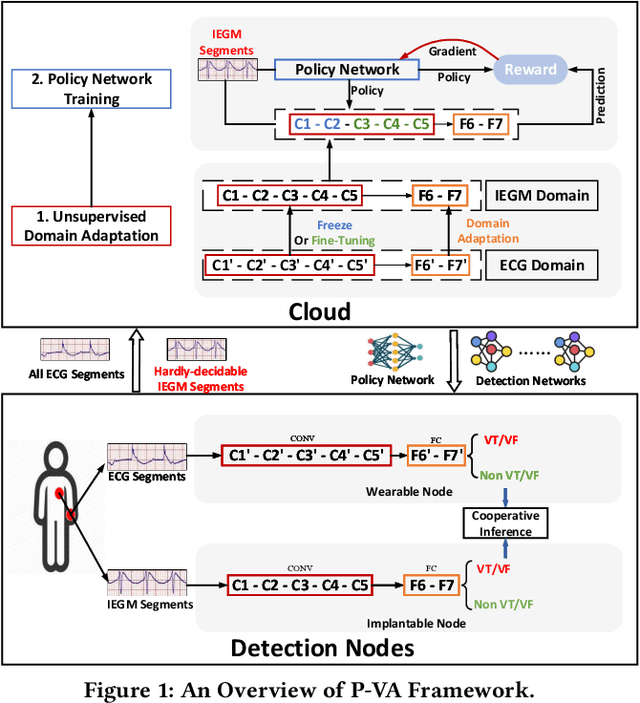
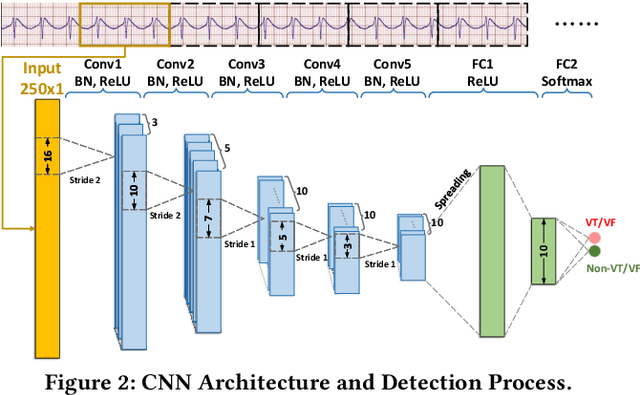
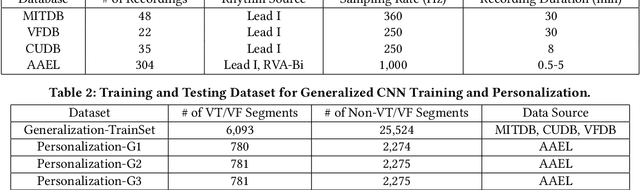
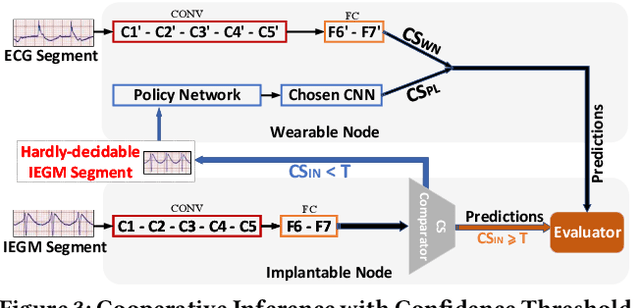
Life-threatening ventricular arrhythmias (VA) are the leading cause of sudden cardiac death (SCD), which is the most significant cause of natural death in the US. The implantable cardioverter defibrillator (ICD) is a small device implanted to patients under high risk of SCD as a preventive treatment. The ICD continuously monitors the intracardiac rhythm and delivers shock when detecting the life-threatening VA. Traditional methods detect VA by setting criteria on the detected rhythm. However, those methods suffer from a high inappropriate shock rate and require a regular follow-up to optimize criteria parameters for each ICD recipient. To ameliorate the challenges, we propose the personalized computing framework for deep learning based VA detection on medical IoT systems. The system consists of intracardiac and surface rhythm monitors, and the cloud platform for data uploading, diagnosis, and CNN model personalization. We equip the system with real-time inference on both intracardiac and surface rhythm monitors. To improve the detection accuracy, we enable the monitors to detect VA collaboratively by proposing the cooperative inference. We also introduce the CNN personalization for each patient based on the computing framework to tackle the unlabeled and limited rhythm data problem. When compared with the traditional detection algorithm, the proposed method achieves comparable accuracy on VA rhythm detection and 6.6% reduction in inappropriate shock rate, while the average inference latency is kept at 71ms.
Towards Cardiac Intervention Assistance: Hardware-aware Neural Architecture Exploration for Real-Time 3D Cardiac Cine MRI Segmentation
Aug 17, 2020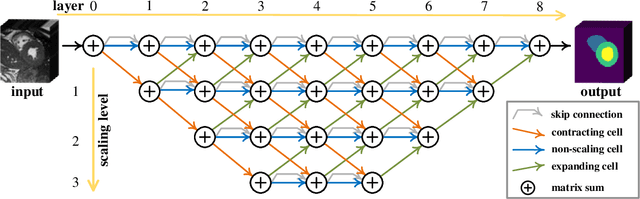
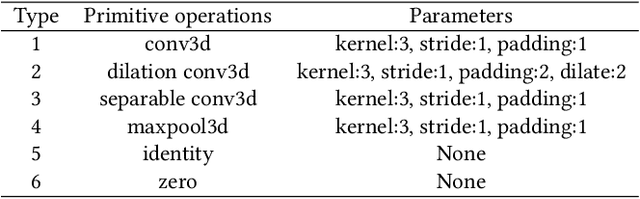
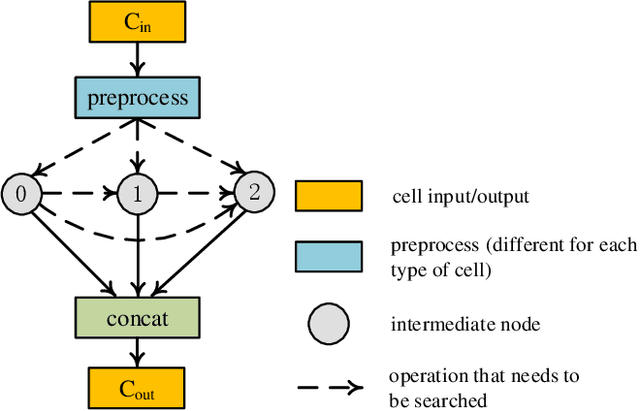
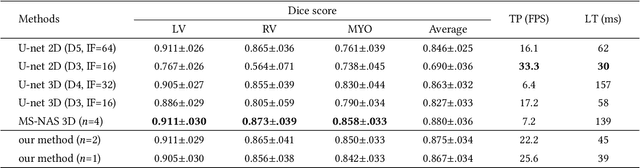
Real-time cardiac magnetic resonance imaging (MRI) plays an increasingly important role in guiding various cardiac interventions. In order to provide better visual assistance, the cine MRI frames need to be segmented on-the-fly to avoid noticeable visual lag. In addition, considering reliability and patient data privacy, the computation is preferably done on local hardware. State-of-the-art MRI segmentation methods mostly focus on accuracy only, and can hardly be adopted for real-time application or on local hardware. In this work, we present the first hardware-aware multi-scale neural architecture search (NAS) framework for real-time 3D cardiac cine MRI segmentation. The proposed framework incorporates a latency regularization term into the loss function to handle real-time constraints, with the consideration of underlying hardware. In addition, the formulation is fully differentiable with respect to the architecture parameters, so that stochastic gradient descent (SGD) can be used for optimization to reduce the computation cost while maintaining optimization quality. Experimental results on ACDC MICCAI 2017 dataset demonstrate that our hardware-aware multi-scale NAS framework can reduce the latency by up to 3.5 times and satisfy the real-time constraints, while still achieving competitive segmentation accuracy, compared with the state-of-the-art NAS segmentation framework.
Standing on the Shoulders of Giants: Hardware and Neural Architecture Co-Search with Hot Start
Jul 17, 2020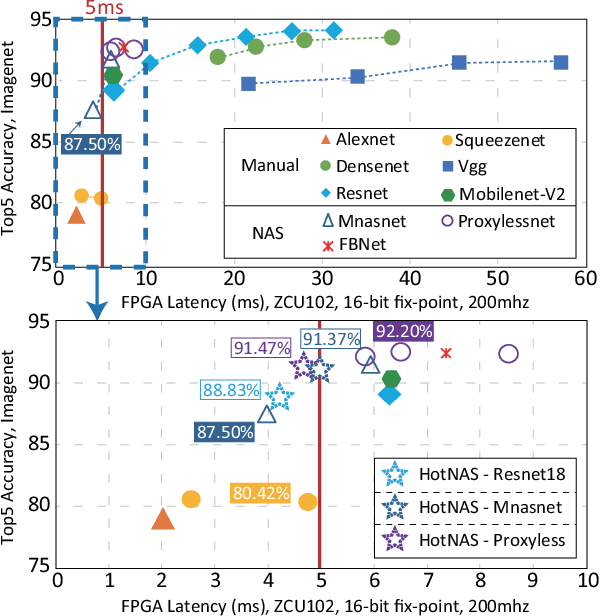
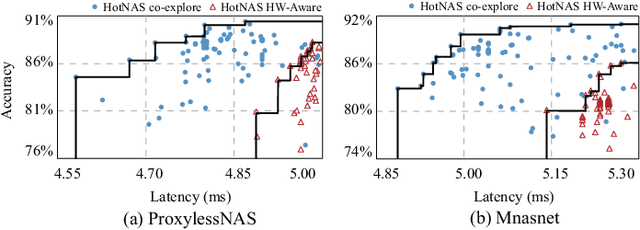
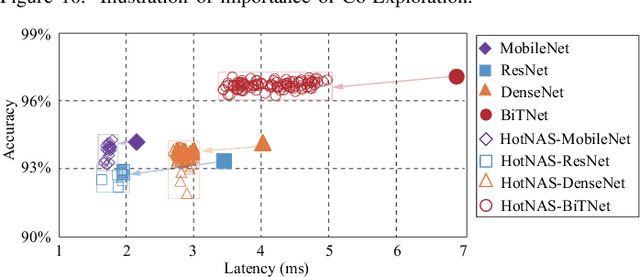
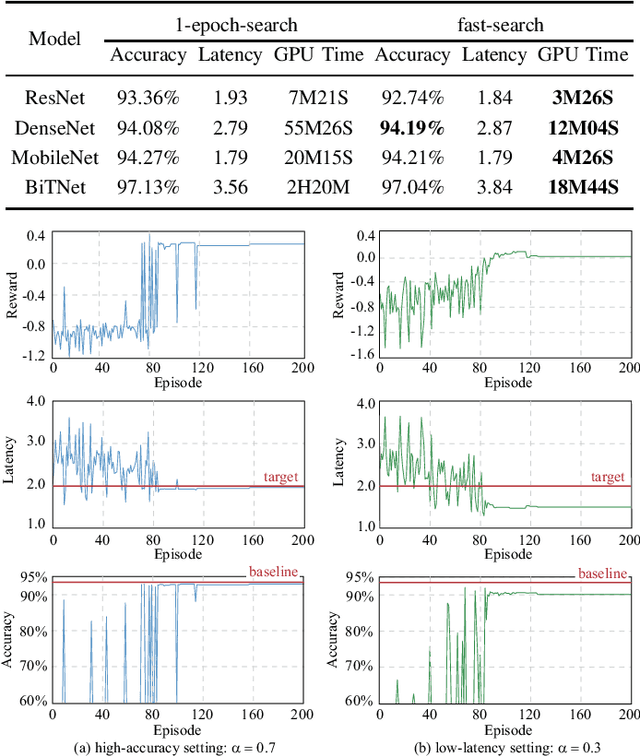
Hardware and neural architecture co-search that automatically generates Artificial Intelligence (AI) solutions from a given dataset is promising to promote AI democratization; however, the amount of time that is required by current co-search frameworks is in the order of hundreds of GPU hours for one target hardware. This inhibits the use of such frameworks on commodity hardware. The root cause of the low efficiency in existing co-search frameworks is the fact that they start from a "cold" state (i.e., search from scratch). In this paper, we propose a novel framework, namely HotNAS, that starts from a "hot" state based on a set of existing pre-trained models (a.k.a. model zoo) to avoid lengthy training time. As such, the search time can be reduced from 200 GPU hours to less than 3 GPU hours. In HotNAS, in addition to hardware design space and neural architecture search space, we further integrate a compression space to conduct model compressing during the co-search, which creates new opportunities to reduce latency but also brings challenges. One of the key challenges is that all of the above search spaces are coupled with each other, e.g., compression may not work without hardware design support. To tackle this issue, HotNAS builds a chain of tools to design hardware to support compression, based on which a global optimizer is developed to automatically co-search all the involved search spaces. Experiments on ImageNet dataset and Xilinx FPGA show that, within the timing constraint of 5ms, neural architectures generated by HotNAS can achieve up to 5.79% Top-1 and 3.97% Top-5 accuracy gain, compared with the existing ones.