 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Open-vocabulary Scene Graph Generation with Prompt-based Finetuning
Aug 17, 2022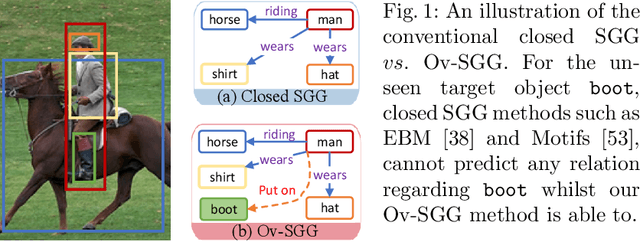
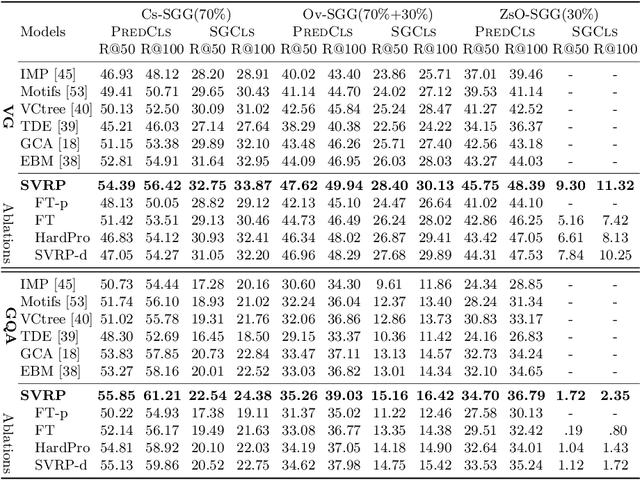
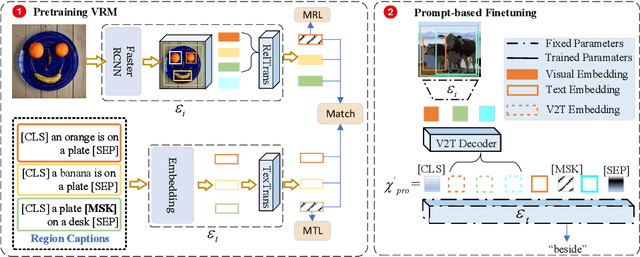
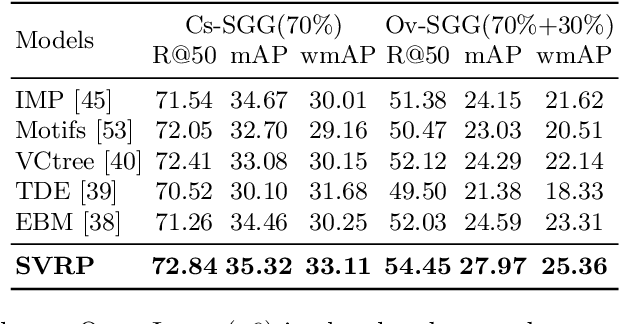
Scene graph generation (SGG) is a fundamental task aimed at detecting visual relations between objects in an image. The prevailing SGG methods require all object classes to be given in the training set. Such a closed setting limits the practical application of SGG. In this paper, we introduce open-vocabulary scene graph generation, a novel, realistic and challenging setting in which a model is trained on a set of base object classes but is required to infer relations for unseen target object classes. To this end, we propose a two-step method that firstly pre-trains on large amounts of coarse-grained region-caption data and then leverages two prompt-based techniques to finetune the pre-trained model without updating its parameters. Moreover, our method can support inference over completely unseen object classes, which existing methods are incapable of handling. On extensive experiments on three benchmark datasets, Visual Genome, GQA, and Open-Image, our method significantly outperforms recent, strong SGG methods on the setting of Ov-SGG, as well as on the conventional closed SGG.
Prompting for Multi-Modal Tracking
Aug 01, 2022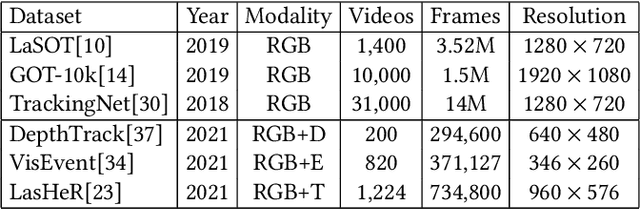
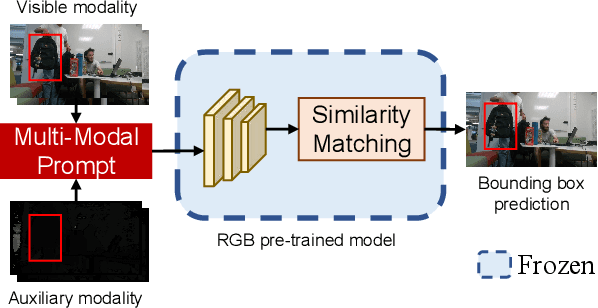
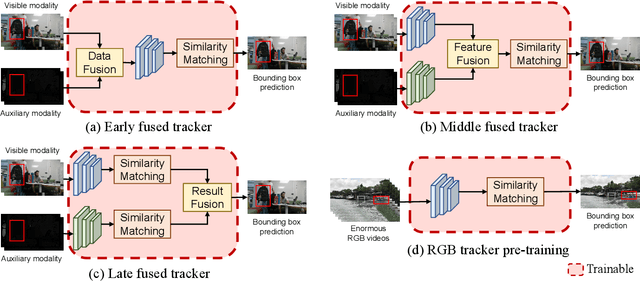
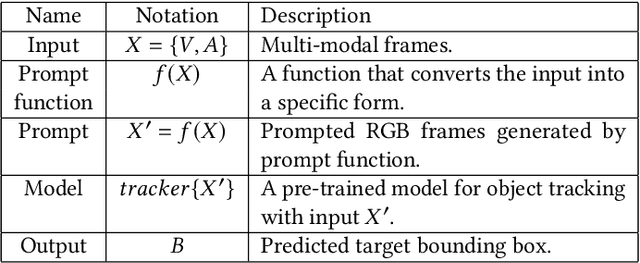
Multi-modal tracking gains attention due to its ability to be more accurate and robust in complex scenarios compared to traditional RGB-based tracking. Its key lies in how to fuse multi-modal data and reduce the gap between modalities. However, multi-modal tracking still severely suffers from data deficiency, thus resulting in the insufficient learning of fusion modules. Instead of building such a fusion module, in this paper, we provide a new perspective on multi-modal tracking by attaching importance to the multi-modal visual prompts. We design a novel multi-modal prompt tracker (ProTrack), which can transfer the multi-modal inputs to a single modality by the prompt paradigm. By best employing the tracking ability of pre-trained RGB trackers learning at scale, our ProTrack can achieve high-performance multi-modal tracking by only altering the inputs, even without any extra training on multi-modal data. Extensive experiments on 5 benchmark datasets demonstrate the effectiveness of the proposed ProTrack.
Frequency Domain Model Augmentation for Adversarial Attack
Jul 12, 2022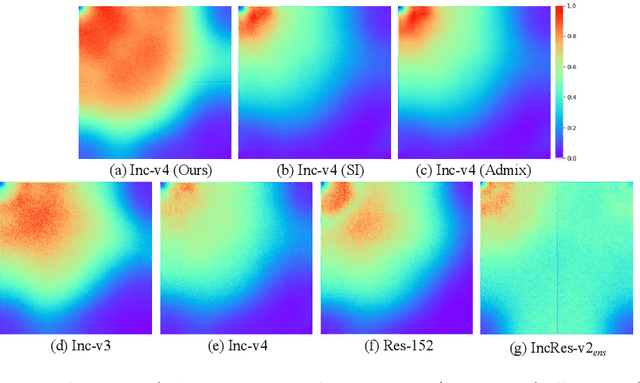
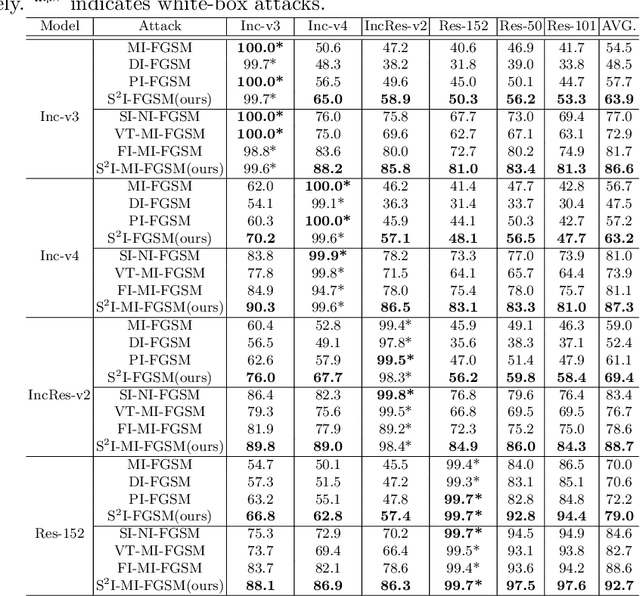
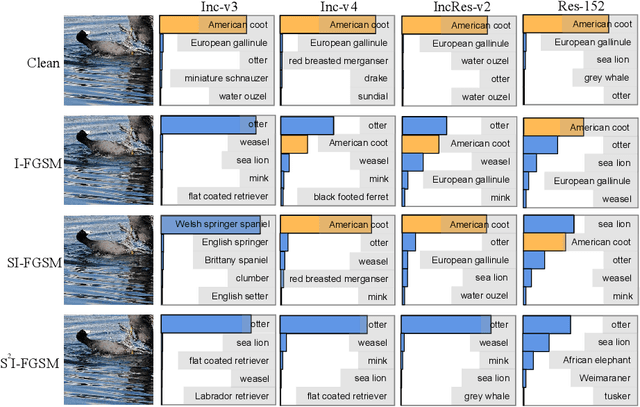
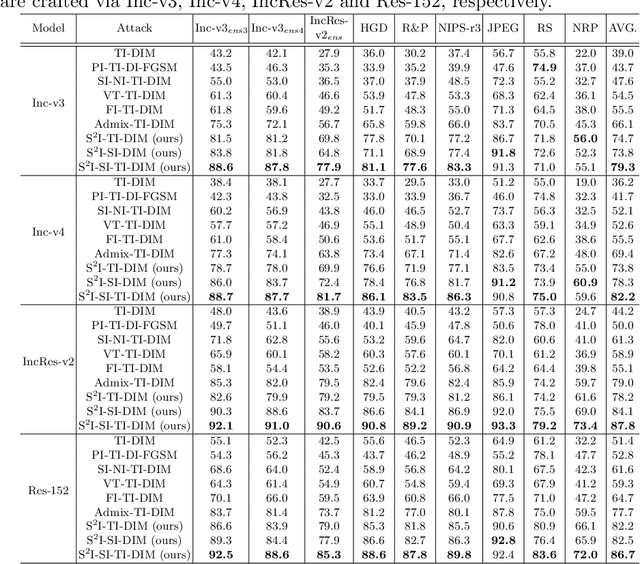
For black-box attacks, the gap between the substitute model and the victim model is usually large, which manifests as a weak attack performance. Motivated by the observation that the transferability of adversarial examples can be improved by attacking diverse models simultaneously, model augmentation methods which simulate different models by using transformed images are proposed. However, existing transformations for spatial domain do not translate to significantly diverse augmented models. To tackle this issue, we propose a novel spectrum simulation attack to craft more transferable adversarial examples against both normally trained and defense models. Specifically, we apply a spectrum transformation to the input and thus perform the model augmentation in the frequency domain. We theoretically prove that the transformation derived from frequency domain leads to a diverse spectrum saliency map, an indicator we proposed to reflect the diversity of substitute models. Notably, our method can be generally combined with existing attacks. Extensive experiments on the ImageNet dataset demonstrate the effectiveness of our method, \textit{e.g.}, attacking nine state-of-the-art defense models with an average success rate of \textbf{95.4\%}. Our code is available in \url{https://github.com/yuyang-long/SSA}.
Adaptive Fine-Grained Predicates Learning for Scene Graph Generation
Jul 11, 2022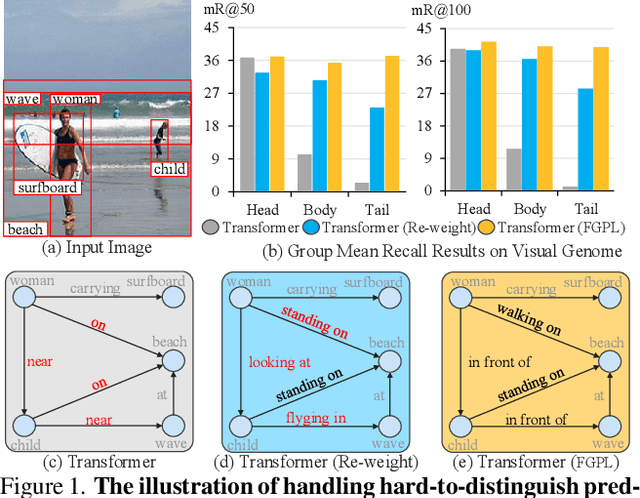
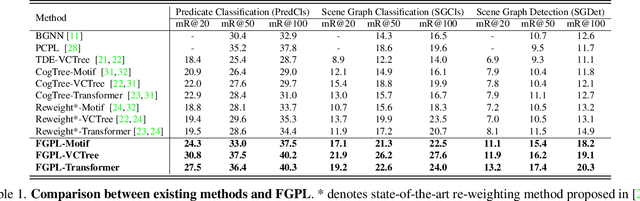
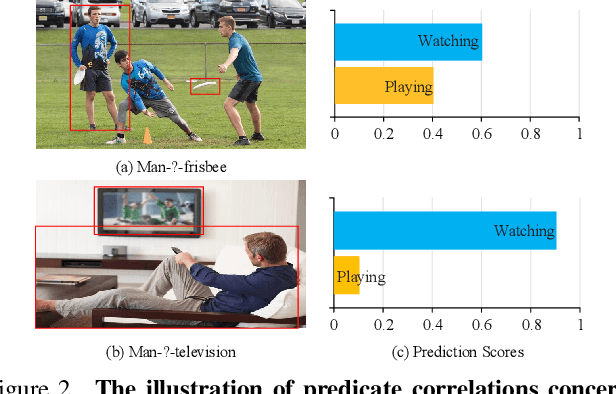
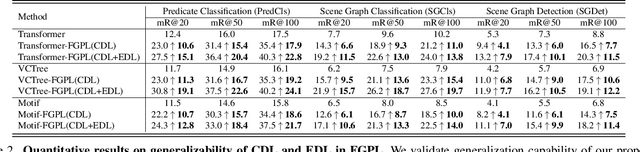
The performance of current Scene Graph Generation (SGG) models is severely hampered by hard-to-distinguish predicates, e.g., woman-on/standing on/walking on-beach. As general SGG models tend to predict head predicates and re-balancing strategies prefer tail categories, none of them can appropriately handle hard-to-distinguish predicates. To tackle this issue, inspired by fine-grained image classification, which focuses on differentiating hard-to-distinguish objects, we propose an Adaptive Fine-Grained Predicates Learning (FGPL-A) which aims at differentiating hard-to-distinguish predicates for SGG. First, we introduce an Adaptive Predicate Lattice (PL-A) to figure out hard-to-distinguish predicates, which adaptively explores predicate correlations in keeping with model's dynamic learning pace. Practically, PL-A is initialized from SGG dataset, and gets refined by exploring model's predictions of current mini-batch. Utilizing PL-A, we propose an Adaptive Category Discriminating Loss (CDL-A) and an Adaptive Entity Discriminating Loss (EDL-A), which progressively regularize model's discriminating process with fine-grained supervision concerning model's dynamic learning status, ensuring balanced and efficient learning process. Extensive experimental results show that our proposed model-agnostic strategy significantly boosts performance of benchmark models on VG-SGG and GQA-SGG datasets by up to 175% and 76% on Mean Recall@100, achieving new state-of-the-art performance. Moreover, experiments on Sentence-to-Graph Retrieval and Image Captioning tasks further demonstrate practicability of our method.
Skeleton-based Action Recognition via Adaptive Cross-Form Learning
Jun 30, 2022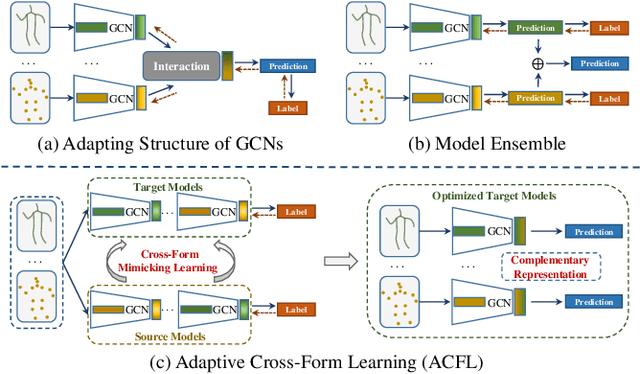
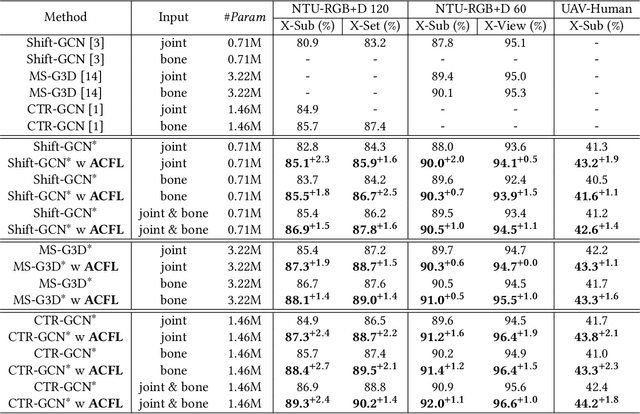
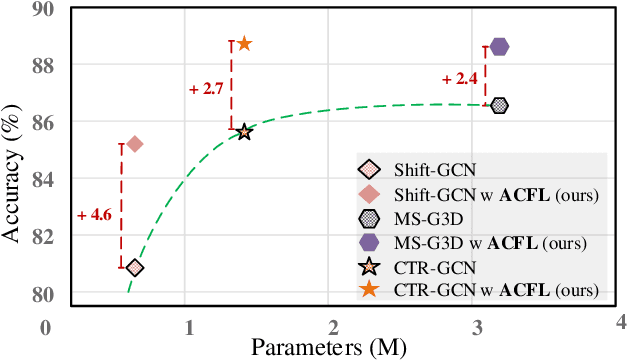
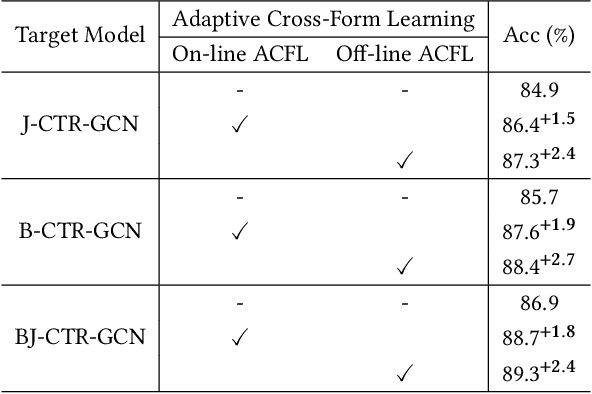
Skeleton-based action recognition aims to project skeleton sequences to action categories, where skeleton sequences are derived from multiple forms of pre-detected points. Compared with earlier methods that focus on exploring single-form skeletons via Graph Convolutional Networks (GCNs), existing methods tend to improve GCNs by leveraging multi-form skeletons due to their complementary cues. However, these methods (either adapting structure of GCNs or model ensemble) require the co-existence of all forms of skeletons during both training and inference stages, while a typical situation in real life is the existence of only partial forms for inference. To tackle this issue, we present Adaptive Cross-Form Learning (ACFL), which empowers well-designed GCNs to generate complementary representation from single-form skeletons without changing model capacity. Specifically, each GCN model in ACFL not only learns action representation from the single-form skeletons, but also adaptively mimics useful representations derived from other forms of skeletons. In this way, each GCN can learn how to strengthen what has been learned, thus exploiting model potential and facilitating action recognition as well. Extensive experiments conducted on three challenging benchmarks, i.e., NTU-RGB+D 120, NTU-RGB+D 60 and UAV-Human, demonstrate the effectiveness and generalizability of the proposed method. Specifically, the ACFL significantly improves various GCN models (i.e., CTR-GCN, MS-G3D, and Shift-GCN), achieving a new record for skeleton-based action recognition.
Learning To Generate Scene Graph from Head to Tail
Jun 23, 2022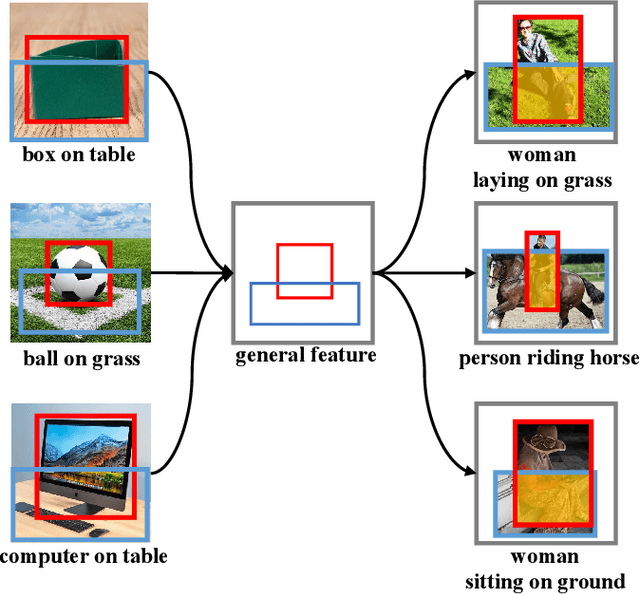
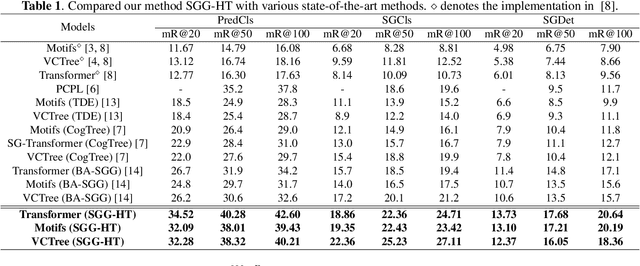
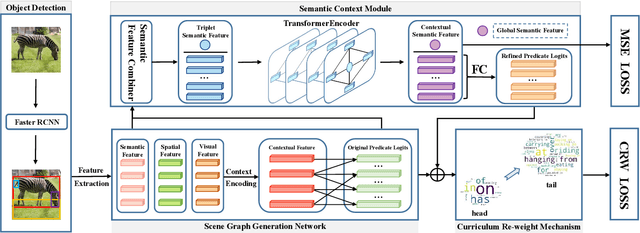
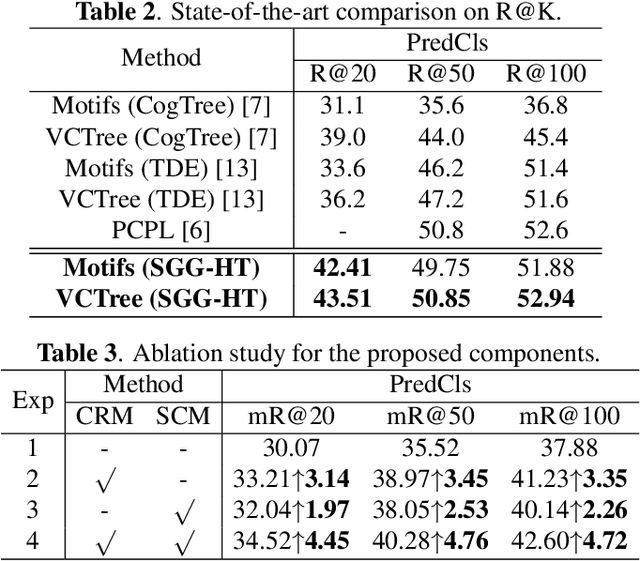
Scene Graph Generation (SGG) represents objects and their interactions with a graph structure. Recently, many works are devoted to solving the imbalanced problem in SGG. However, underestimating the head predicates in the whole training process, they wreck the features of head predicates that provide general features for tail ones. Besides, assigning excessive attention to the tail predicates leads to semantic deviation. Based on this, we propose a novel SGG framework, learning to generate scene graphs from Head to Tail (SGG-HT), containing Curriculum Re-weight Mechanism (CRM) and Semantic Context Module (SCM). CRM learns head/easy samples firstly for robust features of head predicates and then gradually focuses on tail/hard ones. SCM is proposed to relieve semantic deviation by ensuring the semantic consistency between the generated scene graph and the ground truth in global and local representations. Experiments show that SGG-HT significantly alleviates the biased problem and chieves state-of-the-art performances on Visual Genome.
KE-RCNN: Unifying Knowledge based Reasoning into Part-level Attribute Parsing
Jun 21, 2022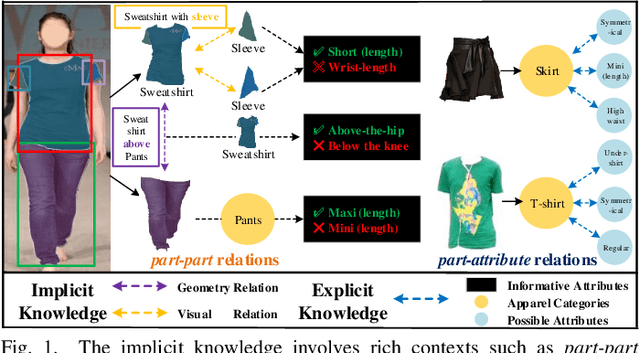
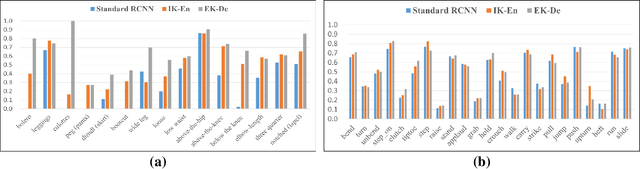
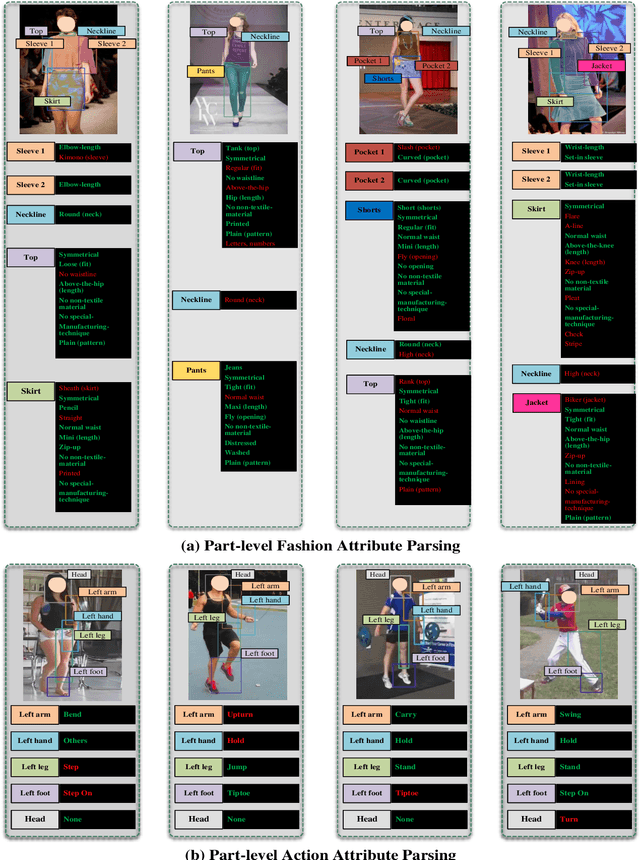
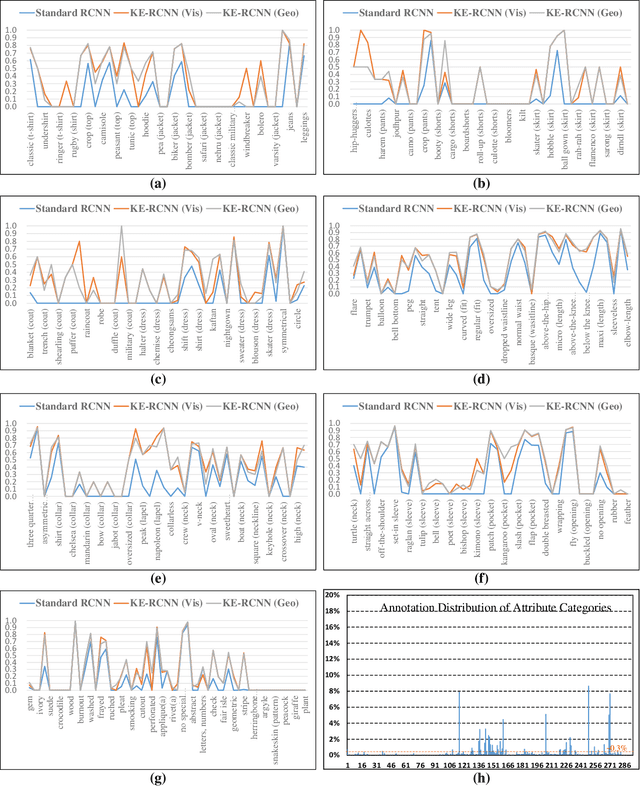
Part-level attribute parsing is a fundamental but challenging task, which requires the region-level visual understanding to provide explainable details of body parts. Most existing approaches address this problem by adding a regional convolutional neural network (RCNN) with an attribute prediction head to a two-stage detector, in which attributes of body parts are identified from local-wise part boxes. However, local-wise part boxes with limit visual clues (i.e., part appearance only) lead to unsatisfying parsing results, since attributes of body parts are highly dependent on comprehensive relations among them. In this article, we propose a Knowledge Embedded RCNN (KE-RCNN) to identify attributes by leveraging rich knowledges, including implicit knowledge (e.g., the attribute ``above-the-hip'' for a shirt requires visual/geometry relations of shirt-hip) and explicit knowledge (e.g., the part of ``shorts'' cannot have the attribute of ``hoodie'' or ``lining''). Specifically, the KE-RCNN consists of two novel components, i.e., Implicit Knowledge based Encoder (IK-En) and Explicit Knowledge based Decoder (EK-De). The former is designed to enhance part-level representation by encoding part-part relational contexts into part boxes, and the latter one is proposed to decode attributes with a guidance of prior knowledge about \textit{part-attribute} relations. In this way, the KE-RCNN is plug-and-play, which can be integrated into any two-stage detectors, e.g., Attribute-RCNN, Cascade-RCNN, HRNet based RCNN and SwinTransformer based RCNN. Extensive experiments conducted on two challenging benchmarks, e.g., Fashionpedia and Kinetics-TPS, demonstrate the effectiveness and generalizability of the KE-RCNN. In particular, it achieves higher improvements over all existing methods, reaching around 3% of AP on Fashionpedia and around 4% of Acc on Kinetics-TPS.
KTN: Knowledge Transfer Network for Learning Multi-person 2D-3D Correspondences
Jun 21, 2022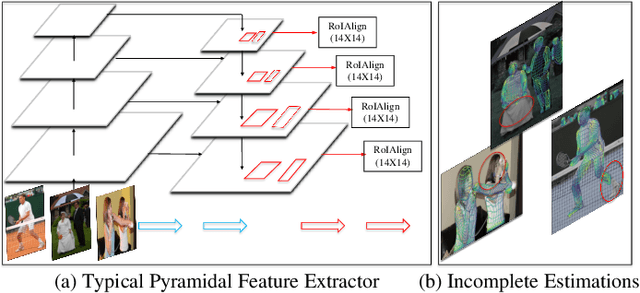
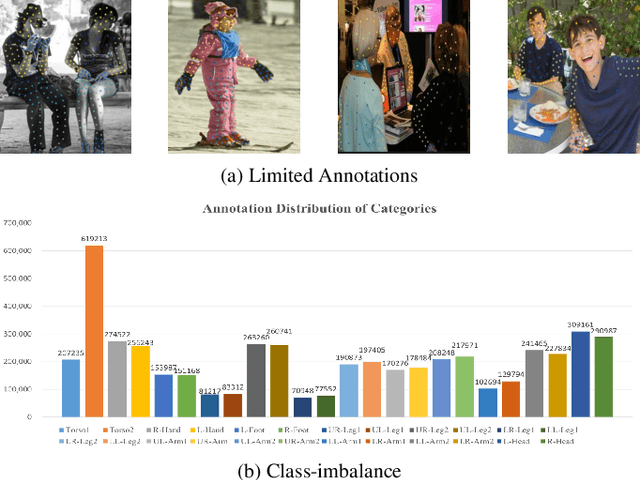
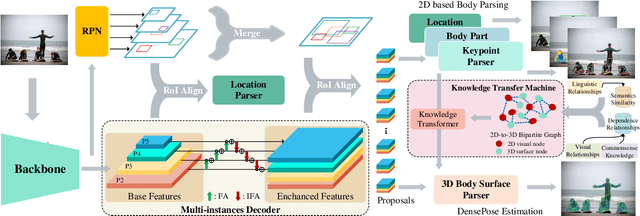
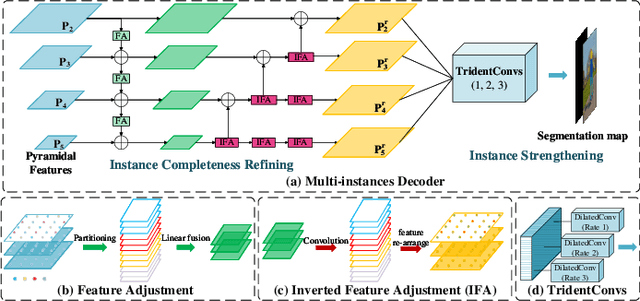
Human densepose estimation, aiming at establishing dense correspondences between 2D pixels of human body and 3D human body template, is a key technique in enabling machines to have an understanding of people in images. It still poses several challenges due to practical scenarios where real-world scenes are complex and only partial annotations are available, leading to incompelete or false estimations. In this work, we present a novel framework to detect the densepose of multiple people in an image. The proposed method, which we refer to Knowledge Transfer Network (KTN), tackles two main problems: 1) how to refine image representation for alleviating incomplete estimations, and 2) how to reduce false estimation caused by the low-quality training labels (i.e., limited annotations and class-imbalance labels). Unlike existing works directly propagating the pyramidal features of regions for densepose estimation, the KTN uses a refinement of pyramidal representation, where it simultaneously maintains feature resolution and suppresses background pixels, and this strategy results in a substantial increase in accuracy. Moreover, the KTN enhances the ability of 3D based body parsing with external knowledges, where it casts 2D based body parsers trained from sufficient annotations as a 3D based body parser through a structural body knowledge graph. In this way, it significantly reduces the adverse effects caused by the low-quality annotations. The effectiveness of KTN is demonstrated by its superior performance to the state-of-the-art methods on DensePose-COCO dataset. Extensive ablation studies and experimental results on representative tasks (e.g., human body segmentation, human part segmentation and keypoints detection) and two popular densepose estimation pipelines (i.e., RCNN and fully-convolutional frameworks), further indicate the generalizability of the proposed method.
From Pixels to Objects: Cubic Visual Attention for Visual Question Answering
Jun 04, 2022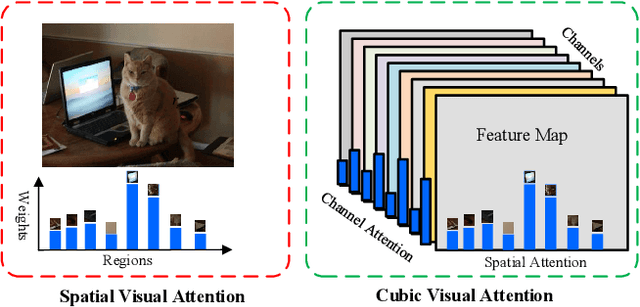
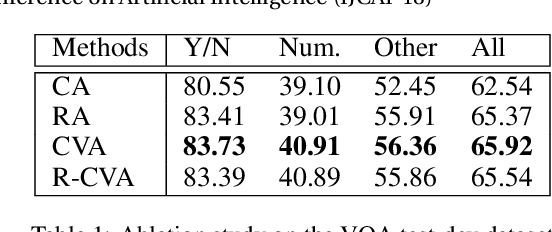
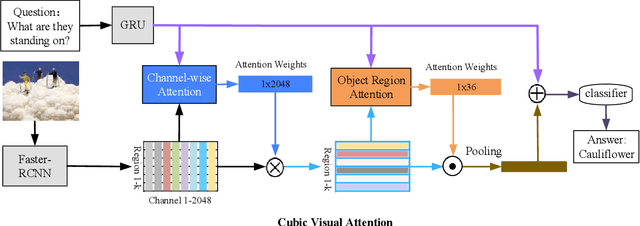
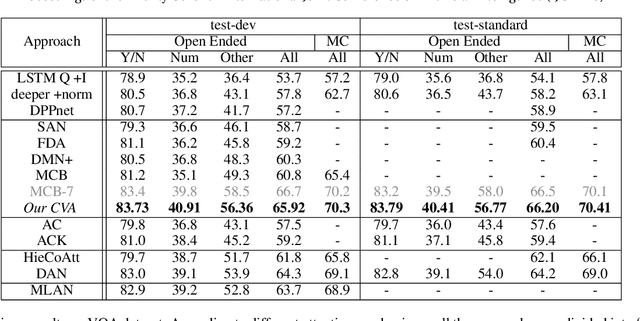
Recently, attention-based Visual Question Answering (VQA) has achieved great success by utilizing question to selectively target different visual areas that are related to the answer. Existing visual attention models are generally planar, i.e., different channels of the last conv-layer feature map of an image share the same weight. This conflicts with the attention mechanism because CNN features are naturally spatial and channel-wise. Also, visual attention models are usually conducted on pixel-level, which may cause region discontinuous problems. In this paper, we propose a Cubic Visual Attention (CVA) model by successfully applying a novel channel and spatial attention on object regions to improve VQA task. Specifically, instead of attending to pixels, we first take advantage of the object proposal networks to generate a set of object candidates and extract their associated conv features. Then, we utilize the question to guide channel attention and spatial attention calculation based on the con-layer feature map. Finally, the attended visual features and the question are combined to infer the answer. We assess the performance of our proposed CVA on three public image QA datasets, including COCO-QA, VQA and Visual7W. Experimental results show that our proposed method significantly outperforms the state-of-the-arts.
Structured Two-stream Attention Network for Video Question Answering
Jun 02, 2022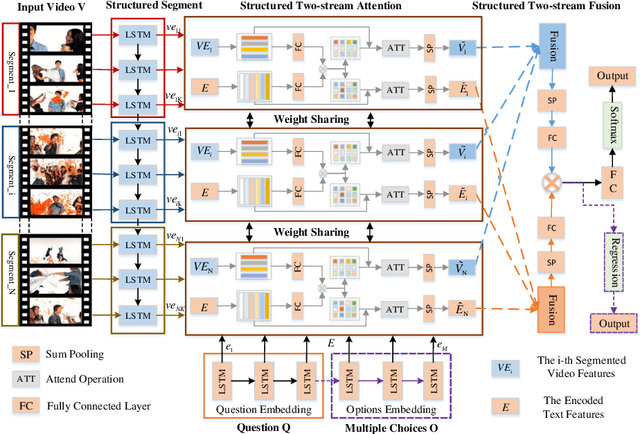
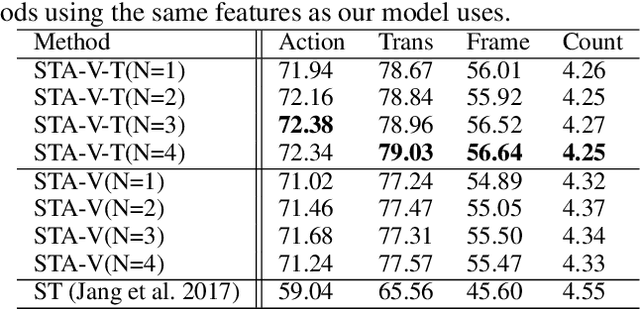

To date, visual question answering (VQA) (i.e., image QA and video QA) is still a holy grail in vision and language understanding, especially for video QA. Compared with image QA that focuses primarily on understanding the associations between image region-level details and corresponding questions, video QA requires a model to jointly reason across both spatial and long-range temporal structures of a video as well as text to provide an accurate answer. In this paper, we specifically tackle the problem of video QA by proposing a Structured Two-stream Attention network, namely STA, to answer a free-form or open-ended natural language question about the content of a given video. First, we infer rich long-range temporal structures in videos using our structured segment component and encode text features. Then, our structured two-stream attention component simultaneously localizes important visual instance, reduces the influence of background video and focuses on the relevant text. Finally, the structured two-stream fusion component incorporates different segments of query and video aware context representation and infers the answers. Experiments on the large-scale video QA dataset \textit{TGIF-QA} show that our proposed method significantly surpasses the best counterpart (i.e., with one representation for the video input) by 13.0%, 13.5%, 11.0% and 0.3 for Action, Trans., TrameQA and Count tasks. It also outperforms the best competitor (i.e., with two representations) on the Action, Trans., TrameQA tasks by 4.1%, 4.7%, and 5.1%.