 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLego-MT: Towards Detachable Models in Massively Multilingual Machine Translation
Dec 20, 2022Traditional multilingual neural machine translation (MNMT) uses a single model to translate all directions. However, with the increasing scale of language pairs, simply using a single model for massive MNMT brings new challenges: parameter tension and large computations. In this paper, we revisit multi-way structures by assigning an individual branch for each language (group). Despite being a simple architecture, it is challenging to train de-centralized models due to the lack of constraints to align representations from all languages. We propose a localized training recipe to map different branches into a unified space, resulting in an efficient detachable model, Lego-MT. For a fair comparison, we collect data from OPUS and build the first large-scale open-source translation benchmark covering 7 language-centric data, each containing 445 language pairs. Experiments show that Lego-MT (1.2B) brings gains of more than 4 BLEU while outperforming M2M-100 (12B) (We will public all training data, models, and checkpoints)
Go-tuning: Improving Zero-shot Learning Abilities of Smaller Language Models
Dec 20, 2022



With increasing scale, large language models demonstrate both quantitative improvement and new qualitative capabilities, especially as zero-shot learners, like GPT-3. However, these results rely heavily on delicate prompt design and large computation. In this work, we explore whether the strong zero-shot ability could be achieved at a smaller model scale without any external supervised data. To achieve this goal, we revisit masked language modeling and present a geometry-guided self-supervised learning method (Go-tuningfor short) by taking a small number of task-aware self-supervised data to update language models further. Experiments show that Go-tuning can enable T5-small (80M) competitive zero-shot results compared with large language models, such as T5-XL (3B). We also apply Go-tuning on multi-task settings and develop a multi-task model, mgo-T5 (250M). It can reach the average performance of OPT (175B) on 9 datasets.
BigText-QA: Question Answering over a Large-Scale Hybrid Knowledge Graph
Dec 12, 2022Answering complex questions over textual resources remains a challenging problem$\unicode{x2013}$especially when interpreting the fine-grained relationships among multiple entities that occur within a natural-language question or clue. Curated knowledge bases (KBs), such as YAGO, DBpedia, Freebase and Wikidata, have been widely used in this context and gained great acceptance for question-answering (QA) applications in the past decade. While current KBs offer a concise representation of structured knowledge, they lack the variety of formulations and semantic nuances as well as the context of information provided by the natural-language sources. With BigText-QA, we aim to develop an integrated QA system which is able to answer questions based on a more redundant form of a knowledge graph (KG) that organizes both structured and unstructured (i.e., "hybrid") knowledge in a unified graphical representation. BigText-QA thereby is able to combine the best of both worlds$\unicode{x2013}$a canonical set of named entities, mapped to a structured background KB (such as YAGO or Wikidata), as well as an open set of textual clauses providing highly diversified relational paraphrases with rich context information.
Enhancing and Adversarial: Improve ASR with Speaker Labels
Nov 11, 2022



ASR can be improved by multi-task learning (MTL) with domain enhancing or domain adversarial training, which are two opposite objectives with the aim to increase/decrease domain variance towards domain-aware/agnostic ASR, respectively. In this work, we study how to best apply these two opposite objectives with speaker labels to improve conformer-based ASR. We also propose a novel adaptive gradient reversal layer for stable and effective adversarial training without tuning effort. Detailed analysis and experimental verification are conducted to show the optimal positions in the ASR neural network (NN) to apply speaker enhancing and adversarial training. We also explore their combination for further improvement, achieving the same performance as i-vectors plus adversarial training. Our best speaker-based MTL achieves 7\% relative improvement on the Switchboard Hub5'00 set. We also investigate the effect of such speaker-based MTL w.r.t. cleaner dataset and weaker ASR NN.
Calibrating Factual Knowledge in Pretrained Language Models
Oct 07, 2022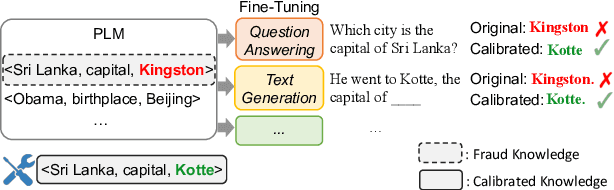
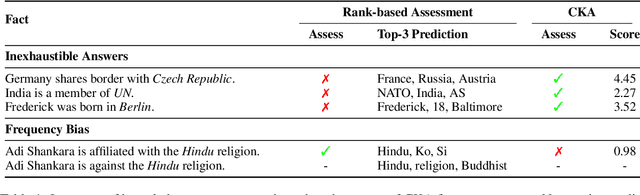


Previous literature has proved that Pretrained Language Models (PLMs) can store factual knowledge. However, we find that facts stored in the PLMs are not always correct. It motivates us to explore a fundamental question: How do we calibrate factual knowledge in PLMs without re-training from scratch? In this work, we propose a simple and lightweight method CaliNet to achieve this goal. To be specific, we first detect whether PLMs can learn the right facts via a contrastive score between right and fake facts. If not, we then use a lightweight method to add and adapt new parameters to specific factual texts. Experiments on the knowledge probing task show the calibration effectiveness and efficiency. In addition, through closed-book question answering, we find that the calibrated PLM possesses knowledge generalization ability after fine-tuning. Beyond the calibration performance, we further investigate and visualize the knowledge calibration mechanism.
Improving the Training Recipe for a Robust Conformer-based Hybrid Model
Jun 26, 2022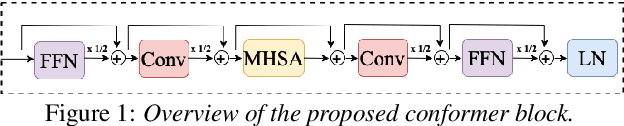
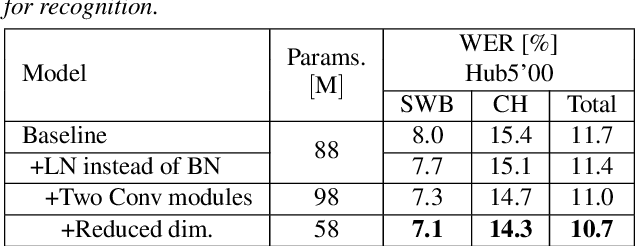
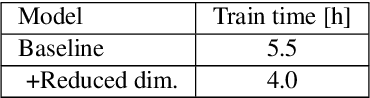
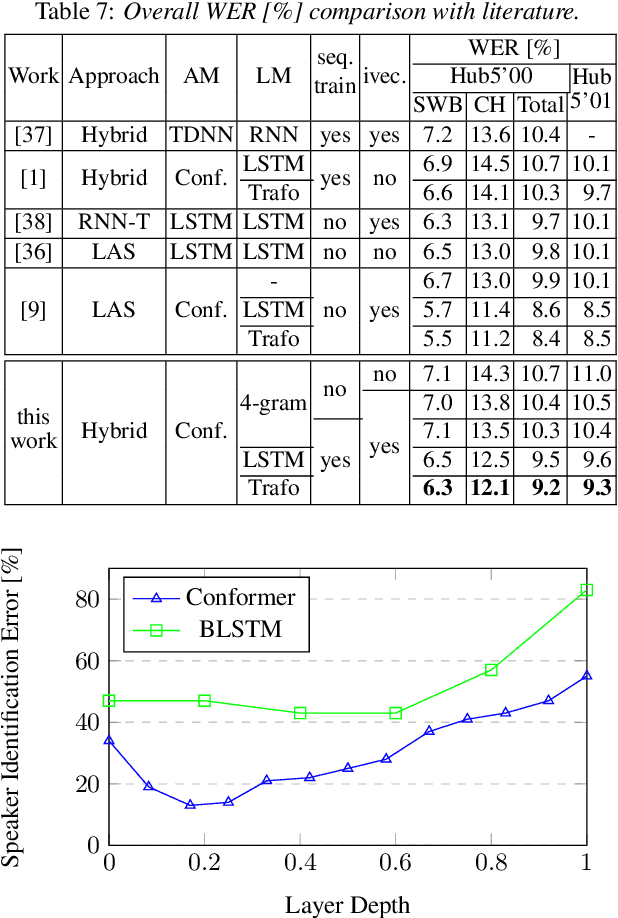
Speaker adaptation is important to build robust automatic speech recognition (ASR) systems. In this work, we investigate various methods for speaker adaptive training (SAT) based on feature-space approaches for a conformer-based acoustic model (AM) on the Switchboard 300h dataset. We propose a method, called Weighted-Simple-Add, which adds weighted speaker information vectors to the input of the multi-head self-attention module of the conformer AM. Using this method for SAT, we achieve 3.5% and 4.5% relative improvement in terms of WER on the CallHome part of Hub5'00 and Hub5'01 respectively. Moreover, we build on top of our previous work where we proposed a novel and competitive training recipe for a conformer-based hybrid AM. We extend and improve this recipe where we achieve 11% relative improvement in terms of word-error-rate (WER) on Switchboard 300h Hub5'00 dataset. We also make this recipe efficient by reducing the total number of parameters by 34% relative.
Contextual Representation Learning beyond Masked Language Modeling
Apr 08, 2022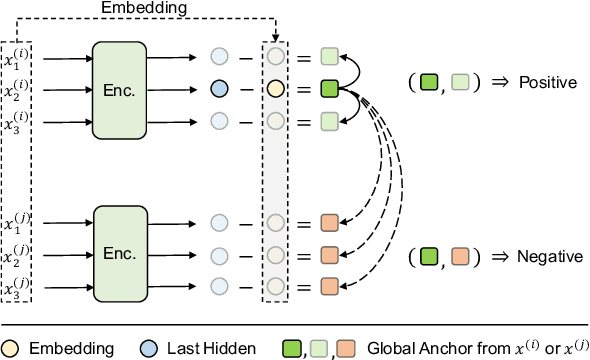

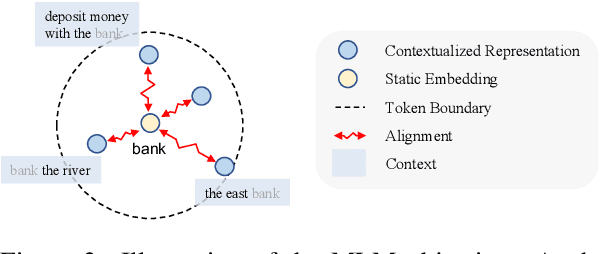
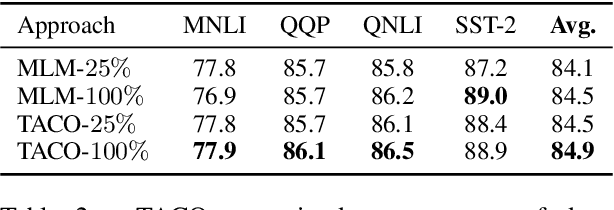
How do masked language models (MLMs) such as BERT learn contextual representations? In this work, we analyze the learning dynamics of MLMs. We find that MLMs adopt sampled embeddings as anchors to estimate and inject contextual semantics to representations, which limits the efficiency and effectiveness of MLMs. To address these issues, we propose TACO, a simple yet effective representation learning approach to directly model global semantics. TACO extracts and aligns contextual semantics hidden in contextualized representations to encourage models to attend global semantics when generating contextualized representations. Experiments on the GLUE benchmark show that TACO achieves up to 5x speedup and up to 1.2 points average improvement over existing MLMs. The code is available at https://github.com/FUZHIYI/TACO.
KNAS: Green Neural Architecture Search
Nov 26, 2021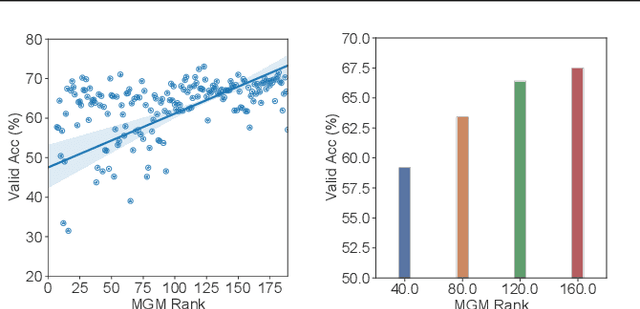
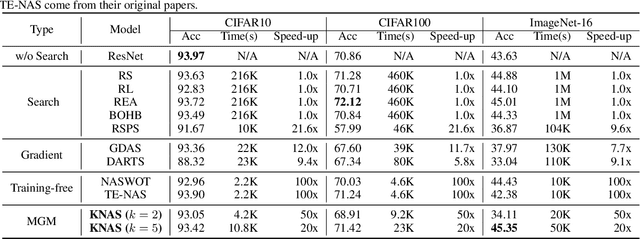

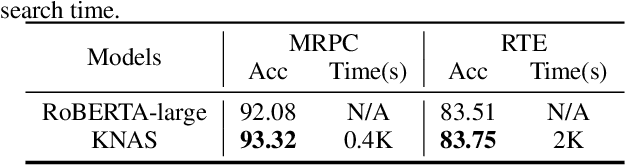
Many existing neural architecture search (NAS) solutions rely on downstream training for architecture evaluation, which takes enormous computations. Considering that these computations bring a large carbon footprint, this paper aims to explore a green (namely environmental-friendly) NAS solution that evaluates architectures without training. Intuitively, gradients, induced by the architecture itself, directly decide the convergence and generalization results. It motivates us to propose the gradient kernel hypothesis: Gradients can be used as a coarse-grained proxy of downstream training to evaluate random-initialized networks. To support the hypothesis, we conduct a theoretical analysis and find a practical gradient kernel that has good correlations with training loss and validation performance. According to this hypothesis, we propose a new kernel based architecture search approach KNAS. Experiments show that KNAS achieves competitive results with orders of magnitude faster than "train-then-test" paradigms on image classification tasks. Furthermore, the extremely low search cost enables its wide applications. The searched network also outperforms strong baseline RoBERTA-large on two text classification tasks. Codes are available at \url{https://github.com/Jingjing-NLP/KNAS} .
A Survey on Green Deep Learning
Nov 10, 2021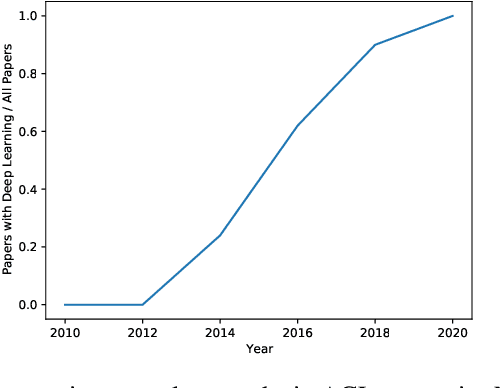
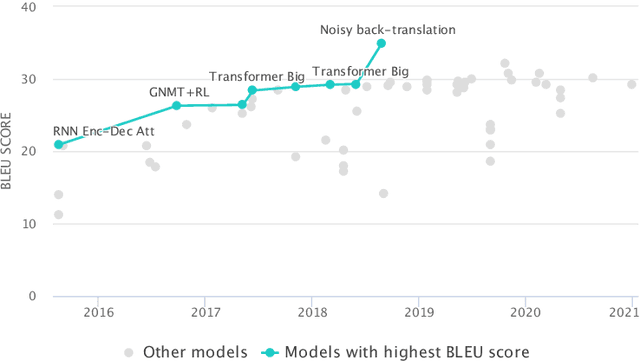
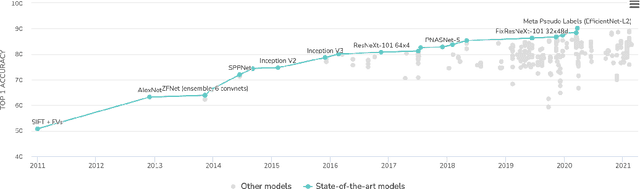
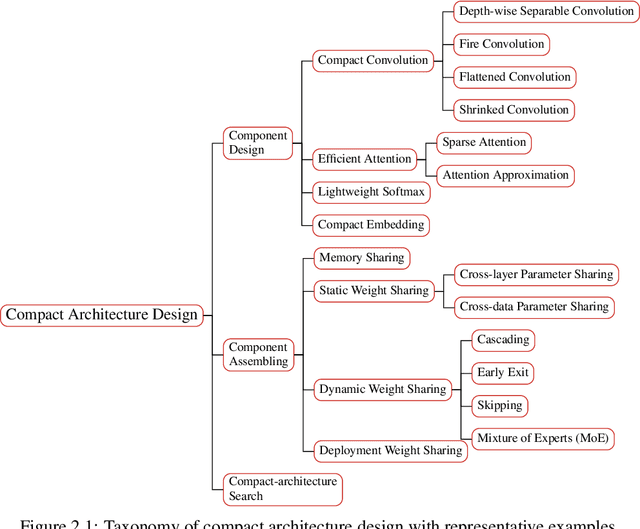
In recent years, larger and deeper models are springing up and continuously pushing state-of-the-art (SOTA) results across various fields like natural language processing (NLP) and computer vision (CV). However, despite promising results, it needs to be noted that the computations required by SOTA models have been increased at an exponential rate. Massive computations not only have a surprisingly large carbon footprint but also have negative effects on research inclusiveness and deployment on real-world applications. Green deep learning is an increasingly hot research field that appeals to researchers to pay attention to energy usage and carbon emission during model training and inference. The target is to yield novel results with lightweight and efficient technologies. Many technologies can be used to achieve this goal, like model compression and knowledge distillation. This paper focuses on presenting a systematic review of the development of Green deep learning technologies. We classify these approaches into four categories: (1) compact networks, (2) energy-efficient training strategies, (3) energy-efficient inference approaches, and (4) efficient data usage. For each category, we discuss the progress that has been achieved and the unresolved challenges.
Conformer-based Hybrid ASR System for Switchboard Dataset
Nov 05, 2021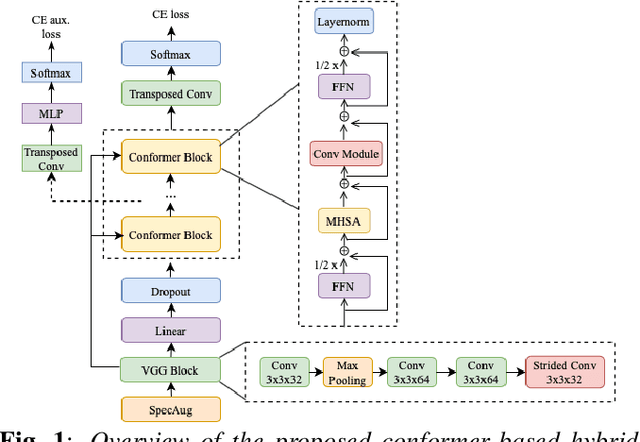
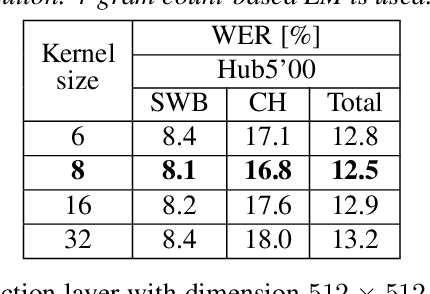
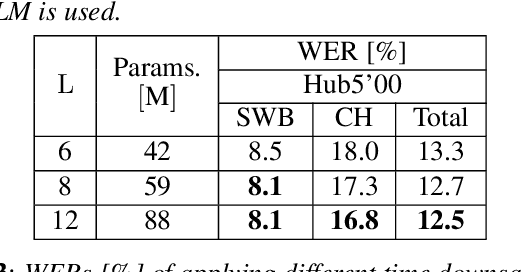
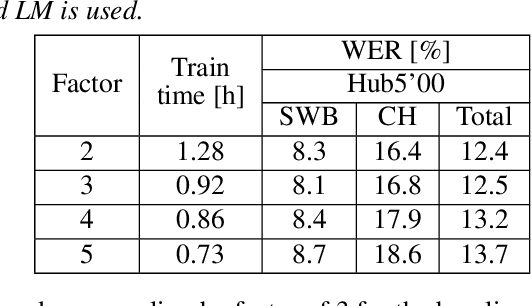
The recently proposed conformer architecture has been successfully used for end-to-end automatic speech recognition (ASR) architectures achieving state-of-the-art performance on different datasets. To our best knowledge, the impact of using conformer acoustic model for hybrid ASR is not investigated. In this paper, we present and evaluate a competitive conformer-based hybrid model training recipe. We study different training aspects and methods to improve word-error-rate as well as to increase training speed. We apply time downsampling methods for efficient training and use transposed convolutions to upsample the output sequence again. We conduct experiments on Switchboard 300h dataset and our conformer-based hybrid model achieves competitive results compared to other architectures. It generalizes very well on Hub5'01 test set and outperforms the BLSTM-based hybrid model significantly.