 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultilingual Knowledge Editing with Language-Agnostic Factual Neurons
Jun 24, 2024



Multilingual knowledge editing (MKE) aims to simultaneously revise factual knowledge across multilingual languages within large language models (LLMs). However, most existing MKE methods just adapt existing monolingual editing methods to multilingual scenarios, overlooking the deep semantic connections of the same factual knowledge between different languages, thereby limiting edit performance. To address this issue, we first investigate how LLMs represent multilingual factual knowledge and discover that the same factual knowledge in different languages generally activates a shared set of neurons, which we call language-agnostic factual neurons. These neurons represent the semantic connections between multilingual knowledge and are mainly located in certain layers. Inspired by this finding, we propose a new MKE method by locating and modifying Language-Agnostic Factual Neurons (LAFN) to simultaneously edit multilingual knowledge. Specifically, we first generate a set of paraphrases for each multilingual knowledge to be edited to precisely locate the corresponding language-agnostic factual neurons. Then we optimize the update values for modifying these located neurons to achieve simultaneous modification of the same factual knowledge in multiple languages. Experimental results on Bi-ZsRE and MzsRE benchmarks demonstrate that our method outperforms existing MKE methods and achieves remarkable edit performance, indicating the importance of considering the semantic connections among multilingual knowledge.
LCS: A Language Converter Strategy for Zero-Shot Neural Machine Translation
Jun 06, 2024



Multilingual neural machine translation models generally distinguish translation directions by the language tag (LT) in front of the source or target sentences. However, current LT strategies cannot indicate the desired target language as expected on zero-shot translation, i.e., the off-target issue. Our analysis reveals that the indication of the target language is sensitive to the placement of the target LT. For example, when placing the target LT on the decoder side, the indication would rapidly degrade along with decoding steps, while placing the target LT on the encoder side would lead to copying or paraphrasing the source input. To address the above issues, we propose a simple yet effective strategy named Language Converter Strategy (LCS). By introducing the target language embedding into the top encoder layers, LCS mitigates confusion in the encoder and ensures stable language indication for the decoder. Experimental results on MultiUN, TED, and OPUS-100 datasets demonstrate that LCS could significantly mitigate the off-target issue, with language accuracy up to 95.28%, 96.21%, and 85.35% meanwhile outperforming the vanilla LT strategy by 3.07, 3,3, and 7.93 BLEU scores on zero-shot translation, respectively.
Outdated Issue Aware Decoding for Factual Knowledge Editing
Jun 06, 2024



Recently, Knowledge Editing has received increasing attention, since it could update the specific knowledge from outdated ones in pretrained models without re-training. However, as pointed out by recent studies, existing related methods tend to merely memorize the superficial word composition of the edited knowledge, rather than truly learning and absorbing it. Consequently, on the reasoning questions, we discover that existing methods struggle to utilize the edited knowledge to reason the new answer, and tend to retain outdated responses, which are generated by the original models utilizing original knowledge. Nevertheless, the outdated responses are unexpected for the correct answers to reasoning questions, which we named as the outdated issue. To alleviate this issue, in this paper, we propose a simple yet effective decoding strategy, i.e., outDated ISsue aware deCOding (DISCO), to enhance the performance of edited models on reasoning questions. Specifically, we capture the difference in the probability distribution between the original and edited models. Further, we amplify the difference of the token prediction in the edited model to alleviate the outdated issue, and thus enhance the model performance w.r.t the edited knowledge. Experimental results suggest that applying DISCO could enhance edited models to reason, e.g., on reasoning questions, DISCO outperforms the prior SOTA method by 12.99 F1 scores, and reduces the ratio of the outdated issue to 5.78% on the zsRE dataset.
Touch100k: A Large-Scale Touch-Language-Vision Dataset for Touch-Centric Multimodal Representation
Jun 06, 2024



Touch holds a pivotal position in enhancing the perceptual and interactive capabilities of both humans and robots. Despite its significance, current tactile research mainly focuses on visual and tactile modalities, overlooking the language domain. Inspired by this, we construct Touch100k, a paired touch-language-vision dataset at the scale of 100k, featuring tactile sensation descriptions in multiple granularities (i.e., sentence-level natural expressions with rich semantics, including contextual and dynamic relationships, and phrase-level descriptions capturing the key features of tactile sensations). Based on the dataset, we propose a pre-training method, Touch-Language-Vision Representation Learning through Curriculum Linking (TLV-Link, for short), inspired by the concept of curriculum learning. TLV-Link aims to learn a tactile representation for the GelSight sensor and capture the relationship between tactile, language, and visual modalities. We evaluate our representation's performance across two task categories (namely, material property identification and robot grasping prediction), focusing on tactile representation and zero-shot touch understanding. The experimental evaluation showcases the effectiveness of our representation. By enabling TLV-Link to achieve substantial improvements and establish a new state-of-the-art in touch-centric multimodal representation learning, Touch100k demonstrates its value as a valuable resource for research. Project page: https://cocacola-lab.github.io/Touch100k/.
DoRA: Enhancing Parameter-Efficient Fine-Tuning with Dynamic Rank Distribution
May 28, 2024



Fine-tuning large-scale pre-trained models is inherently a resource-intensive task. While it can enhance the capabilities of the model, it also incurs substantial computational costs, posing challenges to the practical application of downstream tasks. Existing parameter-efficient fine-tuning (PEFT) methods such as Low-Rank Adaptation (LoRA) rely on a bypass framework that ignores the differential parameter budget requirements across weight matrices, which may lead to suboptimal fine-tuning outcomes. To address this issue, we introduce the Dynamic Low-Rank Adaptation (DoRA) method. DoRA decomposes high-rank LoRA layers into structured single-rank components, allowing for dynamic pruning of parameter budget based on their importance to specific tasks during training, which makes the most of the limited parameter budget. Experimental results demonstrate that DoRA can achieve competitive performance compared with LoRA and full model fine-tuning, and outperform various strong baselines with the same storage parameter budget. Our code is available at https://github.com/MIkumikumi0116/DoRA
Potential and Limitations of LLMs in Capturing Structured Semantics: A Case Study on SRL
May 10, 2024

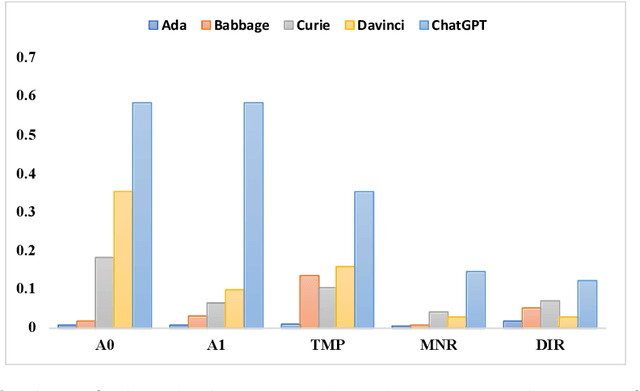

Large Language Models (LLMs) play a crucial role in capturing structured semantics to enhance language understanding, improve interpretability, and reduce bias. Nevertheless, an ongoing controversy exists over the extent to which LLMs can grasp structured semantics. To assess this, we propose using Semantic Role Labeling (SRL) as a fundamental task to explore LLMs' ability to extract structured semantics. In our assessment, we employ the prompting approach, which leads to the creation of our few-shot SRL parser, called PromptSRL. PromptSRL enables LLMs to map natural languages to explicit semantic structures, which provides an interpretable window into the properties of LLMs. We find interesting potential: LLMs can indeed capture semantic structures, and scaling-up doesn't always mirror potential. Additionally, limitations of LLMs are observed in C-arguments, etc. Lastly, we are surprised to discover that significant overlap in the errors is made by both LLMs and untrained humans, accounting for almost 30% of all errors.
Comments as Natural Logic Pivots: Improve Code Generation via Comment Perspective
Apr 11, 2024Code generation aims to understand the problem description and generate corresponding code snippets, where existing works generally decompose such complex tasks into intermediate steps by prompting strategies, such as Chain-of-Thought and its variants. While these studies have achieved some success, their effectiveness is highly dependent on the capabilities of advanced Large Language Models (LLMs) such as GPT-4, particularly in terms of API calls, which significantly limits their practical applicability. Consequently, how to enhance the code generation capabilities of small and medium-scale code LLMs without significantly increasing training costs is an appealing challenge. In this paper, we suggest that code comments are the natural logic pivot between natural language and code language and propose using comments to boost the code generation ability of code LLMs. Concretely, we propose MANGO (comMents As Natural loGic pivOts), including a comment contrastive training strategy and a corresponding logical comment decoding strategy. Experiments are performed on HumanEval and MBPP, utilizing StarCoder and WizardCoder as backbone models, and encompassing model parameter sizes between 3B and 7B. The results indicate that MANGO significantly improves the code pass rate based on the strong baselines. Meanwhile, the robustness of the logical comment decoding strategy is notably higher than the Chain-of-thoughts prompting. The code is publicly available at \url{https://github.com/pppa2019/Mango}.
Towards Comprehensive Multimodal Perception: Introducing the Touch-Language-Vision Dataset
Mar 14, 2024



Tactility provides crucial support and enhancement for the perception and interaction capabilities of both humans and robots. Nevertheless, the multimodal research related to touch primarily focuses on visual and tactile modalities, with limited exploration in the domain of language. Beyond vocabulary, sentence-level descriptions contain richer semantics. Based on this, we construct a touch-language-vision dataset named TLV (Touch-Language-Vision) by human-machine cascade collaboration, featuring sentence-level descriptions for multimode alignment. The new dataset is used to fine-tune our proposed lightweight training framework, TLV-Link (Linking Touch, Language, and Vision through Alignment), achieving effective semantic alignment with minimal parameter adjustments (1%). Project Page: https://xiaoen0.github.io/touch.page/.
TransportationGames: Benchmarking Transportation Knowledge of (Multimodal) Large Language Models
Jan 09, 2024Large language models (LLMs) and multimodal large language models (MLLMs) have shown excellent general capabilities, even exhibiting adaptability in many professional domains such as law, economics, transportation, and medicine. Currently, many domain-specific benchmarks have been proposed to verify the performance of (M)LLMs in specific fields. Among various domains, transportation plays a crucial role in modern society as it impacts the economy, the environment, and the quality of life for billions of people. However, it is unclear how much traffic knowledge (M)LLMs possess and whether they can reliably perform transportation-related tasks. To address this gap, we propose TransportationGames, a carefully designed and thorough evaluation benchmark for assessing (M)LLMs in the transportation domain. By comprehensively considering the applications in real-world scenarios and referring to the first three levels in Bloom's Taxonomy, we test the performance of various (M)LLMs in memorizing, understanding, and applying transportation knowledge by the selected tasks. The experimental results show that although some models perform well in some tasks, there is still much room for improvement overall. We hope the release of TransportationGames can serve as a foundation for future research, thereby accelerating the implementation and application of (M)LLMs in the transportation domain.
Towards Faster k-Nearest-Neighbor Machine Translation
Dec 12, 2023



Recent works have proven the effectiveness of k-nearest-neighbor machine translation(a.k.a kNN-MT) approaches to produce remarkable improvement in cross-domain translations. However, these models suffer from heavy retrieve overhead on the entire datastore when decoding each token. We observe that during the decoding phase, about 67% to 84% of tokens are unvaried after searching over the corpus datastore, which means most of the tokens cause futile retrievals and introduce unnecessary computational costs by initiating k-nearest-neighbor searches. We consider this phenomenon is explainable in linguistics and propose a simple yet effective multi-layer perceptron (MLP) network to predict whether a token should be translated jointly by the neural machine translation model and probabilities produced by the kNN or just by the neural model. The results show that our method succeeds in reducing redundant retrieval operations and significantly reduces the overhead of kNN retrievals by up to 53% at the expense of a slight decline in translation quality. Moreover, our method could work together with all existing kNN-MT systems.