 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Quality-Guided Mixture of Score-Fusion Experts Framework for Human Recognition
Jul 31, 2025Whole-body biometric recognition is a challenging multimodal task that integrates various biometric modalities, including face, gait, and body. This integration is essential for overcoming the limitations of unimodal systems. Traditionally, whole-body recognition involves deploying different models to process multiple modalities, achieving the final outcome by score-fusion (e.g., weighted averaging of similarity matrices from each model). However, these conventional methods may overlook the variations in score distributions of individual modalities, making it challenging to improve final performance. In this work, we present \textbf{Q}uality-guided \textbf{M}ixture of score-fusion \textbf{E}xperts (QME), a novel framework designed for improving whole-body biometric recognition performance through a learnable score-fusion strategy using a Mixture of Experts (MoE). We introduce a novel pseudo-quality loss for quality estimation with a modality-specific Quality Estimator (QE), and a score triplet loss to improve the metric performance. Extensive experiments on multiple whole-body biometric datasets demonstrate the effectiveness of our proposed approach, achieving state-of-the-art results across various metrics compared to baseline methods. Our method is effective for multimodal and multi-model, addressing key challenges such as model misalignment in the similarity score domain and variability in data quality.
Auditing Data Provenance in Real-world Text-to-Image Diffusion Models for Privacy and Copyright Protection
Jun 13, 2025Text-to-image diffusion model since its propose has significantly influenced the content creation due to its impressive generation capability. However, this capability depends on large-scale text-image datasets gathered from web platforms like social media, posing substantial challenges in copyright compliance and personal privacy leakage. Though there are some efforts devoted to explore approaches for auditing data provenance in text-to-image diffusion models, existing work has unrealistic assumptions that can obtain model internal knowledge, e.g., intermediate results, or the evaluation is not reliable. To fill this gap, we propose a completely black-box auditing framework called Feature Semantic Consistency-based Auditing (FSCA). It utilizes two types of semantic connections within the text-to-image diffusion model for auditing, eliminating the need for access to internal knowledge. To demonstrate the effectiveness of our FSCA framework, we perform extensive experiments on LAION-mi dataset and COCO dataset, and compare with eight state-of-the-art baseline approaches. The results show that FSCA surpasses previous baseline approaches across various metrics and different data distributions, showcasing the superiority of our FSCA. Moreover, we introduce a recall balance strategy and a threshold adjustment strategy, which collectively allows FSCA to reach up a user-level accuracy of 90% in a real-world auditing scenario with only 10 samples/user, highlighting its strong auditing potential in real-world applications. Our code is made available at https://github.com/JiePKU/FSCA.
Gradient Boosting Decision Tree with LSTM for Investment Prediction
May 29, 2025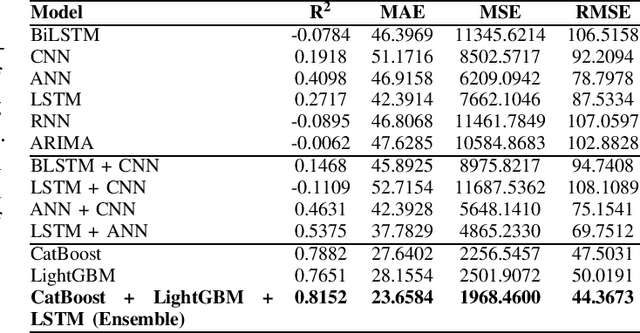
This paper proposes a hybrid framework combining LSTM (Long Short-Term Memory) networks with LightGBM and CatBoost for stock price prediction. The framework processes time-series financial data and evaluates performance using seven models: Artificial Neural Networks (ANNs), Convolutional Neural Networks (CNNs), Bidirectional LSTM (BiLSTM), vanilla LSTM, XGBoost, LightGBM, and standard Neural Networks (NNs). Key metrics, including MAE, R-squared, MSE, and RMSE, are used to establish benchmarks across different time scales. Building on these benchmarks, we develop an ensemble model that combines the strengths of sequential and tree-based approaches. Experimental results show that the proposed framework improves accuracy by 10 to 15 percent compared to individual models and reduces error during market changes. This study highlights the potential of ensemble methods for financial forecasting and provides a flexible design for integrating new machine learning techniques.
Plan and Budget: Effective and Efficient Test-Time Scaling on Large Language Model Reasoning
May 22, 2025



Large Language Models (LLMs) have achieved remarkable success in complex reasoning tasks, but their inference remains computationally inefficient. We observe a common failure mode in many prevalent LLMs, overthinking, where models generate verbose and tangential reasoning traces even for simple queries. Recent works have tried to mitigate this by enforcing fixed token budgets, however, this can lead to underthinking, especially on harder problems. Through empirical analysis, we identify that this inefficiency often stems from unclear problem-solving strategies. To formalize this, we develop a theoretical model, BBAM (Bayesian Budget Allocation Model), which models reasoning as a sequence of sub-questions with varying uncertainty, and introduce the $E^3$ metric to capture the trade-off between correctness and computation efficiency. Building on theoretical results from BBAM, we propose Plan-and-Budget, a model-agnostic, test-time framework that decomposes complex queries into sub-questions and allocates token budgets based on estimated complexity using adaptive scheduling. Plan-and-Budget improves reasoning efficiency across a range of tasks and models, achieving up to +70% accuracy gains, -39% token reduction, and +187.5% improvement in $E^3$. Notably, it elevates a smaller model (DS-Qwen-32B) to match the efficiency of a larger model (DS-LLaMA-70B)-demonstrating Plan-and-Budget's ability to close performance gaps without retraining. Our code is available at anonymous.4open.science/r/P-and-B-6513/.
A Unified and Scalable Membership Inference Method for Visual Self-supervised Encoder via Part-aware Capability
May 15, 2025Self-supervised learning shows promise in harnessing extensive unlabeled data, but it also confronts significant privacy concerns, especially in vision. In this paper, we perform membership inference on visual self-supervised models in a more realistic setting: self-supervised training method and details are unknown for an adversary when attacking as he usually faces a black-box system in practice. In this setting, considering that self-supervised model could be trained by completely different self-supervised paradigms, e.g., masked image modeling and contrastive learning, with complex training details, we propose a unified membership inference method called PartCrop. It is motivated by the shared part-aware capability among models and stronger part response on the training data. Specifically, PartCrop crops parts of objects in an image to query responses within the image in representation space. We conduct extensive attacks on self-supervised models with different training protocols and structures using three widely used image datasets. The results verify the effectiveness and generalization of PartCrop. Moreover, to defend against PartCrop, we evaluate two common approaches, i.e., early stop and differential privacy, and propose a tailored method called shrinking crop scale range. The defense experiments indicate that all of them are effective. Finally, besides prototype testing on toy visual encoders and small-scale image datasets, we quantitatively study the impacts of scaling from both data and model aspects in a realistic scenario and propose a scalable PartCrop-v2 by introducing two structural improvements to PartCrop. Our code is at https://github.com/JiePKU/PartCrop.
Person Recognition at Altitude and Range: Fusion of Face, Body Shape and Gait
May 07, 2025
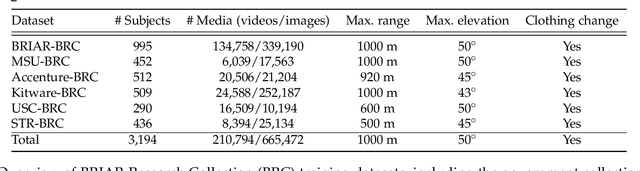

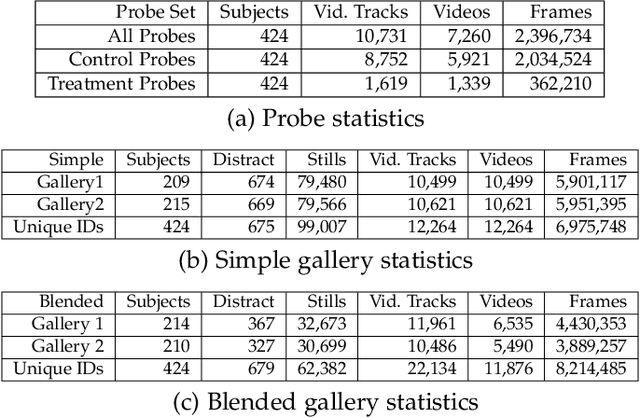
We address the problem of whole-body person recognition in unconstrained environments. This problem arises in surveillance scenarios such as those in the IARPA Biometric Recognition and Identification at Altitude and Range (BRIAR) program, where biometric data is captured at long standoff distances, elevated viewing angles, and under adverse atmospheric conditions (e.g., turbulence and high wind velocity). To this end, we propose FarSight, a unified end-to-end system for person recognition that integrates complementary biometric cues across face, gait, and body shape modalities. FarSight incorporates novel algorithms across four core modules: multi-subject detection and tracking, recognition-aware video restoration, modality-specific biometric feature encoding, and quality-guided multi-modal fusion. These components are designed to work cohesively under degraded image conditions, large pose and scale variations, and cross-domain gaps. Extensive experiments on the BRIAR dataset, one of the most comprehensive benchmarks for long-range, multi-modal biometric recognition, demonstrate the effectiveness of FarSight. Compared to our preliminary system, this system achieves a 34.1% absolute gain in 1:1 verification accuracy (TAR@0.1% FAR), a 17.8% increase in closed-set identification (Rank-20), and a 34.3% reduction in open-set identification errors (FNIR@1% FPIR). Furthermore, FarSight was evaluated in the 2025 NIST RTE Face in Video Evaluation (FIVE), which conducts standardized face recognition testing on the BRIAR dataset. These results establish FarSight as a state-of-the-art solution for operational biometric recognition in challenging real-world conditions.
DianJin-R1: Evaluating and Enhancing Financial Reasoning in Large Language Models
Apr 22, 2025



Effective reasoning remains a core challenge for large language models (LLMs) in the financial domain, where tasks often require domain-specific knowledge, precise numerical calculations, and strict adherence to compliance rules. We propose DianJin-R1, a reasoning-enhanced framework designed to address these challenges through reasoning-augmented supervision and reinforcement learning. Central to our approach is DianJin-R1-Data, a high-quality dataset constructed from CFLUE, FinQA, and a proprietary compliance corpus (Chinese Compliance Check, CCC), combining diverse financial reasoning scenarios with verified annotations. Our models, DianJin-R1-7B and DianJin-R1-32B, are fine-tuned from Qwen2.5-7B-Instruct and Qwen2.5-32B-Instruct using a structured format that generates both reasoning steps and final answers. To further refine reasoning quality, we apply Group Relative Policy Optimization (GRPO), a reinforcement learning method that incorporates dual reward signals: one encouraging structured outputs and another rewarding answer correctness. We evaluate our models on five benchmarks: three financial datasets (CFLUE, FinQA, and CCC) and two general reasoning benchmarks (MATH-500 and GPQA-Diamond). Experimental results show that DianJin-R1 models consistently outperform their non-reasoning counterparts, especially on complex financial tasks. Moreover, on the real-world CCC dataset, our single-call reasoning models match or even surpass the performance of multi-agent systems that require significantly more computational cost. These findings demonstrate the effectiveness of DianJin-R1 in enhancing financial reasoning through structured supervision and reward-aligned learning, offering a scalable and practical solution for real-world applications.
Boosting Multi-View Stereo with Depth Foundation Model in the Absence of Real-World Labels
Apr 16, 2025



Learning-based Multi-View Stereo (MVS) methods have made remarkable progress in recent years. However, how to effectively train the network without using real-world labels remains a challenging problem. In this paper, driven by the recent advancements of vision foundation models, a novel method termed DFM-MVS, is proposed to leverage the depth foundation model to generate the effective depth prior, so as to boost MVS in the absence of real-world labels. Specifically, a depth prior-based pseudo-supervised training mechanism is developed to simulate realistic stereo correspondences using the generated depth prior, thereby constructing effective supervision for the MVS network. Besides, a depth prior-guided error correction strategy is presented to leverage the depth prior as guidance to mitigate the error propagation problem inherent in the widely-used coarse-to-fine network structure. Experimental results on DTU and Tanks & Temples datasets demonstrate that the proposed DFM-MVS significantly outperforms existing MVS methods without using real-world labels.
Commenting Higher-level Code Unit: Full Code, Reduced Code, or Hierarchical Code Summarization
Mar 13, 2025



Commenting code is a crucial activity in software development, as it aids in facilitating future maintenance and updates. To enhance the efficiency of writing comments and reduce developers' workload, researchers has proposed various automated code summarization (ACS) techniques to automatically generate comments/summaries for given code units. However, these ACS techniques primarily focus on generating summaries for code units at the method level. There is a significant lack of research on summarizing higher-level code units, such as file-level and module-level code units, despite the fact that summaries of these higher-level code units are highly useful for quickly gaining a macro-level understanding of software components and architecture. To fill this gap, in this paper, we conduct a systematic study on how to use LLMs for commenting higher-level code units, including file level and module level. These higher-level units are significantly larger than method-level ones, which poses challenges in handling long code inputs within LLM constraints and maintaining efficiency. To address these issues, we explore various summarization strategies for ACS of higher-level code units, which can be divided into three types: full code summarization, reduced code summarization, and hierarchical code summarization. The experimental results suggest that for summarizing file-level code units, using the full code is the most effective approach, with reduced code serving as a cost-efficient alternative. However, for summarizing module-level code units, hierarchical code summarization becomes the most promising strategy. In addition, inspired by the research on method-level ACS, we also investigate using the LLM as an evaluator to evaluate the quality of summaries of higher-level code units. The experimental results demonstrate that the LLM's evaluation results strongly correlate with human evaluations.
Speech Translation Refinement using Large Language Models
Jan 25, 2025



Recent advancements in large language models (LLMs) have demonstrated their remarkable capabilities across various language tasks. Inspired by the success of text-to-text translation refinement, this paper investigates how LLMs can improve the performance of speech translation by introducing a joint refinement process. Through the joint refinement of speech translation (ST) and automatic speech recognition (ASR) transcription via LLMs, the performance of the ST model is significantly improved in both training-free in-context learning and parameter-efficient fine-tuning scenarios. Additionally, we explore the effect of document-level context on refinement under the context-aware fine-tuning scenario. Experimental results on the MuST-C and CoVoST 2 datasets, which include seven translation tasks, demonstrate the effectiveness of the proposed approach using several popular LLMs including GPT-3.5-turbo, LLaMA3-8B, and Mistral-12B. Further analysis further suggests that jointly refining both transcription and translation yields better performance compared to refining translation alone. Meanwhile, incorporating document-level context significantly enhances refinement performance. We release our code and datasets on GitHub.