 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting Overflow in Compressed Token Representations for Retrieval-Augmented Generation
Feb 13, 2026Efficient long-context processing remains a crucial challenge for contemporary large language models (LLMs), especially in resource-constrained environments. Soft compression architectures promise to extend effective context length by replacing long token sequences with smaller sets of learned compressed tokens. Yet, the limits of compressibility -- and when compression begins to erase task-relevant content -- remain underexplored. In this paper, we define token overflow as a regime in which compressed representations no longer contain sufficient information to answer a given query, and propose a methodology to characterize and detect it. In the xRAG soft-compression setting, we find that query-agnostic saturation statistics reliably separate compressed from uncompressed token representations, providing a practical tool for identifying compressed tokens but showing limited overflow detection capability. Lightweight probing classifiers over both query and context xRAG representations detect overflow with 0.72 AUC-ROC on average on HotpotQA, SQuADv2, and TriviaQA datasets, demonstrating that incorporating query information improves detection performance. These results advance from query-independent diagnostics to query-aware detectors, enabling low-cost pre-LLM gating to mitigate compression-induced errors.
Psychologically-Inspired Music Recommendation System
May 06, 2022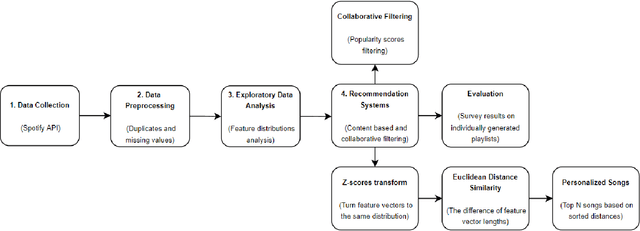
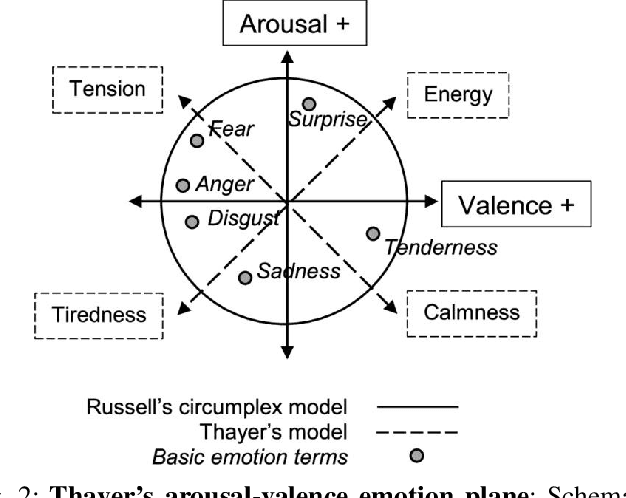

In the last few years, automated recommendation systems have been a major focus in the music field, where companies such as Spotify, Amazon, and Apple are competing in the ability to generate the most personalized music suggestions for their users. One of the challenges developers still fail to tackle is taking into account the psychological and emotional aspects of the music. Our goal is to find a way to integrate users' personal traits and their current emotional state into a single music recommendation system with both collaborative and content-based filtering. We seek to relate the personality and the current emotional state of the listener to the audio features in order to build an emotion-aware MRS. We compare the results both quantitatively and qualitatively to the output of the traditional MRS based on the Spotify API data to understand if our advancements make a significant impact on the quality of music recommendations.