 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLCReg: Long-Tailed Image Classification with Latent Categories based Recognition
Sep 13, 2023



In this work, we tackle the challenging problem of long-tailed image recognition. Previous long-tailed recognition approaches mainly focus on data augmentation or re-balancing strategies for the tail classes to give them more attention during model training. However, these methods are limited by the small number of training images for the tail classes, which results in poor feature representations. To address this issue, we propose the Latent Categories based long-tail Recognition (LCReg) method. Our hypothesis is that common latent features shared by head and tail classes can be used to improve feature representation. Specifically, we learn a set of class-agnostic latent features shared by both head and tail classes, and then use semantic data augmentation on the latent features to implicitly increase the diversity of the training sample. We conduct extensive experiments on five long-tailed image recognition datasets, and the results show that our proposed method significantly improves the baselines.
Efficient Joint Optimization of Layer-Adaptive Weight Pruning in Deep Neural Networks
Aug 24, 2023In this paper, we propose a novel layer-adaptive weight-pruning approach for Deep Neural Networks (DNNs) that addresses the challenge of optimizing the output distortion minimization while adhering to a target pruning ratio constraint. Our approach takes into account the collective influence of all layers to design a layer-adaptive pruning scheme. We discover and utilize a very important additivity property of output distortion caused by pruning weights on multiple layers. This property enables us to formulate the pruning as a combinatorial optimization problem and efficiently solve it through dynamic programming. By decomposing the problem into sub-problems, we achieve linear time complexity, making our optimization algorithm fast and feasible to run on CPUs. Our extensive experiments demonstrate the superiority of our approach over existing methods on the ImageNet and CIFAR-10 datasets. On CIFAR-10, our method achieves remarkable improvements, outperforming others by up to 1.0% for ResNet-32, 0.5% for VGG-16, and 0.7% for DenseNet-121 in terms of top-1 accuracy. On ImageNet, we achieve up to 4.7% and 4.6% higher top-1 accuracy compared to other methods for VGG-16 and ResNet-50, respectively. These results highlight the effectiveness and practicality of our approach for enhancing DNN performance through layer-adaptive weight pruning. Code will be available on https://github.com/Akimoto-Cris/RD_VIT_PRUNE.
Unlimited Knowledge Distillation for Action Recognition in the Dark
Aug 18, 2023Dark videos often lose essential information, which causes the knowledge learned by networks is not enough to accurately recognize actions. Existing knowledge assembling methods require massive GPU memory to distill the knowledge from multiple teacher models into a student model. In action recognition, this drawback becomes serious due to much computation required by video process. Constrained by limited computation source, these approaches are infeasible. To address this issue, we propose an unlimited knowledge distillation (UKD) in this paper. Compared with existing knowledge assembling methods, our UKD can effectively assemble different knowledge without introducing high GPU memory consumption. Thus, the number of teaching models for distillation is unlimited. With our UKD, the network's learned knowledge can be remarkably enriched. Our experiments show that the single stream network distilled with our UKD even surpasses a two-stream network. Extensive experiments are conducted on the ARID dataset.
A Snoring Sound Dataset for Body Position Recognition: Collection, Annotation, and Analysis
Jul 25, 2023



Obstructive Sleep Apnea-Hypopnea Syndrome (OSAHS) is a chronic breathing disorder caused by a blockage in the upper airways. Snoring is a prominent symptom of OSAHS, and previous studies have attempted to identify the obstruction site of the upper airways by snoring sounds. Despite some progress, the classification of the obstruction site remains challenging in real-world clinical settings due to the influence of sleep body position on upper airways. To address this challenge, this paper proposes a snore-based sleep body position recognition dataset (SSBPR) consisting of 7570 snoring recordings, which comprises six distinct labels for sleep body position: supine, supine but left lateral head, supine but right lateral head, left-side lying, right-side lying and prone. Experimental results show that snoring sounds exhibit certain acoustic features that enable their effective utilization for identifying body posture during sleep in real-world scenarios.
Improving the Transferability of Adversarial Examples via Direction Tuning
Mar 27, 2023In the transfer-based adversarial attacks, adversarial examples are only generated by the surrogate models and achieve effective perturbation in the victim models. Although considerable efforts have been developed on improving the transferability of adversarial examples generated by transfer-based adversarial attacks, our investigation found that, the big deviation between the actual and steepest update directions of the current transfer-based adversarial attacks is caused by the large update step length, resulting in the generated adversarial examples can not converge well. However, directly reducing the update step length will lead to serious update oscillation so that the generated adversarial examples also can not achieve great transferability to the victim models. To address these issues, a novel transfer-based attack, namely direction tuning attack, is proposed to not only decrease the update deviation in the large step length, but also mitigate the update oscillation in the small sampling step length, thereby making the generated adversarial examples converge well to achieve great transferability on victim models. In addition, a network pruning method is proposed to smooth the decision boundary, thereby further decreasing the update oscillation and enhancing the transferability of the generated adversarial examples. The experiment results on ImageNet demonstrate that the average attack success rate (ASR) of the adversarial examples generated by our method can be improved from 87.9\% to 94.5\% on five victim models without defenses, and from 69.1\% to 76.2\% on eight advanced defense methods, in comparison with that of latest gradient-based attacks.
Fuzziness-tuned: Improving the Transferability of Adversarial Examples
Mar 17, 2023



With the development of adversarial attacks, adversairal examples have been widely used to enhance the robustness of the training models on deep neural networks. Although considerable efforts of adversarial attacks on improving the transferability of adversarial examples have been developed, the attack success rate of the transfer-based attacks on the surrogate model is much higher than that on victim model under the low attack strength (e.g., the attack strength $\epsilon=8/255$). In this paper, we first systematically investigated this issue and found that the enormous difference of attack success rates between the surrogate model and victim model is caused by the existence of a special area (known as fuzzy domain in our paper), in which the adversarial examples in the area are classified wrongly by the surrogate model while correctly by the victim model. Then, to eliminate such enormous difference of attack success rates for improving the transferability of generated adversarial examples, a fuzziness-tuned method consisting of confidence scaling mechanism and temperature scaling mechanism is proposed to ensure the generated adversarial examples can effectively skip out of the fuzzy domain. The confidence scaling mechanism and the temperature scaling mechanism can collaboratively tune the fuzziness of the generated adversarial examples through adjusting the gradient descent weight of fuzziness and stabilizing the update direction, respectively. Specifically, the proposed fuzziness-tuned method can be effectively integrated with existing adversarial attacks to further improve the transferability of adverarial examples without changing the time complexity. Extensive experiments demonstrated that fuzziness-tuned method can effectively enhance the transferability of adversarial examples in the latest transfer-based attacks.
Hybrid Multimodal Feature Extraction, Mining and Fusion for Sentiment Analysis
Aug 12, 2022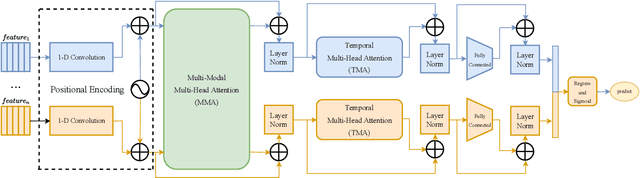
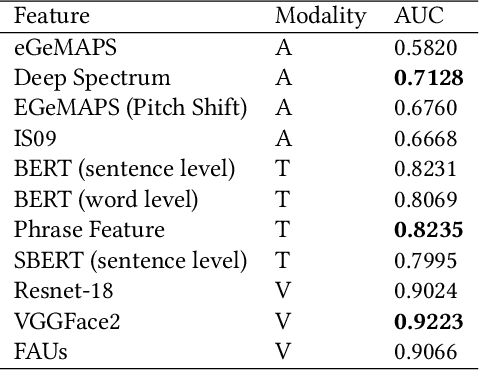
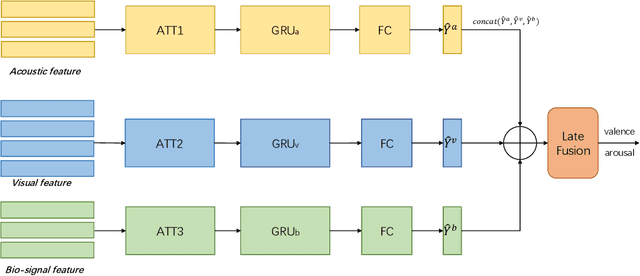
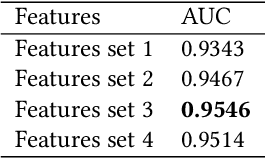
In this paper, we present our solutions for the Multimodal Sentiment Analysis Challenge (MuSe) 2022, which includes MuSe-Humor, MuSe-Reaction and MuSe-Stress Sub-challenges. The MuSe 2022 focuses on humor detection, emotional reactions and multimodal emotional stress utilizing different modalities and data sets. In our work, different kinds of multimodal features are extracted, including acoustic, visual, text and biological features. These features are fused by TEMMA and GRU with self-attention mechanism frameworks. In this paper, 1) several new audio features, facial expression features and paragraph-level text embeddings are extracted for accuracy improvement. 2) we substantially improve the accuracy and reliability of multimodal sentiment prediction by mining and blending the multimodal features. 3) effective data augmentation strategies are applied in model training to alleviate the problem of sample imbalance and prevent the model from learning biased subject characters. For the MuSe-Humor sub-challenge, our model obtains the AUC score of 0.8932. For the MuSe-Reaction sub-challenge, the Pearson's Correlations Coefficient of our approach on the test set is 0.3879, which outperforms all other participants. For the MuSe-Stress sub-challenge, our approach outperforms the baseline in both arousal and valence on the test dataset, reaching a final combined result of 0.5151.
Long-tailed Recognition by Learning from Latent Categories
Jun 02, 2022
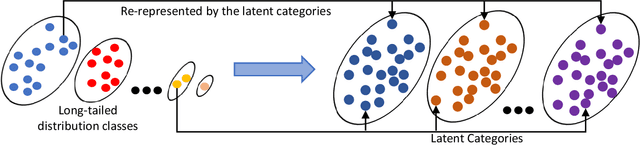
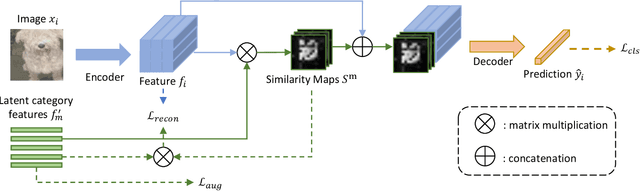

In this work, we address the challenging task of long-tailed image recognition. Previous long-tailed recognition methods commonly focus on the data augmentation or re-balancing strategy of the tail classes to give more attention to tail classes during the model training. However, due to the limited training images for tail classes, the diversity of tail class images is still restricted, which results in poor feature representations. In this work, we hypothesize that common latent features among the head and tail classes can be used to give better feature representation. Motivated by this, we introduce a Latent Categories based long-tail Recognition (LCReg) method. Specifically, we propose to learn a set of class-agnostic latent features shared among the head and tail classes. Then, we implicitly enrich the training sample diversity via applying semantic data augmentation to the latent features. Extensive experiments on five long-tailed image recognition datasets demonstrate that our proposed LCReg is able to significantly outperform previous methods and achieve state-of-the-art results.
FACM: Correct the Output of Deep Neural Network with Middle Layers Features against Adversarial Samples
Jun 02, 2022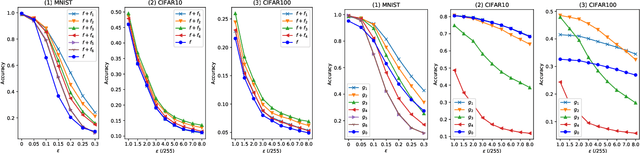
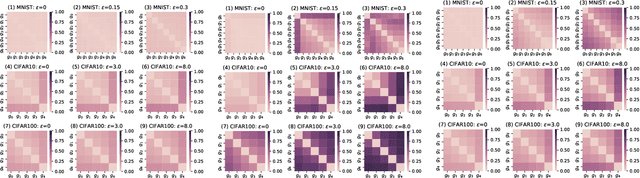


In the strong adversarial attacks against deep neural network (DNN), the output of DNN will be misclassified if and only if the last feature layer of the DNN is completely destroyed by adversarial samples, while our studies found that the middle feature layers of the DNN can still extract the effective features of the original normal category in these adversarial attacks. To this end, in this paper, a middle $\bold{F}$eature layer $\bold{A}$nalysis and $\bold{C}$onditional $\bold{M}$atching prediction distribution (FACM) model is proposed to increase the robustness of the DNN against adversarial samples through correcting the output of DNN with the features extracted by the middle layers of DNN. In particular, the middle $\bold{F}$eature layer $\bold{A}$nalysis (FA) module, the conditional matching prediction distribution (CMPD) module and the output decision module are included in our FACM model to collaboratively correct the classification of adversarial samples. The experiments results show that, our FACM model can significantly improve the robustness of the naturally trained model against various attacks, and our FA model can significantly improve the robustness of the adversarially trained model against white-box attacks with weak transferability and black box attacks where FA model includes the FA module and the output decision module, not the CMPD module.
Mask-Guided Divergence Loss Improves the Generalization and Robustness of Deep Neural Network
Jun 02, 2022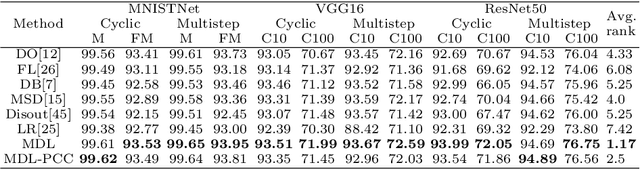
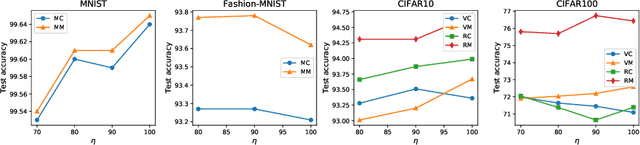
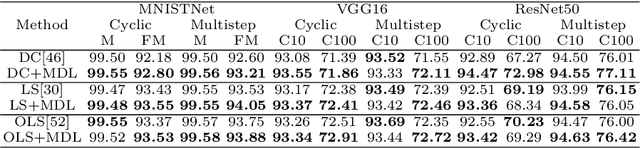
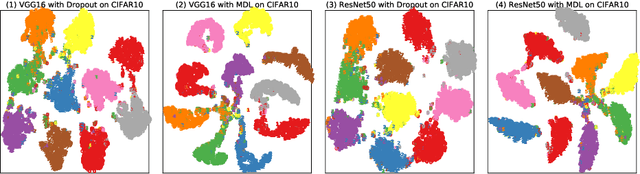
Deep neural network (DNN) with dropout can be regarded as an ensemble model consisting of lots of sub-DNNs (i.e., an ensemble sub-DNN where the sub-DNN is the remaining part of the DNN after dropout), and through increasing the diversity of the ensemble sub-DNN, the generalization and robustness of the DNN can be effectively improved. In this paper, a mask-guided divergence loss function (MDL), which consists of a cross-entropy loss term and an orthogonal term, is proposed to increase the diversity of the ensemble sub-DNN by the added orthogonal term. Particularly, the mask technique is introduced to assist in generating the orthogonal term for avoiding overfitting of the diversity learning. The theoretical analysis and extensive experiments on 4 datasets (i.e., MNIST, FashionMNIST, CIFAR10, and CIFAR100) manifest that MDL can improve the generalization and robustness of standard training and adversarial training. For CIFAR10 and CIFAR100, in standard training, the maximum improvement of accuracy is $1.38\%$ on natural data, $30.97\%$ on FGSM (i.e., Fast Gradient Sign Method) attack, $38.18\%$ on PGD (i.e., Projected Gradient Descent) attack. While in adversarial training, the maximum improvement is $1.68\%$ on natural data, $4.03\%$ on FGSM attack and $2.65\%$ on PGD attack.