 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward matrix multiplication for deep learning inference on the Xilinx Versal
Feb 15, 2023The remarkable positive impact of Deep Neural Networks on many Artificial Intelligence (AI) tasks has led to the development of various high performance algorithms as well as specialized processors and accelerators. In this paper we address this scenario by demonstrating that the principles underlying the modern realization of the general matrix multiplication (GEMM) in conventional processor architectures, are also valid to achieve high performance for the type of operations that arise in deep learning (DL) on an exotic accelerator such as the AI Engine (AIE) tile embedded in Xilinx Versal platforms. In particular, our experimental results with a prototype implementation of the GEMM kernel, on a Xilinx Versal VCK190, delivers performance close to 86.7% of the theoretical peak that can be expected on an AIE tile, for 16-bit integer operands.
Guided Hybrid Quantization for Object detection in Multimodal Remote Sensing Imagery via One-to-one Self-teaching
Dec 31, 2022



Considering the computation complexity, we propose a Guided Hybrid Quantization with One-to-one Self-Teaching (GHOST}) framework. More concretely, we first design a structure called guided quantization self-distillation (GQSD), which is an innovative idea for realizing lightweight through the synergy of quantization and distillation. The training process of the quantization model is guided by its full-precision model, which is time-saving and cost-saving without preparing a huge pre-trained model in advance. Second, we put forward a hybrid quantization (HQ) module to obtain the optimal bit width automatically under a constrained condition where a threshold for distribution distance between the center and samples is applied in the weight value search space. Third, in order to improve information transformation, we propose a one-to-one self-teaching (OST) module to give the student network a ability of self-judgment. A switch control machine (SCM) builds a bridge between the student network and teacher network in the same location to help the teacher to reduce wrong guidance and impart vital knowledge to the student. This distillation method allows a model to learn from itself and gain substantial improvement without any additional supervision. Extensive experiments on a multimodal dataset (VEDAI) and single-modality datasets (DOTA, NWPU, and DIOR) show that object detection based on GHOST outperforms the existing detectors. The tiny parameters (<9.7 MB) and Bit-Operations (BOPs) (<2158 G) compared with any remote sensing-based, lightweight or distillation-based algorithms demonstrate the superiority in the lightweight design domain. Our code and model will be released at https://github.com/icey-zhang/GHOST.
Vision Transformers are Parameter-Efficient Audio-Visual Learners
Dec 15, 2022



Vision transformers (ViTs) have achieved impressive results on various computer vision tasks in the last several years. In this work, we study the capability of frozen ViTs, pretrained only on visual data, to generalize to audio-visual data without finetuning any of its original parameters. To do so, we propose a latent audio-visual hybrid (LAVISH) adapter that adapts pretrained ViTs to audio-visual tasks by injecting a small number of trainable parameters into every layer of a frozen ViT. To efficiently fuse visual and audio cues, our LAVISH adapter uses a small set of latent tokens, which form an attention bottleneck, thus, eliminating the quadratic cost of standard cross-attention. Compared to the existing modality-specific audio-visual methods, our approach achieves competitive or even better performance on various audio-visual tasks while using fewer tunable parameters and without relying on costly audio pretraining or external audio encoders. Our code is available at https://genjib.github.io/project_page/LAVISH/
VindLU: A Recipe for Effective Video-and-Language Pretraining
Dec 09, 2022



The last several years have witnessed remarkable progress in video-and-language (VidL) understanding. However, most modern VidL approaches use complex and specialized model architectures and sophisticated pretraining protocols, making the reproducibility, analysis and comparisons of these frameworks difficult. Hence, instead of proposing yet another new VidL model, this paper conducts a thorough empirical study demystifying the most important factors in the VidL model design. Among the factors that we investigate are (i) the spatiotemporal architecture design, (ii) the multimodal fusion schemes, (iii) the pretraining objectives, (iv) the choice of pretraining data, (v) pretraining and finetuning protocols, and (vi) dataset and model scaling. Our empirical study reveals that the most important design factors include: temporal modeling, video-to-text multimodal fusion, masked modeling objectives, and joint training on images and videos. Using these empirical insights, we then develop a step-by-step recipe, dubbed VindLU, for effective VidL pretraining. Our final model trained using our recipe achieves comparable or better than state-of-the-art results on several VidL tasks without relying on external CLIP pretraining. In particular, on the text-to-video retrieval task, our approach obtains 61.2% on DiDeMo, and 55.0% on ActivityNet, outperforming current SOTA by 7.8% and 6.1% respectively. Furthermore, our model also obtains state-of-the-art video question-answering results on ActivityNet-QA, MSRVTT-QA, MSRVTT-MC and TVQA. Our code and pretrained models are publicly available at: https://github.com/klauscc/VindLU.
Perceiver-VL: Efficient Vision-and-Language Modeling with Iterative Latent Attention
Nov 21, 2022We present Perceiver-VL, a vision-and-language framework that efficiently handles high-dimensional multimodal inputs such as long videos and text. Powered by the iterative latent cross-attention of Perceiver, our framework scales with linear complexity, in contrast to the quadratic complexity of self-attention used in many state-of-the-art transformer-based models. To further improve the efficiency of our framework, we also study applying LayerDrop on cross-attention layers and introduce a mixed-stream architecture for cross-modal retrieval. We evaluate Perceiver-VL on diverse video-text and image-text benchmarks, where Perceiver-VL achieves the lowest GFLOPs and latency while maintaining competitive performance. In addition, we also provide comprehensive analyses of various aspects of our framework, including pretraining data, scalability of latent size and input size, dropping cross-attention layers at inference to reduce latency, modality aggregation strategy, positional encoding, and weight initialization strategy. Our code and checkpoints are available at: https://github.com/zinengtang/Perceiver_VL
SuperYOLO: Super Resolution Assisted Object Detection in Multimodal Remote Sensing Imagery
Sep 27, 2022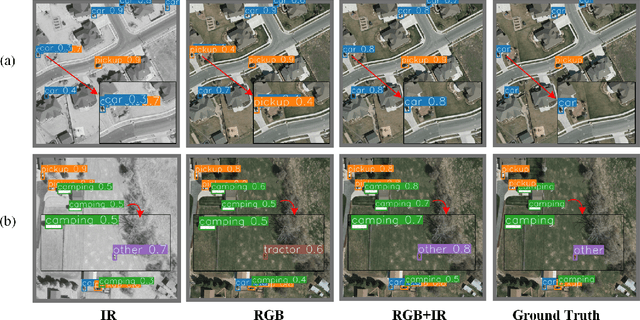
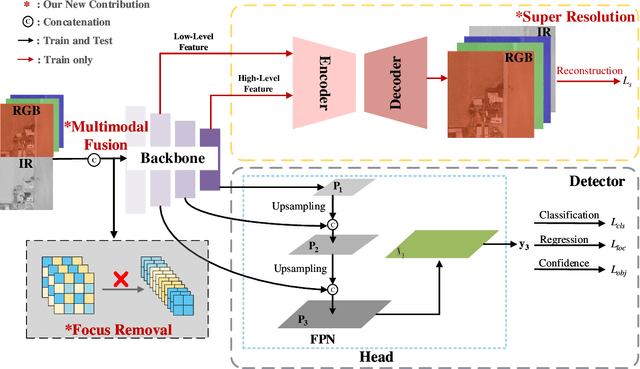
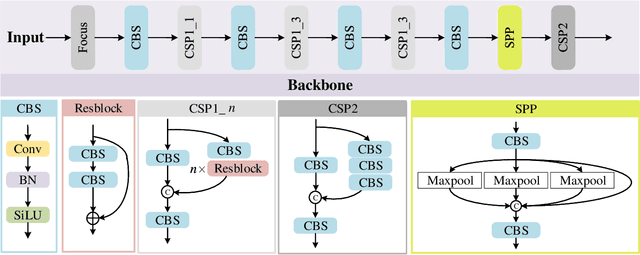
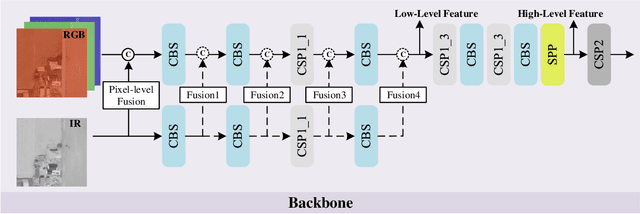
In this paper, we propose an accurate yet fast small object detection method for RSI, named SuperYOLO, which fuses multimodal data and performs high resolution (HR) object detection on multiscale objects by utilizing the assisted super resolution (SR) learning and considering both the detection accuracy and computation cost. First, we construct a compact baseline by removing the Focus module to keep the HR features and significantly overcomes the missing error of small objects. Second, we utilize pixel-level multimodal fusion (MF) to extract information from various data to facilitate more suitable and effective features for small objects in RSI. Furthermore, we design a simple and flexible SR branch to learn HR feature representations that can discriminate small objects from vast backgrounds with low-resolution (LR) input, thus further improving the detection accuracy. Moreover, to avoid introducing additional computation, the SR branch is discarded in the inference stage and the computation of the network model is reduced due to the LR input. Experimental results show that, on the widely used VEDAI RS dataset, SuperYOLO achieves an accuracy of 73.61% (in terms of mAP50), which is more than 10% higher than the SOTA large models such as YOLOv5l, YOLOv5x and RS designed YOLOrs. Meanwhile, the GFOLPs and parameter size of SuperYOLO are about 18.1x and 4.2x less than YOLOv5x. Our proposed model shows a favorable accuracy-speed trade-off compared to the state-of-art models. The code will be open sourced at https://github.com/icey-zhang/SuperYOLO.
Mid-level Representation Enhancement and Graph Embedded Uncertainty Suppressing for Facial Expression Recognition
Jul 27, 2022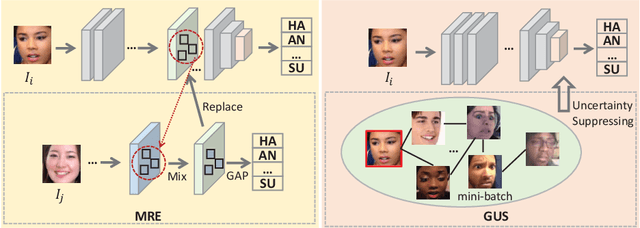
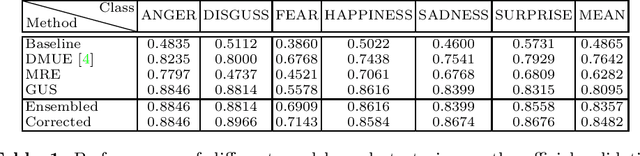
Facial expression is an essential factor in conveying human emotional states and intentions. Although remarkable advancement has been made in facial expression recognition (FER) task, challenges due to large variations of expression patterns and unavoidable data uncertainties still remain. In this paper, we propose mid-level representation enhancement (MRE) and graph embedded uncertainty suppressing (GUS) addressing these issues. On one hand, MRE is introduced to avoid expression representation learning being dominated by a limited number of highly discriminative patterns. On the other hand, GUS is introduced to suppress the feature ambiguity in the representation space. The proposed method not only has stronger generalization capability to handle different variations of expression patterns but also more robustness to capture expression representations. Experimental evaluation on Aff-Wild2 have verified the effectiveness of the proposed method.
Revealing Single Frame Bias for Video-and-Language Learning
Jun 07, 2022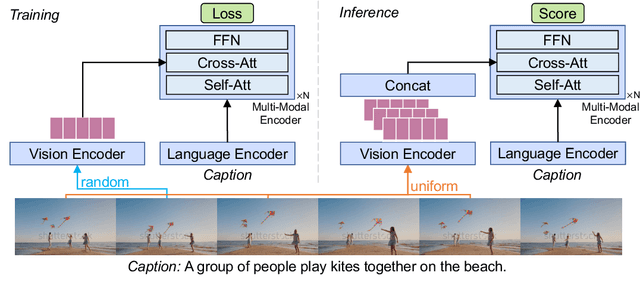
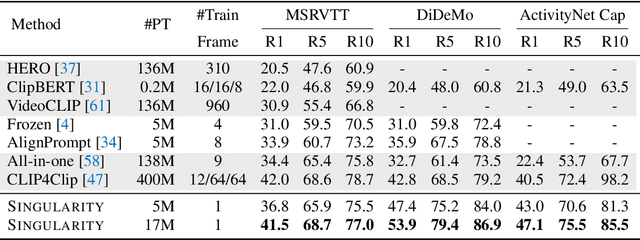
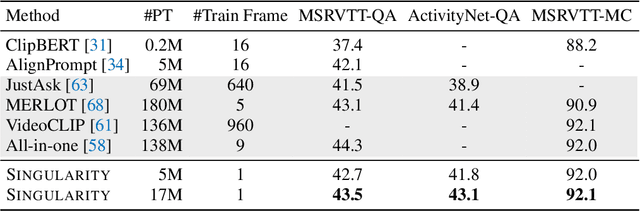

Training an effective video-and-language model intuitively requires multiple frames as model inputs. However, it is unclear whether using multiple frames is beneficial to downstream tasks, and if yes, whether the performance gain is worth the drastically-increased computation and memory costs resulting from using more frames. In this work, we explore single-frame models for video-and-language learning. On a diverse set of video-and-language tasks (including text-to-video retrieval and video question answering), we show the surprising result that, with large-scale pre-training and a proper frame ensemble strategy at inference time, a single-frame trained model that does not consider temporal information can achieve better performance than existing methods that use multiple frames for training. This result reveals the existence of a strong "static appearance bias" in popular video-and-language datasets. Therefore, to allow for a more comprehensive evaluation of video-and-language models, we propose two new retrieval tasks based on existing fine-grained action recognition datasets that encourage temporal modeling. Our code is available at https://github.com/jayleicn/singularity
Language Models with Image Descriptors are Strong Few-Shot Video-Language Learners
May 29, 2022
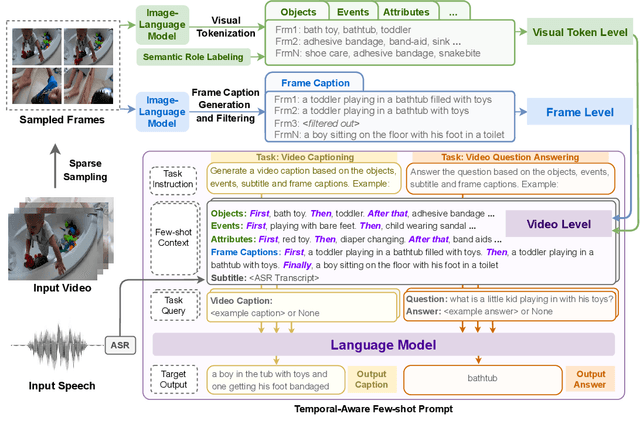
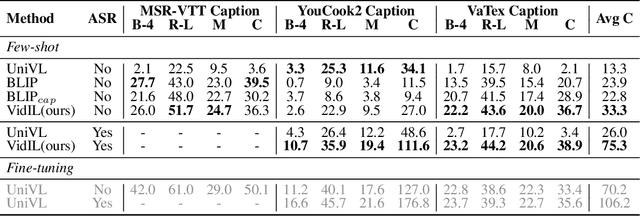

The goal of this work is to build flexible video-language models that can generalize to various video-to-text tasks from few examples, such as domain-specific captioning, question answering, and future event prediction. Existing few-shot video-language learners focus exclusively on the encoder, resulting in the absence of a video-to-text decoder to handle generative tasks. Video captioners have been pretrained on large-scale video-language datasets, but they rely heavily on finetuning and lack the ability to generate text for unseen tasks in a few-shot setting. We propose VidIL, a few-shot Video-language Learner via Image and Language models, which demonstrates strong performance on few-shot video-to-text tasks without the necessity of pretraining or finetuning on any video datasets. We use the image-language models to translate the video content into frame captions, object, attribute, and event phrases, and compose them into a temporal structure template. We then instruct a language model, with a prompt containing a few in-context examples, to generate a target output from the composed content. The flexibility of prompting allows the model to capture any form of text input, such as automatic speech recognition (ASR) transcripts. Our experiments demonstrate the power of language models in understanding videos on a wide variety of video-language tasks, including video captioning, video question answering, video caption retrieval, and video future event prediction. Especially, on video future event prediction, our few-shot model significantly outperforms state-of-the-art supervised models trained on large-scale video datasets. Code and resources are publicly available for research purposes at https://github.com/MikeWangWZHL/VidIL .
ECLIPSE: Efficient Long-range Video Retrieval using Sight and Sound
Apr 06, 2022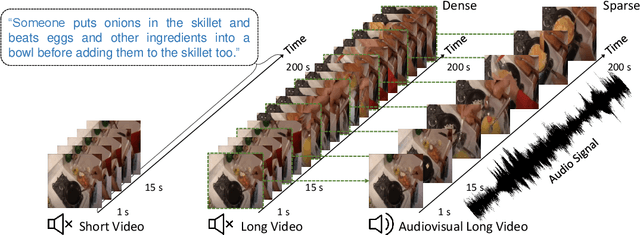
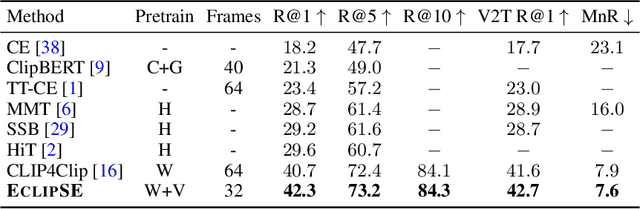
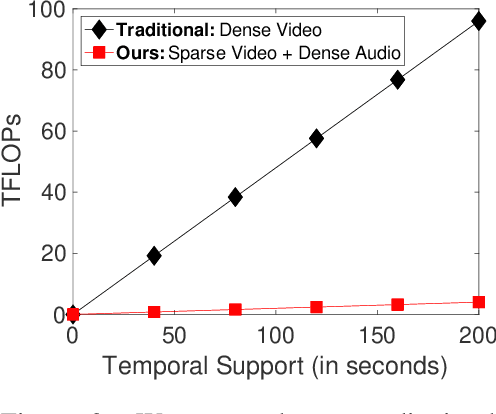
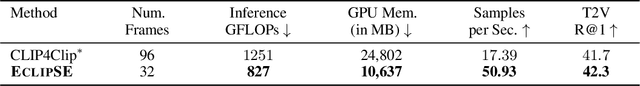
We introduce an audiovisual method for long-range text-to-video retrieval. Unlike previous approaches designed for short video retrieval (e.g., 5-15 seconds in duration), our approach aims to retrieve minute-long videos that capture complex human actions. One challenge of standard video-only approaches is the large computational cost associated with processing hundreds of densely extracted frames from such long videos. To address this issue, we propose to replace parts of the video with compact audio cues that succinctly summarize dynamic audio events and are cheap to process. Our method, named ECLIPSE (Efficient CLIP with Sound Encoding), adapts the popular CLIP model to an audiovisual video setting, by adding a unified audiovisual transformer block that captures complementary cues from the video and audio streams. In addition to being 2.92x faster and 2.34x memory-efficient than long-range video-only approaches, our method also achieves better text-to-video retrieval accuracy on several diverse long-range video datasets such as ActivityNet, QVHighlights, YouCook2, DiDeMo and Charades.