 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSocialNav-SUB: Benchmarking VLMs for Scene Understanding in Social Robot Navigation
Sep 10, 2025Robot navigation in dynamic, human-centered environments requires socially-compliant decisions grounded in robust scene understanding. Recent Vision-Language Models (VLMs) exhibit promising capabilities such as object recognition, common-sense reasoning, and contextual understanding-capabilities that align with the nuanced requirements of social robot navigation. However, it remains unclear whether VLMs can accurately understand complex social navigation scenes (e.g., inferring the spatial-temporal relations among agents and human intentions), which is essential for safe and socially compliant robot navigation. While some recent works have explored the use of VLMs in social robot navigation, no existing work systematically evaluates their ability to meet these necessary conditions. In this paper, we introduce the Social Navigation Scene Understanding Benchmark (SocialNav-SUB), a Visual Question Answering (VQA) dataset and benchmark designed to evaluate VLMs for scene understanding in real-world social robot navigation scenarios. SocialNav-SUB provides a unified framework for evaluating VLMs against human and rule-based baselines across VQA tasks requiring spatial, spatiotemporal, and social reasoning in social robot navigation. Through experiments with state-of-the-art VLMs, we find that while the best-performing VLM achieves an encouraging probability of agreeing with human answers, it still underperforms simpler rule-based approach and human consensus baselines, indicating critical gaps in social scene understanding of current VLMs. Our benchmark sets the stage for further research on foundation models for social robot navigation, offering a framework to explore how VLMs can be tailored to meet real-world social robot navigation needs. An overview of this paper along with the code and data can be found at https://larg.github.io/socialnav-sub .
Robot Air Hockey: A Manipulation Testbed for Robot Learning with Reinforcement Learning
May 06, 2024



Reinforcement Learning is a promising tool for learning complex policies even in fast-moving and object-interactive domains where human teleoperation or hard-coded policies might fail. To effectively reflect this challenging category of tasks, we introduce a dynamic, interactive RL testbed based on robot air hockey. By augmenting air hockey with a large family of tasks ranging from easy tasks like reaching, to challenging ones like pushing a block by hitting it with a puck, as well as goal-based and human-interactive tasks, our testbed allows a varied assessment of RL capabilities. The robot air hockey testbed also supports sim-to-real transfer with three domains: two simulators of increasing fidelity and a real robot system. Using a dataset of demonstration data gathered through two teleoperation systems: a virtualized control environment, and human shadowing, we assess the testbed with behavior cloning, offline RL, and RL from scratch.
Using Machine Learning to Reduce Observational Biases When Detecting New Impacts on Mars
Jul 12, 2022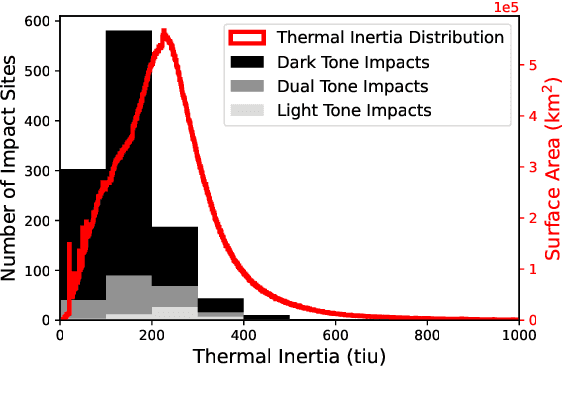
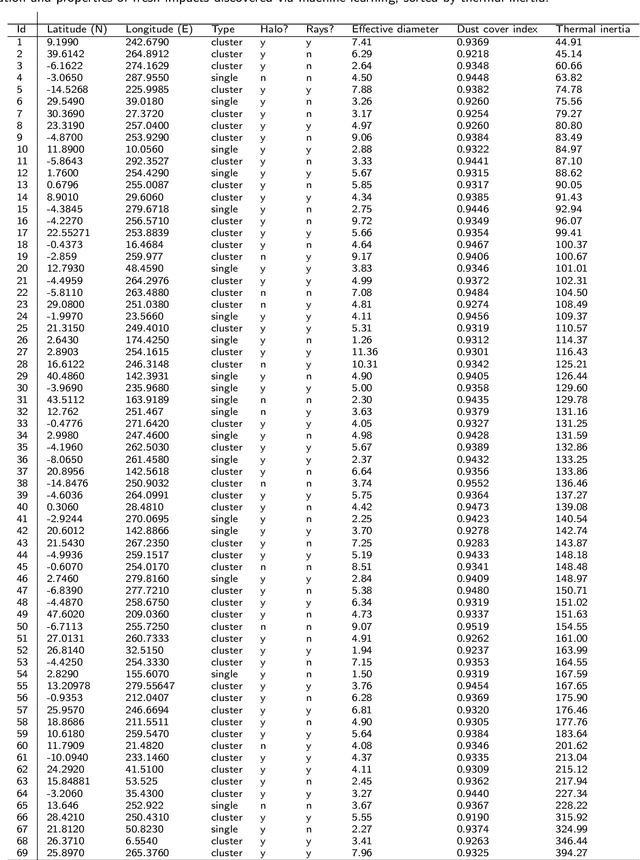
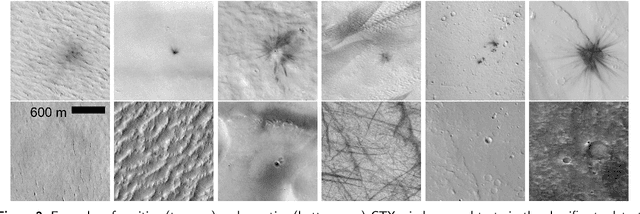
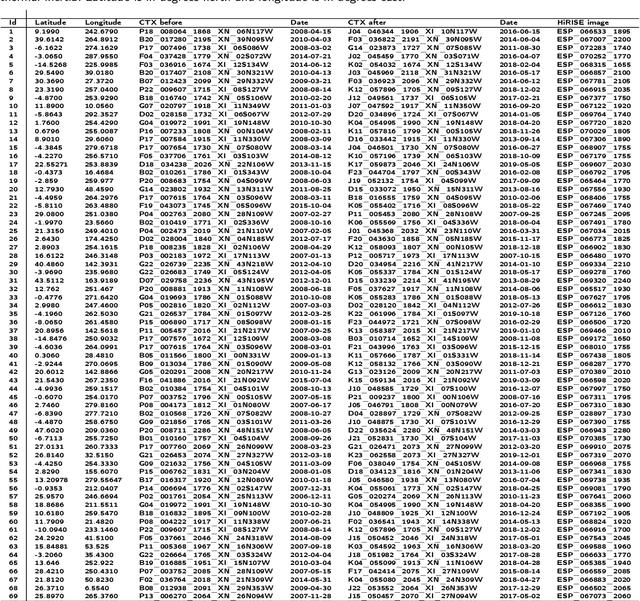
The current inventory of recent (fresh) impacts on Mars shows a strong bias towards areas of low thermal inertia. These areas are generally visually bright, and impacts create dark scours and rays that make them easier to detect. It is expected that impacts occur at a similar rate in areas of higher thermal inertia, but those impacts are under-detected. This study investigates the use of a trained machine learning classifier to increase the detection of fresh impacts on Mars using CTX data. This approach discovered 69 new fresh impacts that have been confirmed with follow-up HiRISE images. We found that examining candidates partitioned by thermal inertia (TI) values, which is only possible due to the large number of machine learning candidates, helps reduce the observational bias and increase the number of known high-TI impacts.
* 17 pages, 10 figures, 2 tables (Author's preprint, accepted version)