 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChat-REC: Towards Interactive and Explainable LLMs-Augmented Recommender System
Apr 04, 2023Large language models (LLMs) have demonstrated their significant potential to be applied for addressing various application tasks. However, traditional recommender systems continue to face great challenges such as poor interactivity and explainability, which actually also hinder their broad deployment in real-world systems. To address these limitations, this paper proposes a novel paradigm called Chat-Rec (ChatGPT Augmented Recommender System) that innovatively augments LLMs for building conversational recommender systems by converting user profiles and historical interactions into prompts. Chat-Rec is demonstrated to be effective in learning user preferences and establishing connections between users and products through in-context learning, which also makes the recommendation process more interactive and explainable. What's more, within the Chat-Rec framework, user's preferences can transfer to different products for cross-domain recommendations, and prompt-based injection of information into LLMs can also handle the cold-start scenarios with new items. In our experiments, Chat-Rec effectively improve the results of top-k recommendations and performs better in zero-shot rating prediction task. Chat-Rec offers a novel approach to improving recommender systems and presents new practical scenarios for the implementation of AIGC (AI generated content) in recommender system studies.
AMC-Net: An Effective Network for Automatic Modulation Classification
Apr 02, 2023Automatic modulation classification (AMC) is a crucial stage in the spectrum management, signal monitoring, and control of wireless communication systems. The accurate classification of the modulation format plays a vital role in the subsequent decoding of the transmitted data. End-to-end deep learning methods have been recently applied to AMC, outperforming traditional feature engineering techniques. However, AMC still has limitations in low signal-to-noise ratio (SNR) environments. To address the drawback, we propose a novel AMC-Net that improves recognition by denoising the input signal in the frequency domain while performing multi-scale and effective feature extraction. Experiments on two representative datasets demonstrate that our model performs better in efficiency and effectiveness than the most current methods.
Immune Defense: A Novel Adversarial Defense Mechanism for Preventing the Generation of Adversarial Examples
Mar 08, 2023



The vulnerability of Deep Neural Networks (DNNs) to adversarial examples has been confirmed. Existing adversarial defenses primarily aim at preventing adversarial examples from attacking DNNs successfully, rather than preventing their generation. If the generation of adversarial examples is unregulated, images within reach are no longer secure and pose a threat to non-robust DNNs. Although gradient obfuscation attempts to address this issue, it has been shown to be circumventable. Therefore, we propose a novel adversarial defense mechanism, which is referred to as immune defense and is the example-based pre-defense. This mechanism applies carefully designed quasi-imperceptible perturbations to the raw images to prevent the generation of adversarial examples for the raw images, and thereby protecting both images and DNNs. These perturbed images are referred to as Immune Examples (IEs). In the white-box immune defense, we provide a gradient-based and an optimization-based approach, respectively. Additionally, the more complex black-box immune defense is taken into consideration. We propose Masked Gradient Sign Descent (MGSD) to reduce approximation error and stabilize the update to improve the transferability of IEs and thereby ensure their effectiveness against black-box adversarial attacks. The experimental results demonstrate that the optimization-based approach has superior performance and better visual quality in white-box immune defense. In contrast, the gradient-based approach has stronger transferability and the proposed MGSD significantly improve the transferability of baselines.
Breaking the Lower Bound with (Little) Structure: Acceleration in Non-Convex Stochastic Optimization with Heavy-Tailed Noise
Feb 14, 2023We consider the stochastic optimization problem with smooth but not necessarily convex objectives in the heavy-tailed noise regime, where the stochastic gradient's noise is assumed to have bounded $p$th moment ($p\in(1,2]$). Zhang et al. (2020) is the first to prove the $\Omega(T^{\frac{1-p}{3p-2}})$ lower bound for convergence (in expectation) and provides a simple clipping algorithm that matches this optimal rate. Cutkosky and Mehta (2021) proposes another algorithm, which is shown to achieve the nearly optimal high-probability convergence guarantee $O(\log(T/\delta)T^{\frac{1-p}{3p-2}})$, where $\delta$ is the probability of failure. However, this desirable guarantee is only established under the additional assumption that the stochastic gradient itself is bounded in $p$th moment, which fails to hold even for quadratic objectives and centered Gaussian noise. In this work, we first improve the analysis of the algorithm in Cutkosky and Mehta (2021) to obtain the same nearly optimal high-probability convergence rate $O(\log(T/\delta)T^{\frac{1-p}{3p-2}})$, without the above-mentioned restrictive assumption. Next, and curiously, we show that one can achieve a faster rate than that dictated by the lower bound $\Omega(T^{\frac{1-p}{3p-2}})$ with only a tiny bit of structure, i.e., when the objective function $F(x)$ is assumed to be in the form of $\mathbb{E}_{\Xi\sim\mathcal{D}}[f(x,\Xi)]$, arguably the most widely applicable class of stochastic optimization problems. For this class of problems, we propose the first variance-reduced accelerated algorithm and establish that it guarantees a high-probability convergence rate of $O(\log(T/\delta)T^{\frac{1-p}{2p-1}})$ under a mild condition, which is faster than $\Omega(T^{\frac{1-p}{3p-2}})$. Notably, even when specialized to the finite-variance case, our result yields the (near-)optimal high-probability rate $O(\log(T/\delta)T^{-1/3})$.
ConsRec: Learning Consensus Behind Interactions for Group Recommendation
Feb 07, 2023
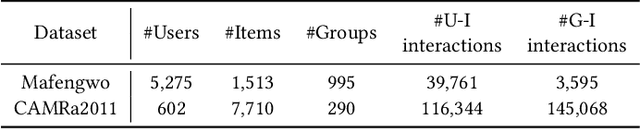


Since group activities have become very common in daily life, there is an urgent demand for generating recommendations for a group of users, referred to as group recommendation task. Existing group recommendation methods usually infer groups' preferences via aggregating diverse members' interests. Actually, groups' ultimate choice involves compromises between members, and finally, an agreement can be reached. However, existing individual information aggregation lacks a holistic group-level consideration, failing to capture the consensus information. Besides, their specific aggregation strategies either suffer from high computational costs or become too coarse-grained to make precise predictions. To solve the aforementioned limitations, in this paper, we focus on exploring consensus behind group behavior data. To comprehensively capture the group consensus, we innovatively design three distinct views which provide mutually complementary information to enable multi-view learning, including member-level aggregation, item-level tastes, and group-level inherent preferences. To integrate and balance the multi-view information, an adaptive fusion component is further proposed. As to member-level aggregation, different from existing linear or attentive strategies, we design a novel hypergraph neural network that allows for efficient hypergraph convolutional operations to generate expressive member-level aggregation. We evaluate our ConsRec on two real-world datasets and experimental results show that our model outperforms state-of-the-art methods. An extensive case study also verifies the effectiveness of consensus modeling.
HumanMAC: Masked Motion Completion for Human Motion Prediction
Feb 07, 2023Human motion prediction is a classical problem in computer vision and computer graphics, which has a wide range of practical applications. Previous effects achieve great empirical performance based on an encoding-decoding fashion. The methods of this fashion work by first encoding previous motions to latent representations and then decoding the latent representations into predicted motions. However, in practice, they are still unsatisfactory due to several issues, including complicated loss constraints, cumbersome training processes, and scarce switch of different categories of motions in prediction. In this paper, to address the above issues, we jump out of the foregoing fashion and propose a novel framework from a new perspective. Specifically, our framework works in a denoising diffusion style. In the training stage, we learn a motion diffusion model that generates motions from random noise. In the inference stage, with a denoising procedure, we make motion prediction conditioning on observed motions to output more continuous and controllable predictions. The proposed framework enjoys promising algorithmic properties, which only needs one loss in optimization and is trained in an end-to-end manner. Additionally, it accomplishes the switch of different categories of motions effectively, which is significant in realistic tasks, \textit{e.g.}, the animation task. Comprehensive experiments on benchmarks confirm the superiority of the proposed framework. The project page is available at \url{https://lhchen.top/Human-MAC}.
Deep Dynamic Scene Deblurring from Optical Flow
Jan 18, 2023



Deblurring can not only provide visually more pleasant pictures and make photography more convenient, but also can improve the performance of objection detection as well as tracking. However, removing dynamic scene blur from images is a non-trivial task as it is difficult to model the non-uniform blur mathematically. Several methods first use single or multiple images to estimate optical flow (which is treated as an approximation of blur kernels) and then adopt non-blind deblurring algorithms to reconstruct the sharp images. However, these methods cannot be trained in an end-to-end manner and are usually computationally expensive. In this paper, we explore optical flow to remove dynamic scene blur by using the multi-scale spatially variant recurrent neural network (RNN). We utilize FlowNets to estimate optical flow from two consecutive images in different scales. The estimated optical flow provides the RNN weights in different scales so that the weights can better help RNNs to remove blur in the feature spaces. Finally, we develop a convolutional neural network (CNN) to restore the sharp images from the deblurred features. Both quantitative and qualitative evaluations on the benchmark datasets demonstrate that the proposed method performs favorably against state-of-the-art algorithms in terms of accuracy, speed, and model size.
Revisiting the Linear-Programming Framework for Offline RL with General Function Approximation
Dec 28, 2022Offline reinforcement learning (RL) concerns pursuing an optimal policy for sequential decision-making from a pre-collected dataset, without further interaction with the environment. Recent theoretical progress has focused on developing sample-efficient offline RL algorithms with various relaxed assumptions on data coverage and function approximators, especially to handle the case with excessively large state-action spaces. Among them, the framework based on the linear-programming (LP) reformulation of Markov decision processes has shown promise: it enables sample-efficient offline RL with function approximation, under only partial data coverage and realizability assumptions on the function classes, with favorable computational tractability. In this work, we revisit the LP framework for offline RL, and advance the existing results in several aspects, relaxing certain assumptions and achieving optimal statistical rates in terms of sample size. Our key enabler is to introduce proper constraints in the reformulation, instead of using any regularization as in the literature, sometimes also with careful choices of the function classes and initial state distributions. We hope our insights further advocate the study of the LP framework, as well as the induced primal-dual minimax optimization, in offline RL.
Mutimodal Ranking Optimization for Heterogeneous Face Re-identification
Dec 11, 2022



Heterogeneous face re-identification, namely matching heterogeneous faces across disjoint visible light (VIS) and near-infrared (NIR) cameras, has become an important problem in video surveillance application. However, the large domain discrepancy between heterogeneous NIR-VIS faces makes the performance of face re-identification degraded dramatically. To solve this problem, a multimodal fusion ranking optimization algorithm for heterogeneous face re-identification is proposed in this paper. Firstly, we design a heterogeneous face translation network to obtain multimodal face pairs, including NIR-VIS/NIR-NIR/VIS-VIS face pairs, through mutual transformation between NIR-VIS faces. Secondly, we propose linear and non-linear fusion strategies to aggregate initial ranking lists of multimodal face pairs and acquire the optimized re-ranked list based on modal complementarity. The experimental results show that the proposed multimodal fusion ranking optimization algorithm can effectively utilize the complementarity and outperforms some relative methods on the SCface dataset.
Robot Kinematics: Motion, Kinematics and Dynamics
Nov 28, 2022This is a follow-up tutorial article of our previous article entitled "Robot Basics: Representation, Rotation and Velocity". For better understanding of the topics covered in this articles, we recommend the readers to first read our previous tutorial article on robot basics. Specifically, in this article, we will cover some more advanced topics on robot kinematics, including robot motion, forward kinematics, inverse kinematics, and robot dynamics. For the topics, terminologies and notations introduced in the previous article, we will use them directly without re-introducing them again in this article. Also similar to the previous article, math and formulas will also be heavily used in this article as well (hope the readers are well prepared for the upcoming math bomb). After reading this article, readers should be able to have a deeper understanding about how robot motion, kinematics and dynamics. As to some more advanced topics about robot control, we will introduce them in the following tutorial articles for readers instead.