 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCosFly: Plan in the Matrix, Fly in the World
May 18, 2026We present CosFly, a box-structured planning and multimodal simulation pipeline for aerial tracking, together with CosFly-Track, a large-scale UAV dataset for dynamic target tracking across diverse environments including urban centers, highways, rural landscapes, forests, and coastal towns. In our current implementation on CARLA, CosFly provides a modular 7-step construction pipeline that converts complex 3D worlds into structured obstacle representations for planning, then projects the resulting trajectories back into multi-modal sensor data -- including RGB images, high-precision depth maps, and semantic segmentation masks -- paired with natural language navigation instructions. A key feature is the support for configurable fixed-FOV zoom levels (one FOV setting drawn per trajectory and held constant throughout), enabling simulation of various focal lengths through camera-intrinsic adjustments. The pipeline covers the complete workflow from 3D map export through grid simplification, pedestrian and drone trajectory planning, multi-modal rendering with 6-DOF pose annotations, quality inspection, and teacher-student caption generation. We analyze two trajectory-planning paradigms for aerial target tracking: a conventional two-stage pipeline with front-end candidate generation and backend refinement, and a direct gradient-based formulation that optimizes multiple tracking constraints in a single objective. The public CosFly-Track release contains 250 validated trajectories and approximately 100,000 rendered images with complete 6-DOF drone pose annotations (position x, y, z and orientation yaw, pitch, roll). Together, the pipeline and dataset establish a scalable foundation for aerial-ground collaborative research, supporting dynamic target tracking, UAV navigation, and multi-modal perception across diverse environments.
Vision-and-Language Navigation for UAVs: Progress, Challenges, and a Research Roadmap
Apr 15, 2026Vision-and-Language Navigation for Unmanned Aerial Vehicles (UAV-VLN) represents a pivotal challenge in embodied artificial intelligence, focused on enabling UAVs to interpret high-level human commands and execute long-horizon tasks in complex 3D environments. This paper provides a comprehensive and structured survey of the field, from its formal task definition to the current state of the art. We establish a methodological taxonomy that charts the technological evolution from early modular and deep learning approaches to contemporary agentic systems driven by large foundation models, including Vision-Language Models (VLMs), Vision-Language-Action (VLA) models, and the emerging integration of generative world models with VLA architectures for physically-grounded reasoning. The survey systematically reviews the ecosystem of essential resources simulators, datasets, and evaluation metrics that facilitates standardized research. Furthermore, we conduct a critical analysis of the primary challenges impeding real-world deployment: the simulation-to-reality gap, robust perception in dynamic outdoor settings, reasoning with linguistic ambiguity, and the efficient deployment of large models on resource-constrained hardware. By synthesizing current benchmarks and limitations, this survey concludes by proposing a forward-looking research roadmap to guide future inquiry into key frontiers such as multi-agent swarm coordination and air-ground collaborative robotics.
Deep Blind Video Super-resolution
Mar 10, 2020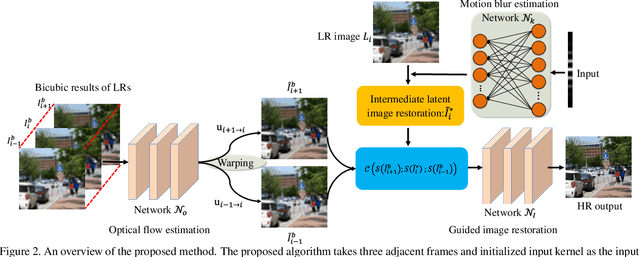
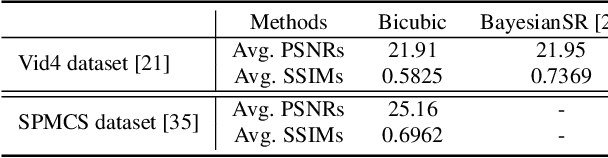


Existing video super-resolution (SR) algorithms usually assume that the blur kernels in the degradation process are known and do not model the blur kernels in the restoration. However, this assumption does not hold for video SR and usually leads to over-smoothed super-resolved images. In this paper, we propose a deep convolutional neural network (CNN) model to solve video SR by a blur kernel modeling approach. The proposed deep CNN model consists of motion blur estimation, motion estimation, and latent image restoration modules. The motion blur estimation module is used to provide reliable blur kernels. With the estimated blur kernel, we develop an image deconvolution method based on the image formation model of video SR to generate intermediate latent images so that some sharp image contents can be restored well. However, the generated intermediate latent images may contain artifacts. To generate high-quality images, we use the motion estimation module to explore the information from adjacent frames, where the motion estimation can constrain the deep CNN model for better image restoration. We show that the proposed algorithm is able to generate clearer images with finer structural details. Extensive experimental results show that the proposed algorithm performs favorably against state-of-the-art methods.