 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge2D Supervised Monocular 3D Object Detection by Global-to-Local 3D Reconstruction
Jun 08, 2023With the advent of the big model era, the demand for data has become more important. Especially in monocular 3D object detection, expensive manual annotations potentially limit further developments. Existing works have investigated weakly supervised algorithms with the help of LiDAR modality to generate 3D pseudo labels, which cannot be applied to ordinary videos. In this paper, we propose a novel paradigm, termed as BA$^2$-Det, leveraging the idea of global-to-local 3D reconstruction for 2D supervised monocular 3D object detection. Specifically, we recover 3D structures from monocular videos by scene-level global reconstruction with global bundle adjustment (BA) and obtain object clusters by the DoubleClustering algorithm. Learning from completely reconstructed objects in global BA, GBA-Learner predicts pseudo labels for occluded objects. Finally, we train an LBA-Learner with object-centric local BA to generalize the generated 3D pseudo labels to moving objects. Experiments on the large-scale Waymo Open Dataset show that the performance of BA$^2$-Det is on par with the fully-supervised BA-Det trained with 10% videos and even outperforms some pioneer fully-supervised methods. We also show the great potential of BA$^2$-Det for detecting open-set 3D objects in complex scenes. The code will be made available. Project page: https://ba2det.site .
You Only Need Two Detectors to Achieve Multi-Modal 3D Multi-Object Tracking
Apr 18, 2023



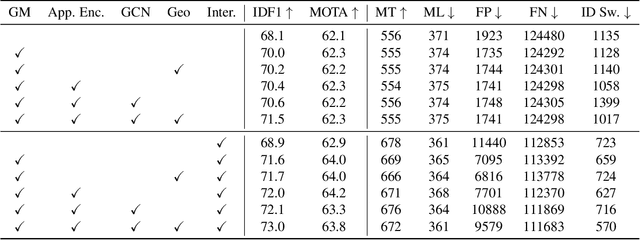
Firstly, a new multi-object tracking framework is proposed in this paper based on multi-modal fusion. By integrating object detection and multi-object tracking into the same model, this framework avoids the complex data association process in the classical TBD paradigm, and requires no additional training. Secondly, confidence of historical trajectory regression is explored, possible states of a trajectory in the current frame (weak object or strong object) are analyzed and a confidence fusion module is designed to guide non-maximum suppression of trajectory and detection for ordered association. Finally, extensive experiments are conducted on the KITTI and Waymo datasets. The results show that the proposed method can achieve robust tracking by using only two modal detectors and it is more accurate than many of the latest TBD paradigm-based multi-modal tracking methods. The source codes of the proposed method are available at https://github.com/wangxiyang2022/YONTD-MOT
3D Video Object Detection with Learnable Object-Centric Global Optimization
Mar 27, 2023We explore long-term temporal visual correspondence-based optimization for 3D video object detection in this work. Visual correspondence refers to one-to-one mappings for pixels across multiple images. Correspondence-based optimization is the cornerstone for 3D scene reconstruction but is less studied in 3D video object detection, because moving objects violate multi-view geometry constraints and are treated as outliers during scene reconstruction. We address this issue by treating objects as first-class citizens during correspondence-based optimization. In this work, we propose BA-Det, an end-to-end optimizable object detector with object-centric temporal correspondence learning and featuremetric object bundle adjustment. Empirically, we verify the effectiveness and efficiency of BA-Det for multiple baseline 3D detectors under various setups. Our BA-Det achieves SOTA performance on the large-scale Waymo Open Dataset (WOD) with only marginal computation cost. Our code is available at https://github.com/jiaweihe1996/BA-Det.
Learnable Graph Matching: A Practical Paradigm for Data Association
Mar 27, 2023



Data association is at the core of many computer vision tasks, e.g., multiple object tracking, image matching, and point cloud registration. Existing methods usually solve the data association problem by network flow optimization, bipartite matching, or end-to-end learning directly. Despite their popularity, we find some defects of the current solutions: they mostly ignore the intra-view context information; besides, they either train deep association models in an end-to-end way and hardly utilize the advantage of optimization-based assignment methods, or only use an off-the-shelf neural network to extract features. In this paper, we propose a general learnable graph matching method to address these issues. Especially, we model the intra-view relationships as an undirected graph. Then data association turns into a general graph matching problem between graphs. Furthermore, to make optimization end-to-end differentiable, we relax the original graph matching problem into continuous quadratic programming and then incorporate training into a deep graph neural network with KKT conditions and implicit function theorem. In MOT task, our method achieves state-of-the-art performance on several MOT datasets. For image matching, our method outperforms state-of-the-art methods with half training data and iterations on a popular indoor dataset, ScanNet. Code will be available at https://github.com/jiaweihe1996/GMTracker.
3D Multi-Object Tracking Based on Uncertainty-Guided Data Association
Mar 03, 2023



In the existing literature, most 3D multi-object tracking algorithms based on the tracking-by-detection framework employed deterministic tracks and detections for similarity calculation in the data association stage. Namely, the inherent uncertainties existing in tracks and detections are overlooked. In this work, we discard the commonly used deterministic tracks and deterministic detections for data association, instead, we propose to model tracks and detections as random vectors in which uncertainties are taken into account. Then, based on the Jensen-Shannon divergence, the similarity between two multidimensional distributions, i.e. track and detection, is evaluated for data association purposes. Lastly, the level of track uncertainty is incorporated in our cost function design to guide the data association process. Comparative experiments have been conducted on two typical datasets, KITTI and nuScenes, and the results indicated that our proposed method outperformed the compared state-of-the-art 3D tracking algorithms. For the benefit of the community, our code has been made available at https://github.com/hejiawei2023/UG3DMOT.
Densely Constrained Depth Estimator for Monocular 3D Object Detection
Jul 21, 2022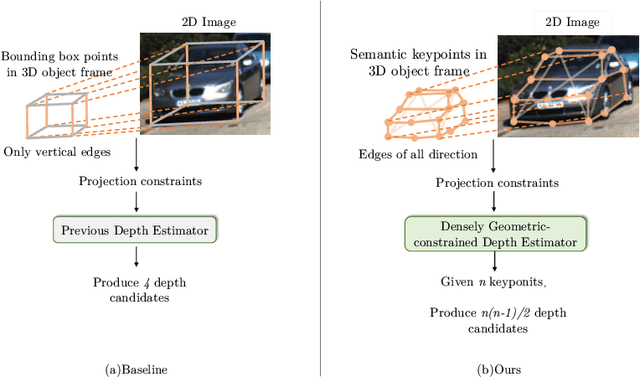
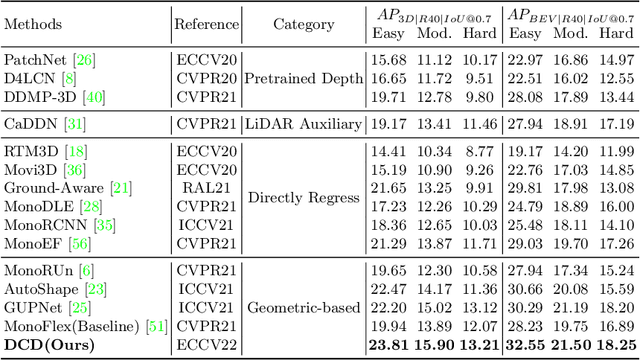
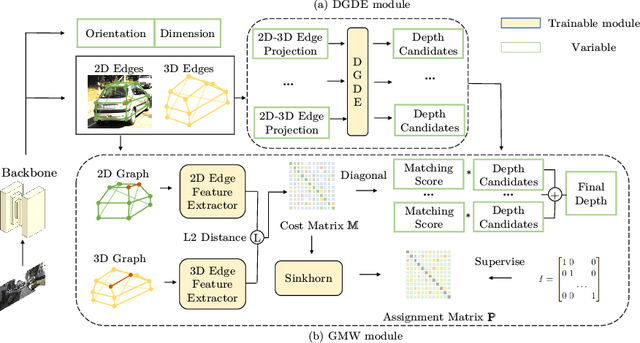
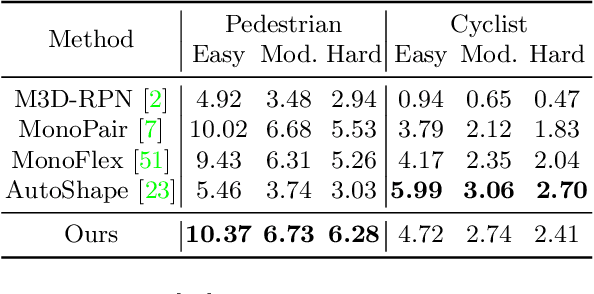
Estimating accurate 3D locations of objects from monocular images is a challenging problem because of lacking depth. Previous work shows that utilizing the object's keypoint projection constraints to estimate multiple depth candidates boosts the detection performance. However, the existing methods can only utilize vertical edges as projection constraints for depth estimation. So these methods only use a small number of projection constraints and produce insufficient depth candidates, leading to inaccurate depth estimation. In this paper, we propose a method that utilizes dense projection constraints from edges of any direction. In this way, we employ much more projection constraints and produce considerable depth candidates. Besides, we present a graph matching weighting module to merge the depth candidates. The proposed method DCD (Densely Constrained Detector) achieves state-of-the-art performance on the KITTI and WOD benchmarks. Code is released at https://github.com/BraveGroup/DCD.
DeepFusionMOT: A 3D Multi-Object Tracking Framework Based on Camera-LiDAR Fusion with Deep Association
Feb 24, 2022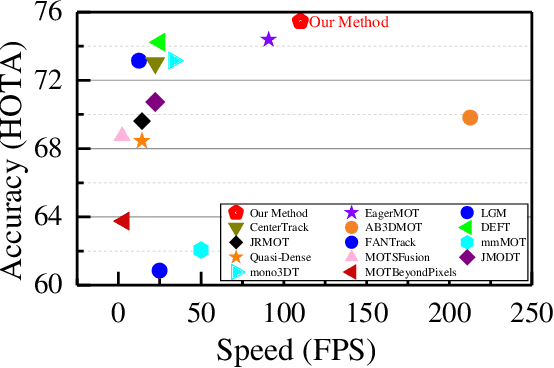
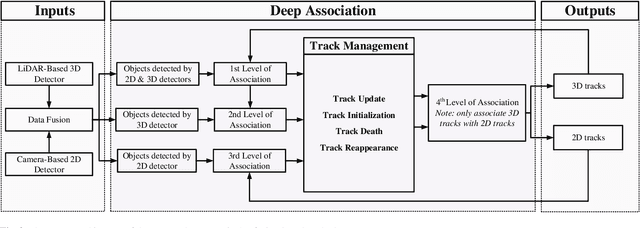
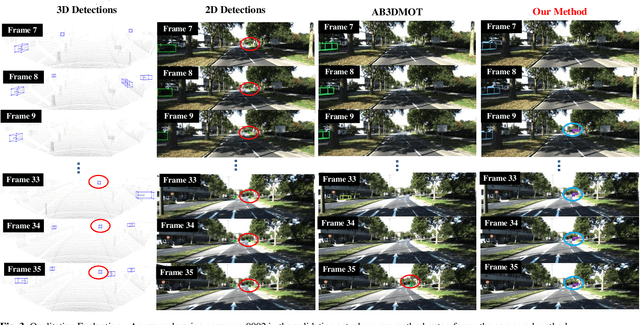

In the recent literature, on the one hand, many 3D multi-object tracking (MOT) works have focused on tracking accuracy and neglected computation speed, commonly by designing rather complex cost functions and feature extractors. On the other hand, some methods have focused too much on computation speed at the expense of tracking accuracy. In view of these issues, this paper proposes a robust and fast camera-LiDAR fusion-based MOT method that achieves a good trade-off between accuracy and speed. Relying on the characteristics of camera and LiDAR sensors, an effective deep association mechanism is designed and embedded in the proposed MOT method. This association mechanism realizes tracking of an object in a 2D domain when the object is far away and only detected by the camera, and updating of the 2D trajectory with 3D information obtained when the object appears in the LiDAR field of view to achieve a smooth fusion of 2D and 3D trajectories. Extensive experiments based on the KITTI dataset indicate that our proposed method presents obvious advantages over the state-of-the-art MOT methods in terms of both tracking accuracy and processing speed. Our code is made publicly available for the benefit of the community
Piggyback GAN: Efficient Lifelong Learning for Image Conditioned Generation
Apr 24, 2021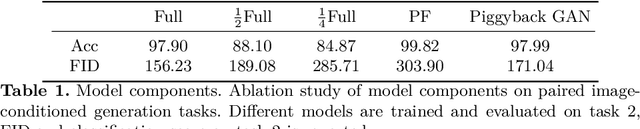
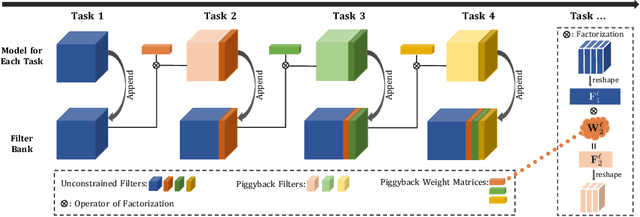
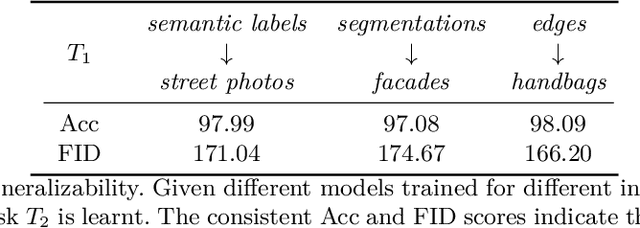
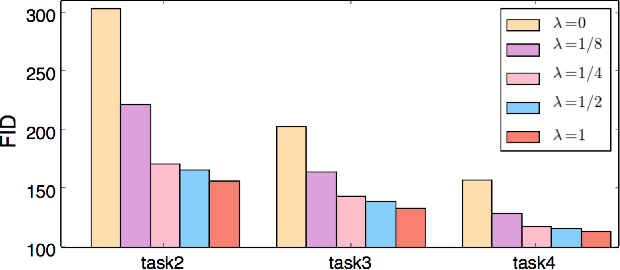
Humans accumulate knowledge in a lifelong fashion. Modern deep neural networks, on the other hand, are susceptible to catastrophic forgetting: when adapted to perform new tasks, they often fail to preserve their performance on previously learned tasks. Given a sequence of tasks, a naive approach addressing catastrophic forgetting is to train a separate standalone model for each task, which scales the total number of parameters drastically without efficiently utilizing previous models. In contrast, we propose a parameter efficient framework, Piggyback GAN, which learns the current task by building a set of convolutional and deconvolutional filters that are factorized into filters of the models trained on previous tasks. For the current task, our model achieves high generation quality on par with a standalone model at a lower number of parameters. For previous tasks, our model can also preserve generation quality since the filters for previous tasks are not altered. We validate Piggyback GAN on various image-conditioned generation tasks across different domains, and provide qualitative and quantitative results to show that the proposed approach can address catastrophic forgetting effectively and efficiently.
Learnable Graph Matching: Incorporating Graph Partitioning with Deep Feature Learning for Multiple Object Tracking
Mar 30, 2021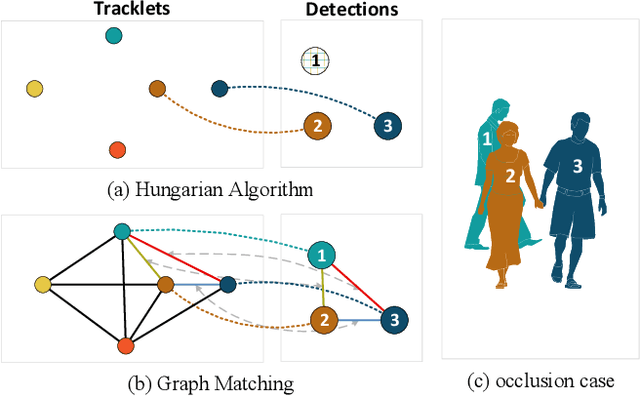
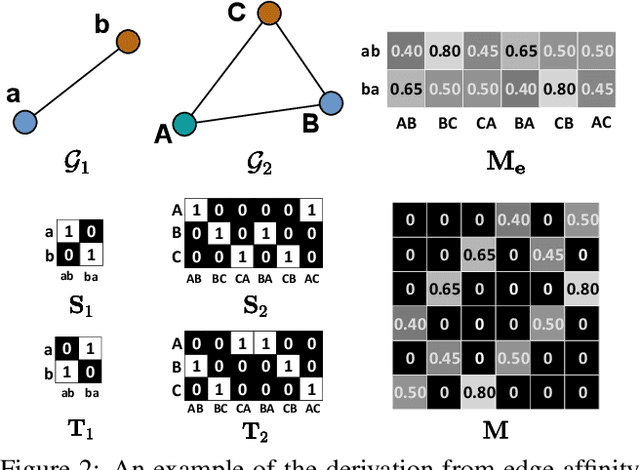

Data association across frames is at the core of Multiple Object Tracking (MOT) task. This problem is usually solved by a traditional graph-based optimization or directly learned via deep learning. Despite their popularity, we find some points worth studying in current paradigm: 1) Existing methods mostly ignore the context information among tracklets and intra-frame detections, which makes the tracker hard to survive in challenging cases like severe occlusion. 2) The end-to-end association methods solely rely on the data fitting power of deep neural networks, while they hardly utilize the advantage of optimization-based assignment methods. 3) The graph-based optimization methods mostly utilize a separate neural network to extract features, which brings the inconsistency between training and inference. Therefore, in this paper we propose a novel learnable graph matching method to address these issues. Briefly speaking, we model the relationships between tracklets and the intra-frame detections as a general undirected graph. Then the association problem turns into a general graph matching between tracklet graph and detection graph. Furthermore, to make the optimization end-to-end differentiable, we relax the original graph matching into continuous quadratic programming and then incorporate the training of it into a deep graph network with the help of the implicit function theorem. Lastly, our method GMTracker, achieves state-of-the-art performance on several standard MOT datasets. Our code will be available at https://github.com/jiaweihe1996/GMTracker .
Variational Selective Autoencoder: Learning from Partially-Observed Heterogeneous Data
Feb 25, 2021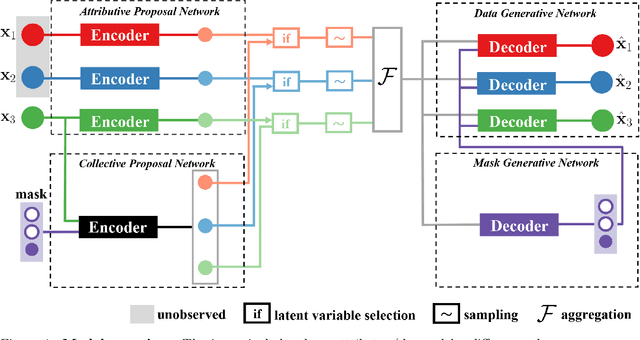
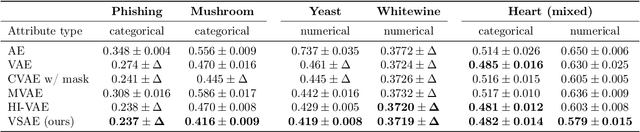
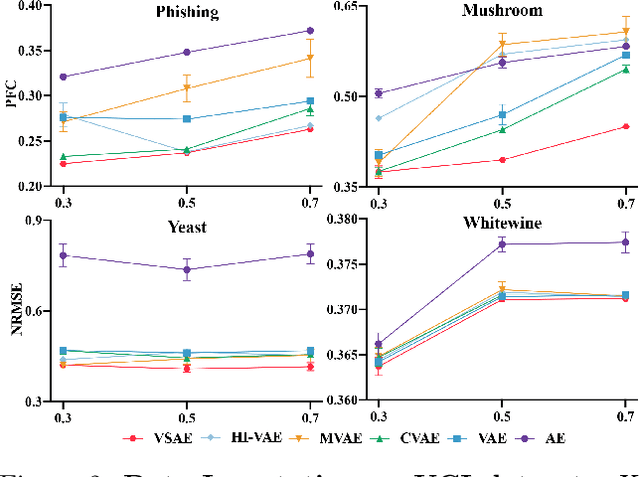
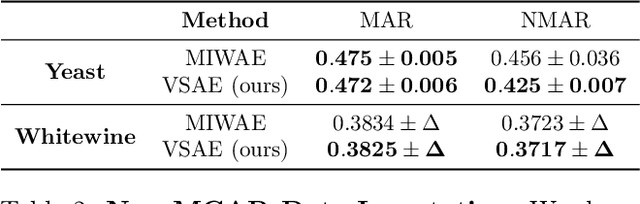
Learning from heterogeneous data poses challenges such as combining data from various sources and of different types. Meanwhile, heterogeneous data are often associated with missingness in real-world applications due to heterogeneity and noise of input sources. In this work, we propose the variational selective autoencoder (VSAE), a general framework to learn representations from partially-observed heterogeneous data. VSAE learns the latent dependencies in heterogeneous data by modeling the joint distribution of observed data, unobserved data, and the imputation mask which represents how the data are missing. It results in a unified model for various downstream tasks including data generation and imputation. Evaluation on both low-dimensional and high-dimensional heterogeneous datasets for these two tasks shows improvement over state-of-the-art models.