 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnveiling Redundancy in Diffusion Transformers (DiTs): A Systematic Study
Nov 18, 2024The increased model capacity of Diffusion Transformers (DiTs) and the demand for generating higher resolutions of images and videos have led to a significant rise in inference latency, impacting real-time performance adversely. While prior research has highlighted the presence of high similarity in activation values between adjacent diffusion steps (referred to as redundancy) and proposed various caching mechanisms to mitigate computational overhead, the exploration of redundancy in existing literature remains limited, with findings often not generalizable across different DiT models. This study aims to address this gap by conducting a comprehensive investigation into redundancy across a broad spectrum of mainstream DiT models. Our experimental analysis reveals substantial variations in the distribution of redundancy across diffusion steps among different DiT models. Interestingly, within a single model, the redundancy distribution remains stable regardless of variations in input prompts, step counts, or scheduling strategies. Given the lack of a consistent pattern across diverse models, caching strategies designed for a specific group of models may not easily transfer to others. To overcome this challenge, we introduce a tool for analyzing the redundancy of individual models, enabling subsequent research to develop tailored caching strategies for specific model architectures. The project is publicly available at https://github.com/xdit-project/DiTCacheAnalysis.
xDiT: an Inference Engine for Diffusion Transformers (DiTs) with Massive Parallelism
Nov 04, 2024



Diffusion models are pivotal for generating high-quality images and videos. Inspired by the success of OpenAI's Sora, the backbone of diffusion models is evolving from U-Net to Transformer, known as Diffusion Transformers (DiTs). However, generating high-quality content necessitates longer sequence lengths, exponentially increasing the computation required for the attention mechanism, and escalating DiTs inference latency. Parallel inference is essential for real-time DiTs deployments, but relying on a single parallel method is impractical due to poor scalability at large scales. This paper introduces xDiT, a comprehensive parallel inference engine for DiTs. After thoroughly investigating existing DiTs parallel approaches, xDiT chooses Sequence Parallel (SP) and PipeFusion, a novel Patch-level Pipeline Parallel method, as intra-image parallel strategies, alongside CFG parallel for inter-image parallelism. xDiT can flexibly combine these parallel approaches in a hybrid manner, offering a robust and scalable solution. Experimental results on two 8xL40 GPUs (PCIe) nodes interconnected by Ethernet and an 8xA100 (NVLink) node showcase xDiT's exceptional scalability across five state-of-the-art DiTs. Notably, we are the first to demonstrate DiTs scalability on Ethernet-connected GPU clusters. xDiT is available at https://github.com/xdit-project/xDiT.
PipeFusion: Displaced Patch Pipeline Parallelism for Inference of Diffusion Transformer Models
May 23, 2024This paper introduces PipeFusion, a novel approach that harnesses multi-GPU parallelism to address the high computational and latency challenges of generating high-resolution images with diffusion transformers (DiT) models. PipeFusion splits images into patches and distributes the network layers across multiple devices. It employs a pipeline parallel manner to orchestrate communication and computations. By leveraging the high similarity between the input from adjacent diffusion steps, PipeFusion eliminates the waiting time in the pipeline by reusing the one-step stale feature maps to provide context for the current step. Our experiments demonstrate that it can generate higher image resolution where existing DiT parallel approaches meet OOM. PipeFusion significantly reduces the required communication bandwidth, enabling DiT inference to be hosted on GPUs connected via PCIe rather than the more costly NVLink infrastructure, which substantially lowers the overall operational expenses for serving DiT models. Our code is publicly available at https://github.com/PipeFusion/PipeFusion.
A Unified Sequence Parallelism Approach for Long Context Generative AI
May 15, 2024Sequence parallelism (SP), which divides the sequence dimension of input tensors across multiple computational devices, is becoming key to unlocking the long-context capabilities of generative AI models. This paper investigates the state-of-the-art SP approaches, i.e. DeepSpeed-Ulysses and Ring-Attention, and proposes a unified SP approach, which is more robust to transformer model architectures and network hardware topology. This paper compares the communication and memory cost of SP and existing parallelism, including data/tensor/zero/expert/pipeline parallelism, and discusses the best practices for designing hybrid 4D parallelism involving SP. We achieved 86% MFU on two 8xA800 nodes using SP for sequence length 208K for the LLAMA3-8B model. Our code is publicly available on \url{https://github.com/feifeibear/long-context-attention}.
AutoChunk: Automated Activation Chunk for Memory-Efficient Long Sequence Inference
Jan 19, 2024



Large deep learning models have achieved impressive performance across a range of applications. However, their large memory requirements, including parameter memory and activation memory, have become a significant challenge for their practical serving. While existing methods mainly address parameter memory, the importance of activation memory has been overlooked. Especially for long input sequences, activation memory is expected to experience a significant exponential growth as the length of sequences increases. In this approach, we propose AutoChunk, an automatic and adaptive compiler system that efficiently reduces activation memory for long sequence inference by chunk strategies. The proposed system generates chunk plans by optimizing through multiple stages. In each stage, the chunk search pass explores all possible chunk candidates and the chunk selection pass identifies the optimal one. At runtime, AutoChunk employs code generation to automatically apply chunk strategies. The experiments demonstrate that AutoChunk can reduce over 80\% of activation memory while maintaining speed loss within 10%, extend max sequence length by 3.2x to 11.7x, and outperform state-of-the-art methods by a large margin.
Colossal-Auto: Unified Automation of Parallelization and Activation Checkpoint for Large-scale Models
Feb 22, 2023



In recent years, large-scale models have demonstrated state-of-the-art performance across various domains. However, training such models requires various techniques to address the problem of limited computing power and memory on devices such as GPUs. Some commonly used techniques include pipeline parallelism, tensor parallelism, and activation checkpointing. While existing works have focused on finding efficient distributed execution plans (Zheng et al. 2022) and activation checkpoint scheduling (Herrmann et al. 2019, Beaumont et al. 2021}, there has been no method proposed to optimize these two plans jointly. Moreover, ahead-of-time compilation relies heavily on accurate memory and computing overhead estimation, which is often time-consuming and misleading. Existing training systems and machine learning pipelines either physically execute each operand or estimate memory usage with a scaled input tensor. To address these challenges, we introduce a system that can jointly optimize distributed execution and gradient checkpointing plans. Additionally, we provide an easy-to-use symbolic profiler that generates memory and computing statistics for any PyTorch model with a minimal time cost. Our approach allows users to parallelize their model training on the given hardware with minimum code change based. The source code is publicly available at Colossal-AI GitHub or https://github.com/hpcaitech/ColossalAI
Elixir: Train a Large Language Model on a Small GPU Cluster
Dec 10, 2022In recent years, the number of parameters of one deep learning (DL) model has been growing much faster than the growth of GPU memory space. People who are inaccessible to a large number of GPUs resort to heterogeneous training systems for storing model parameters in CPU memory. Existing heterogeneous systems are based on parallelization plans in the scope of the whole model. They apply a consistent parallel training method for all the operators in the computation. Therefore, engineers need to pay a huge effort to incorporate a new type of model parallelism and patch its compatibility with other parallelisms. For example, Mixture-of-Experts (MoE) is still incompatible with ZeRO-3 in Deepspeed. Also, current systems face efficiency problems on small scale, since they are designed and tuned for large-scale training. In this paper, we propose Elixir, a new parallel heterogeneous training system, which is designed for efficiency and flexibility. Elixir utilizes memory resources and computing resources of both GPU and CPU. For flexibility, Elixir generates parallelization plans in the granularity of operators. Any new type of model parallelism can be incorporated by assigning a parallel pattern to the operator. For efficiency, Elixir implements a hierarchical distributed memory management scheme to accelerate inter-GPU communications and CPU-GPU data transmissions. As a result, Elixir can train a 30B OPT model on an A100 with 40GB CUDA memory, meanwhile reaching 84% efficiency of Pytorch GPU training. With its super-linear scalability, the training efficiency becomes the same as Pytorch GPU training on multiple GPUs. Also, large MoE models can be trained 5.3x faster than dense models of the same size. Now Elixir is integrated into ColossalAI and is available on its main branch.
EnergonAI: An Inference System for 10-100 Billion Parameter Transformer Models
Sep 06, 2022
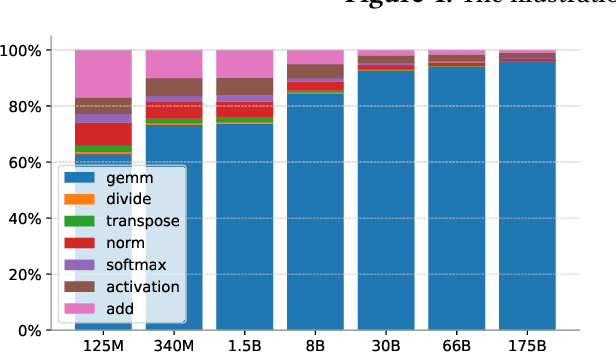
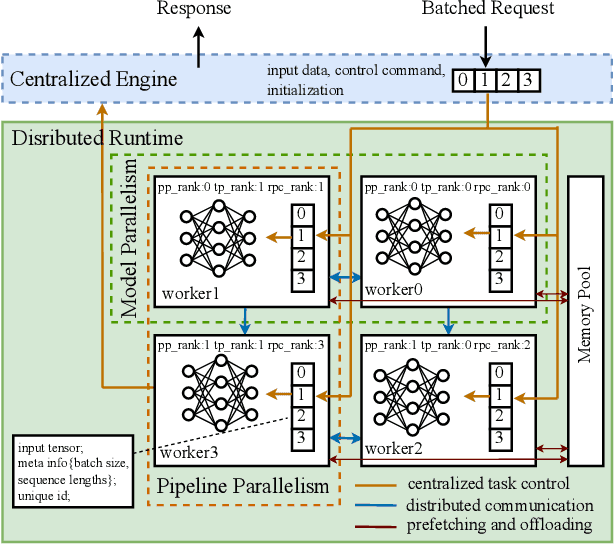
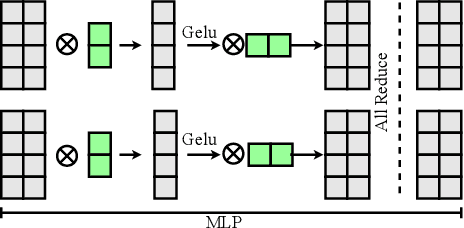
Large transformer models display promising performance on a wide range of natural language processing (NLP) tasks. Although the AI community has expanded the model scale to the trillion parameter level, the practical deployment of 10-100 billion parameter models is still uncertain due to the latency, throughput, and memory constraints. In this paper, we proposed EnergonAI to solve the challenges of the efficient deployment of 10-100 billion parameter transformer models on single- or multi-GPU systems. EnergonAI adopts a hierarchy-controller system architecture to coordinate multiple devices and efficiently support different parallel patterns. It delegates the execution of sub-models to multiple workers in the single-controller style and applies tensor parallelism and pipeline parallelism among the workers in a multi-controller style. Upon the novel architecture, we propose three techniques, i.e. non-blocking pipeline parallelism, distributed redundant computation elimination, and peer memory pooling. EnergonAI enables the users to program complex parallel code the same as a serial one. Compared with the FasterTransformer, we have proven that EnergonAI has superior performance on latency and throughput. In our experiments, EnergonAI can achieve 37% latency reduction in tensor parallelism, 10% scalability improvement in pipeline parallelism, and it improves the model scale inferred on a single GPU by using a larger heterogeneous memory space at cost of limited performance reduction.
A Frequency-aware Software Cache for Large Recommendation System Embeddings
Aug 08, 2022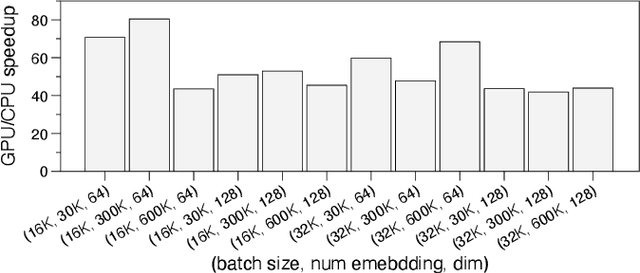
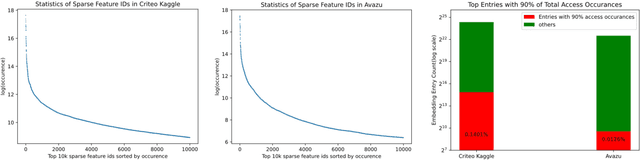
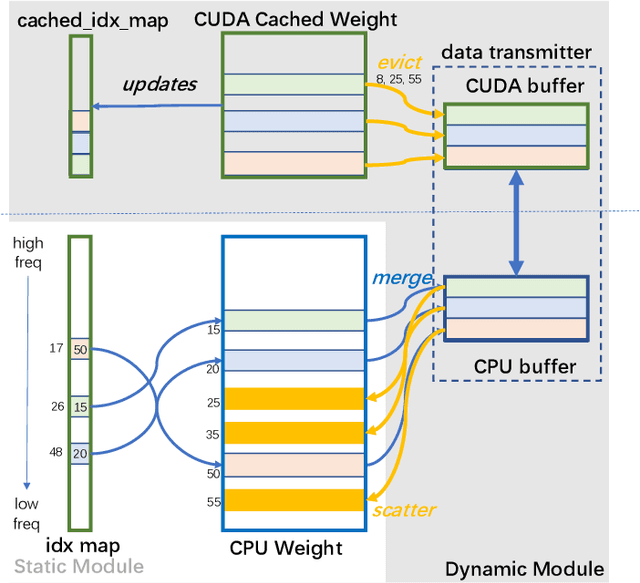
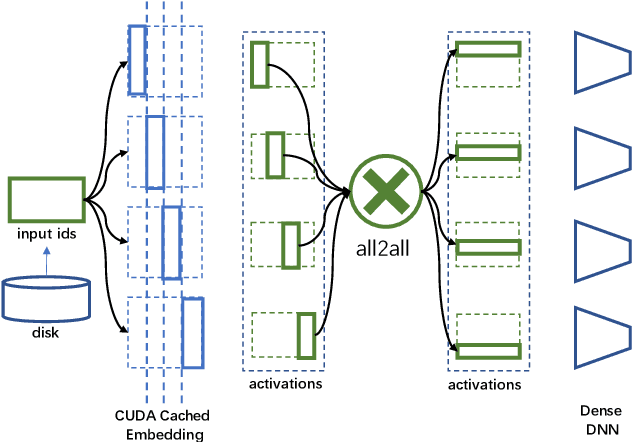
Deep learning recommendation models (DLRMs) have been widely applied in Internet companies. The embedding tables of DLRMs are too large to fit on GPU memory entirely. We propose a GPU-based software cache approaches to dynamically manage the embedding table in the CPU and GPU memory space by leveraging the id's frequency statistics of the target dataset. Our proposed software cache is efficient in training entire DLRMs on GPU in a synchronized update manner. It is also scaled to multiple GPUs in combination with the widely used hybrid parallel training approaches. Evaluating our prototype system shows that we can keep only 1.5% of the embedding parameters in the GPU to obtain a decent end-to-end training speed.
PatrickStar: Parallel Training of Pre-trained Models via a Chunk-based Memory Management
Aug 12, 2021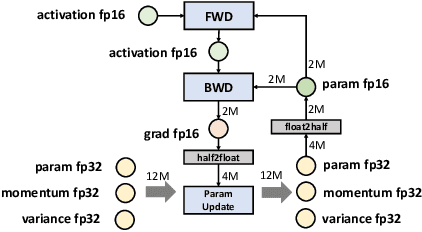

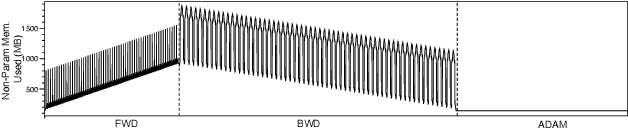
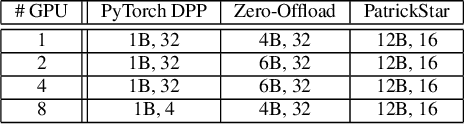
The pre-trained model (PTM) is revolutionizing Artificial intelligence (AI) technology. It learns a model with general language features on the vast text and then fine-tunes the model using a task-specific dataset. Unfortunately, PTM training requires prohibitively expensive computing devices, especially fine-tuning, which is still a game for a small proportion of people in the AI community. Enabling PTMs training on low-quality devices, PatrickStar now makes PTM accessible to everyone. PatrickStar reduces memory requirements of computing platforms by using the CPU-GPU heterogeneous memory space to store model data, consisting of parameters, gradients, and optimizer states. We observe that the GPU memory available for model data changes regularly, in a tide-like pattern, decreasing and increasing iteratively. However, the existing heterogeneous training works do not take advantage of this pattern. Instead, they statically partition the model data among CPU and GPU, leading to both memory waste and memory abuse. In contrast, PatrickStar manages model data in chunks, which are dynamically distributed in heterogeneous memory spaces. Chunks consist of stateful tensors which run as finite state machines during training. Guided by the runtime memory statistics collected in a warm-up iteration, chunks are orchestrated efficiently in heterogeneous memory and generate lower CPU-GPU data transmission volume. Symbiosis with the Zero Redundancy Optimizer, PatrickStar scales to multiple GPUs using data parallelism, with the lowest communication bandwidth requirements and more efficient bandwidth utilization. Experimental results show PatrickStar trains a 12 billion parameters GPT model, 2x larger than the STOA work, on an 8-V100 and 240GB CPU memory node, and is also more efficient on the same model size.