 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeswCaffe: a Parallel Framework for Accelerating Deep Learning Applications on Sunway TaihuLight
Paper and Code
Mar 16, 2019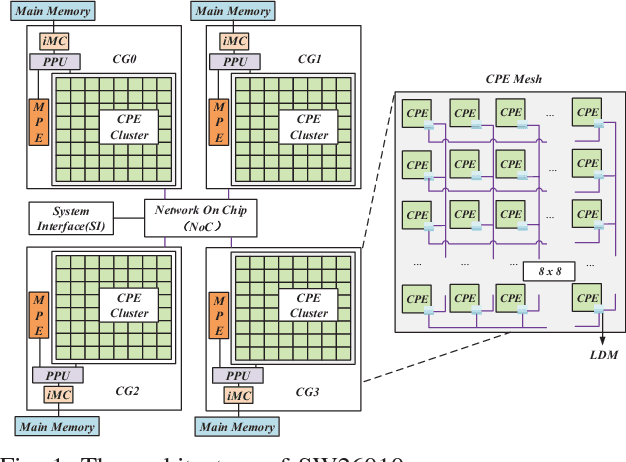
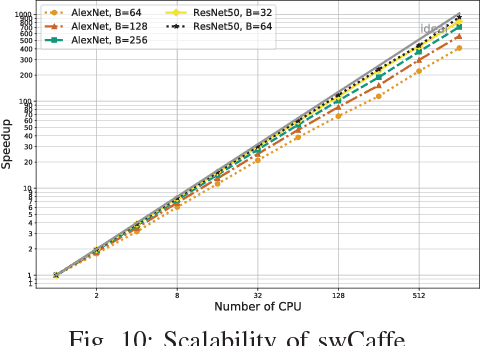
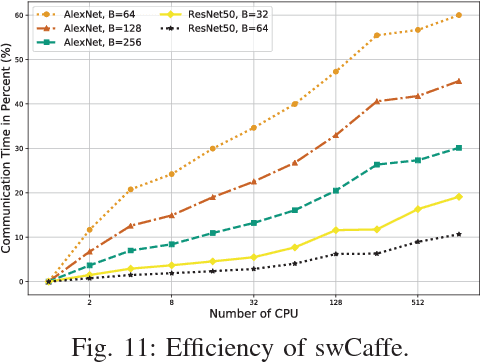
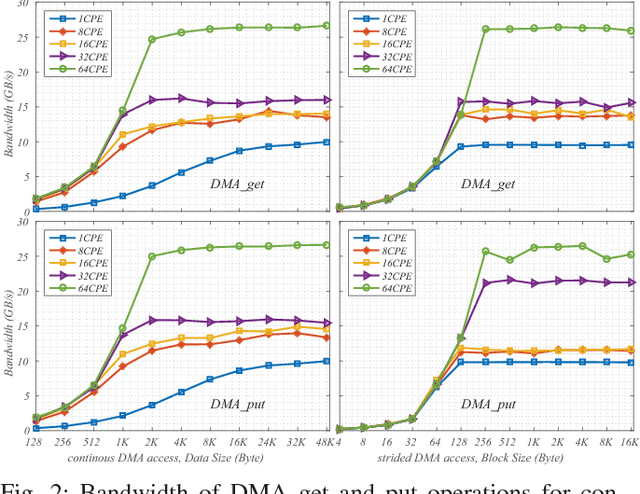
This paper reports our efforts on swCaffe, a highly efficient parallel framework for accelerating deep neural networks (DNNs) training on Sunway TaihuLight, the current fastest supercomputer in the world that adopts a unique many-core heterogeneous architecture, with 40,960 SW26010 processors connected through a customized communication network. First, we point out some insightful principles to fully exploit the performance of the innovative many-core architecture. Second, we propose a set of optimization strategies for redesigning a variety of neural network layers based on Caffe. Third, we put forward a topology-aware parameter synchronization scheme to scale the synchronous Stochastic Gradient Descent (SGD) method to multiple processors efficiently. We evaluate our framework by training a variety of widely used neural networks with the ImageNet dataset. On a single node, swCaffe can achieve 23\%\~{}119\% overall performance compared with Caffe running on K40m GPU. As compared with the Caffe on CPU, swCaffe runs 3.04\~{}7.84x faster on all the networks. Finally, we present the scalability of swCaffe for the training of ResNet-50 and AlexNet on the scale of 1024 nodes.