 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage-Guided Face Animation by Recurrent StyleGAN-based Generator
Aug 11, 2022


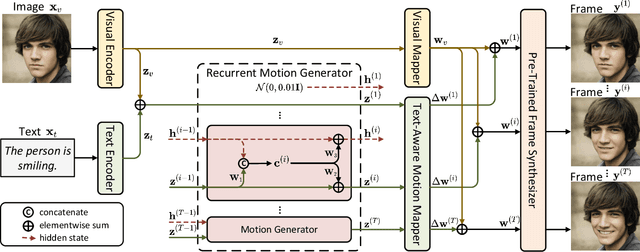
Recent works on language-guided image manipulation have shown great power of language in providing rich semantics, especially for face images. However, the other natural information, motions, in language is less explored. In this paper, we leverage the motion information and study a novel task, language-guided face animation, that aims to animate a static face image with the help of languages. To better utilize both semantics and motions from languages, we propose a simple yet effective framework. Specifically, we propose a recurrent motion generator to extract a series of semantic and motion information from the language and feed it along with visual information to a pre-trained StyleGAN to generate high-quality frames. To optimize the proposed framework, three carefully designed loss functions are proposed including a regularization loss to keep the face identity, a path length regularization loss to ensure motion smoothness, and a contrastive loss to enable video synthesis with various language guidance in one single model. Extensive experiments with both qualitative and quantitative evaluations on diverse domains (\textit{e.g.,} human face, anime face, and dog face) demonstrate the superiority of our model in generating high-quality and realistic videos from one still image with the guidance of language. Code will be available at https://github.com/TiankaiHang/language-guided-animation.git.
Exploring Anchor-based Detection for Ego4D Natural Language Query
Aug 10, 2022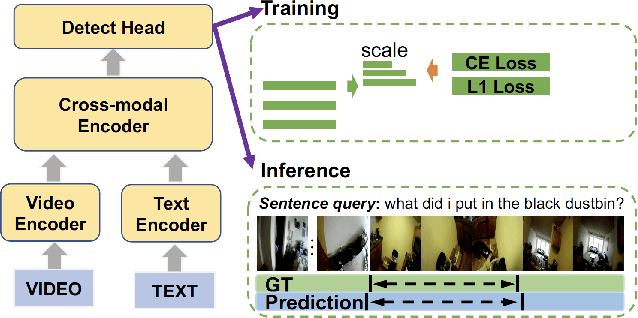
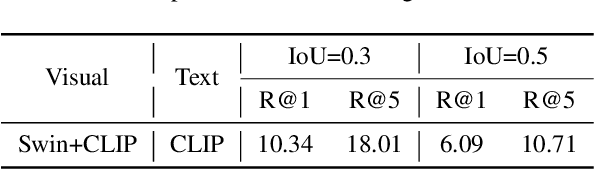

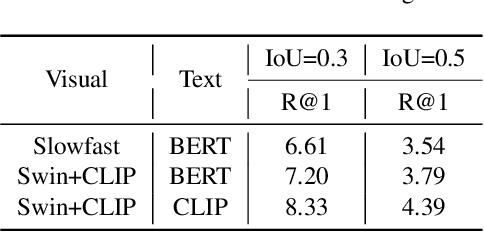
In this paper we provide the technique report of Ego4D natural language query challenge in CVPR 2022. Natural language query task is challenging due to the requirement of comprehensive understanding of video contents. Most previous works address this task based on third-person view datasets while few research interest has been placed in the ego-centric view by far. Great progress has been made though, we notice that previous works can not adapt well to ego-centric view datasets e.g., Ego4D mainly because of two reasons: 1) most queries in Ego4D have a excessively small temporal duration (e.g., less than 5 seconds); 2) queries in Ego4D are faced with much more complex video understanding of long-term temporal orders. Considering these, we propose our solution of this challenge to solve the above issues.
GRIT-VLP: Grouped Mini-batch Sampling for Efficient Vision and Language Pre-training
Aug 08, 2022Most of the currently existing vision and language pre-training (VLP) methods have mainly focused on how to extract and align vision and text features. In contrast to the mainstream VLP methods, we highlight that two routinely applied steps during pre-training have crucial impact on the performance of the pre-trained model: in-batch hard negative sampling for image-text matching (ITM) and assigning the large masking probability for the masked language modeling (MLM). After empirically showing the unexpected effectiveness of above two steps, we systematically devise our GRIT-VLP, which adaptively samples mini-batches for more effective mining of hard negative samples for ITM while maintaining the computational cost for pre-training. Our method consists of three components: 1) GRouped mIni-baTch sampling (GRIT) strategy that collects similar examples in a mini-batch, 2) ITC consistency loss for improving the mining ability, and 3) enlarged masking probability for MLM. Consequently, we show our GRIT-VLP achieves a new state-of-the-art performance on various downstream tasks with much less computational cost. Furthermore, we demonstrate that our model is essentially in par with ALBEF, the previous state-of-the-art, only with one-third of training epochs on the same training data. Code is available at https://github.com/jaeseokbyun/GRIT-VLP.
Learning Spatiotemporal Frequency-Transformer for Compressed Video Super-Resolution
Aug 05, 2022



Compressed video super-resolution (VSR) aims to restore high-resolution frames from compressed low-resolution counterparts. Most recent VSR approaches often enhance an input frame by borrowing relevant textures from neighboring video frames. Although some progress has been made, there are grand challenges to effectively extract and transfer high-quality textures from compressed videos where most frames are usually highly degraded. In this paper, we propose a novel Frequency-Transformer for compressed video super-resolution (FTVSR) that conducts self-attention over a joint space-time-frequency domain. First, we divide a video frame into patches, and transform each patch into DCT spectral maps in which each channel represents a frequency band. Such a design enables a fine-grained level self-attention on each frequency band, so that real visual texture can be distinguished from artifacts, and further utilized for video frame restoration. Second, we study different self-attention schemes, and discover that a divided attention which conducts a joint space-frequency attention before applying temporal attention on each frequency band, leads to the best video enhancement quality. Experimental results on two widely-used video super-resolution benchmarks show that FTVSR outperforms state-of-the-art approaches on both uncompressed and compressed videos with clear visual margins. Code is available at https://github.com/researchmm/FTVSR.
Expanding Language-Image Pretrained Models for General Video Recognition
Aug 04, 2022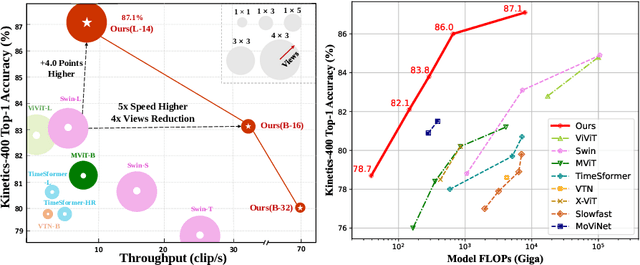
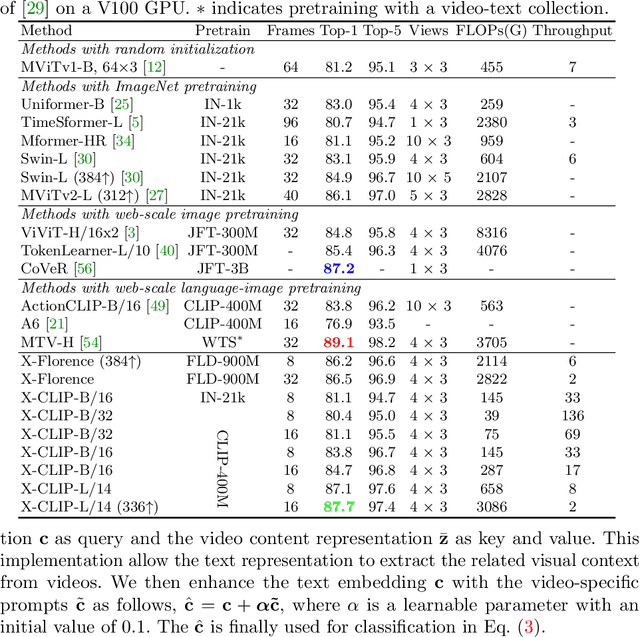
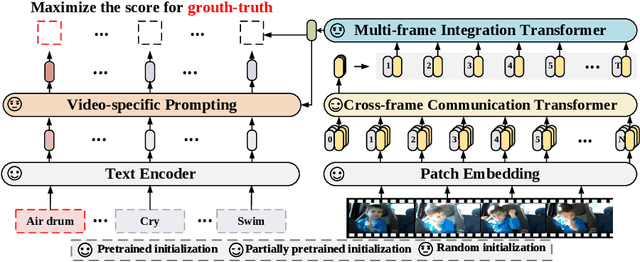
Contrastive language-image pretraining has shown great success in learning visual-textual joint representation from web-scale data, demonstrating remarkable "zero-shot" generalization ability for various image tasks. However, how to effectively expand such new language-image pretraining methods to video domains is still an open problem. In this work, we present a simple yet effective approach that adapts the pretrained language-image models to video recognition directly, instead of pretraining a new model from scratch. More concretely, to capture the long-range dependencies of frames along the temporal dimension, we propose a cross-frame attention mechanism that explicitly exchanges information across frames. Such module is lightweight and can be plugged into pretrained language-image models seamlessly. Moreover, we propose a video-specific prompting scheme, which leverages video content information for generating discriminative textual prompts. Extensive experiments demonstrate that our approach is effective and can be generalized to different video recognition scenarios. In particular, under fully-supervised settings, our approach achieves a top-1 accuracy of 87.1% on Kinectics-400, while using 12 times fewer FLOPs compared with Swin-L and ViViT-H. In zero-shot experiments, our approach surpasses the current state-of-the-art methods by +7.6% and +14.9% in terms of top-1 accuracy under two popular protocols. In few-shot scenarios, our approach outperforms previous best methods by +32.1% and +23.1% when the labeled data is extremely limited. Code and models are available at https://aka.ms/X-CLIP
TinyViT: Fast Pretraining Distillation for Small Vision Transformers
Jul 21, 2022



Vision transformer (ViT) recently has drawn great attention in computer vision due to its remarkable model capability. However, most prevailing ViT models suffer from huge number of parameters, restricting their applicability on devices with limited resources. To alleviate this issue, we propose TinyViT, a new family of tiny and efficient small vision transformers pretrained on large-scale datasets with our proposed fast distillation framework. The central idea is to transfer knowledge from large pretrained models to small ones, while enabling small models to get the dividends of massive pretraining data. More specifically, we apply distillation during pretraining for knowledge transfer. The logits of large teacher models are sparsified and stored in disk in advance to save the memory cost and computation overheads. The tiny student transformers are automatically scaled down from a large pretrained model with computation and parameter constraints. Comprehensive experiments demonstrate the efficacy of TinyViT. It achieves a top-1 accuracy of 84.8% on ImageNet-1k with only 21M parameters, being comparable to Swin-B pretrained on ImageNet-21k while using 4.2 times fewer parameters. Moreover, increasing image resolutions, TinyViT can reach 86.5% accuracy, being slightly better than Swin-L while using only 11% parameters. Last but not the least, we demonstrate a good transfer ability of TinyViT on various downstream tasks. Code and models are available at https://github.com/microsoft/Cream/tree/main/TinyViT.
TTVFI: Learning Trajectory-Aware Transformer for Video Frame Interpolation
Jul 19, 2022



Video frame interpolation (VFI) aims to synthesize an intermediate frame between two consecutive frames. State-of-the-art approaches usually adopt a two-step solution, which includes 1) generating locally-warped pixels by flow-based motion estimations, 2) blending the warped pixels to form a full frame through deep neural synthesis networks. However, due to the inconsistent warping from the two consecutive frames, the warped features for new frames are usually not aligned, which leads to distorted and blurred frames, especially when large and complex motions occur. To solve this issue, in this paper we propose a novel Trajectory-aware Transformer for Video Frame Interpolation (TTVFI). In particular, we formulate the warped features with inconsistent motions as query tokens, and formulate relevant regions in a motion trajectory from two original consecutive frames into keys and values. Self-attention is learned on relevant tokens along the trajectory to blend the pristine features into intermediate frames through end-to-end training. Experimental results demonstrate that our method outperforms other state-of-the-art methods in four widely-used VFI benchmarks. Both code and pre-trained models will be released soon.
Degradation-Guided Meta-Restoration Network for Blind Super-Resolution
Jul 03, 2022
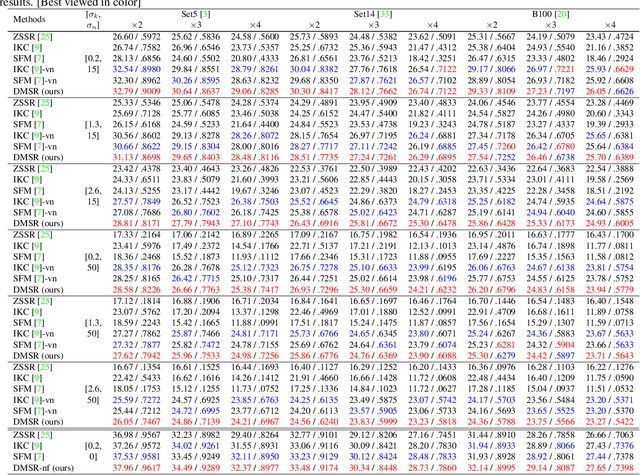
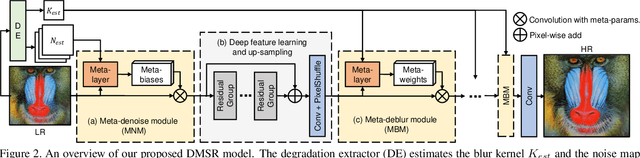
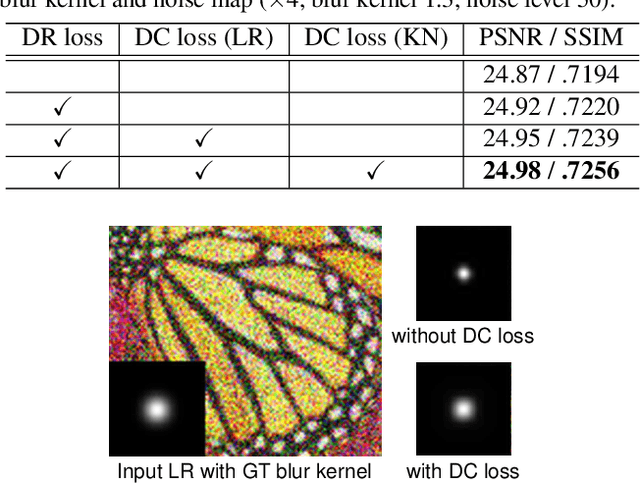
Blind super-resolution (SR) aims to recover high-quality visual textures from a low-resolution (LR) image, which is usually degraded by down-sampling blur kernels and additive noises. This task is extremely difficult due to the challenges of complicated image degradations in the real-world. Existing SR approaches either assume a predefined blur kernel or a fixed noise, which limits these approaches in challenging cases. In this paper, we propose a Degradation-guided Meta-restoration network for blind Super-Resolution (DMSR) that facilitates image restoration for real cases. DMSR consists of a degradation extractor and meta-restoration modules. The extractor estimates the degradations in LR inputs and guides the meta-restoration modules to predict restoration parameters for different degradations on-the-fly. DMSR is jointly optimized by a novel degradation consistency loss and reconstruction losses. Through such an optimization, DMSR outperforms SOTA by a large margin on three widely-used benchmarks. A user study including 16 subjects further validates the superiority of DMSR in real-world blind SR tasks.
Learning Trajectory-Aware Transformer for Video Super-Resolution
Apr 20, 2022



Video super-resolution (VSR) aims to restore a sequence of high-resolution (HR) frames from their low-resolution (LR) counterparts. Although some progress has been made, there are grand challenges to effectively utilize temporal dependency in entire video sequences. Existing approaches usually align and aggregate video frames from limited adjacent frames (e.g., 5 or 7 frames), which prevents these approaches from satisfactory results. In this paper, we take one step further to enable effective spatio-temporal learning in videos. We propose a novel Trajectory-aware Transformer for Video Super-Resolution (TTVSR). In particular, we formulate video frames into several pre-aligned trajectories which consist of continuous visual tokens. For a query token, self-attention is only learned on relevant visual tokens along spatio-temporal trajectories. Compared with vanilla vision Transformers, such a design significantly reduces the computational cost and enables Transformers to model long-range features. We further propose a cross-scale feature tokenization module to overcome scale-changing problems that often occur in long-range videos. Experimental results demonstrate the superiority of the proposed TTVSR over state-of-the-art models, by extensive quantitative and qualitative evaluations in four widely-used video super-resolution benchmarks. Both code and pre-trained models can be downloaded at https://github.com/researchmm/TTVSR.
MiniViT: Compressing Vision Transformers with Weight Multiplexing
Apr 14, 2022



Vision Transformer (ViT) models have recently drawn much attention in computer vision due to their high model capability. However, ViT models suffer from huge number of parameters, restricting their applicability on devices with limited memory. To alleviate this problem, we propose MiniViT, a new compression framework, which achieves parameter reduction in vision transformers while retaining the same performance. The central idea of MiniViT is to multiplex the weights of consecutive transformer blocks. More specifically, we make the weights shared across layers, while imposing a transformation on the weights to increase diversity. Weight distillation over self-attention is also applied to transfer knowledge from large-scale ViT models to weight-multiplexed compact models. Comprehensive experiments demonstrate the efficacy of MiniViT, showing that it can reduce the size of the pre-trained Swin-B transformer by 48\%, while achieving an increase of 1.0\% in Top-1 accuracy on ImageNet. Moreover, using a single-layer of parameters, MiniViT is able to compress DeiT-B by 9.7 times from 86M to 9M parameters, without seriously compromising the performance. Finally, we verify the transferability of MiniViT by reporting its performance on downstream benchmarks. Code and models are available at here.