 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-stage Attention ResU-Net for Semantic Segmentation of Fine-Resolution Remote Sensing Images
Dec 01, 2020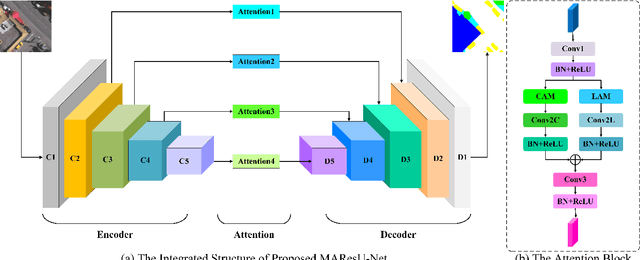
The attention mechanism can refine the extracted feature maps and boost the classification performance of the deep network, which has become an essential technique in computer vision and natural language processing. However, the memory and computational costs of the dot-product attention mechanism increase quadratically with the spatio-temporal size of the input. Such growth hinders the usage of attention mechanisms considerably in application scenarios with large-scale inputs. In this Letter, we propose a Linear Attention Mechanism (LAM) to address this issue, which is approximately equivalent to dot-product attention with computational efficiency. Such a design makes the incorporation between attention mechanisms and deep networks much more flexible and versatile. Based on the proposed LAM, we re-factor the skip connections in the raw U-Net and design a Multi-stage Attention ResU-Net (MAResU-Net) for semantic segmentation from fine-resolution remote sensing images. Experiments conducted on the Vaihingen dataset demonstrated the effectiveness and efficiency of our MAResU-Net. Open-source code is available at https://github.com/lironui/Multistage-Attention-ResU-Net.
Multi-Attention-Network for Semantic Segmentation of High-Resolution Remote Sensing Images
Sep 03, 2020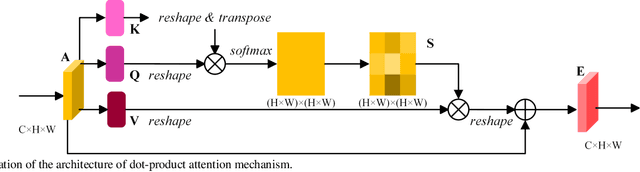
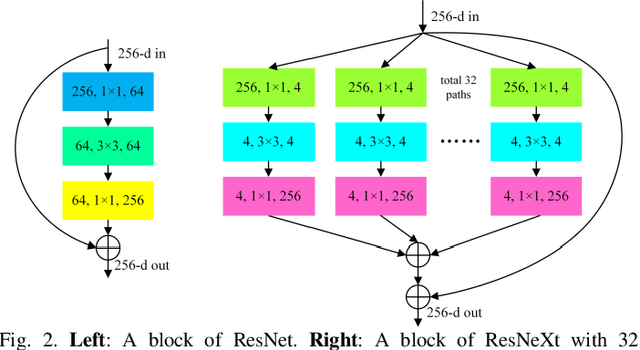
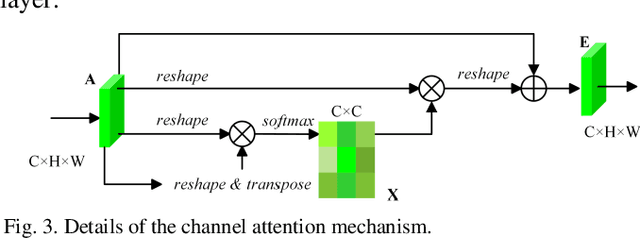
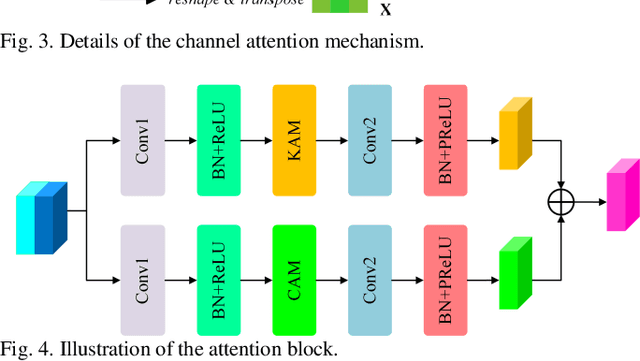
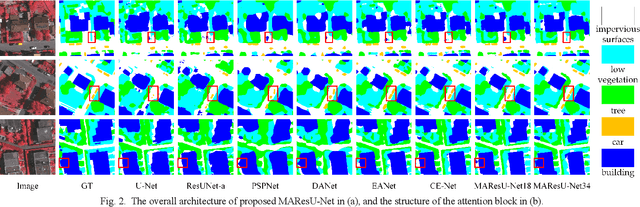
Semantic segmentation of remote sensing images plays an important role in land resource management, yield estimation, and economic assessment. Even though the semantic segmentation of remote sensing images has been prominently improved by convolutional neural networks, there are still several limitations contained in standard models. First, for encoder-decoder architectures like U-Net, the utilization of multi-scale features causes overuse of information, where similar low-level features are exploited at multiple scales for multiple times. Second, long-range dependencies of feature maps are not sufficiently explored, leading to feature representations associated with each semantic class are not optimal. Third, despite the dot-product attention mechanism has been introduced and harnessed widely in semantic segmentation to model long-range dependencies, the high time and space complexities of attention impede the usage of attention in application scenarios with large input. In this paper, we proposed a Multi-Attention-Network (MANet) to remedy these drawbacks, which extracts contextual dependencies by multi efficient attention mechanisms. A novel attention mechanism named kernel attention with linear complexity is proposed to alleviate the high computational demand of attention. Based on kernel attention and channel attention, we integrate local feature maps extracted by ResNeXt-101 with their corresponding global dependencies, and adaptively signalize interdependent channel maps. Experiments conducted on two remote sensing image datasets captured by variant satellites demonstrate that the performance of our MANet transcends the DeepLab V3+, PSPNet, FastFCN, and other baseline algorithms.
Linear Attention Mechanism: An Efficient Attention for Semantic Segmentation
Aug 20, 2020
In this paper, to remedy this deficiency, we propose a Linear Attention Mechanism which is approximate to dot-product attention with much less memory and computational costs. The efficient design makes the incorporation between attention mechanisms and neural networks more flexible and versatile. Experiments conducted on semantic segmentation demonstrated the effectiveness of linear attention mechanism. Code is available at https://github.com/lironui/Linear-Attention-Mechanism.
A Batch Normalized Inference Network Keeps the KL Vanishing Away
Jun 01, 2020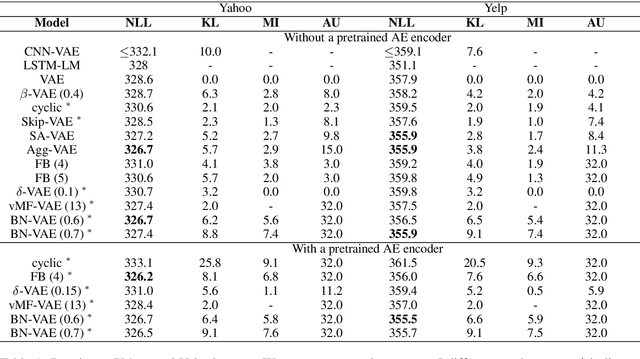
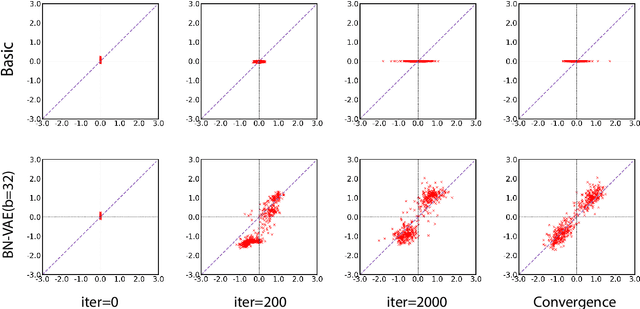
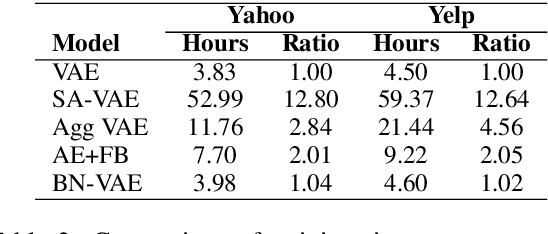
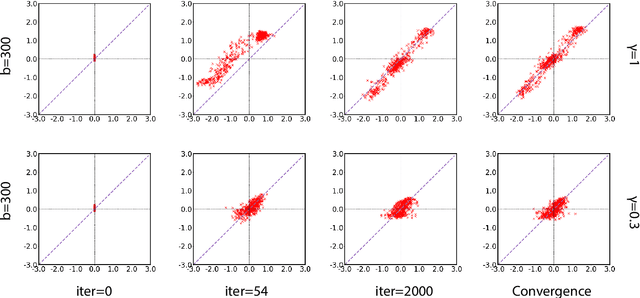
Variational Autoencoder (VAE) is widely used as a generative model to approximate a model's posterior on latent variables by combining the amortized variational inference and deep neural networks. However, when paired with strong autoregressive decoders, VAE often converges to a degenerated local optimum known as "posterior collapse". Previous approaches consider the Kullback Leibler divergence (KL) individual for each datapoint. We propose to let the KL follow a distribution across the whole dataset, and analyze that it is sufficient to prevent posterior collapse by keeping the expectation of the KL's distribution positive. Then we propose Batch Normalized-VAE (BN-VAE), a simple but effective approach to set a lower bound of the expectation by regularizing the distribution of the approximate posterior's parameters. Without introducing any new model component or modifying the objective, our approach can avoid the posterior collapse effectively and efficiently. We further show that the proposed BN-VAE can be extended to conditional VAE (CVAE). Empirically, our approach surpasses strong autoregressive baselines on language modeling, text classification and dialogue generation, and rivals more complex approaches while keeping almost the same training time as VAE.
Joint Extraction of Entities and Relations Based on a Novel Decomposition Strategy
Sep 11, 2019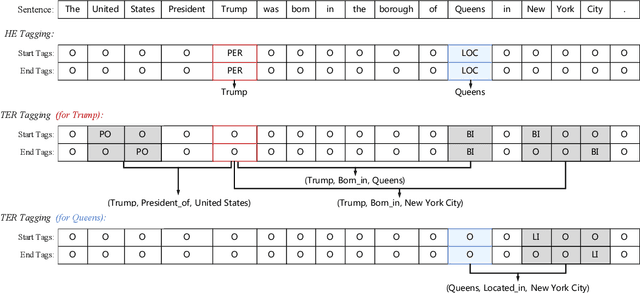

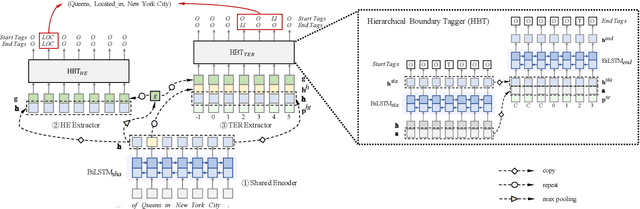
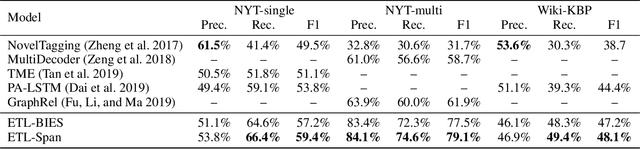
Joint extraction of entities and relations aims to detect entity pairs along with their relations using a single model. Prior works typically solve this task in the extract-then-classify or unified labeling manner. However, these methods either suffer from the redundant entity pairs, or ignore the important inner structure in the process of extracting entities and relations. To address these limitations, in this paper, we first decompose the joint extraction task into two inner-related subtasks, namely HE extraction and TER extraction. The former subtask is to distinguish all head-entities that may be involved with target relations, and the latter is to identify corresponding tail-entities and relations for each extracted head-entity. Next, these two subtasks are further deconstructed into several sequence labeling problems based on our proposed span-based tagging scheme, which are conveniently solved by a hierarchical boundary tagger and a multi-span decoding algorithm. Owing to the reasonable decomposition strategy, our model can fully capture the semantic interdependency between different steps, as well as reduce noise from irrelevant entity pairs.Experimental results show that our method outperforms previous work by 5.6%, 17.2% and 3.7% (F1 score), achieving a new state-of-the-art on three public datasets.
A Novel Hierarchical Binary Tagging Framework for Joint Extraction of Entities and Relations
Sep 07, 2019
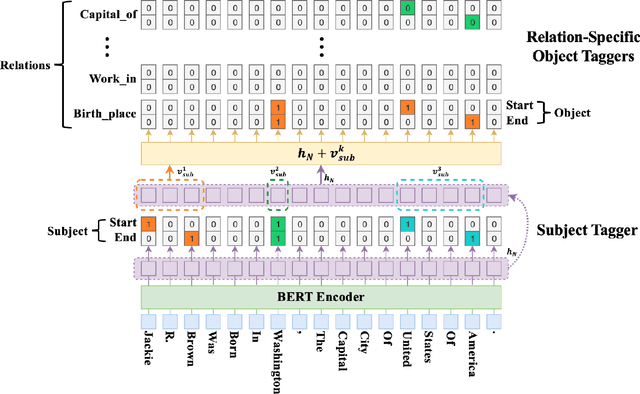
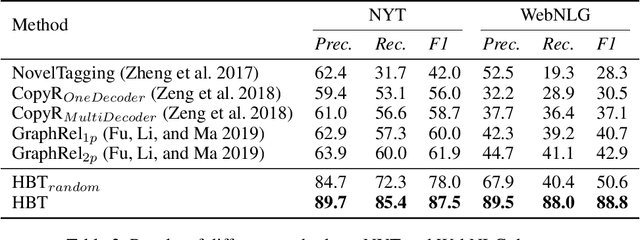
Extracting relational triples from unstructured text is crucial for large-scale knowledge graph construction. However, few existing works excel in solving the overlapping triple problem where multiple relational triples in the same sentence share the same entities. We propose a novel Hierarchical Binary Tagging (HBT) framework derived from a principled problem formulation. Instead of treating relations as discrete labels as in previous works, our new framework models relations as functions that map subjects to objects in a sentence, which naturally handles overlapping triples. Experiments show that the proposed framework already outperforms state-of-the-art methods even its encoder module uses a randomly initialized BERT encoder, showing the power of the new tagging framework. It enjoys further performance boost when employing a pretrained BERT encoder, outperforming the strongest baseline by 25.6 and 45.9 absolute gain in F1-score on two public datasets NYT and WebNLG, respectively. In-depth analysis on different types of overlapping triples shows that the method delivers consistent performance gain in all scenarios.
O-GAN: Extremely Concise Approach for Auto-Encoding Generative Adversarial Networks
Mar 05, 2019



In this paper, we propose Orthogonal Generative Adversarial Networks (O-GANs). We decompose the network of discriminator orthogonally and add an extra loss into the objective of common GANs, which can enforce discriminator become an effective encoder. The same extra loss can be embedded into any kind of GANs and there is almost no increase in computation. Furthermore, we discuss the principle of our method, which is relative to the fully-exploiting of the remaining degrees of freedom of discriminator. As we know, our solution is the simplest approach to train a generative adversarial network with auto-encoding ability.
Artist Style Transfer Via Quadratic Potential
Mar 05, 2019


In this paper we address the problem of artist style transfer where the painting style of a given artist is applied on a real world photograph. We train our neural networks in adversarial setting via recently introduced quadratic potential divergence for stable learning process. To further improve the quality of generated artist stylized images we also integrate some of the recently introduced deep learning techniques in our method. To our best knowledge this is the first attempt towards artist style transfer via quadratic potential divergence. We provide some stylized image samples in the supplementary material. The source code for experimentation was written in PyTorch and is available online in my GitHub repository.
Evaluating Generalization Ability of Convolutional Neural Networks and Capsule Networks for Image Classification via Top-2 Classification
Jan 29, 2019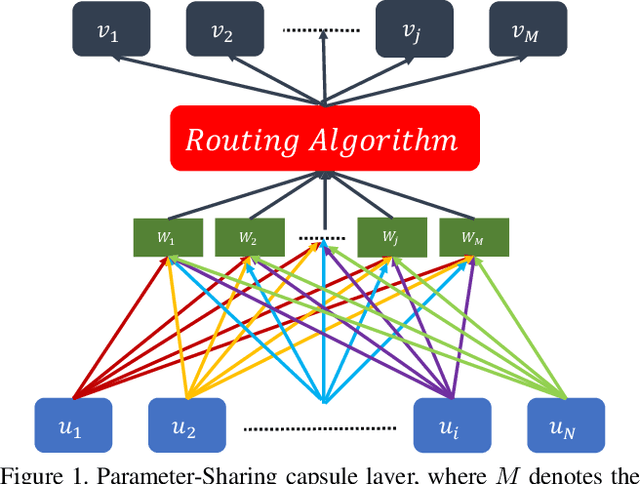
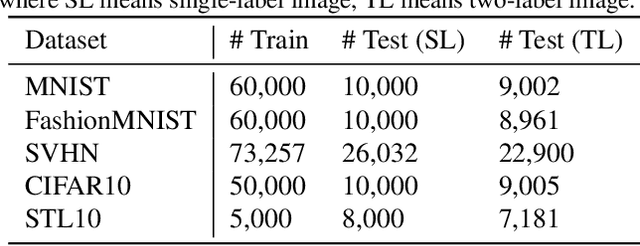


Image classification is a challenging problem which aims to identify the category of object in the image. In recent years, deep Convolutional Neural Networks (CNNs) have been applied to handle this task, and impressive improvement has been achieved. However, some research showed the output of CNNs can be easily altered by adding relatively small perturbations to the input image, such as modifying few pixels. Recently, Capsule Networks (CapsNets) are proposed, which can help eliminating this limitation. Experiments on MNIST dataset revealed that capsules can better characterize the features of object than CNNs. But it's hard to find a suitable quantitative method to compare the generalization ability of CNNs and CapsNets. In this paper, we propose a new image classification task called Top-2 classification to evaluate the generalization ability of CNNs and CapsNets. The models are trained on single label image samples same as the traditional image classification task. But in the test stage, we randomly concatenate two test image samples which contain different labels, and then use the trained models to predict the top-2 labels on the unseen newly-created two label image samples. This task can provide us precise quantitative results to compare the generalization ability of CNNs and CapsNets. Back to the CapsNet, because it uses Full Connectivity (FC) mechanism among all capsules, it requires many parameters. To reduce the number of parameters, we introduce the Parameter-Sharing (PS) mechanism between capsules. Experiments on five widely used benchmark image datasets demonstrate the method significantly reduces the number of parameters, without losing the effectiveness of extracting features. Further, on the Top-2 classification task, the proposed PS CapsNets obtain impressive higher accuracy compared to the traditional CNNs and FC CapsNets by a large margin.
GAN-QP: A Novel GAN Framework without Gradient Vanishing and Lipschitz Constraint
Dec 08, 2018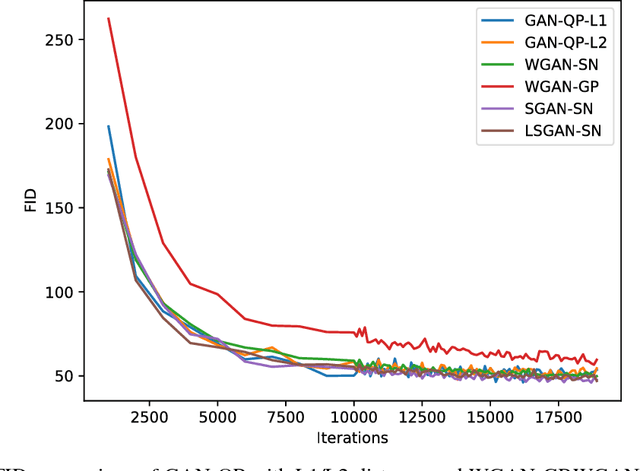



We know SGAN may have a risk of gradient vanishing. A significant improvement is WGAN, with the help of 1-Lipschitz constraint on discriminator to prevent from gradient vanishing. Is there any GAN having no gradient vanishing and no 1-Lipschitz constraint on discriminator? We do find one, called GAN-QP. To construct a new framework of Generative Adversarial Network (GAN) usually includes three steps: 1. choose a probability divergence; 2. convert it into a dual form; 3. play a min-max game. In this articles, we demonstrate that the first step is not necessary. We can analyse the property of divergence and even construct new divergence in dual space directly. As a reward, we obtain a simpler alternative of WGAN: GAN-QP. We demonstrate that GAN-QP have a better performance than WGAN in theory and practice.