 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMDPE: A Multimodal Deception Dataset with Personality and Emotional Characteristics
Jul 17, 2024



Deception detection has garnered increasing attention in recent years due to the significant growth of digital media and heightened ethical and security concerns. It has been extensively studied using multimodal methods, including video, audio, and text. In addition, individual differences in deception production and detection are believed to play a crucial role.Although some studies have utilized individual information such as personality traits to enhance the performance of deception detection, current systems remain limited, partly due to a lack of sufficient datasets for evaluating performance. To address this issue, we introduce a multimodal deception dataset MDPE. Besides deception features, this dataset also includes individual differences information in personality and emotional expression characteristics. It can explore the impact of individual differences on deception behavior. It comprises over 104 hours of deception and emotional videos from 193 subjects. Furthermore, we conducted numerous experiments to provide valuable insights for future deception detection research. MDPE not only supports deception detection, but also provides conditions for tasks such as personality recognition and emotion recognition, and can even study the relationships between them. We believe that MDPE will become a valuable resource for promoting research in the field of affective computing.
An Unsupervised Domain Adaptation Method for Locating Manipulated Region in partially fake Audio
Jul 11, 2024
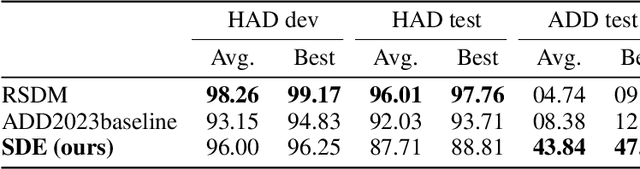
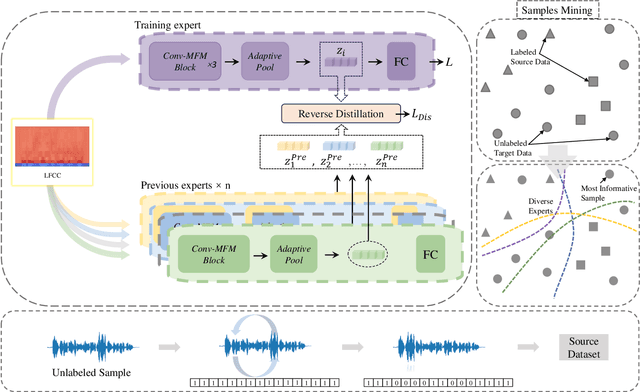

When the task of locating manipulation regions in partially-fake audio (PFA) involves cross-domain datasets, the performance of deep learning models drops significantly due to the shift between the source and target domains. To address this issue, existing approaches often employ data augmentation before training. However, they overlook the characteristics in target domain that are absent in source domain. Inspired by the mixture-of-experts model, we propose an unsupervised method named Samples mining with Diversity and Entropy (SDE). Our method first learns from a collection of diverse experts that achieve great performance from different perspectives in the source domain, but with ambiguity on target samples. We leverage these diverse experts to select the most informative samples by calculating their entropy. Furthermore, we introduced a label generation method tailored for these selected samples that are incorporated in the training process in source domain integrating the target domain information. We applied our method to a cross-domain partially fake audio detection dataset, ADD2023Track2. By introducing 10% of unknown samples from the target domain, we achieved an F1 score of 43.84%, which represents a relative increase of 77.2% compared to the second-best method.
ASRRL-TTS: Agile Speaker Representation Reinforcement Learning for Text-to-Speech Speaker Adaptation
Jul 07, 2024



Speaker adaptation, which involves cloning voices from unseen speakers in the Text-to-Speech task, has garnered significant interest due to its numerous applications in multi-media fields. Despite recent advancements, existing methods often struggle with inadequate speaker representation accuracy and overfitting, particularly in limited reference speeches scenarios. To address these challenges, we propose an Agile Speaker Representation Reinforcement Learning strategy to enhance speaker similarity in speaker adaptation tasks. ASRRL is the first work to apply reinforcement learning to improve the modeling accuracy of speaker embeddings in speaker adaptation, addressing the challenge of decoupling voice content and timbre. Our approach introduces two action strategies tailored to different reference speeches scenarios. In the single-sentence scenario, a knowledge-oriented optimal routine searching RL method is employed to expedite the exploration and retrieval of refinement information on the fringe of speaker representations. In the few-sentence scenario, we utilize a dynamic RL method to adaptively fuse reference speeches, enhancing the robustness and accuracy of speaker modeling. To achieve optimal results in the target domain, a multi-scale fusion scoring mechanism based reward model that evaluates speaker similarity, speech quality, and intelligibility across three dimensions is proposed, ensuring that improvements in speaker similarity do not compromise speech quality or intelligibility. The experimental results on the LibriTTS and VCTK datasets within mainstream TTS frameworks demonstrate the extensibility and generalization capabilities of the proposed ASRRL method. The results indicate that the ASRRL method significantly outperforms traditional fine-tuning approaches, achieving higher speaker similarity and better overall speech quality with limited reference speeches.
Fake News Detection and Manipulation Reasoning via Large Vision-Language Models
Jul 02, 2024Fake news becomes a growing threat to information security and public opinion with the rapid sprawl of media manipulation. Therefore, fake news detection attracts widespread attention from academic community. Traditional fake news detection models demonstrate remarkable performance on authenticity binary classification but their ability to reason detailed faked traces based on the news content remains under-explored. Furthermore, due to the lack of external knowledge, the performance of existing methods on fact-related news is questionable, leaving their practical implementation unclear. In this paper, we propose a new multi-media research topic, namely manipulation reasoning. Manipulation reasoning aims to reason manipulations based on news content. To support the research, we introduce a benchmark for fake news detection and manipulation reasoning, referred to as Human-centric and Fact-related Fake News (HFFN). The benchmark highlights the centrality of human and the high factual relevance, with detailed manual annotations. HFFN encompasses four realistic domains with fake news samples generated through three manipulation approaches. Moreover, a Multi-modal news Detection and Reasoning langUage Model (M-DRUM) is presented not only to judge on the authenticity of multi-modal news, but also raise analytical reasoning about potential manipulations. On the feature extraction level, a cross-attention mechanism is employed to extract fine-grained fusion features from multi-modal inputs. On the reasoning level, a large vision-language model (LVLM) serves as the backbone to facilitate fact-related reasoning. A two-stage training framework is deployed to better activate the capacity of identification and reasoning. Comprehensive experiments demonstrate that our model outperforms state-of-the-art (SOTA) fake news detection models and powerful LVLMs like GPT-4 and LLaVA.
MINT: a Multi-modal Image and Narrative Text Dubbing Dataset for Foley Audio Content Planning and Generation
Jun 15, 2024



Foley audio, critical for enhancing the immersive experience in multimedia content, faces significant challenges in the AI-generated content (AIGC) landscape. Despite advancements in AIGC technologies for text and image generation, the foley audio dubbing remains rudimentary due to difficulties in cross-modal scene matching and content correlation. Current text-to-audio technology, which relies on detailed and acoustically relevant textual descriptions, falls short in practical video dubbing applications. Existing datasets like AudioSet, AudioCaps, Clotho, Sound-of-Story, and WavCaps do not fully meet the requirements for real-world foley audio dubbing task. To address this, we introduce the Multi-modal Image and Narrative Text Dubbing Dataset (MINT), designed to enhance mainstream dubbing tasks such as literary story audiobooks dubbing, image/silent video dubbing. Besides, to address the limitations of existing TTA technology in understanding and planning complex prompts, a Foley Audio Content Planning, Generation, and Alignment (CPGA) framework is proposed, which includes a content planning module leveraging large language models for complex multi-modal prompts comprehension. Additionally, the training process is optimized using Proximal Policy Optimization based reinforcement learning, significantly improving the alignment and auditory realism of generated foley audio. Experimental results demonstrate that our approach significantly advances the field of foley audio dubbing, providing robust solutions for the challenges of multi-modal dubbing. Even when utilizing the relatively lightweight GPT-2 model, our framework outperforms open-source multimodal large models such as LLaVA, DeepSeek-VL, and Moondream2. The dataset is available at https://github.com/borisfrb/MINT .
Codecfake: An Initial Dataset for Detecting LLM-based Deepfake Audio
Jun 12, 2024



With the proliferation of Large Language Model (LLM) based deepfake audio, there is an urgent need for effective detection methods. Previous deepfake audio generation methods typically involve a multi-step generation process, with the final step using a vocoder to predict the waveform from handcrafted features. However, LLM-based audio is directly generated from discrete neural codecs in an end-to-end generation process, skipping the final step of vocoder processing. This poses a significant challenge for current audio deepfake detection (ADD) models based on vocoder artifacts. To effectively detect LLM-based deepfake audio, we focus on the core of the generation process, the conversion from neural codec to waveform. We propose Codecfake dataset, which is generated by seven representative neural codec methods. Experiment results show that codec-trained ADD models exhibit a 41.406% reduction in average equal error rate compared to vocoder-trained ADD models on the Codecfake test set.
RawBMamba: End-to-End Bidirectional State Space Model for Audio Deepfake Detection
Jun 10, 2024



Fake artefacts for discriminating between bonafide and fake audio can exist in both short- and long-range segments. Therefore, combining local and global feature information can effectively discriminate between bonafide and fake audio. This paper proposes an end-to-end bidirectional state space model, named RawBMamba, to capture both short- and long-range discriminative information for audio deepfake detection. Specifically, we use sinc Layer and multiple convolutional layers to capture short-range features, and then design a bidirectional Mamba to address Mamba's unidirectional modelling problem and further capture long-range feature information. Moreover, we develop a bidirectional fusion module to integrate embeddings, enhancing audio context representation and combining short- and long-range information. The results show that our proposed RawBMamba achieves a 34.1\% improvement over Rawformer on ASVspoof2021 LA dataset, and demonstrates competitive performance on other datasets.
PPPR: Portable Plug-in Prompt Refiner for Text to Audio Generation
Jun 07, 2024



Text-to-Audio (TTA) aims to generate audio that corresponds to the given text description, playing a crucial role in media production. The text descriptions in TTA datasets lack rich variations and diversity, resulting in a drop in TTA model performance when faced with complex text. To address this issue, we propose a method called Portable Plug-in Prompt Refiner, which utilizes rich knowledge about textual descriptions inherent in large language models to effectively enhance the robustness of TTA acoustic models without altering the acoustic training set. Furthermore, a Chain-of-Thought that mimics human verification is introduced to enhance the accuracy of audio descriptions, thereby improving the accuracy of generated content in practical applications. The experiments show that our method achieves a state-of-the-art Inception Score (IS) of 8.72, surpassing AudioGen, AudioLDM and Tango.
TraceableSpeech: Towards Proactively Traceable Text-to-Speech with Watermarking
Jun 07, 2024



Various threats posed by the progress in text-to-speech (TTS) have prompted the need to reliably trace synthesized speech. However, contemporary approaches to this task involve adding watermarks to the audio separately after generation, a process that hurts both speech quality and watermark imperceptibility. In addition, these approaches are limited in robustness and flexibility. To address these problems, we propose TraceableSpeech, a novel TTS model that directly generates watermarked speech, improving watermark imperceptibility and speech quality. Furthermore, We design the frame-wise imprinting and extraction of watermarks, achieving higher robustness against resplicing attacks and temporal flexibility in operation. Experimental results show that TraceableSpeech outperforms the strong baseline where VALL-E or HiFicodec individually uses WavMark in watermark imperceptibility, speech quality and resilience against resplicing attacks. It also can apply to speech of various durations.
Genuine-Focused Learning using Mask AutoEncoder for Generalized Fake Audio Detection
Jun 05, 2024



The generalization of Fake Audio Detection (FAD) is critical due to the emergence of new spoofing techniques. Traditional FAD methods often focus solely on distinguishing between genuine and known spoofed audio. We propose a Genuine-Focused Learning (GFL) framework guided, aiming for highly generalized FAD, called GFL-FAD. This method incorporates a Counterfactual Reasoning Enhanced Representation (CRER) based on audio reconstruction using the Mask AutoEncoder (MAE) architecture to accurately model genuine audio features. To reduce the influence of spoofed audio during training, we introduce a genuine audio reconstruction loss, maintaining the focus on learning genuine data features. In addition, content-related bottleneck (BN) features are extracted from the MAE to supplement the knowledge of the original audio. These BN features are adaptively fused with CRER to further improve robustness. Our method achieves state-of-the-art performance with an EER of 0.25% on ASVspoof2019 LA.