 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Partially Spoofed Audio Localization with Boundary-aware Attention Mechanism
Jul 31, 2024The task of partially spoofed audio localization aims to accurately determine audio authenticity at a frame level. Although some works have achieved encouraging results, utilizing boundary information within a single model remains an unexplored research topic. In this work, we propose a novel method called Boundary-aware Attention Mechanism (BAM). Specifically, it consists of two core modules: Boundary Enhancement and Boundary Frame-wise Attention. The former assembles the intra-frame and inter-frame information to extract discriminative boundary features that are subsequently used for boundary position detection and authenticity decision, while the latter leverages boundary prediction results to explicitly control the feature interaction between frames, which achieves effective discrimination between real and fake frames. Experimental results on PartialSpoof database demonstrate our proposed method achieves the best performance. The code is available at https://github.com/media-sec-lab/BAM.
An Unsupervised Domain Adaptation Method for Locating Manipulated Region in partially fake Audio
Jul 11, 2024
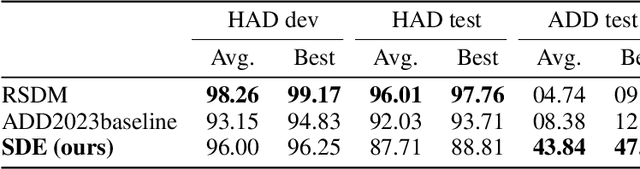
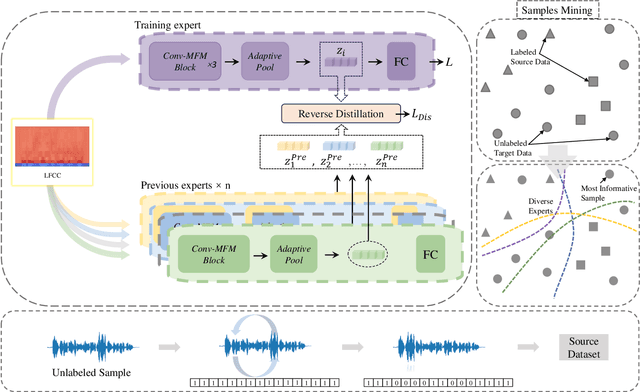

When the task of locating manipulation regions in partially-fake audio (PFA) involves cross-domain datasets, the performance of deep learning models drops significantly due to the shift between the source and target domains. To address this issue, existing approaches often employ data augmentation before training. However, they overlook the characteristics in target domain that are absent in source domain. Inspired by the mixture-of-experts model, we propose an unsupervised method named Samples mining with Diversity and Entropy (SDE). Our method first learns from a collection of diverse experts that achieve great performance from different perspectives in the source domain, but with ambiguity on target samples. We leverage these diverse experts to select the most informative samples by calculating their entropy. Furthermore, we introduced a label generation method tailored for these selected samples that are incorporated in the training process in source domain integrating the target domain information. We applied our method to a cross-domain partially fake audio detection dataset, ADD2023Track2. By introducing 10% of unknown samples from the target domain, we achieved an F1 score of 43.84%, which represents a relative increase of 77.2% compared to the second-best method.
Frequency-mix Knowledge Distillation for Fake Speech Detection
Jun 14, 2024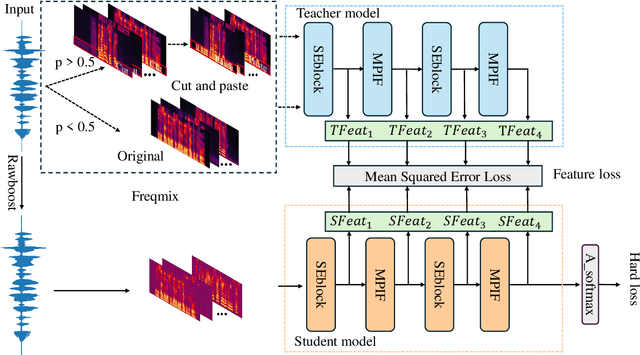
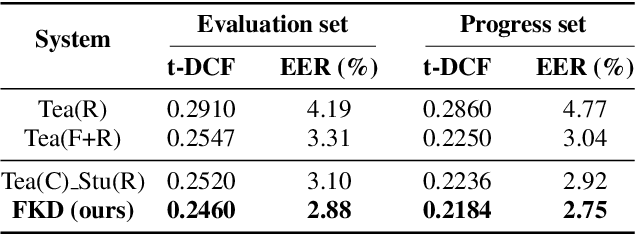
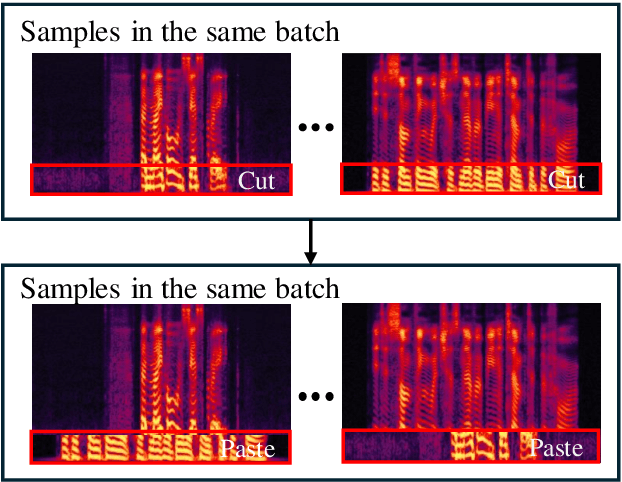
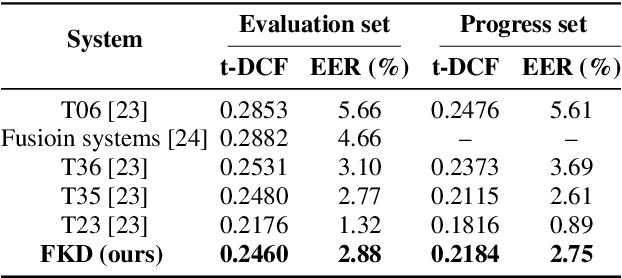
In the telephony scenarios, the fake speech detection (FSD) task to combat speech spoofing attacks is challenging. Data augmentation (DA) methods are considered effective means to address the FSD task in telephony scenarios, typically divided into time domain and frequency domain stages. While each has its advantages, both can result in information loss. To tackle this issue, we propose a novel DA method, Frequency-mix (Freqmix), and introduce the Freqmix knowledge distillation (FKD) to enhance model information extraction and generalization abilities. Specifically, we use Freqmix-enhanced data as input for the teacher model, while the student model's input undergoes time-domain DA method. We use a multi-level feature distillation approach to restore information and improve the model's generalization capabilities. Our approach achieves state-of-the-art results on ASVspoof 2021 LA dataset, showing a 31\% improvement over baseline and performs competitively on ASVspoof 2021 DF dataset.
RawBMamba: End-to-End Bidirectional State Space Model for Audio Deepfake Detection
Jun 10, 2024



Fake artefacts for discriminating between bonafide and fake audio can exist in both short- and long-range segments. Therefore, combining local and global feature information can effectively discriminate between bonafide and fake audio. This paper proposes an end-to-end bidirectional state space model, named RawBMamba, to capture both short- and long-range discriminative information for audio deepfake detection. Specifically, we use sinc Layer and multiple convolutional layers to capture short-range features, and then design a bidirectional Mamba to address Mamba's unidirectional modelling problem and further capture long-range feature information. Moreover, we develop a bidirectional fusion module to integrate embeddings, enhancing audio context representation and combining short- and long-range information. The results show that our proposed RawBMamba achieves a 34.1\% improvement over Rawformer on ASVspoof2021 LA dataset, and demonstrates competitive performance on other datasets.
TraceableSpeech: Towards Proactively Traceable Text-to-Speech with Watermarking
Jun 07, 2024



Various threats posed by the progress in text-to-speech (TTS) have prompted the need to reliably trace synthesized speech. However, contemporary approaches to this task involve adding watermarks to the audio separately after generation, a process that hurts both speech quality and watermark imperceptibility. In addition, these approaches are limited in robustness and flexibility. To address these problems, we propose TraceableSpeech, a novel TTS model that directly generates watermarked speech, improving watermark imperceptibility and speech quality. Furthermore, We design the frame-wise imprinting and extraction of watermarks, achieving higher robustness against resplicing attacks and temporal flexibility in operation. Experimental results show that TraceableSpeech outperforms the strong baseline where VALL-E or HiFicodec individually uses WavMark in watermark imperceptibility, speech quality and resilience against resplicing attacks. It also can apply to speech of various durations.
EVDA: Evolving Deepfake Audio Detection Continual Learning Benchmark
May 15, 2024The rise of advanced large language models such as GPT-4, GPT-4o, and the Claude family has made fake audio detection increasingly challenging. Traditional fine-tuning methods struggle to keep pace with the evolving landscape of synthetic speech, necessitating continual learning approaches that can adapt to new audio while retaining the ability to detect older types. Continual learning, which acts as an effective tool for detecting newly emerged deepfake audio while maintaining performance on older types, lacks a well-constructed and user-friendly evaluation framework. To address this gap, we introduce EVDA, a benchmark for evaluating continual learning methods in deepfake audio detection. EVDA includes classic datasets from the Anti-Spoofing Voice series, Chinese fake audio detection series, and newly generated deepfake audio from models like GPT-4 and GPT-4o. It supports various continual learning techniques, such as Elastic Weight Consolidation (EWC), Learning without Forgetting (LwF), and recent methods like Regularized Adaptive Weight Modification (RAWM) and Radian Weight Modification (RWM). Additionally, EVDA facilitates the development of robust algorithms by providing an open interface for integrating new continual learning methods
MER 2024: Semi-Supervised Learning, Noise Robustness, and Open-Vocabulary Multimodal Emotion Recognition
Apr 29, 2024



Multimodal emotion recognition is an important research topic in artificial intelligence. Over the past few decades, researchers have made remarkable progress by increasing dataset size and building more effective architectures. However, due to various reasons (such as complex environments and inaccurate labels), current systems still cannot meet the demands of practical applications. Therefore, we plan to organize a series of challenges around emotion recognition to further promote the development of this field. Last year, we launched MER2023, focusing on three topics: multi-label learning, noise robustness, and semi-supervised learning. This year, we continue to organize MER2024. In addition to expanding the dataset size, we introduce a new track around open-vocabulary emotion recognition. The main consideration for this track is that existing datasets often fix the label space and use majority voting to enhance annotator consistency, but this process may limit the model's ability to describe subtle emotions. In this track, we encourage participants to generate any number of labels in any category, aiming to describe the emotional state as accurately as possible. Our baseline is based on MERTools and the code is available at: https://github.com/zeroQiaoba/MERTools/tree/master/MER2024.
What to Remember: Self-Adaptive Continual Learning for Audio Deepfake Detection
Dec 15, 2023The rapid evolution of speech synthesis and voice conversion has raised substantial concerns due to the potential misuse of such technology, prompting a pressing need for effective audio deepfake detection mechanisms. Existing detection models have shown remarkable success in discriminating known deepfake audio, but struggle when encountering new attack types. To address this challenge, one of the emergent effective approaches is continual learning. In this paper, we propose a continual learning approach called Radian Weight Modification (RWM) for audio deepfake detection. The fundamental concept underlying RWM involves categorizing all classes into two groups: those with compact feature distributions across tasks, such as genuine audio, and those with more spread-out distributions, like various types of fake audio. These distinctions are quantified by means of the in-class cosine distance, which subsequently serves as the basis for RWM to introduce a trainable gradient modification direction for distinct data types. Experimental evaluations against mainstream continual learning methods reveal the superiority of RWM in terms of knowledge acquisition and mitigating forgetting in audio deepfake detection. Furthermore, RWM's applicability extends beyond audio deepfake detection, demonstrating its potential significance in diverse machine learning domains such as image recognition.
Learning to Behave Like Clean Speech: Dual-Branch Knowledge Distillation for Noise-Robust Fake Audio Detection
Oct 13, 2023



Most research in fake audio detection (FAD) focuses on improving performance on standard noise-free datasets. However, in actual situations, there is usually noise interference, which will cause significant performance degradation in FAD systems. To improve the noise robustness, we propose a dual-branch knowledge distillation fake audio detection (DKDFAD) method. Specifically, a parallel data flow of the clean teacher branch and the noisy student branch is designed, and interactive fusion and response-based teacher-student paradigms are proposed to guide the training of noisy data from the data distribution and decision-making perspectives. In the noise branch, speech enhancement is first introduced for denoising, which reduces the interference of strong noise. The proposed interactive fusion combines denoising features and noise features to reduce the impact of speech distortion and seek consistency with the data distribution of clean branch. The teacher-student paradigm maps the student's decision space to the teacher's decision space, making noisy speech behave as clean. In addition, a joint training method is used to optimize the two branches to achieve global optimality. Experimental results based on multiple datasets show that the proposed method performs well in noisy environments and maintains performance in cross-dataset experiments.
Controllable Residual Speaker Representation for Voice Conversion
Sep 15, 2023Recently, there have been significant advancements in voice conversion, resulting in high-quality performance. However, there are still two critical challenges in this field. Firstly, current voice conversion methods have limited robustness when encountering unseen speakers. Secondly, they also have limited ability to control timbre representation. To address these challenges, this paper presents a novel approach leverages tokens of multi-layer residual approximations to enhance robustness when dealing with unseen speakers, called the residual speaker module. The introduction of multi-layer approximations facilitates the separation of information from the timbre, enabling effective control over timbre in voice conversion. The proposed method outperforms baselines in both subjective and objective evaluations, demonstrating superior performance and increased robustness. Our demo page is publicly available.