 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Emotion Regression with Multi-Objective Optimization and VAD-Aware Audio Modeling for the 10th ABAW EMI Track
Mar 14, 2026We participated in the 10th ABAW Challenge, focusing on the Emotional Mimicry Intensity (EMI) Estimation track on the Hume-Vidmimic2 dataset. This task aims to predict six continuous emotion dimensions: Admiration, Amusement, Determination, Empathic Pain, Excitement, and Joy. Through systematic multimodal exploration of pretrained high-level features, we found that, under our pretrained feature setting, direct feature concatenation outperformed the more complex fusion strategies we tested. This empirical finding motivated us to design a systematic approach built upon three core principles: (i) preserving modality-specific attributes through feature-level concatenation; (ii) improving training stability and metric alignment via multi-objective optimization; and (iii) enriching acoustic representations with a VAD-inspired latent prior. Our final framework integrates concatenation-based multimodal fusion, a shared six-dimensional regression head, multi-objective optimization with MSE, Pearson-correlation, and auxiliary branch supervision, EMA for parameter stabilization, and a VAD-inspired latent prior for the acoustic branch. On the official validation set, the proposed scheme achieved our best mean Pearson Correlation Coefficient of 0.478567.
MER 2024: Semi-Supervised Learning, Noise Robustness, and Open-Vocabulary Multimodal Emotion Recognition
Apr 29, 2024



Multimodal emotion recognition is an important research topic in artificial intelligence. Over the past few decades, researchers have made remarkable progress by increasing dataset size and building more effective architectures. However, due to various reasons (such as complex environments and inaccurate labels), current systems still cannot meet the demands of practical applications. Therefore, we plan to organize a series of challenges around emotion recognition to further promote the development of this field. Last year, we launched MER2023, focusing on three topics: multi-label learning, noise robustness, and semi-supervised learning. This year, we continue to organize MER2024. In addition to expanding the dataset size, we introduce a new track around open-vocabulary emotion recognition. The main consideration for this track is that existing datasets often fix the label space and use majority voting to enhance annotator consistency, but this process may limit the model's ability to describe subtle emotions. In this track, we encourage participants to generate any number of labels in any category, aiming to describe the emotional state as accurately as possible. Our baseline is based on MERTools and the code is available at: https://github.com/zeroQiaoba/MERTools/tree/master/MER2024.
GPT-4V with Emotion: A Zero-shot Benchmark for Multimodal Emotion Understanding
Dec 07, 2023



Recently, GPT-4 with Vision (GPT-4V) has shown remarkable performance across various multimodal tasks. However, its efficacy in emotion recognition remains a question. This paper quantitatively evaluates GPT-4V's capabilities in multimodal emotion understanding, encompassing tasks such as facial emotion recognition, visual sentiment analysis, micro-expression recognition, dynamic facial emotion recognition, and multimodal emotion recognition. Our experiments show that GPT-4V exhibits impressive multimodal and temporal understanding capabilities, even surpassing supervised systems in some tasks. Despite these achievements, GPT-4V is currently tailored for general domains. It performs poorly in micro-expression recognition that requires specialized expertise. The main purpose of this paper is to present quantitative results of GPT-4V on emotion understanding and establish a zero-shot benchmark for future research. Code and evaluation results are available at: https://github.com/zeroQiaoba/gpt4v-emotion.
LSTM Fully Convolutional Networks for Time Series Classification
Sep 08, 2017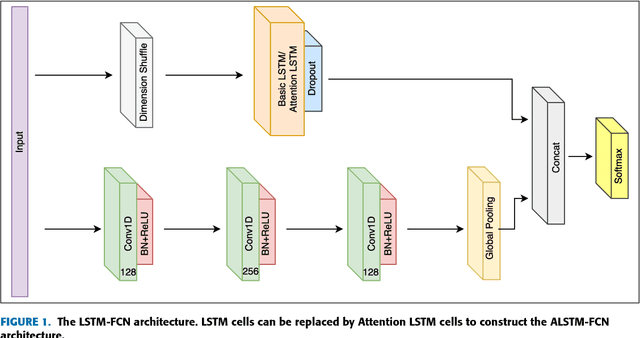
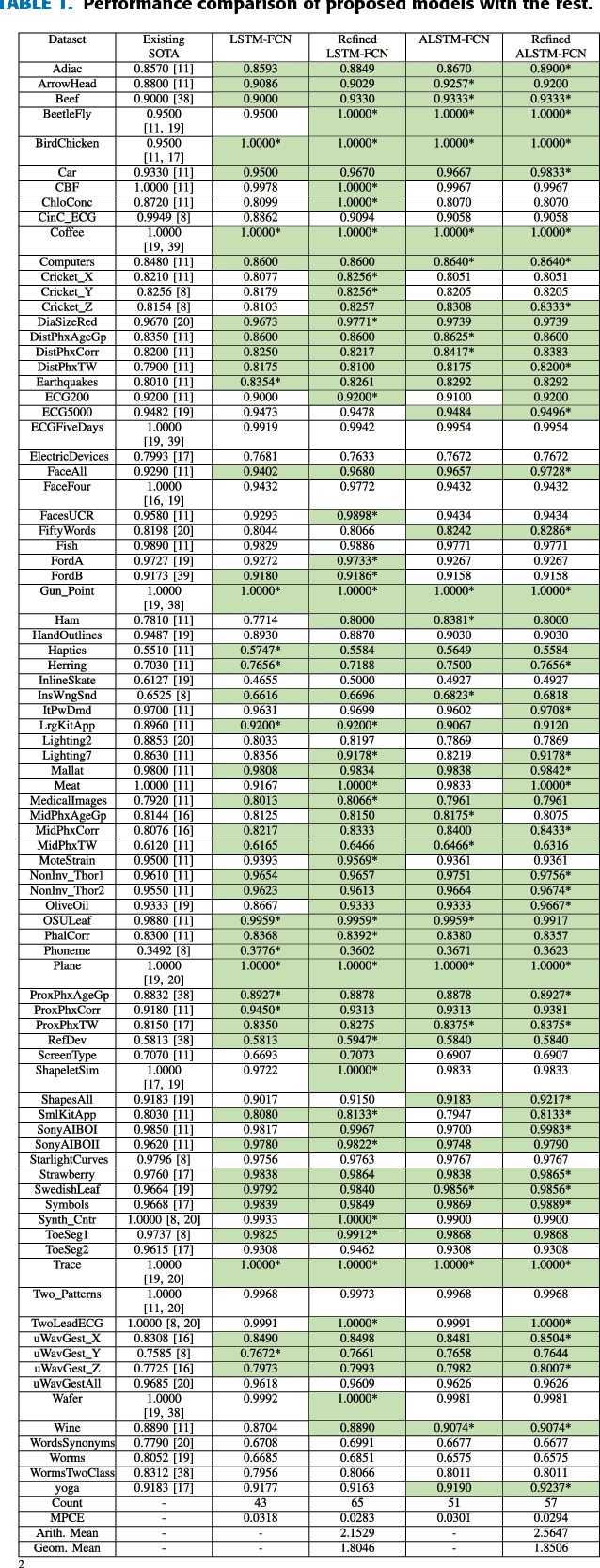
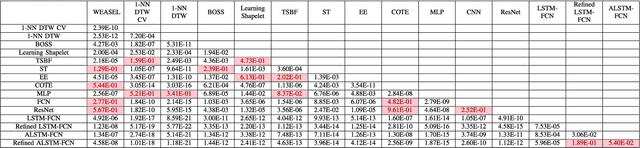
Fully convolutional neural networks (FCN) have been shown to achieve state-of-the-art performance on the task of classifying time series sequences. We propose the augmentation of fully convolutional networks with long short term memory recurrent neural network (LSTM RNN) sub-modules for time series classification. Our proposed models significantly enhance the performance of fully convolutional networks with a nominal increase in model size and require minimal preprocessing of the dataset. The proposed Long Short Term Memory Fully Convolutional Network (LSTM-FCN) achieves state-of-the-art performance compared to others. We also explore the usage of attention mechanism to improve time series classification with the Attention Long Short Term Memory Fully Convolutional Network (ALSTM-FCN). Utilization of the attention mechanism allows one to visualize the decision process of the LSTM cell. Furthermore, we propose fine-tuning as a method to enhance the performance of trained models. An overall analysis of the performance of our model is provided and compared to other techniques.