 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Brain Ultrasound Ablation Thermal Dose Modeling with in Vivo Experimental Validation
Sep 04, 2024



Intracorporeal needle-based therapeutic ultrasound (NBTU) is a minimally invasive option for intervening in malignant brain tumors, commonly used in thermal ablation procedures. This technique is suitable for both primary and metastatic cancers, utilizing a high-frequency alternating electric field (up to 10 MHz) to excite a piezoelectric transducer. The resulting rapid deformation of the transducer produces an acoustic wave that propagates through tissue, leading to localized high-temperature heating at the target tumor site and inducing rapid cell death. To optimize the design of NBTU transducers for thermal dose delivery during treatment, numerical modeling of the acoustic pressure field generated by the deforming piezoelectric transducer is frequently employed. The bioheat transfer process generated by the input pressure field is used to track the thermal propagation of the applicator over time. Magnetic resonance thermal imaging (MRTI) can be used to experimentally validate these models. Validation results using MRTI demonstrated the feasibility of this model, showing a consistent thermal propagation pattern. However, a thermal damage isodose map is more advantageous for evaluating therapeutic efficacy. To achieve a more accurate simulation based on the actual brain tissue environment, a new finite element method (FEM) simulation with enhanced damage evaluation capabilities was conducted. The results showed that the highest temperature and ablated volume differed between experimental and simulation results by 2.1884{\deg}C (3.71%) and 0.0631 cm$^3$ (5.74%), respectively. The lowest Pearson correlation coefficient (PCC) for peak temperature was 0.7117, and the lowest Dice coefficient for the ablated area was 0.7021, indicating a good agreement in accuracy between simulation and experiment.
One-shot Localization and Segmentation of Medical Images with Foundation Models
Oct 28, 2023



Recent advances in Vision Transformers (ViT) and Stable Diffusion (SD) models with their ability to capture rich semantic features of the image have been used for image correspondence tasks on natural images. In this paper, we examine the ability of a variety of pre-trained ViT (DINO, DINOv2, SAM, CLIP) and SD models, trained exclusively on natural images, for solving the correspondence problems on medical images. While many works have made a case for in-domain training, we show that the models trained on natural images can offer good performance on medical images across different modalities (CT,MR,Ultrasound) sourced from various manufacturers, over multiple anatomical regions (brain, thorax, abdomen, extremities), and on wide variety of tasks. Further, we leverage the correspondence with respect to a template image to prompt a Segment Anything (SAM) model to arrive at single shot segmentation, achieving dice range of 62%-90% across tasks, using just one image as reference. We also show that our single-shot method outperforms the recently proposed few-shot segmentation method - UniverSeg (Dice range 47%-80%) on most of the semantic segmentation tasks(six out of seven) across medical imaging modalities.
Towards Emergent Language Symbolic Semantic Segmentation and Model Interpretability
Aug 04, 2020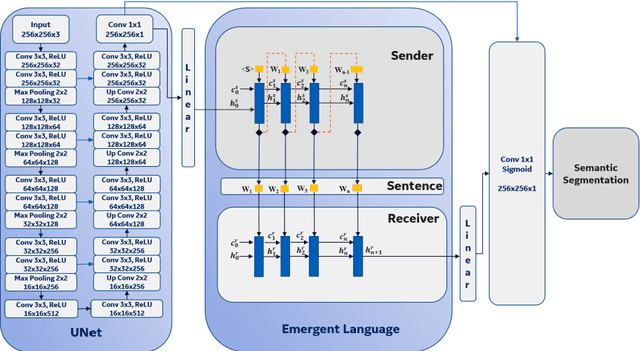
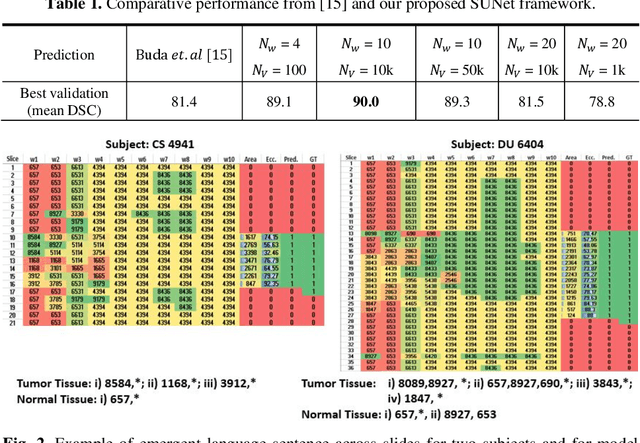
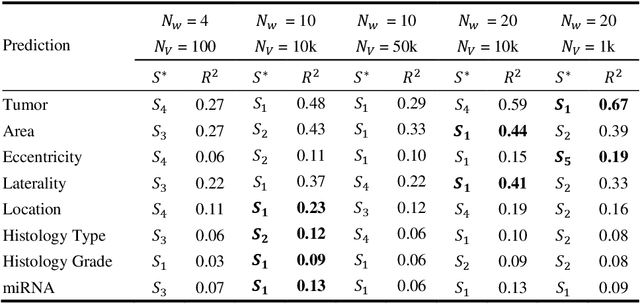
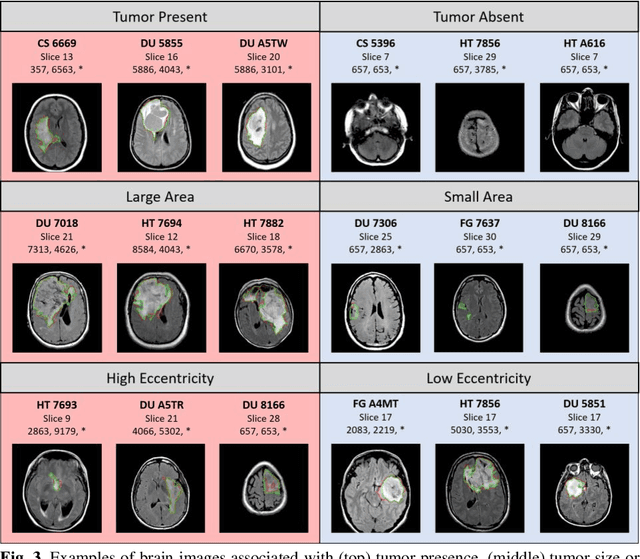
Recent advances in methods focused on the grounding problem have resulted in techniques that can be used to construct a symbolic language associated with a specific domain. Inspired by how humans communicate complex ideas through language, we developed a generalized Symbolic Semantic ($\text{S}^2$) framework for interpretable segmentation. Unlike adversarial models (e.g., GANs), we explicitly model cooperation between two agents, a Sender and a Receiver, that must cooperate to achieve a common goal. The Sender receives information from a high layer of a segmentation network and generates a symbolic sentence derived from a categorical distribution. The Receiver obtains the symbolic sentences and co-generates the segmentation mask. In order for the model to converge, the Sender and Receiver must learn to communicate using a private language. We apply our architecture to segment tumors in the TCGA dataset. A UNet-like architecture is used to generate input to the Sender network which produces a symbolic sentence, and a Receiver network co-generates the segmentation mask based on the sentence. Our Segmentation framework achieved similar or better performance compared with state-of-the-art segmentation methods. In addition, our results suggest direct interpretation of the symbolic sentences to discriminate between normal and tumor tissue, tumor morphology, and other image characteristics.
Variational Encoder-based Reliable Classification
Feb 19, 2020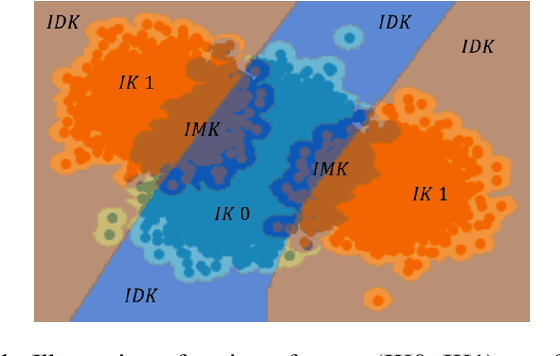
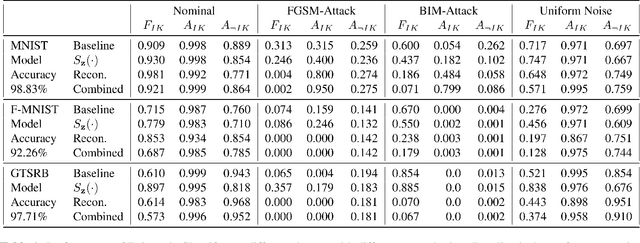
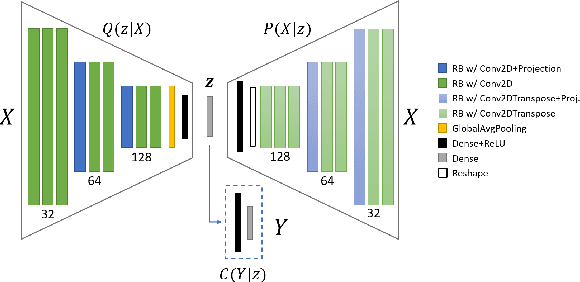
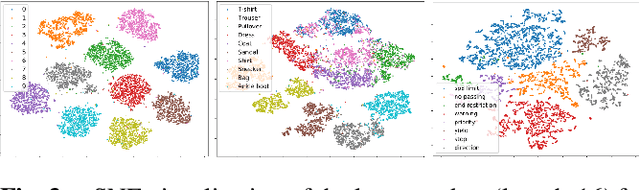
Machine learning models provide statistically impressive results which might be individually unreliable. To provide reliability, we propose an Epistemic Classifier (EC) that can provide justification of its belief using support from the training dataset as well as quality of reconstruction. Our approach is based on modified variational auto-encoders that can identify a semantically meaningful low-dimensional space where perceptually similar instances are close in $\ell_2$-distance too. Our results demonstrate improved reliability of predictions and robust identification of samples with adversarial attacks as compared to baseline of softmax-based thresholding.