 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRetrieval Augmented Cross-Modal Tag Recommendation in Software Q&A Sites
Feb 06, 2024Posts in software Q\&A sites often consist of three main parts: title, description and code, which are interconnected and jointly describe the question. Existing tag recommendation methods often treat different modalities as a whole or inadequately consider the interaction between different modalities. Additionally, they focus on extracting information directly from the post itself, neglecting the information from external knowledge sources. Therefore, we propose a Retrieval Augmented Cross-Modal (RACM) Tag Recommendation Model in Software Q\&A Sites. Specifically, we first use the input post as a query and enhance the representation of different modalities by retrieving information from external knowledge sources. For the retrieval-augmented representations, we employ a cross-modal context-aware attention to leverage the main modality description for targeted feature extraction across the submodalities title and code. In the fusion process, a gate mechanism is employed to achieve fine-grained feature selection, controlling the amount of information extracted from the submodalities. Finally, the fused information is used for tag recommendation. Experimental results on three real-world datasets demonstrate that our model outperforms the state-of-the-art counterparts.
Parallax-Tolerant Image Stitching with Epipolar Displacement Field
Nov 28, 2023Large parallax image stitching is a challenging task. Existing methods often struggle to maintain both the local and global structures of the image while reducing alignment artifacts and warping distortions. In this paper, we propose a novel approach that utilizes epipolar geometry to establish a warping technique based on the epipolar displacement field. Initially, the warping rule for pixels in the epipolar geometry is established through the infinite homography. Subsequently, Subsequently, the epipolar displacement field, which represents the sliding distance of the warped pixel along the epipolar line, is formulated by thin plate splines based on the principle of local elastic deformation. The stitching result can be generated by inversely warping the pixels according to the epipolar displacement field. This method incorporates the epipolar constraints in the warping rule, which ensures high-quality alignment and maintains the projectivity of the panorama. Qualitative and quantitative comparative experiments demonstrate the competitiveness of the proposed method in stitching images large parallax.
Windformer:Bi-Directional Long-Distance Spatio-Temporal Network For Wind Speed Prediction
Nov 24, 2023Wind speed prediction is critical to the management of wind power generation. Due to the large range of wind speed fluctuations and wake effect, there may also be strong correlations between long-distance wind turbines. This difficult-to-extract feature has become a bottleneck for improving accuracy. History and future time information includes the trend of airflow changes, whether this dynamic information can be utilized will also affect the prediction effect. In response to the above problems, this paper proposes Windformer. First, Windformer divides the wind turbine cluster into multiple non-overlapping windows and calculates correlations inside the windows, then shifts the windows partially to provide connectivity between windows, and finally fuses multi-channel features based on detailed and global information. To dynamically model the change process of wind speed, this paper extracts time series in both history and future directions simultaneously. Compared with other current-advanced methods, the Mean Square Error (MSE) of Windformer is reduced by 0.5\% to 15\% on two datasets from NERL.
A meta learning scheme for fast accent domain expansion in Mandarin speech recognition
Jul 23, 2023Spoken languages show significant variation across mandarin and accent. Despite the high performance of mandarin automatic speech recognition (ASR), accent ASR is still a challenge task. In this paper, we introduce meta-learning techniques for fast accent domain expansion in mandarin speech recognition, which expands the field of accents without deteriorating the performance of mandarin ASR. Meta-learning or learn-to-learn can learn general relation in multi domains not only for over-fitting a specific domain. So we select meta-learning in the domain expansion task. This more essential learning will cause improved performance on accent domain extension tasks. We combine the methods of meta learning and freeze of model parameters, which makes the recognition performance more stable in different cases and the training faster about 20%. Our approach significantly outperforms other methods about 3% relatively in the accent domain expansion task. Compared to the baseline model, it improves relatively 37% under the condition that the mandarin test set remains unchanged. In addition, it also proved this method to be effective on a large amount of data with a relative performance improvement of 4% on the accent test set.
SST-ReversibleNet: Reversible-prior-based Spectral-Spatial Transformer for Efficient Hyperspectral Image Reconstruction
May 06, 2023



Spectral image reconstruction is an important task in snapshot compressed imaging. This paper aims to propose a new end-to-end framework with iterative capabilities similar to a deep unfolding network to improve reconstruction accuracy, independent of optimization conditions, and to reduce the number of parameters. A novel framework called the reversible-prior-based method is proposed. Inspired by the reversibility of the optical path, the reversible-prior-based framework projects the reconstructions back into the measurement space, and then the residuals between the projected data and the real measurements are fed into the network for iteration. The reconstruction subnet in the network then learns the mapping of the residuals to the true values to improve reconstruction accuracy. In addition, a novel spectral-spatial transformer is proposed to account for the global correlation of spectral data in both spatial and spectral dimensions while balancing network depth and computational complexity, in response to the shortcomings of existing transformer-based denoising modules that ignore spatial texture features or learn local spatial features at the expense of global spatial features. Extensive experiments show that our SST-ReversibleNet significantly outperforms state-of-the-art methods on simulated and real HSI datasets, while requiring lower computational and storage costs. https://github.com/caizeyu1992/SST
IDPL: Intra-subdomain adaptation adversarial learning segmentation method based on Dynamic Pseudo Labels
Oct 07, 2022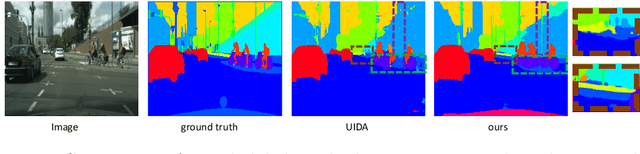

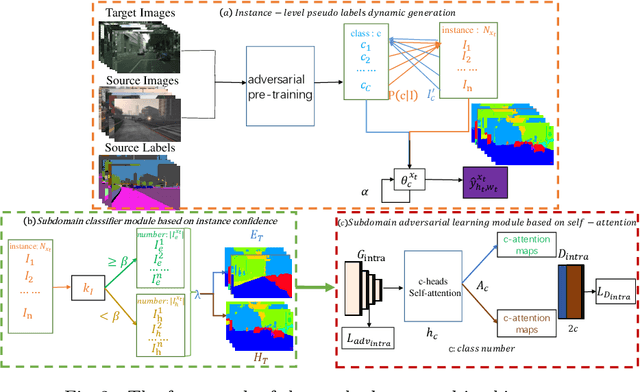
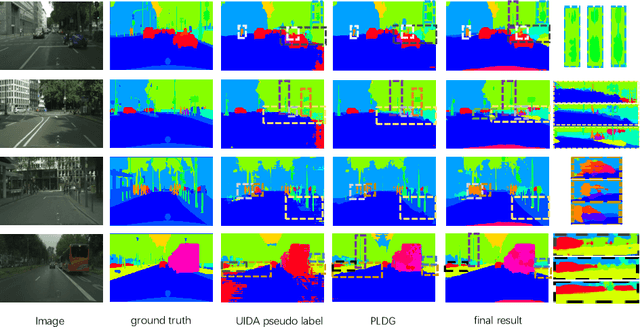
Unsupervised domain adaptation(UDA) has been applied to image semantic segmentation to solve the problem of domain offset. However, in some difficult categories with poor recognition accuracy, the segmentation effects are still not ideal. To this end, in this paper, Intra-subdomain adaptation adversarial learning segmentation method based on Dynamic Pseudo Labels(IDPL) is proposed. The whole process consists of 3 steps: Firstly, the instance-level pseudo label dynamic generation module is proposed, which fuses the class matching information in global classes and local instances, thus adaptively generating the optimal threshold for each class, obtaining high-quality pseudo labels. Secondly, the subdomain classifier module based on instance confidence is constructed, which can dynamically divide the target domain into easy and difficult subdomains according to the relative proportion of easy and difficult instances. Finally, the subdomain adversarial learning module based on self-attention is proposed. It uses multi-head self-attention to confront the easy and difficult subdomains at the class level with the help of generated high-quality pseudo labels, so as to focus on mining the features of difficult categories in the high-entropy region of target domain images, which promotes class-level conditional distribution alignment between the subdomains, improving the segmentation performance of difficult categories. For the difficult categories, the experimental results show that the performance of IDPL is significantly improved compared with other latest mainstream methods.
* Accepted at The 29th International Conference on Neural Information Processing (ICONIP 2022)
Nextformer: A ConvNeXt Augmented Conformer For End-To-End Speech Recognition
Jun 30, 2022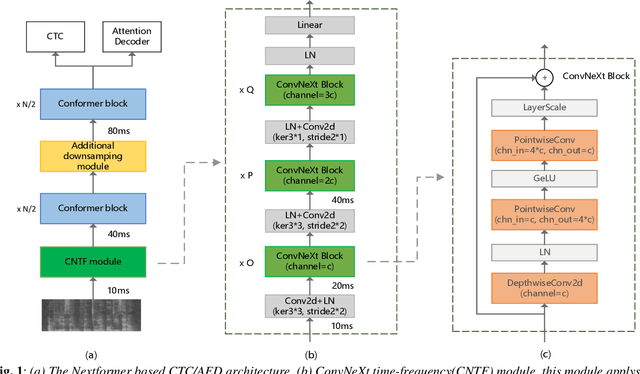
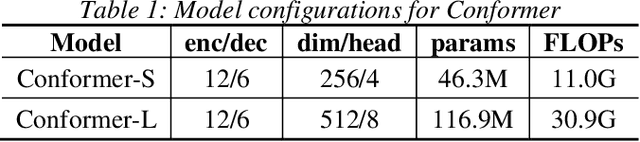
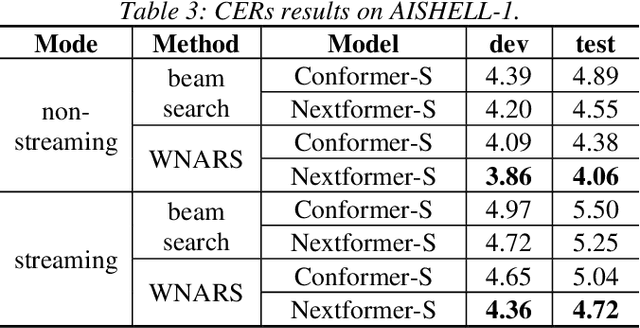
Conformer models have achieved state-of-the-art(SOTA) results in end-to-end speech recognition. However Conformer mainly focuses on temporal modeling while pays less attention on time-frequency property of speech feature. In this paper we augment Conformer with ConvNeXt and propose Nextformer structure. We use stacks of ConvNeXt block to replace the commonly used subsampling module in Conformer for utilizing the information contained in time-frequency speech feature. Besides, we insert an additional downsampling module in middle of Conformer layers to make our model more efficient and accurate. We conduct experiments on two opening datasets, AISHELL-1 and WenetSpeech. On AISHELL-1, compared to Conformer baselines, Nextformer obtains 7.3% and 6.3% relative CER reduction in non-streaming and streaming mode respectively, and on a much larger WenetSpeech dataset, Nextformer gives 5.0%~6.5% and 7.5%~14.6% relative CER reduction in non-streaming and streaming mode, while keep the computational cost FLOPs comparable to Conformer. To the best of our knowledge, the proposed Nextformer model achieves SOTA results on AISHELL-1(CER 4.06%) and WenetSpeech(CER 7.56%/11.29%).
Deep Embedded Clustering with Distribution Consistency Preservation for Attributed Networks
May 28, 2022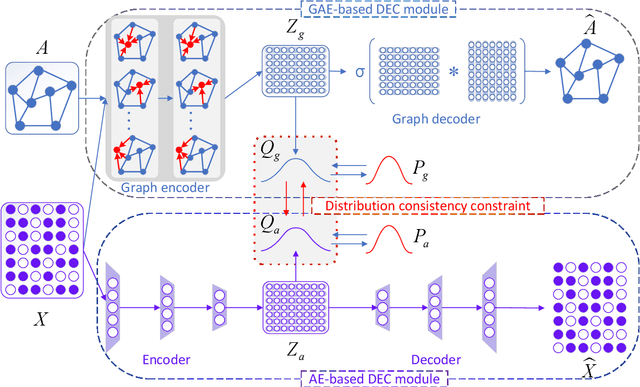
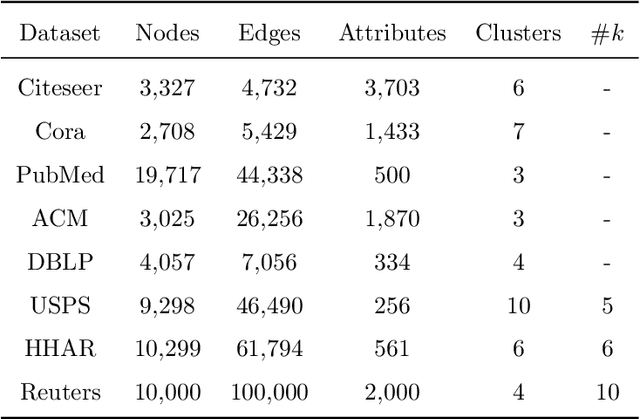

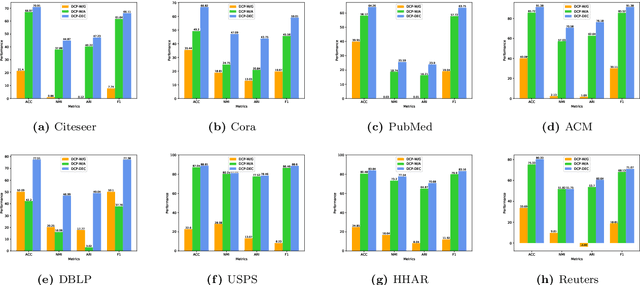
Many complex systems in the real world can be characterized by attributed networks. To mine the potential information in these networks, deep embedded clustering, which obtains node representations and clusters simultaneously, has been paid much attention in recent years. Under the assumption of consistency for data in different views, the cluster structure of network topology and that of node attributes should be consistent for an attributed network. However, many existing methods ignore this property, even though they separately encode node representations from network topology and node attributes meanwhile clustering nodes on representation vectors learnt from one of the views. Therefore, in this study, we propose an end-to-end deep embedded clustering model for attributed networks. It utilizes graph autoencoder and node attribute autoencoder to respectively learn node representations and cluster assignments. In addition, a distribution consistency constraint is introduced to maintain the latent consistency of cluster distributions of two views. Extensive experiments on several datasets demonstrate that the proposed model achieves significantly better or competitive performance compared with the state-of-the-art methods. The source code can be found at https://github.com/Zhengymm/DCP.
Non-generative Generalized Zero-shot Learning via Task-correlated Disentanglement and Controllable Samples Synthesis
Mar 13, 2022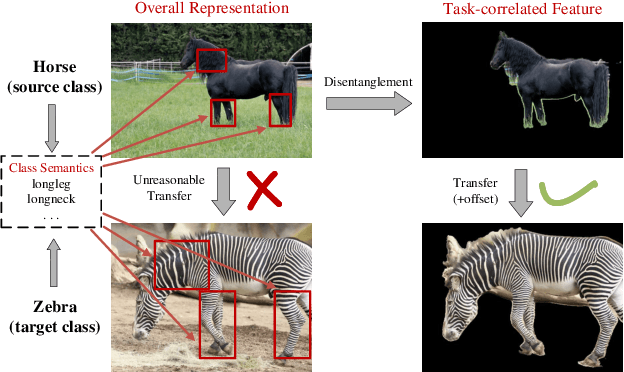
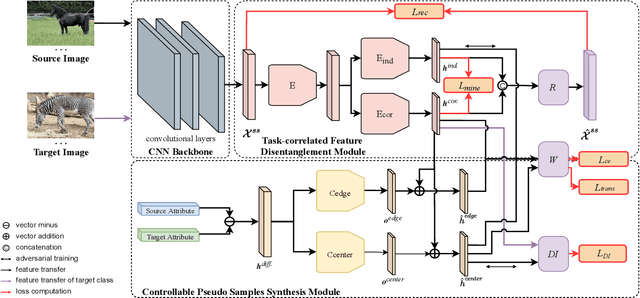
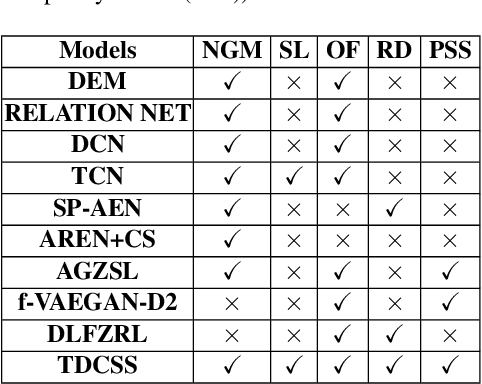
Synthesizing pseudo samples is currently the most effective way to solve the Generalized Zero Shot Learning (GZSL) problem. Most models achieve competitive performance but still suffer from two problems: (1) Feature confounding, the overall representations confound task-correlated and task-independent features, and existing models disentangle them in a generative way, but they are unreasonable to synthesize reliable pseudo samples with limited samples; (2) Distribution uncertainty, that massive data is needed when existing models synthesize samples from the uncertain distribution, which causes poor performance in limited samples of seen classes. In this paper, we propose a non-generative model to address these problems correspondingly in two modules: (1) Task-correlated feature disentanglement, to exclude the task-correlated features from task-independent ones by adversarial learning of domain adaption towards reasonable synthesis; (2) Controllable pseudo sample synthesis, to synthesize edge-pseudo and center-pseudo samples with certain characteristics towards more diversity generated and intuitive transfer. In addation, to describe the new scene that is the limit seen class samples in the training process, we further formulate a new ZSL task named the 'Few-shot Seen class and Zero-shot Unseen class learning' (FSZU). Extensive experiments on four benchmarks verify that the proposed method is competitive in the GZSL and the FSZU tasks.
Learning to Learn a Cold-start Sequential Recommender
Oct 18, 2021
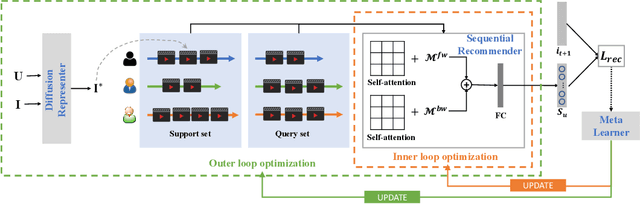
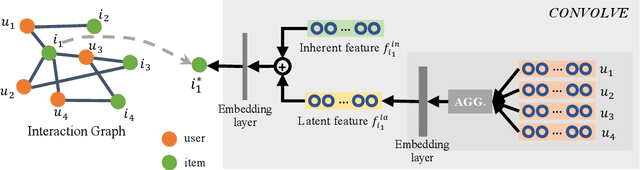
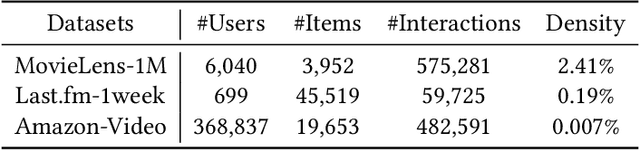
The cold-start recommendation is an urgent problem in contemporary online applications. It aims to provide users whose behaviors are literally sparse with as accurate recommendations as possible. Many data-driven algorithms, such as the widely used matrix factorization, underperform because of data sparseness. This work adopts the idea of meta-learning to solve the user's cold-start recommendation problem. We propose a meta-learning based cold-start sequential recommendation framework called metaCSR, including three main components: Diffusion Representer for learning better user/item embedding through information diffusion on the interaction graph; Sequential Recommender for capturing temporal dependencies of behavior sequences; Meta Learner for extracting and propagating transferable knowledge of prior users and learning a good initialization for new users. metaCSR holds the ability to learn the common patterns from regular users' behaviors and optimize the initialization so that the model can quickly adapt to new users after one or a few gradient updates to achieve optimal performance. The extensive quantitative experiments on three widely-used datasets show the remarkable performance of metaCSR in dealing with user cold-start problem. Meanwhile, a series of qualitative analysis demonstrates that the proposed metaCSR has good generalization.