 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysical probes expose and alleviate chemical-environment collapse in molecular representations
May 11, 2026Nuclear magnetic resonance (NMR) spectroscopy provides an experimental readout of local chemical environments, but its use in molecular representation learning has been constrained by heterogeneous data and incomplete atom-level assignments. Here we construct complementary high-fidelity experimental and computational 13C NMR resources, which reveal a recurrent form of representational collapse: atoms that are equivalent in molecular topology can remain experimentally distinct in their real chemical environments, whereas explicit 3D descriptions are further limited by static conformations in dynamic regimes. To alleviate this bottleneck, we develop CLAIM (Contrastive Learning for Atom-to-molecule Inference of Molecular NMR), a framework that aligns efficient topological molecular inputs with atom-resolved NMR observables. Through hierarchical chemical priors and cross-level contrastive learning, CLAIM restores lost chemical resolution and markedly improves atom-level molecule-spectrum retrieval. CLAIM remains robust in flexible and tautomeric systems for 13C NMR prediction, improves stereoisomer discrimination without explicit 3D modelling, and transfers to broader molecular property tasks including ADMET prediction and fluorescence estimation. These results establish physically grounded spectral alignment as an effective strategy for alleviating chemical-environment collapse and for guiding experimentally grounded molecular representation learning.
Nextformer: A ConvNeXt Augmented Conformer For End-To-End Speech Recognition
Jun 30, 2022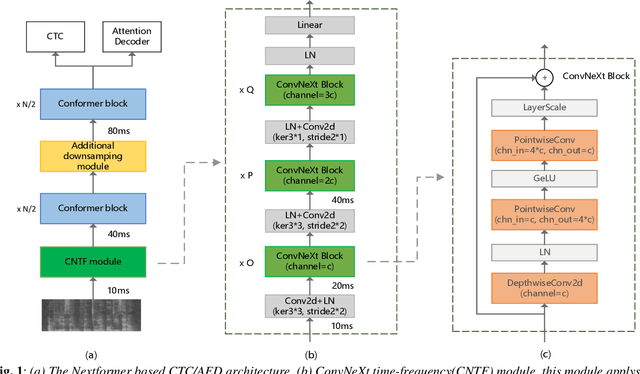
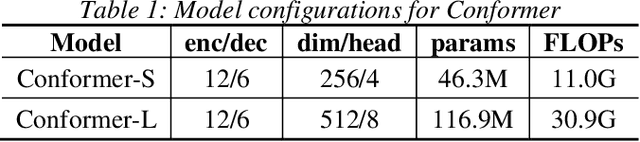
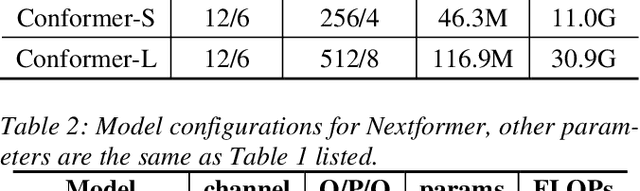
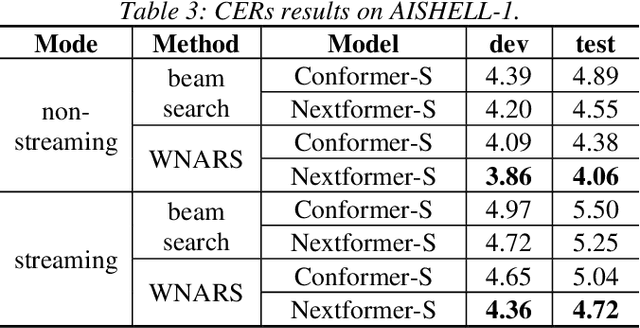
Conformer models have achieved state-of-the-art(SOTA) results in end-to-end speech recognition. However Conformer mainly focuses on temporal modeling while pays less attention on time-frequency property of speech feature. In this paper we augment Conformer with ConvNeXt and propose Nextformer structure. We use stacks of ConvNeXt block to replace the commonly used subsampling module in Conformer for utilizing the information contained in time-frequency speech feature. Besides, we insert an additional downsampling module in middle of Conformer layers to make our model more efficient and accurate. We conduct experiments on two opening datasets, AISHELL-1 and WenetSpeech. On AISHELL-1, compared to Conformer baselines, Nextformer obtains 7.3% and 6.3% relative CER reduction in non-streaming and streaming mode respectively, and on a much larger WenetSpeech dataset, Nextformer gives 5.0%~6.5% and 7.5%~14.6% relative CER reduction in non-streaming and streaming mode, while keep the computational cost FLOPs comparable to Conformer. To the best of our knowledge, the proposed Nextformer model achieves SOTA results on AISHELL-1(CER 4.06%) and WenetSpeech(CER 7.56%/11.29%).