 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOff-Policy Reinforcement Learning with Delayed Rewards
Jun 22, 2021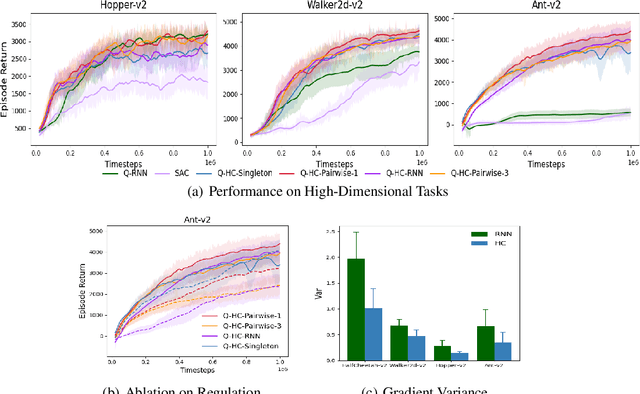
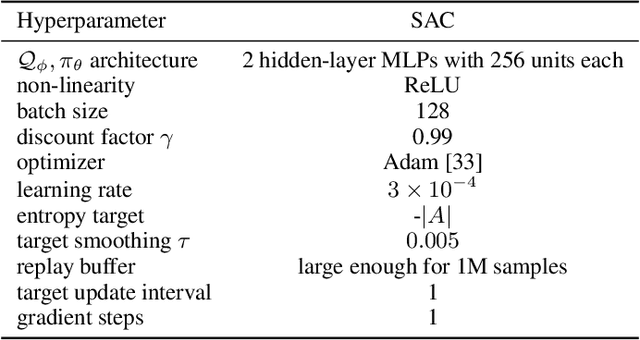
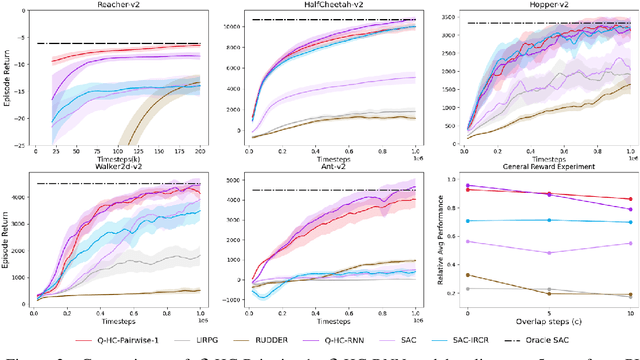
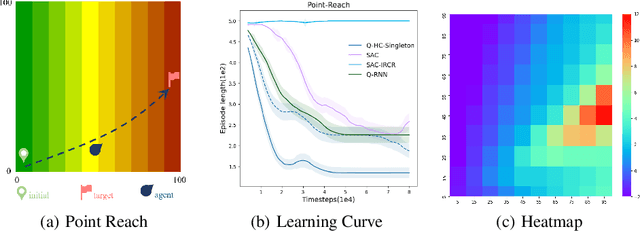
We study deep reinforcement learning (RL) algorithms with delayed rewards. In many real-world tasks, instant rewards are often not readily accessible or even defined immediately after the agent performs actions. In this work, we first formally define the environment with delayed rewards and discuss the challenges raised due to the non-Markovian nature of such environments. Then, we introduce a general off-policy RL framework with a new Q-function formulation that can handle the delayed rewards with theoretical convergence guarantees. For practical tasks with high dimensional state spaces, we further introduce the HC-decomposition rule of the Q-function in our framework which naturally leads to an approximation scheme that helps boost the training efficiency and stability. We finally conduct extensive experiments to demonstrate the superior performance of our algorithms over the existing work and their variants.
DAP: Detection-Aware Pre-training with Weak Supervision
Mar 30, 2021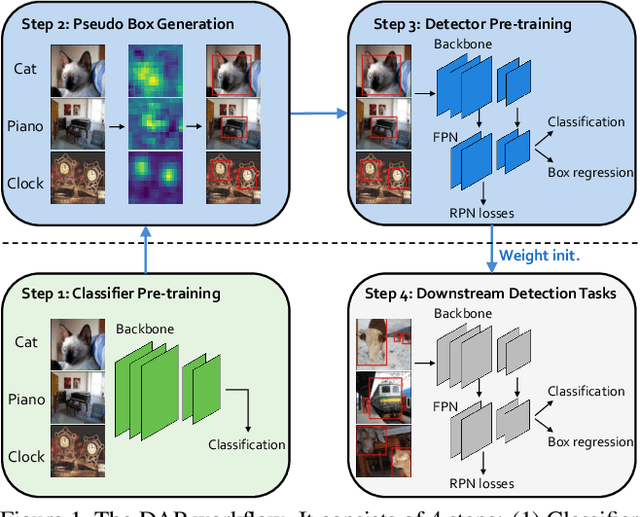
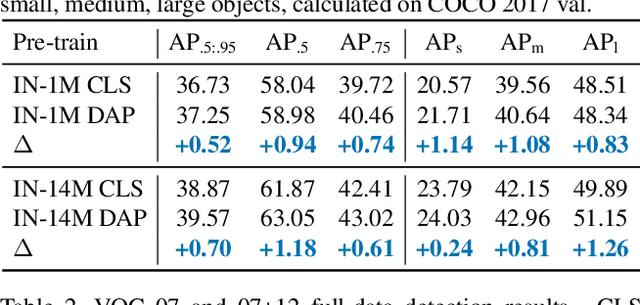
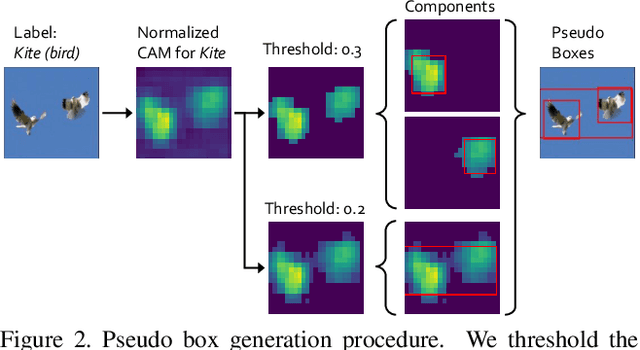
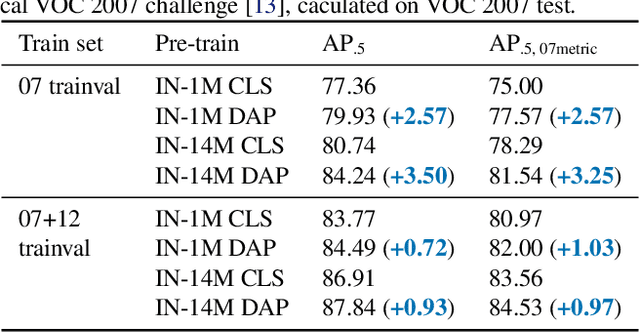
This paper presents a detection-aware pre-training (DAP) approach, which leverages only weakly-labeled classification-style datasets (e.g., ImageNet) for pre-training, but is specifically tailored to benefit object detection tasks. In contrast to the widely used image classification-based pre-training (e.g., on ImageNet), which does not include any location-related training tasks, we transform a classification dataset into a detection dataset through a weakly supervised object localization method based on Class Activation Maps to directly pre-train a detector, making the pre-trained model location-aware and capable of predicting bounding boxes. We show that DAP can outperform the traditional classification pre-training in terms of both sample efficiency and convergence speed in downstream detection tasks including VOC and COCO. In particular, DAP boosts the detection accuracy by a large margin when the number of examples in the downstream task is small.
Learning Neural Generative Dynamics for Molecular Conformation Generation
Feb 28, 2021
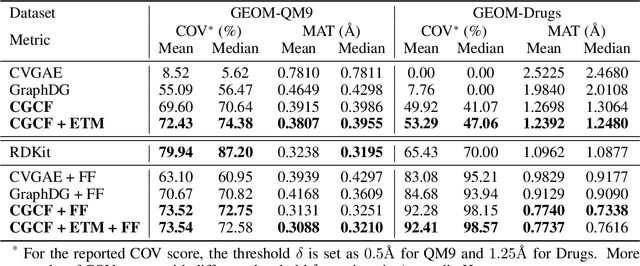
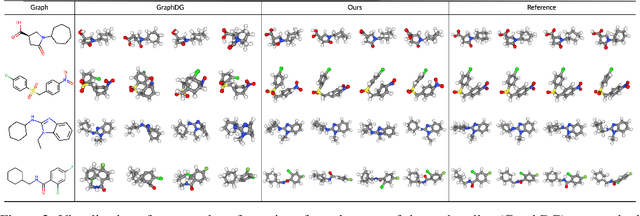
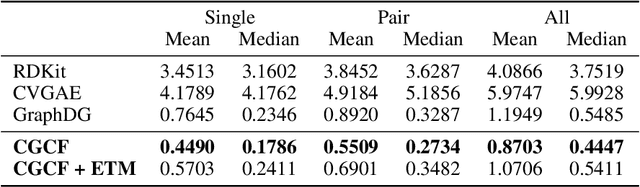
We study how to generate molecule conformations (\textit{i.e.}, 3D structures) from a molecular graph. Traditional methods, such as molecular dynamics, sample conformations via computationally expensive simulations. Recently, machine learning methods have shown great potential by training on a large collection of conformation data. Challenges arise from the limited model capacity for capturing complex distributions of conformations and the difficulty in modeling long-range dependencies between atoms. Inspired by the recent progress in deep generative models, in this paper, we propose a novel probabilistic framework to generate valid and diverse conformations given a molecular graph. We propose a method combining the advantages of both flow-based and energy-based models, enjoying: (1) a high model capacity to estimate the multimodal conformation distribution; (2) explicitly capturing the complex long-range dependencies between atoms in the observation space. Extensive experiments demonstrate the superior performance of the proposed method on several benchmarks, including conformation generation and distance modeling tasks, with a significant improvement over existing generative models for molecular conformation sampling.
Harnessing Distribution Ratio Estimators for Learning Agents with Quality and Diversity
Nov 05, 2020


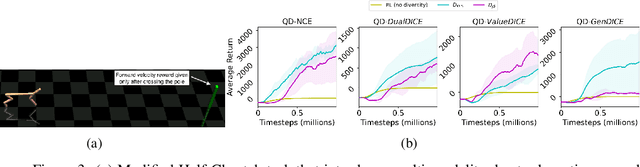
Quality-Diversity (QD) is a concept from Neuroevolution with some intriguing applications to Reinforcement Learning. It facilitates learning a population of agents where each member is optimized to simultaneously accumulate high task-returns and exhibit behavioral diversity compared to other members. In this paper, we build on a recent kernel-based method for training a QD policy ensemble with Stein variational gradient descent. With kernels based on $f$-divergence between the stationary distributions of policies, we convert the problem to that of efficient estimation of the ratio of these stationary distributions. We then study various distribution ratio estimators used previously for off-policy evaluation and imitation and re-purpose them to compute the gradients for policies in an ensemble such that the resultant population is diverse and of high-quality.
Off-Policy Interval Estimation with Lipschitz Value Iteration
Oct 29, 2020
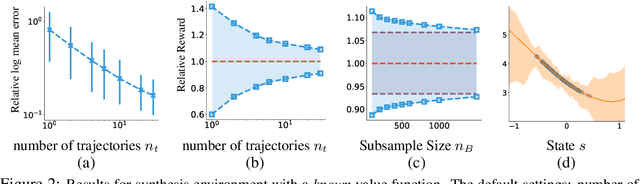
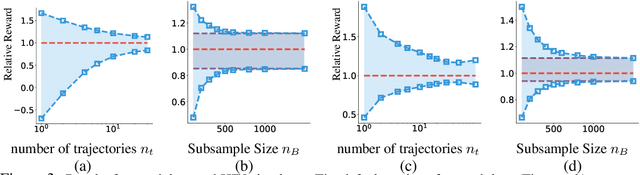
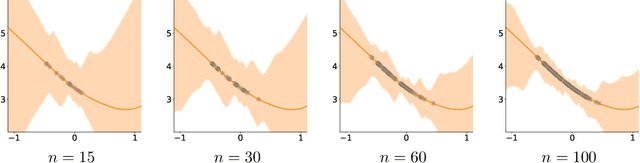
Off-policy evaluation provides an essential tool for evaluating the effects of different policies or treatments using only observed data. When applied to high-stakes scenarios such as medical diagnosis or financial decision-making, it is crucial to provide provably correct upper and lower bounds of the expected reward, not just a classical single point estimate, to the end-users, as executing a poor policy can be very costly. In this work, we propose a provably correct method for obtaining interval bounds for off-policy evaluation in a general continuous setting. The idea is to search for the maximum and minimum values of the expected reward among all the Lipschitz Q-functions that are consistent with the observations, which amounts to solving a constrained optimization problem on a Lipschitz function space. We go on to introduce a Lipschitz value iteration method to monotonically tighten the interval, which is simple yet efficient and provably convergent. We demonstrate the practical efficiency of our method on a range of benchmarks.
Learning Guidance Rewards with Trajectory-space Smoothing
Oct 23, 2020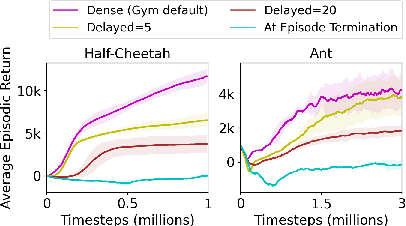

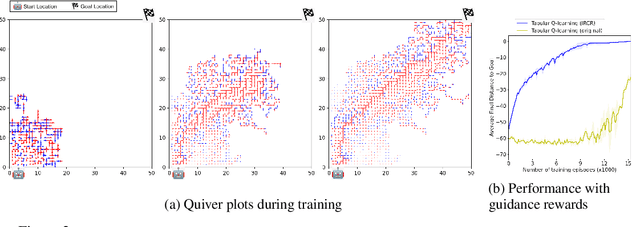
Long-term temporal credit assignment is an important challenge in deep reinforcement learning (RL). It refers to the ability of the agent to attribute actions to consequences that may occur after a long time interval. Existing policy-gradient and Q-learning algorithms typically rely on dense environmental rewards that provide rich short-term supervision and help with credit assignment. However, they struggle to solve tasks with delays between an action and the corresponding rewarding feedback. To make credit assignment easier, recent works have proposed algorithms to learn dense "guidance" rewards that could be used in place of the sparse or delayed environmental rewards. This paper is in the same vein -- starting with a surrogate RL objective that involves smoothing in the trajectory-space, we arrive at a new algorithm for learning guidance rewards. We show that the guidance rewards have an intuitive interpretation, and can be obtained without training any additional neural networks. Due to the ease of integration, we use the guidance rewards in a few popular algorithms (Q-learning, Actor-Critic, Distributional-RL) and present results in single-agent and multi-agent tasks that elucidate the benefit of our approach when the environmental rewards are sparse or delayed.
Efficient Competitive Self-Play Policy Optimization
Sep 13, 2020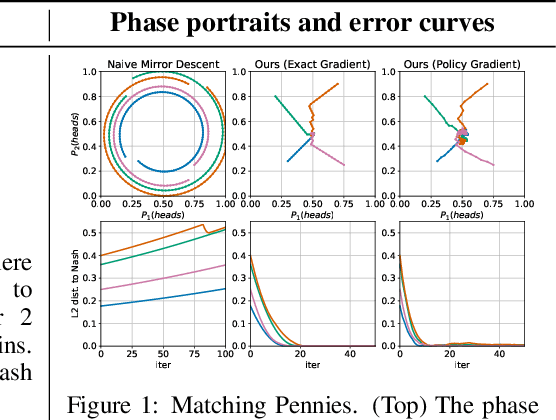
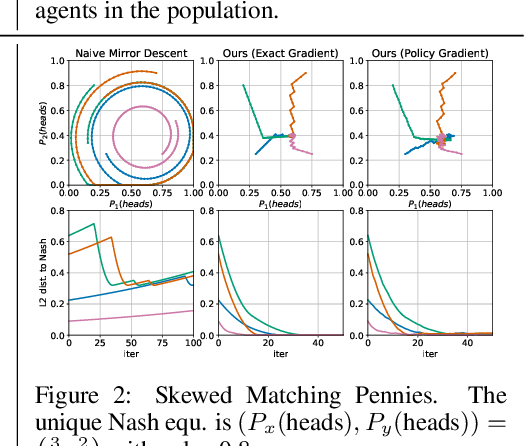
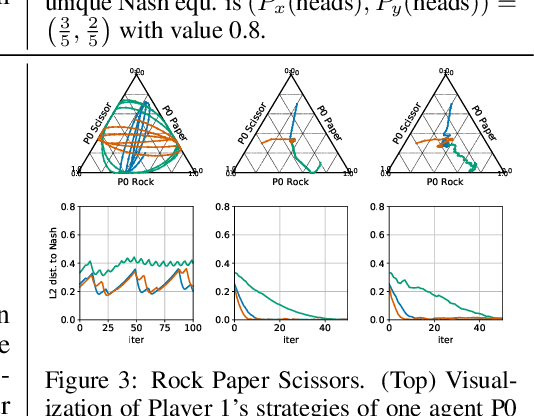
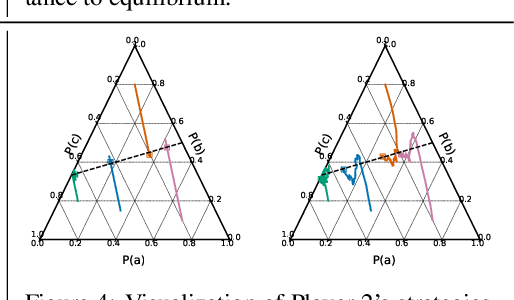
Reinforcement learning from self-play has recently reported many successes. Self-play, where the agents compete with themselves, is often used to generate training data for iterative policy improvement. In previous work, heuristic rules are designed to choose an opponent for the current learner. Typical rules include choosing the latest agent, the best agent, or a random historical agent. However, these rules may be inefficient in practice and sometimes do not guarantee convergence even in the simplest matrix games. In this paper, we propose a new algorithmic framework for competitive self-play reinforcement learning in two-player zero-sum games. We recognize the fact that the Nash equilibrium coincides with the saddle point of the stochastic payoff function, which motivates us to borrow ideas from classical saddle point optimization literature. Our method trains several agents simultaneously, and intelligently takes each other as opponent based on simple adversarial rules derived from a principled perturbation-based saddle optimization method. We prove theoretically that our algorithm converges to an approximate equilibrium with high probability in convex-concave games under standard assumptions. Beyond the theory, we further show the empirical superiority of our method over baseline methods relying on the aforementioned opponent-selection heuristics in matrix games, grid-world soccer, Gomoku, and simulated robot sumo, with neural net policy function approximators.
Pre-training of Graph Neural Network for Modeling Effects of Mutations on Protein-Protein Binding Affinity
Aug 28, 2020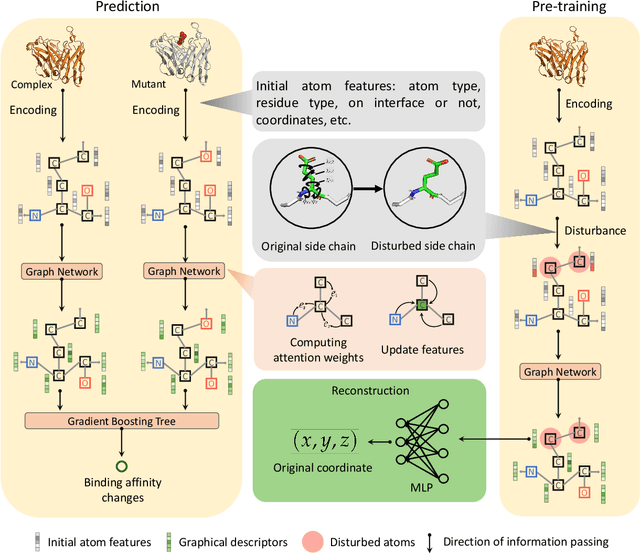
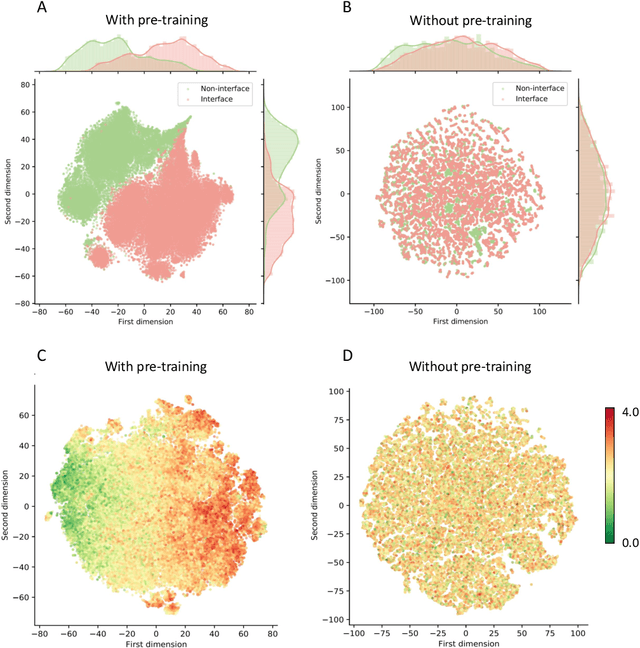
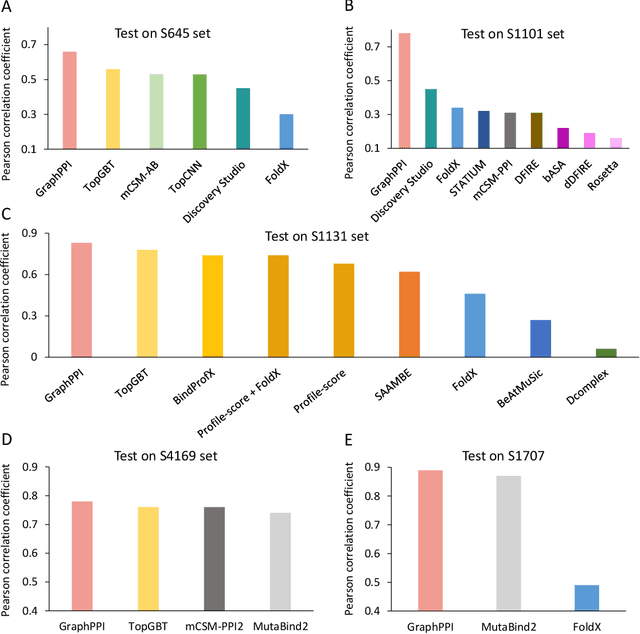
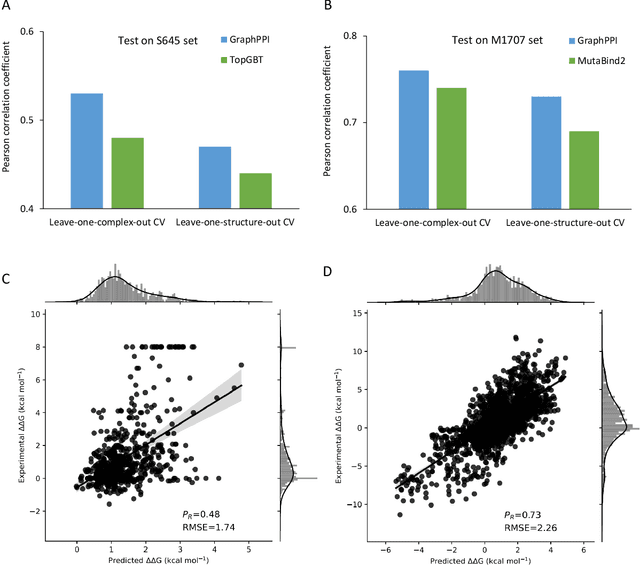
Modeling the effects of mutations on the binding affinity plays a crucial role in protein engineering and drug design. In this study, we develop a novel deep learning based framework, named GraphPPI, to predict the binding affinity changes upon mutations based on the features provided by a graph neural network (GNN). In particular, GraphPPI first employs a well-designed pre-training scheme to enforce the GNN to capture the features that are predictive of the effects of mutations on binding affinity in an unsupervised manner and then integrates these graphical features with gradient-boosting trees to perform the prediction. Experiments showed that, without any annotated signals, GraphPPI can capture meaningful patterns of the protein structures. Also, GraphPPI achieved new state-of-the-art performance in predicting the binding affinity changes upon both single- and multi-point mutations on five benchmark datasets. In-depth analyses also showed GraphPPI can accurately estimate the effects of mutations on the binding affinity between SARS-CoV-2 and its neutralizing antibodies. These results have established GraphPPI as a powerful and useful computational tool in the studies of protein design.
Boosting Weakly Supervised Object Detection with Progressive Knowledge Transfer
Jul 15, 2020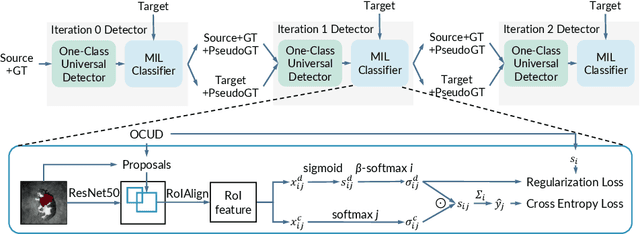
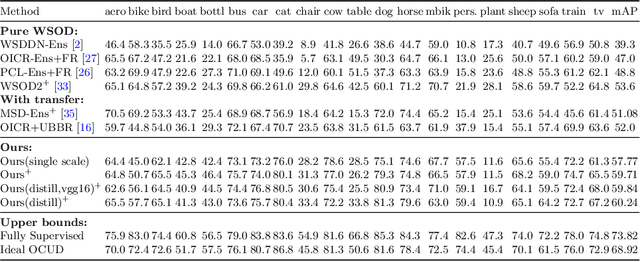
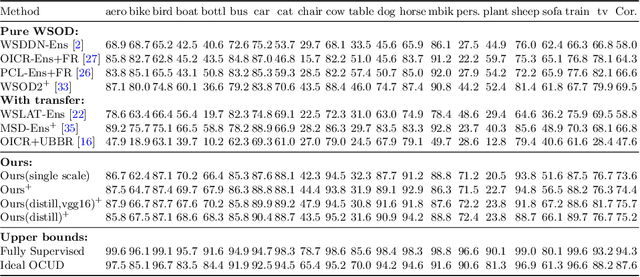
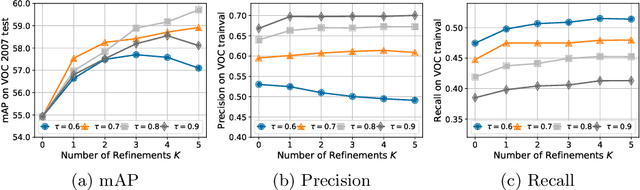
In this paper, we propose an effective knowledge transfer framework to boost the weakly supervised object detection accuracy with the help of an external fully-annotated source dataset, whose categories may not overlap with the target domain. This setting is of great practical value due to the existence of many off-the-shelf detection datasets. To more effectively utilize the source dataset, we propose to iteratively transfer the knowledge from the source domain by a one-class universal detector and learn the target-domain detector. The box-level pseudo ground truths mined by the target-domain detector in each iteration effectively improve the one-class universal detector. Therefore, the knowledge in the source dataset is more thoroughly exploited and leveraged. Extensive experiments are conducted with Pascal VOC 2007 as the target weakly-annotated dataset and COCO/ImageNet as the source fully-annotated dataset. With the proposed solution, we achieved an mAP of $59.7\%$ detection performance on the VOC test set and an mAP of $60.2\%$ after retraining a fully supervised Faster RCNN with the mined pseudo ground truths. This is significantly better than any previously known results in related literature and sets a new state-of-the-art of weakly supervised object detection under the knowledge transfer setting. Code: \url{https://github.com/mikuhatsune/wsod_transfer}.
Accelerating Nonconvex Learning via Replica Exchange Langevin Diffusion
Jul 04, 2020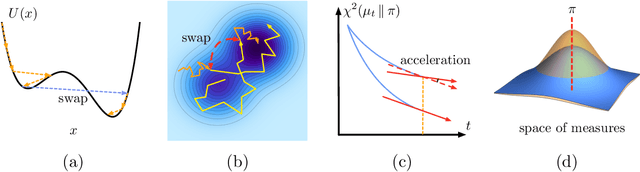
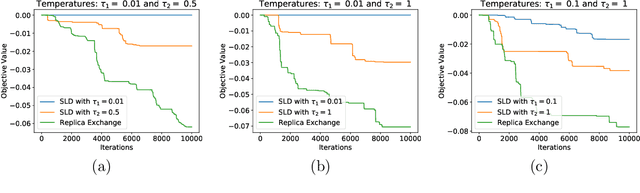
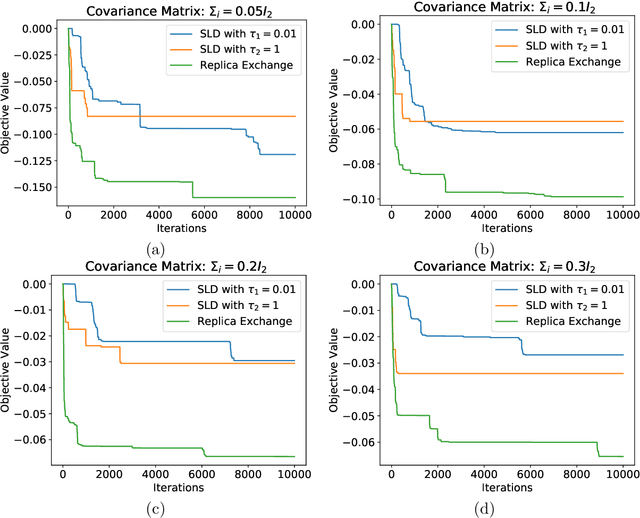
Langevin diffusion is a powerful method for nonconvex optimization, which enables the escape from local minima by injecting noise into the gradient. In particular, the temperature parameter controlling the noise level gives rise to a tradeoff between ``global exploration'' and ``local exploitation'', which correspond to high and low temperatures. To attain the advantages of both regimes, we propose to use replica exchange, which swaps between two Langevin diffusions with different temperatures. We theoretically analyze the acceleration effect of replica exchange from two perspectives: (i) the convergence in \chi^2-divergence, and (ii) the large deviation principle. Such an acceleration effect allows us to faster approach the global minima. Furthermore, by discretizing the replica exchange Langevin diffusion, we obtain a discrete-time algorithm. For such an algorithm, we quantify its discretization error in theory and demonstrate its acceleration effect in practice.