 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIS-COUNT: Large-scale Object Counting from Satellite Images with Covariate-based Importance Sampling
Dec 16, 2021
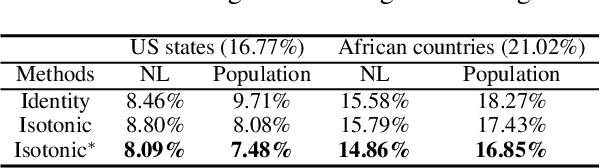
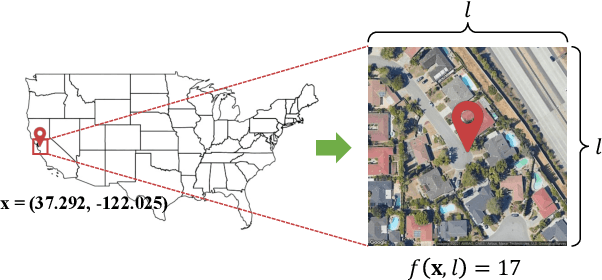
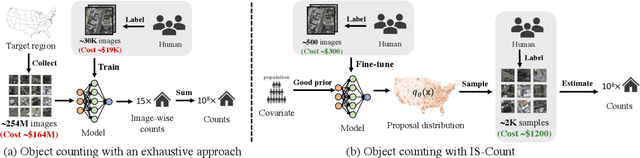
Object detection in high-resolution satellite imagery is emerging as a scalable alternative to on-the-ground survey data collection in many environmental and socioeconomic monitoring applications. However, performing object detection over large geographies can still be prohibitively expensive due to the high cost of purchasing imagery and compute. Inspired by traditional survey data collection strategies, we propose an approach to estimate object count statistics over large geographies through sampling. Given a cost budget, our method selects a small number of representative areas by sampling from a learnable proposal distribution. Using importance sampling, we are able to accurately estimate object counts after processing only a small fraction of the images compared to an exhaustive approach. We show empirically that the proposed framework achieves strong performance on estimating the number of buildings in the United States and Africa, cars in Kenya, brick kilns in Bangladesh, and swimming pools in the U.S., while requiring as few as 0.01% of satellite images compared to an exhaustive approach.
Variational Automatic Curriculum Learning for Sparse-Reward Cooperative Multi-Agent Problems
Nov 08, 2021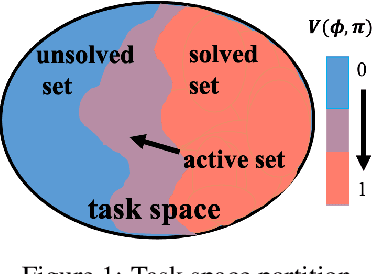

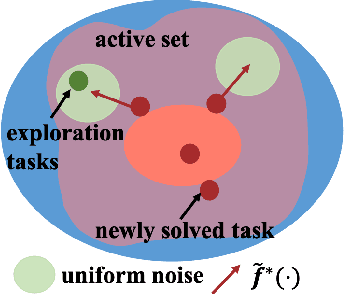

We introduce a curriculum learning algorithm, Variational Automatic Curriculum Learning (VACL), for solving challenging goal-conditioned cooperative multi-agent reinforcement learning problems. We motivate our paradigm through a variational perspective, where the learning objective can be decomposed into two terms: task learning on the current task distribution, and curriculum update to a new task distribution. Local optimization over the second term suggests that the curriculum should gradually expand the training tasks from easy to hard. Our VACL algorithm implements this variational paradigm with two practical components, task expansion and entity progression, which produces training curricula over both the task configurations as well as the number of entities in the task. Experiment results show that VACL solves a collection of sparse-reward problems with a large number of agents. Particularly, using a single desktop machine, VACL achieves 98% coverage rate with 100 agents in the simple-spread benchmark and reproduces the ramp-use behavior originally shown in OpenAI's hide-and-seek project. Our project website is at https://sites.google.com/view/vacl-neurips-2021.
Pseudo-Spherical Contrastive Divergence
Nov 01, 2021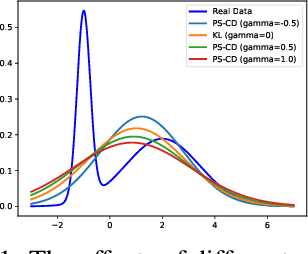
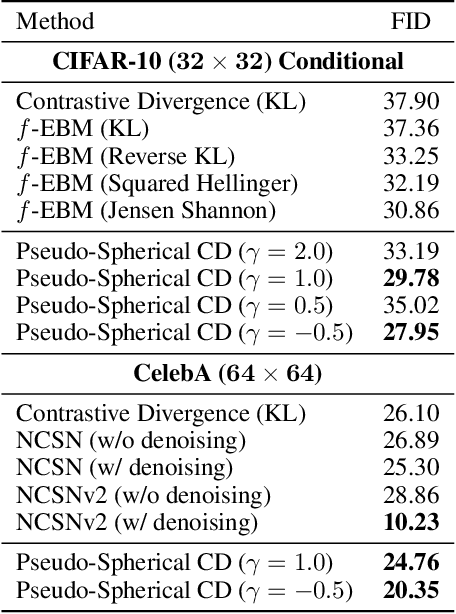

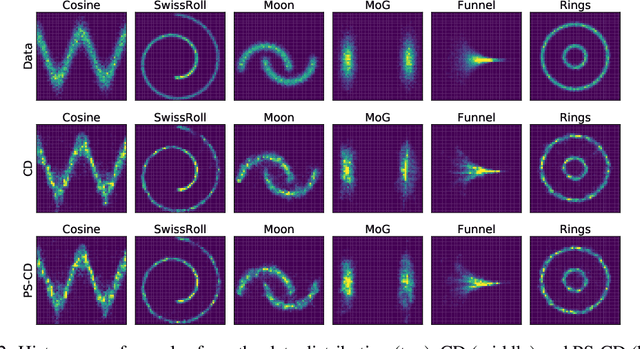
Energy-based models (EBMs) offer flexible distribution parametrization. However, due to the intractable partition function, they are typically trained via contrastive divergence for maximum likelihood estimation. In this paper, we propose pseudo-spherical contrastive divergence (PS-CD) to generalize maximum likelihood learning of EBMs. PS-CD is derived from the maximization of a family of strictly proper homogeneous scoring rules, which avoids the computation of the intractable partition function and provides a generalized family of learning objectives that include contrastive divergence as a special case. Moreover, PS-CD allows us to flexibly choose various learning objectives to train EBMs without additional computational cost or variational minimax optimization. Theoretical analysis on the proposed method and extensive experiments on both synthetic data and commonly used image datasets demonstrate the effectiveness and modeling flexibility of PS-CD, as well as its robustness to data contamination, thus showing its superiority over maximum likelihood and $f$-EBMs.
SDEdit: Image Synthesis and Editing with Stochastic Differential Equations
Aug 02, 2021
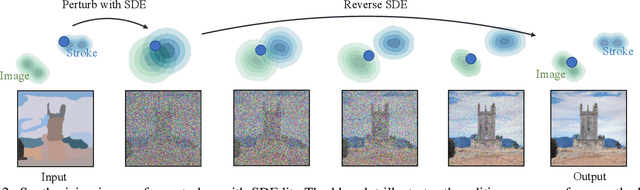
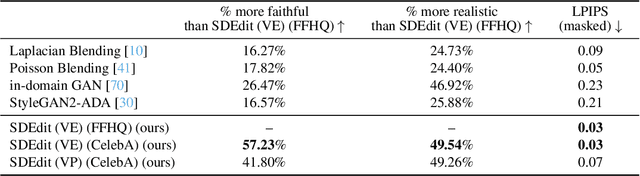

We introduce a new image editing and synthesis framework, Stochastic Differential Editing (SDEdit), based on a recent generative model using stochastic differential equations (SDEs). Given an input image with user edits (e.g., hand-drawn color strokes), we first add noise to the input according to an SDE, and subsequently denoise it by simulating the reverse SDE to gradually increase its likelihood under the prior. Our method does not require task-specific loss function designs, which are critical components for recent image editing methods based on GAN inversion. Compared to conditional GANs, we do not need to collect new datasets of original and edited images for new applications. Therefore, our method can quickly adapt to various editing tasks at test time without re-training models. Our approach achieves strong performance on a wide range of applications, including image synthesis and editing guided by stroke paintings and image compositing.
CSDI: Conditional Score-based Diffusion Models for Probabilistic Time Series Imputation
Jul 07, 2021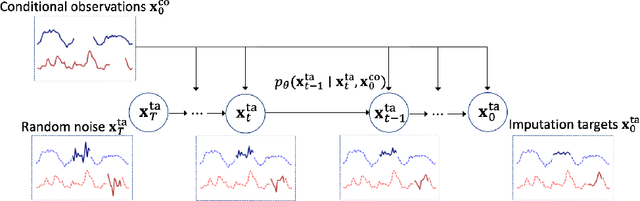

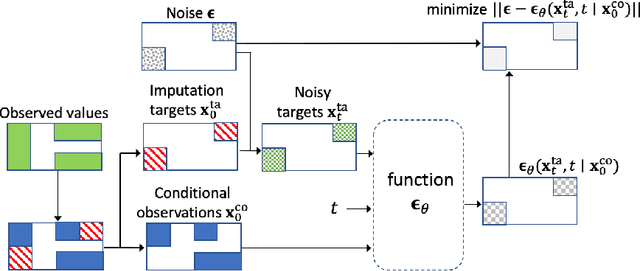
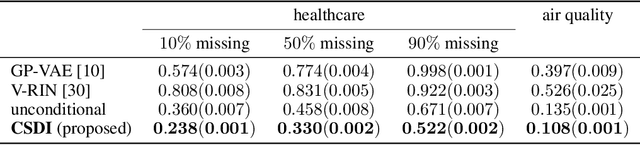
The imputation of missing values in time series has many applications in healthcare and finance. While autoregressive models are natural candidates for time series imputation, score-based diffusion models have recently outperformed existing counterparts including autoregressive models in many tasks such as image generation and audio synthesis, and would be promising for time series imputation. In this paper, we propose Conditional Score-based Diffusion models for Imputation (CSDI), a novel time series imputation method that utilizes score-based diffusion models conditioned on observed data. Unlike existing score-based approaches, the conditional diffusion model is explicitly trained for imputation and can exploit correlations between observed values. On healthcare and environmental data, CSDI improves by 40-70% over existing probabilistic imputation methods on popular performance metrics. In addition, deterministic imputation by CSDI reduces the error by 5-20% compared to the state-of-the-art deterministic imputation methods. Furthermore, CSDI can also be applied to time series interpolation and probabilistic forecasting, and is competitive with existing baselines.
IQ-Learn: Inverse soft-Q Learning for Imitation
Jun 23, 2021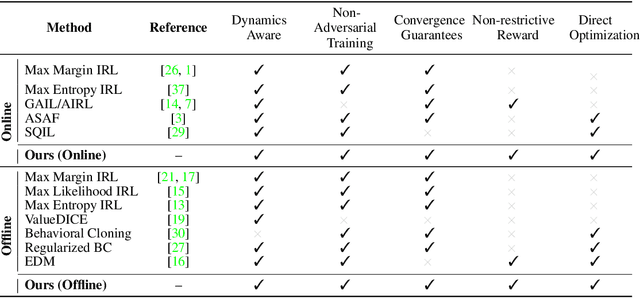
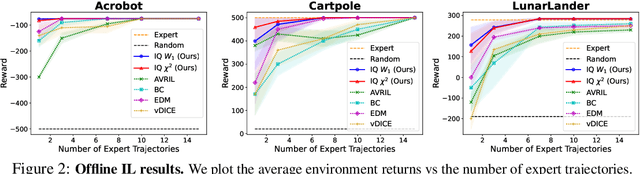
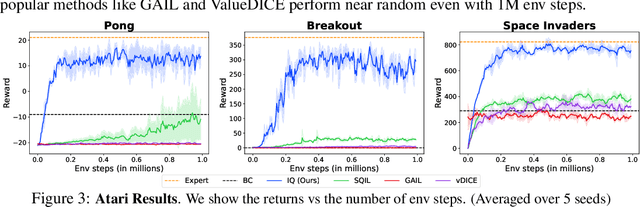
In many sequential decision-making problems (e.g., robotics control, game playing, sequential prediction), human or expert data is available containing useful information about the task. However, imitation learning (IL) from a small amount of expert data can be challenging in high-dimensional environments with complex dynamics. Behavioral cloning is a simple method that is widely used due to its simplicity of implementation and stable convergence but doesn't utilize any information involving the environment's dynamics. Many existing methods that exploit dynamics information are difficult to train in practice due to an adversarial optimization process over reward and policy approximators or biased, high variance gradient estimators. We introduce a method for dynamics-aware IL which avoids adversarial training by learning a single Q-function, implicitly representing both reward and policy. On standard benchmarks, the implicitly learned rewards show a high positive correlation with the ground-truth rewards, illustrating our method can also be used for inverse reinforcement learning (IRL). Our method, Inverse soft-Q learning (IQ-Learn) obtains state-of-the-art results in offline and online imitation learning settings, surpassing existing methods both in the number of required environment interactions and scalability in high-dimensional spaces.
D2C: Diffusion-Denoising Models for Few-shot Conditional Generation
Jun 12, 2021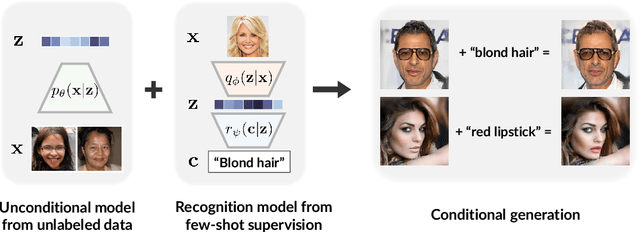
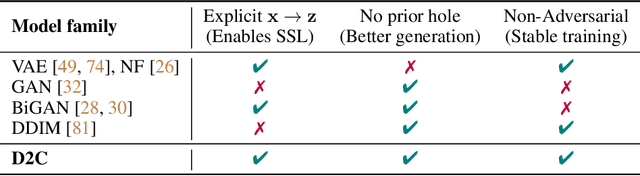
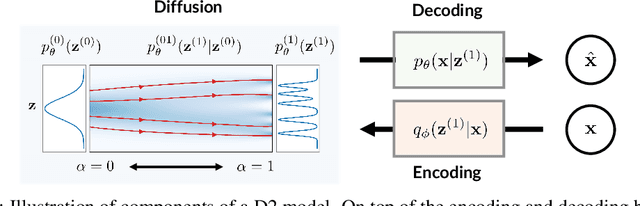
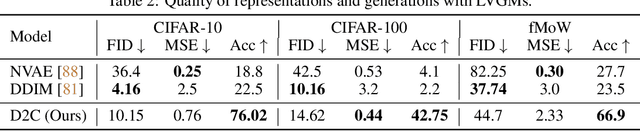
Conditional generative models of high-dimensional images have many applications, but supervision signals from conditions to images can be expensive to acquire. This paper describes Diffusion-Decoding models with Contrastive representations (D2C), a paradigm for training unconditional variational autoencoders (VAEs) for few-shot conditional image generation. D2C uses a learned diffusion-based prior over the latent representations to improve generation and contrastive self-supervised learning to improve representation quality. D2C can adapt to novel generation tasks conditioned on labels or manipulation constraints, by learning from as few as 100 labeled examples. On conditional generation from new labels, D2C achieves superior performance over state-of-the-art VAEs and diffusion models. On conditional image manipulation, D2C generations are two orders of magnitude faster to produce over StyleGAN2 ones and are preferred by 50% - 60% of the human evaluators in a double-blind study.
Improved Autoregressive Modeling with Distribution Smoothing
Mar 28, 2021


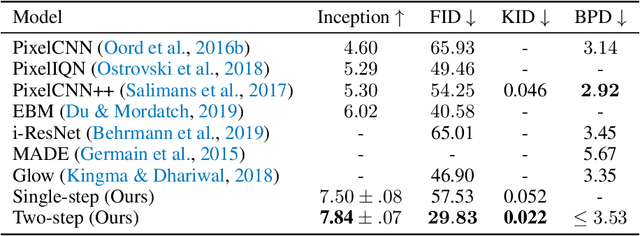
While autoregressive models excel at image compression, their sample quality is often lacking. Although not realistic, generated images often have high likelihood according to the model, resembling the case of adversarial examples. Inspired by a successful adversarial defense method, we incorporate randomized smoothing into autoregressive generative modeling. We first model a smoothed version of the data distribution, and then reverse the smoothing process to recover the original data distribution. This procedure drastically improves the sample quality of existing autoregressive models on several synthetic and real-world image datasets while obtaining competitive likelihoods on synthetic datasets.
Negative Data Augmentation
Feb 09, 2021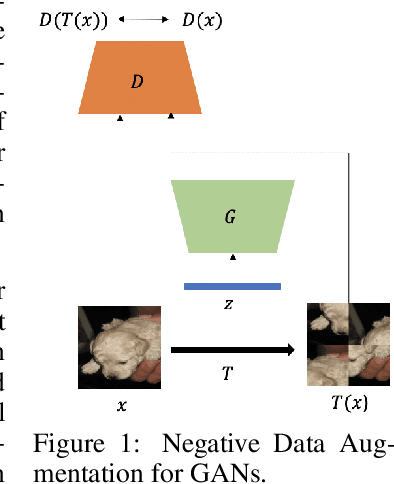



Data augmentation is often used to enlarge datasets with synthetic samples generated in accordance with the underlying data distribution. To enable a wider range of augmentations, we explore negative data augmentation strategies (NDA)that intentionally create out-of-distribution samples. We show that such negative out-of-distribution samples provide information on the support of the data distribution, and can be leveraged for generative modeling and representation learning. We introduce a new GAN training objective where we use NDA as an additional source of synthetic data for the discriminator. We prove that under suitable conditions, optimizing the resulting objective still recovers the true data distribution but can directly bias the generator towards avoiding samples that lack the desired structure. Empirically, models trained with our method achieve improved conditional/unconditional image generation along with improved anomaly detection capabilities. Further, we incorporate the same negative data augmentation strategy in a contrastive learning framework for self-supervised representation learning on images and videos, achieving improved performance on downstream image classification, object detection, and action recognition tasks. These results suggest that prior knowledge on what does not constitute valid data is an effective form of weak supervision across a range of unsupervised learning tasks.
Autoregressive Score Matching
Oct 24, 2020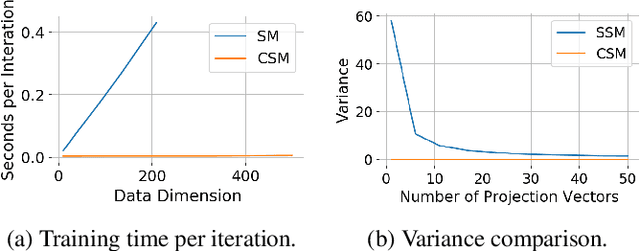


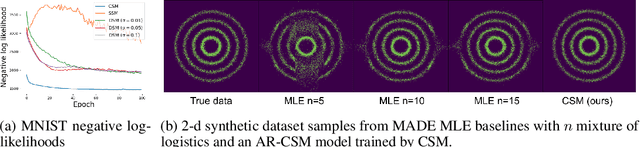
Autoregressive models use chain rule to define a joint probability distribution as a product of conditionals. These conditionals need to be normalized, imposing constraints on the functional families that can be used. To increase flexibility, we propose autoregressive conditional score models (AR-CSM) where we parameterize the joint distribution in terms of the derivatives of univariate log-conditionals (scores), which need not be normalized. To train AR-CSM, we introduce a new divergence between distributions named Composite Score Matching (CSM). For AR-CSM models, this divergence between data and model distributions can be computed and optimized efficiently, requiring no expensive sampling or adversarial training. Compared to previous score matching algorithms, our method is more scalable to high dimensional data and more stable to optimize. We show with extensive experimental results that it can be applied to density estimation on synthetic data, image generation, image denoising, and training latent variable models with implicit encoders.