 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQwen2.5-Omni Technical Report
Mar 26, 2025



In this report, we present Qwen2.5-Omni, an end-to-end multimodal model designed to perceive diverse modalities, including text, images, audio, and video, while simultaneously generating text and natural speech responses in a streaming manner. To enable the streaming of multimodal information inputs, both audio and visual encoders utilize a block-wise processing approach. To synchronize the timestamps of video inputs with audio, we organize the audio and video sequentially in an interleaved manner and propose a novel position embedding approach, named TMRoPE(Time-aligned Multimodal RoPE). To concurrently generate text and speech while avoiding interference between the two modalities, we propose \textbf{Thinker-Talker} architecture. In this framework, Thinker functions as a large language model tasked with text generation, while Talker is a dual-track autoregressive model that directly utilizes the hidden representations from the Thinker to produce audio tokens as output. Both the Thinker and Talker models are designed to be trained and inferred in an end-to-end manner. For decoding audio tokens in a streaming manner, we introduce a sliding-window DiT that restricts the receptive field, aiming to reduce the initial package delay. Qwen2.5-Omni is comparable with the similarly sized Qwen2.5-VL and outperforms Qwen2-Audio. Furthermore, Qwen2.5-Omni achieves state-of-the-art performance on multimodal benchmarks like Omni-Bench. Notably, Qwen2.5-Omni's performance in end-to-end speech instruction following is comparable to its capabilities with text inputs, as evidenced by benchmarks such as MMLU and GSM8K. As for speech generation, Qwen2.5-Omni's streaming Talker outperforms most existing streaming and non-streaming alternatives in robustness and naturalness.
Qwen2.5-VL Technical Report
Feb 19, 2025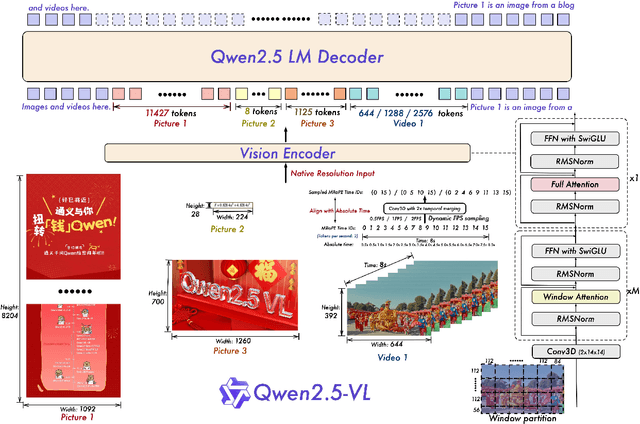
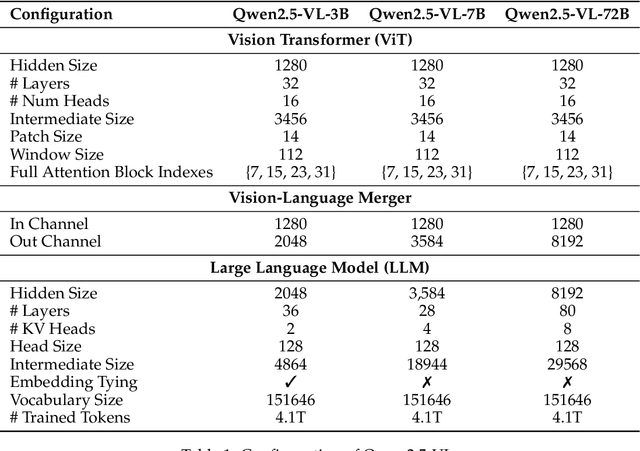
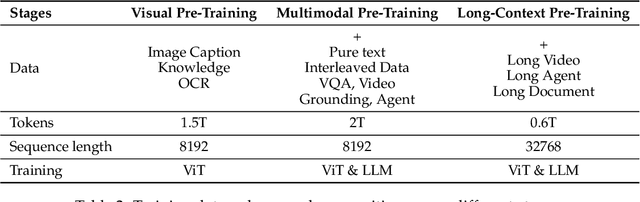
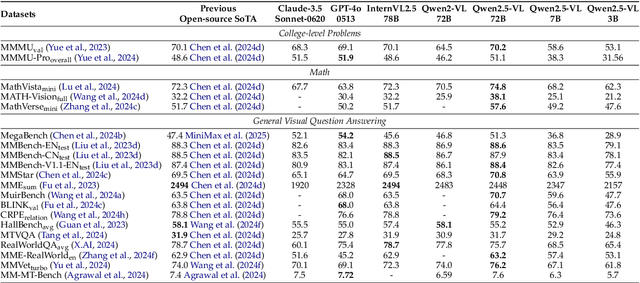
We introduce Qwen2.5-VL, the latest flagship model of Qwen vision-language series, which demonstrates significant advancements in both foundational capabilities and innovative functionalities. Qwen2.5-VL achieves a major leap forward in understanding and interacting with the world through enhanced visual recognition, precise object localization, robust document parsing, and long-video comprehension. A standout feature of Qwen2.5-VL is its ability to localize objects using bounding boxes or points accurately. It provides robust structured data extraction from invoices, forms, and tables, as well as detailed analysis of charts, diagrams, and layouts. To handle complex inputs, Qwen2.5-VL introduces dynamic resolution processing and absolute time encoding, enabling it to process images of varying sizes and videos of extended durations (up to hours) with second-level event localization. This allows the model to natively perceive spatial scales and temporal dynamics without relying on traditional normalization techniques. By training a native dynamic-resolution Vision Transformer (ViT) from scratch and incorporating Window Attention, we reduce computational overhead while maintaining native resolution. As a result, Qwen2.5-VL excels not only in static image and document understanding but also as an interactive visual agent capable of reasoning, tool usage, and task execution in real-world scenarios such as operating computers and mobile devices. Qwen2.5-VL is available in three sizes, addressing diverse use cases from edge AI to high-performance computing. The flagship Qwen2.5-VL-72B model matches state-of-the-art models like GPT-4o and Claude 3.5 Sonnet, particularly excelling in document and diagram understanding. Additionally, Qwen2.5-VL maintains robust linguistic performance, preserving the core language competencies of the Qwen2.5 LLM.
Agent AI with LangGraph: A Modular Framework for Enhancing Machine Translation Using Large Language Models
Dec 05, 2024



This paper explores the transformative role of Agent AI and LangGraph in advancing the automation and effectiveness of machine translation (MT). Agents are modular components designed to perform specific tasks, such as translating between particular languages, with specializations like TranslateEnAgent, TranslateFrenchAgent, and TranslateJpAgent for English, French, and Japanese translations, respectively. These agents leverage the powerful semantic capabilities of large language models (LLMs), such as GPT-4o, to ensure accurate, contextually relevant translations while maintaining modularity, scalability, and context retention. LangGraph, a graph-based framework built on LangChain, simplifies the creation and management of these agents and their workflows. It supports dynamic state management, enabling agents to maintain dialogue context and automates complex workflows by linking agents and facilitating their collaboration. With flexibility, open-source community support, and seamless integration with LLMs, LangGraph empowers agents to deliver high-quality translations. Together, Agent AI and LangGraph create a cohesive system where LangGraph orchestrates agent interactions, ensuring that user inputs are analyzed, routed, and processed efficiently. Experimental results demonstrate the potential of this system to enhance multilingual translation accuracy and scalability. By highlighting modular design and automated workflows, this paper sets the stage for further innovations in intelligent machine translation services.
Intelligent Spark Agents: A Modular LangGraph Framework for Scalable, Visualized, and Enhanced Big Data Machine Learning Workflows
Dec 03, 2024



Apache Spark is better suited for load data mining and machine learning that require a lot of iteration by using memory-distributed data sets. Due to the complexity of Spark, the high learning threshold of Scala, and the low reusability of its code, this paper designs and implements a Spark-based visual process AI+machine learning method under a big data environment. On the one hand, it designs component models to describe the basic steps of machine learning, including data preprocessing, feature processing, and model training. Practice and validate evaluation. On the other hand, a visual process modeling tool is provided to support analysts to design machine learning processes, which can be translated automatically into Spark platform code for efficient execution. This tool can greatly improve the AI machine learning efficiency of the Spark platform. This paper introduces the method theory, key technologies, and effectiveness of the tool. This paper explores the application of Spark in the field of large model agents. Langchain, as an open-source framework, is committed to simplifying the development of end-to-end applications based on language models. It provides interfaces for interacting with a variety of large language models, optimizing prompt engineering, and endowing large models with the ability to invoke external tools. LangGraph demonstrates its powerful state management and graph construction capabilities by defining node functions and graphs to build complex agent applications. The development of Spark agent applications based on LangGraph has further promoted the development of AI applications in the big data analysis environment .
Exploration of LLM Multi-Agent Application Implementation Based on LangGraph+CrewAI
Nov 27, 2024



With the rapid development of large model technology, the application of agent technology in various fields is becoming increasingly widespread, profoundly changing people's work and lifestyles. In complex and dynamic systems, multi-agents achieve complex tasks that are difficult for a single agent to complete through division of labor and collaboration among agents. This paper discusses the integrated application of LangGraph and CrewAI. LangGraph improves the efficiency of information transmission through graph architecture, while CrewAI enhances team collaboration capabilities and system performance through intelligent task allocation and resource management. The main research contents of this paper are: (1) designing the architecture of agents based on LangGraph for precise control; (2) enhancing the capabilities of agents based on CrewAI to complete a variety of tasks. This study aims to delve into the application of LangGraph and CrewAI in multi-agent systems, providing new perspectives for the future development of agent technology, and promoting technological progress and application innovation in the field of large model intelligent agents.
Enhancing Multi-Agent Consensus through Third-Party LLM Integration: Analyzing Uncertainty and Mitigating Hallucinations in Large Language Models
Nov 25, 2024



Large Language Models (LLMs) still face challenges when dealing with complex reasoning tasks, often resulting in hallucinations, which limit the practical application of LLMs. To alleviate this issue, this paper proposes a new method that integrates different LLMs to expand the knowledge boundary, reduce dependence on a single model, and promote in-depth debate among agents. The main contributions include: 1) Introducing third-party LLMs to adjust the attention weights of agents through uncertainty estimation and confidence analysis, optimizing consensus formation in multi-agent systems; 2) Experiments on arithmetic datasets have validated the effectiveness of the method, surpassing traditional multi-agent baselines. This research provides a new perspective for large models to alleviate hallucination phenomena when dealing with complex tasks.
ChannelGPT: A Large Model to Generate Digital Twin Channel for 6G Environment Intelligence
Oct 17, 2024



6G is envisaged to provide multimodal sensing, pervasive intelligence, global coverage, global coverage, etc., which poses extreme intricacy and new challenges to the network design and optimization. As the core part of 6G, wireless channel is the carrier and enabler for the flourishing technologies and novel services, which intrinsically determines the ultimate system performance. However, how to describe and utilize the complicated and high-dynamic characteristics of wireless channel accurately and effectively still remains great hallenges. To tackle this, digital twin is envisioned as a powerful technology to migrate the physical entities to virtual and computational world. In this article, we propose a large model driven digital twin channel generator (ChannelGPT) embedded with environment intelligence (EI) to enable pervasive intelligence paradigm for 6G network. EI is an iterative and interactive procedure to boost the system performance with online environment adaptivity. Firstly, ChannelGPT is capable of utilization the multimodal data from wireless channel and corresponding physical environment with the equipped sensing ability. Then, based on the fine-tuned large model, ChannelGPT can generate multi-scenario channel parameters, associated map information and wireless knowledge simultaneously, in terms of each task requirement. Furthermore, with the support of online multidimensional channel and environment information, the network entity will make accurate and immediate decisions for each 6G system layer. In practice, we also establish a ChannelGPT prototype to generate high-fidelity channel data for varied scenarios to validate the accuracy and generalization ability based on environment intelligence.
Wireless Environment Information Sensing, Feature, Semantic, and Knowledge: Four Steps Towards 6G AI-Enabled Air Interface
Sep 28, 2024



The air interface technology plays a crucial role in optimizing the communication quality for users. To address the challenges brought by the radio channel variations to air interface design, this article proposes a framework of wireless environment information-aided 6G AI-enabled air interface (WEI-6G AI$^{2}$), which actively acquires real-time environment details to facilitate channel fading prediction and communication technology optimization. Specifically, we first outline the role of WEI in supporting the 6G AI$^{2}$ in scenario adaptability, real-time inference, and proactive action. Then, WEI is delineated into four progressive steps: raw sensing data, features obtained by data dimensionality reduction, semantics tailored to tasks, and knowledge that quantifies the environmental impact on the channel. To validate the availability and compare the effect of different types of WEI, a path loss prediction use case is designed. The results demonstrate that leveraging environment knowledge requires only 2.2 ms of model inference time, which can effectively support real-time design for future 6G AI$^{2}$. Additionally, WEI can reduce the pilot overhead by 25\%. Finally, several open issues are pointed out, including multi-modal sensing data synchronization and information extraction method construction.
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Sep 18, 2024



We present the Qwen2-VL Series, an advanced upgrade of the previous Qwen-VL models that redefines the conventional predetermined-resolution approach in visual processing. Qwen2-VL introduces the Naive Dynamic Resolution mechanism, which enables the model to dynamically process images of varying resolutions into different numbers of visual tokens. This approach allows the model to generate more efficient and accurate visual representations, closely aligning with human perceptual processes. The model also integrates Multimodal Rotary Position Embedding (M-RoPE), facilitating the effective fusion of positional information across text, images, and videos. We employ a unified paradigm for processing both images and videos, enhancing the model's visual perception capabilities. To explore the potential of large multimodal models, Qwen2-VL investigates the scaling laws for large vision-language models (LVLMs). By scaling both the model size-with versions at 2B, 8B, and 72B parameters-and the amount of training data, the Qwen2-VL Series achieves highly competitive performance. Notably, the Qwen2-VL-72B model achieves results comparable to leading models such as GPT-4o and Claude3.5-Sonnet across various multimodal benchmarks, outperforming other generalist models. Code is available at \url{https://github.com/QwenLM/Qwen2-VL}.
Multi-tool Integration Application for Math Reasoning Using Large Language Model
Aug 22, 2024



Mathematical reasoning is an important research direction in the field of artificial intelligence. This article proposes a novel multi tool application framework for mathematical reasoning, aiming to achieve more comprehensive and accurate mathematical reasoning by utilizing the collaborative effect of large language models (LLMs) and multiple external tools. Firstly, use a Math Tool to perform basic mathematical calculations during the inference process through interaction with LLM. Secondly, Code Tool can generate code fragments that comply with syntax rules and execute them, providing support for complex mathematical problems. Then, through the iterative reasoning of the CoT Tool, the logical coherence and accuracy of mathematical reasoning are enhanced. Ultimately, by using self consistency tools to select the final answer based on different parameters, the consistency and reliability of reasoning are improved. Through the synergistic effect of these tools, the framework has achieved significant performance improvement in mathematical reasoning tasks. We conducted experiments on the NumGLUE Task 4 test set, which includes 220 mathematical reasoning fill in the blank questions. The experimental results showed that, based on Math Tool, Code Tool, and CoT Tool, in Task 4 task,our method achieved an accuracy of 89.09,compared with the GPT3+FewShot baseline, Few Shot+ERNIE-4.0+self consistency improved by 49.09%, and compared with fine-tuning the Fine tuning baseline, Few Shot+ERNIE-4.0+self consistency improved by 52.29%