 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlashMemory-DeepSeek-V4: Lightning Index Ultra-Long Context via Lookahead Sparse Attention
Jun 09, 2026Conventional LLMs keep the full KV cache loaded during decoding, causing a severe GPU memory bottleneck for ultra-long context serving. In this report, we propose Lookahead Sparse Attention (LSA), a novel inference paradigm powered by a Neural Memory Indexer built upon the DeepSeek-V4 architecture. Rather than passively attending to all historical tokens, LSA proactively predicts future context demands and preserves only the query-critical KV chunks in the GPU memory. Crucially, we instantiate this architecture via a backbone-free decoupled training strategy. By formulating the indexer as a standard dual-encoder architecture, we train it independently using standard retrieval training frameworks without ever loading the massive backbone model into GPU memory. We demonstrate that this "less is more" paradigm significantly maximizes serving efficiency while acting as an effective attention denoiser in tasks that rely on long-term global memory. Across primary long-context evaluation suites (e.g., LongBench-v2, LongMemEval, and RULER), FM-DS-V4 compresses the average physical KV cache footprint down to merely 13.5% of the full-context baseline, while consistently preserving or slightly elevating downstream accuracy (+0.6% absolute margin on average). Crucially, at extreme 500K scales, FlashMemory suppresses the physical KV cache overhead by over 90% without destabilizing the backbone's core reasoning capacities.
Internalize the Temperature: On-Policy Self-Distillation as Policy Reheater for Reinforcement Learning
May 30, 2026Reinforcement learning from verifiable rewards improves the reasoning ability of large language models, but often suffers from entropy collapse, in which increasingly concentrated policies reduce rollout diversity and useful learning signals. Existing remedies either constrain the RL objective (e.g., entropy regularization) or adjust sampling temperature during rollout collection, but these interventions remain external to the model parameters. We propose Temperature-Scaled On-Policy Self-Distillation (TS-OPSD), a lightweight policy reheating method that internalizes the exploratory effect of temperature into model parameters. Starting from an entropy-collapsed RL checkpoint, TS-OPSD constructs a self-teacher by applying high-temperature scaling to the model's own logits, then distills the resulting smoother distribution back into the student. This policy reheating requires no external teacher, privileged data, or additional inference cost. Experiments on Qwen3-4B-Base and Qwen3-8B-Base show that policy reheating yields a stronger initialization for continued RL than both standard continued RL and rollout-level temperature reheating. Further analyses show that TS-OPSD mainly reduces output sharpness while preserving intermediate representations, top candidate sets, and reasoning capability. These results suggest that entropy restoration can serve as a simple post-collapse intervention for extending reasoning-oriented RL.
CoWork-X: Experience-Optimized Co-Evolution for Multi-Agent Collaboration System
Feb 04, 2026Large language models are enabling language-conditioned agents in interactive environments, but highly cooperative tasks often impose two simultaneous constraints: sub-second real-time coordination and sustained multi-episode adaptation under a strict online token budget. Existing approaches either rely on frequent in-episode reasoning that induces latency and timing jitter, or deliver post-episode improvements through unstructured text that is difficult to compile into reliable low-cost execution. We propose CoWork-X, an active co-evolution framework that casts peer collaboration as a closed-loop optimization problem across episodes, inspired by fast--slow memory separation. CoWork-X instantiates a Skill-Agent that executes via HTN (hierarchical task network)-based skill retrieval from a structured, interpretable, and compositional skill library, and a post-episode Co-Optimizer that performs patch-style skill consolidation with explicit budget constraints and drift regularization. Experiments in challenging Overcooked-AI-like realtime collaboration benchmarks demonstrate that CoWork-X achieves stable, cumulative performance gains while steadily reducing online latency and token usage.
S2J: Bridging the Gap Between Solving and Judging Ability in Generative Reward Models
Sep 26, 2025


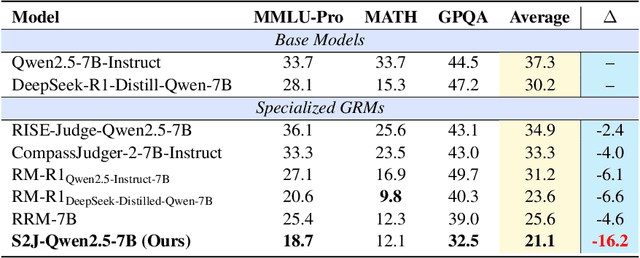
With the rapid development of large language models (LLMs), generative reward models (GRMs) have been widely adopted for reward modeling and evaluation. Previous studies have primarily focused on training specialized GRMs by optimizing them on preference datasets with the judgment correctness as supervision. While it's widely accepted that GRMs with stronger problem-solving capabilities typically exhibit superior judgment abilities, we first identify a significant solve-to-judge gap when examining individual queries. Specifically, the solve-to-judge gap refers to the phenomenon where GRMs struggle to make correct judgments on some queries (14%-37%), despite being fully capable of solving them. In this paper, we propose the Solve-to-Judge (S2J) approach to address this problem. Specifically, S2J simultaneously leverages both the solving and judging capabilities on a single GRM's output for supervision, explicitly linking the GRM's problem-solving and evaluation abilities during model optimization, thereby narrowing the gap. Our comprehensive experiments demonstrate that S2J effectively reduces the solve-to-judge gap by 16.2%, thereby enhancing the model's judgment performance by 5.8%. Notably, S2J achieves state-of-the-art (SOTA) performance among GRMs built on the same base model while utilizing a significantly smaller training dataset. Moreover, S2J accomplishes this through self-evolution without relying on more powerful external models for distillation.
VFaith: Do Large Multimodal Models Really Reason on Seen Images Rather than Previous Memories?
Jun 13, 2025Recent extensive works have demonstrated that by introducing long CoT, the capabilities of MLLMs to solve complex problems can be effectively enhanced. However, the reasons for the effectiveness of such paradigms remain unclear. It is challenging to analysis with quantitative results how much the model's specific extraction of visual cues and its subsequent so-called reasoning during inference process contribute to the performance improvements. Therefore, evaluating the faithfulness of MLLMs' reasoning to visual information is crucial. To address this issue, we first present a cue-driven automatic and controllable editing pipeline with the help of GPT-Image-1. It enables the automatic and precise editing of specific visual cues based on the instruction. Furthermore, we introduce VFaith-Bench, the first benchmark to evaluate MLLMs' visual reasoning capabilities and analyze the source of such capabilities with an emphasis on the visual faithfulness. Using the designed pipeline, we constructed comparative question-answer pairs by altering the visual cues in images that are crucial for solving the original reasoning problem, thereby changing the question's answer. By testing similar questions with images that have different details, the average accuracy reflects the model's visual reasoning ability, while the difference in accuracy before and after editing the test set images effectively reveals the relationship between the model's reasoning ability and visual perception. We further designed specific metrics to expose this relationship. VFaith-Bench includes 755 entries divided into five distinct subsets, along with an additional human-labeled perception task. We conducted in-depth testing and analysis of existing mainstream flagship models and prominent open-source model series/reasoning models on VFaith-Bench, further investigating the underlying factors of their reasoning capabilities.
Improve LLM-as-a-Judge Ability as a General Ability
Feb 17, 2025



LLM-as-a-Judge leverages the generative and reasoning capabilities of large language models (LLMs) to evaluate LLM responses across diverse scenarios, providing accurate preference signals. This approach plays a vital role in aligning LLMs with human values, ensuring ethical and reliable AI outputs that align with societal norms. Recent studies have raised many methods to train LLM as generative judges, but most of them are data consuming or lack accuracy, and only focus on LLM's judge ability. In this work, we regard judge ability as a general ability of LLM and implement a two-stage training approach, comprising supervised fine-tuning (SFT) warm-up and direct preference optimization (DPO) enhancement, to achieve judge style adaptation and improve judgment accuracy. Additionally, we introduce an efficient data synthesis method to generate judgmental content. Experimental results demonstrate that our approach, utilizing only about 2% to 40% of the data required by other methods, achieves SOTA performance on RewardBench. Furthermore, our training method enhances the general capabilities of the model by constructing complicated judge task, and the judge signals provided by our model have significantly enhanced the downstream DPO training performance of our internal models in our test to optimize policy model with Judge Model. We also open-source our model weights and training data to facilitate further research.
A Deep Dive Into Large Language Model Code Generation Mistakes: What and Why?
Nov 03, 2024



Recent advancements in Large Language Models (LLMs) have led to their widespread application in automated code generation. However, these models can still generate defective code that deviates from the specification. Previous research has mainly focused on the mistakes in LLM-generated standalone functions, overlooking real-world software development situations where the successful generation of the code requires software contexts such as external dependencies. In this paper, we considered both of these code generation situations and identified a range of \textit{non-syntactic mistakes} arising from LLMs' misunderstandings of coding question specifications. Seven categories of non-syntactic mistakes were identified through extensive manual analyses, four of which were missed by previous works. To better understand these mistakes, we proposed six reasons behind these mistakes from various perspectives. Moreover, we explored the effectiveness of LLMs in detecting mistakes and their reasons. Our evaluation demonstrated that GPT-4 with the ReAct prompting technique can achieve an F1 score of up to 0.65 when identifying reasons for LLM's mistakes, such as misleading function signatures. We believe that these findings offer valuable insights into enhancing the quality of LLM-generated code.