 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHSSBench: Benchmarking Humanities and Social Sciences Ability for Multimodal Large Language Models
Jun 04, 2025



Multimodal Large Language Models (MLLMs) have demonstrated significant potential to advance a broad range of domains. However, current benchmarks for evaluating MLLMs primarily emphasize general knowledge and vertical step-by-step reasoning typical of STEM disciplines, while overlooking the distinct needs and potential of the Humanities and Social Sciences (HSS). Tasks in the HSS domain require more horizontal, interdisciplinary thinking and a deep integration of knowledge across related fields, which presents unique challenges for MLLMs, particularly in linking abstract concepts with corresponding visual representations. Addressing this gap, we present HSSBench, a dedicated benchmark designed to assess the capabilities of MLLMs on HSS tasks in multiple languages, including the six official languages of the United Nations. We also introduce a novel data generation pipeline tailored for HSS scenarios, in which multiple domain experts and automated agents collaborate to generate and iteratively refine each sample. HSSBench contains over 13,000 meticulously designed samples, covering six key categories. We benchmark more than 20 mainstream MLLMs on HSSBench and demonstrate that it poses significant challenges even for state-of-the-art models. We hope that this benchmark will inspire further research into enhancing the cross-disciplinary reasoning abilities of MLLMs, especially their capacity to internalize and connect knowledge across fields.
Improve LLM-as-a-Judge Ability as a General Ability
Feb 17, 2025



LLM-as-a-Judge leverages the generative and reasoning capabilities of large language models (LLMs) to evaluate LLM responses across diverse scenarios, providing accurate preference signals. This approach plays a vital role in aligning LLMs with human values, ensuring ethical and reliable AI outputs that align with societal norms. Recent studies have raised many methods to train LLM as generative judges, but most of them are data consuming or lack accuracy, and only focus on LLM's judge ability. In this work, we regard judge ability as a general ability of LLM and implement a two-stage training approach, comprising supervised fine-tuning (SFT) warm-up and direct preference optimization (DPO) enhancement, to achieve judge style adaptation and improve judgment accuracy. Additionally, we introduce an efficient data synthesis method to generate judgmental content. Experimental results demonstrate that our approach, utilizing only about 2% to 40% of the data required by other methods, achieves SOTA performance on RewardBench. Furthermore, our training method enhances the general capabilities of the model by constructing complicated judge task, and the judge signals provided by our model have significantly enhanced the downstream DPO training performance of our internal models in our test to optimize policy model with Judge Model. We also open-source our model weights and training data to facilitate further research.
Improving Subgraph Representation Learning via Multi-View Augmentation
May 25, 2022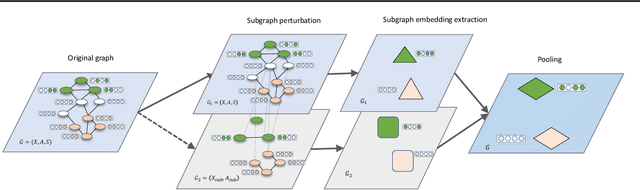
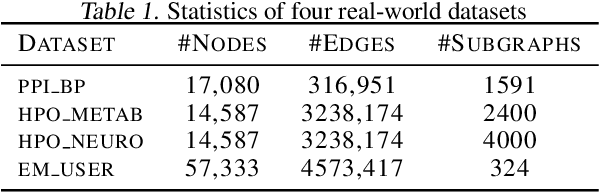

Subgraph representation learning based on Graph Neural Network (GNN) has broad applications in chemistry and biology, such as molecule property prediction and gene collaborative function prediction. On the other hand, graph augmentation techniques have shown promising results in improving graph-based and node-based classification tasks but are rarely explored in the GNN-based subgraph representation learning literature. In this work, we developed a novel multiview augmentation mechanism to improve subgraph representation learning and thus the accuracy of downstream prediction tasks. The augmentation technique creates multiple variants of subgraphs and embeds these variants into the original graph to achieve both high training efficiency, scalability, and improved accuracy. Experiments on several real-world subgraph benchmarks demonstrate the superiority of our proposed multi-view augmentation techniques.