 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompound Figure Separation of Biomedical Images: Mining Large Datasets for Self-supervised Learning
Aug 30, 2022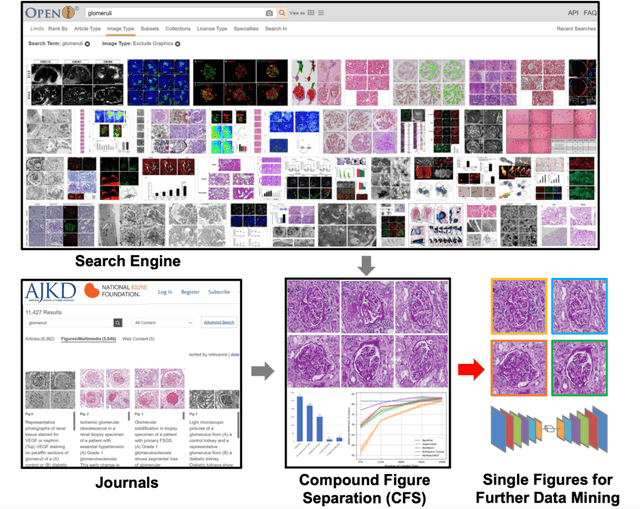
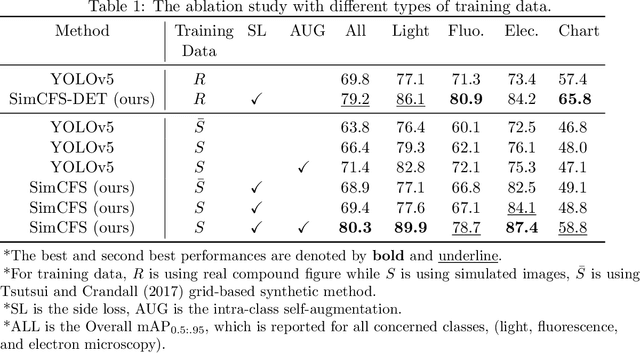
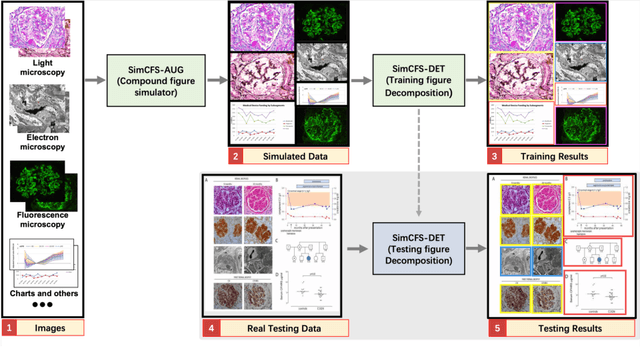
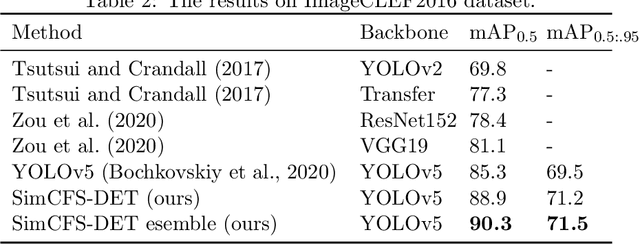
With the rapid development of self-supervised learning (e.g., contrastive learning), the importance of having large-scale images (even without annotations) for training a more generalizable AI model has been widely recognized in medical image analysis. However, collecting large-scale task-specific unannotated data at scale can be challenging for individual labs. Existing online resources, such as digital books, publications, and search engines, provide a new resource for obtaining large-scale images. However, published images in healthcare (e.g., radiology and pathology) consist of a considerable amount of compound figures with subplots. In order to extract and separate compound figures into usable individual images for downstream learning, we propose a simple compound figure separation (SimCFS) framework without using the traditionally required detection bounding box annotations, with a new loss function and a hard case simulation. Our technical contribution is four-fold: (1) we introduce a simulation-based training framework that minimizes the need for resource extensive bounding box annotations; (2) we propose a new side loss that is optimized for compound figure separation; (3) we propose an intra-class image augmentation method to simulate hard cases; and (4) to the best of our knowledge, this is the first study that evaluates the efficacy of leveraging self-supervised learning with compound image separation. From the results, the proposed SimCFS achieved state-of-the-art performance on the ImageCLEF 2016 Compound Figure Separation Database. The pretrained self-supervised learning model using large-scale mined figures improved the accuracy of downstream image classification tasks with a contrastive learning algorithm. The source code of SimCFS is made publicly available at https://github.com/hrlblab/ImageSeperation.
* Accepted for publication at the Journal of Machine Learning for Biomedical Imaging (MELBA) https://www.melba-journal.org/papers/2022:025.html. arXiv admin note: substantial text overlap with arXiv:2107.08650
Holistic Fine-grained GGS Characterization: From Detection to Unbalanced Classification
Jan 31, 2022



Recent studies have demonstrated the diagnostic and prognostic values of global glomerulosclerosis (GGS) in IgA nephropathy, aging, and end-stage renal disease. However, the fine-grained quantitative analysis of multiple GGS subtypes (e.g., obsolescent, solidified, and disappearing glomerulosclerosis) is typically a resource extensive manual process. Very few automatic methods, if any, have been developed to bridge this gap for such analytics. In this paper, we present a holistic pipeline to quantify GGS (with both detection and classification) from a whole slide image in a fully automatic manner. In addition, we conduct the fine-grained classification for the sub-types of GGS. Our study releases the open-source quantitative analytical tool for fine-grained GGS characterization while tackling the technical challenges in unbalanced classification and integrating detection and classification.
Semi-Supervised Contrastive Learning for Remote Sensing: Identifying Ancient Urbanization in the South Central Andes
Dec 13, 2021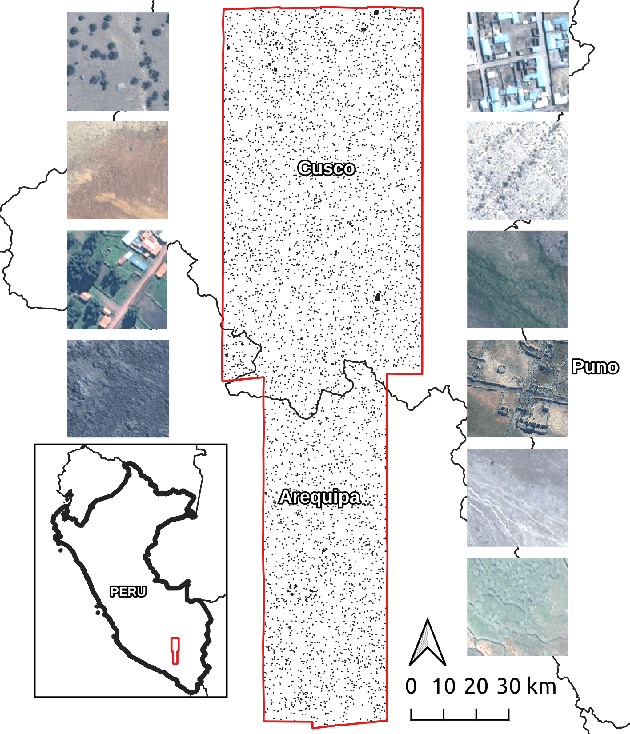

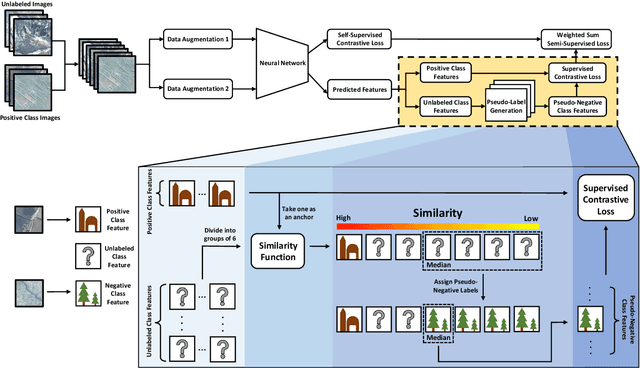

The detection of ancient settlements is a key focus in landscape archaeology. Traditionally, settlements were identified through pedestrian survey, as researchers physically traversed the landscape and recorded settlement locations. Recently the manual identification and labeling of ancient remains in satellite imagery have increased the scale of archaeological data collection, but the process remains tremendously time-consuming and arduous. The development of self-supervised learning (e.g., contrastive learning) offers a scalable learning scheme in locating archaeological sites using unlabeled satellite and historical aerial images. However, archaeology sites are only present in a very small proportion of the whole landscape, while the modern contrastive-supervised learning approach typically yield inferior performance on the highly balanced dataset, such as identifying sparsely localized ancient urbanization on a large area using satellite images. In this work, we propose a framework to solve this long-tail problem. As opposed to the existing contrastive learning approaches that typically treat the labeled and unlabeled data separately, the proposed method reforms the learning paradigm under a semi-supervised setting to fully utilize the precious annotated data (<7% in our setting). Specifically, the highly unbalanced nature of the data is employed as the prior knowledge to form pseudo negative pairs by ranking the similarities between unannotated image patches and annotated anchor images. In this study, we used 95,358 unlabeled images and 5,830 labeled images to solve the problem of detecting ancient buildings from a long-tailed satellite image dataset. From the results, our semi-supervised contrastive learning model achieved a promising testing balanced accuracy of 79.0%, which is 3.8% improvement over state-of-the-art approaches.
Exploring Versatile Prior for Human Motion via Motion Frequency Guidance
Nov 25, 2021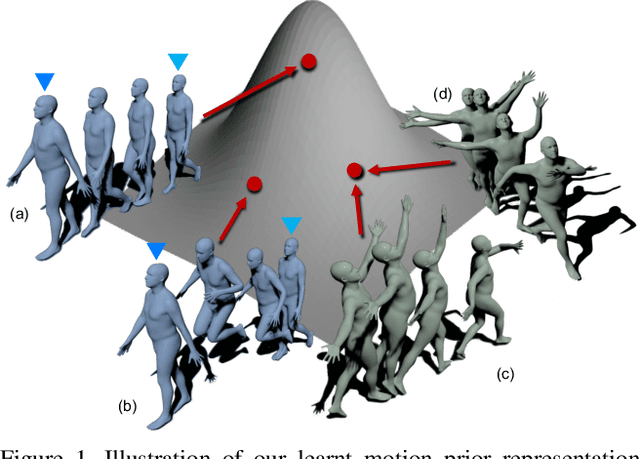
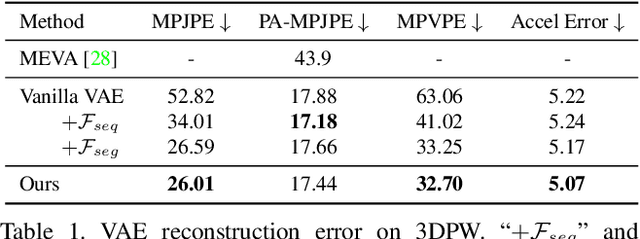
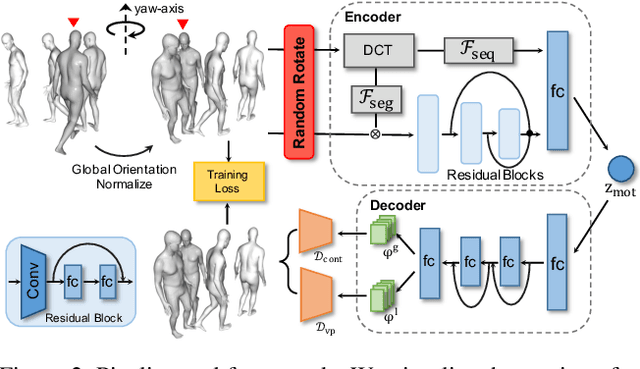
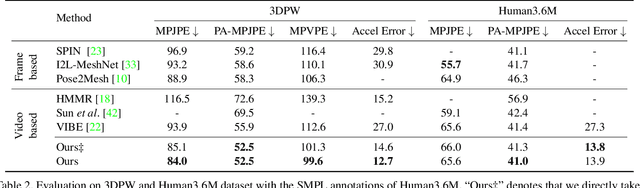
Prior plays an important role in providing the plausible constraint on human motion. Previous works design motion priors following a variety of paradigms under different circumstances, leading to the lack of versatility. In this paper, we first summarize the indispensable properties of the motion prior, and accordingly, design a framework to learn the versatile motion prior, which models the inherent probability distribution of human motions. Specifically, for efficient prior representation learning, we propose a global orientation normalization to remove redundant environment information in the original motion data space. Also, a two-level, sequence-based and segment-based, frequency guidance is introduced into the encoding stage. Then, we adopt a denoising training scheme to disentangle the environment information from input motion data in a learnable way, so as to generate consistent and distinguishable representation. Embedding our motion prior into prevailing backbones on three different tasks, we conduct extensive experiments, and both quantitative and qualitative results demonstrate the versatility and effectiveness of our motion prior. Our model and code are available at https://github.com/JchenXu/human-motion-prior.
Compound Figure Separation of Biomedical Images with Side Loss
Jul 19, 2021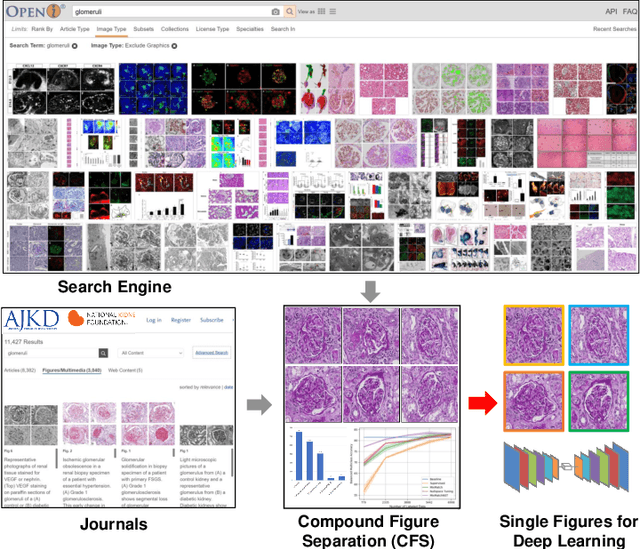
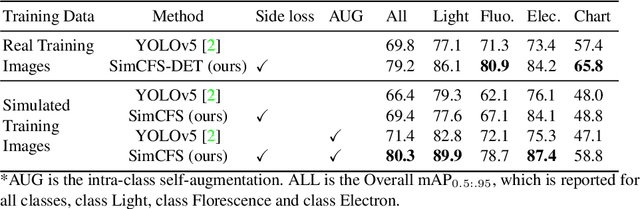
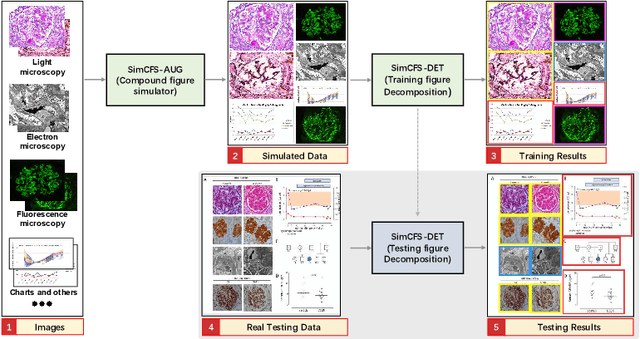
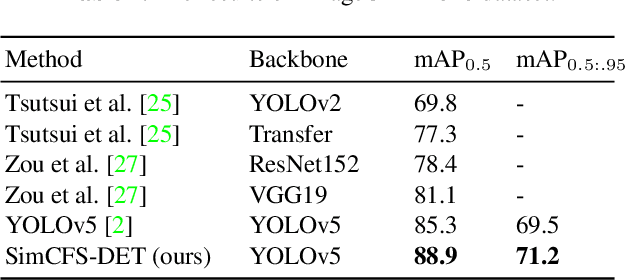
Unsupervised learning algorithms (e.g., self-supervised learning, auto-encoder, contrastive learning) allow deep learning models to learn effective image representations from large-scale unlabeled data. In medical image analysis, even unannotated data can be difficult to obtain for individual labs. Fortunately, national-level efforts have been made to provide efficient access to obtain biomedical image data from previous scientific publications. For instance, NIH has launched the Open-i search engine that provides a large-scale image database with free access. However, the images in scientific publications consist of a considerable amount of compound figures with subplots. To extract and curate individual subplots, many different compound figure separation approaches have been developed, especially with the recent advances in deep learning. However, previous approaches typically required resource extensive bounding box annotation to train detection models. In this paper, we propose a simple compound figure separation (SimCFS) framework that uses weak classification annotations from individual images. Our technical contribution is three-fold: (1) we introduce a new side loss that is designed for compound figure separation; (2) we introduce an intra-class image augmentation method to simulate hard cases; (3) the proposed framework enables an efficient deployment to new classes of images, without requiring resource extensive bounding box annotations. From the results, the SimCFS achieved a new state-of-the-art performance on the ImageCLEF 2016 Compound Figure Separation Database. The source code of SimCFS is made publicly available at https://github.com/hrlblab/ImageSeperation.
Omni-supervised Point Cloud Segmentation via Gradual Receptive Field Component Reasoning
May 21, 2021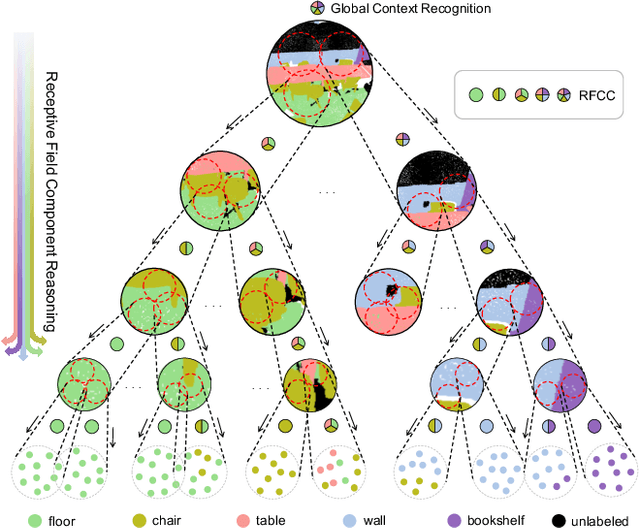
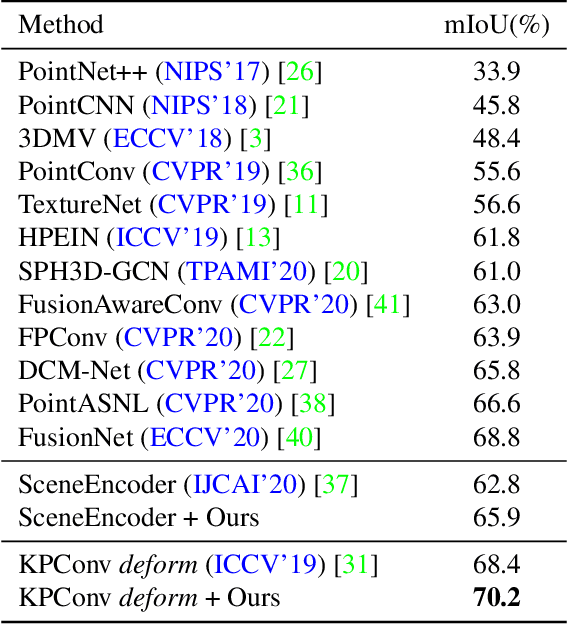
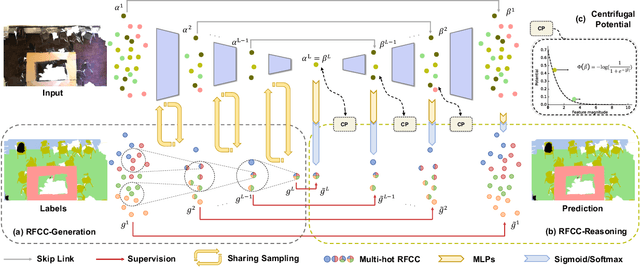
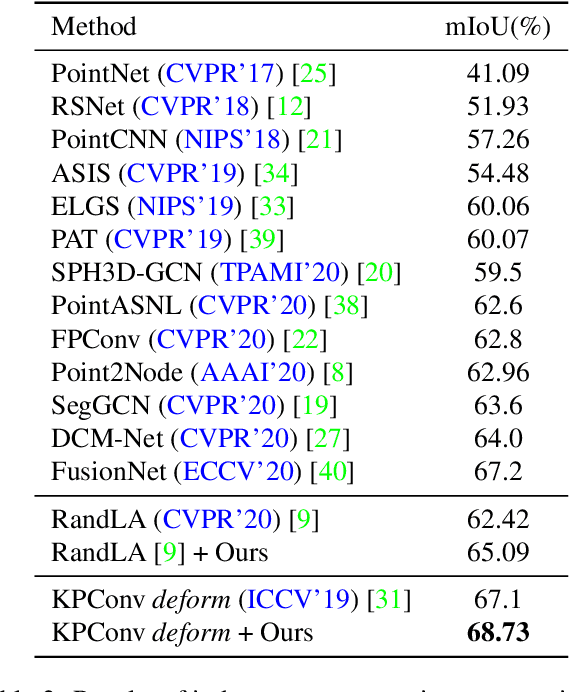
Hidden features in neural network usually fail to learn informative representation for 3D segmentation as supervisions are only given on output prediction, while this can be solved by omni-scale supervision on intermediate layers. In this paper, we bring the first omni-scale supervision method to point cloud segmentation via the proposed gradual Receptive Field Component Reasoning (RFCR), where target Receptive Field Component Codes (RFCCs) are designed to record categories within receptive fields for hidden units in the encoder. Then, target RFCCs will supervise the decoder to gradually infer the RFCCs in a coarse-to-fine categories reasoning manner, and finally obtain the semantic labels. Because many hidden features are inactive with tiny magnitude and make minor contributions to RFCC prediction, we propose a Feature Densification with a centrifugal potential to obtain more unambiguous features, and it is in effect equivalent to entropy regularization over features. More active features can further unleash the potential of our omni-supervision method. We embed our method into four prevailing backbones and test on three challenging benchmarks. Our method can significantly improve the backbones in all three datasets. Specifically, our method brings new state-of-the-art performances for S3DIS as well as Semantic3D and ranks the 1st in the ScanNet benchmark among all the point-based methods. Code will be publicly available at https://github.com/azuki-miho/RFCR.
Boundary-Aware Geometric Encoding for Semantic Segmentation of Point Clouds
Jan 07, 2021
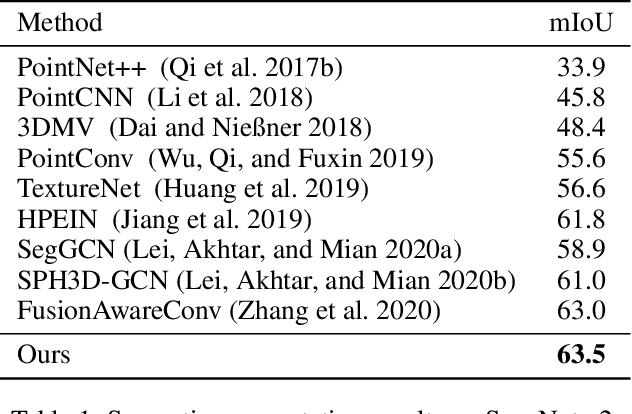
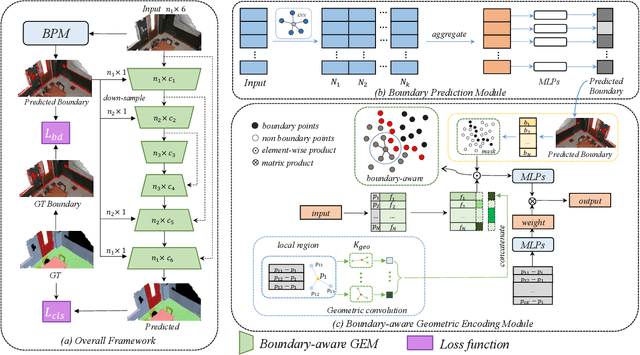
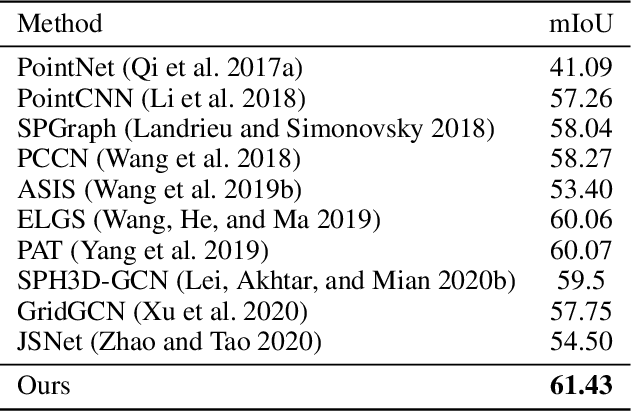
Boundary information plays a significant role in 2D image segmentation, while usually being ignored in 3D point cloud segmentation where ambiguous features might be generated in feature extraction, leading to misclassification in the transition area between two objects. In this paper, firstly, we propose a Boundary Prediction Module (BPM) to predict boundary points. Based on the predicted boundary, a boundary-aware Geometric Encoding Module (GEM) is designed to encode geometric information and aggregate features with discrimination in a neighborhood, so that the local features belonging to different categories will not be polluted by each other. To provide extra geometric information for boundary-aware GEM, we also propose a light-weight Geometric Convolution Operation (GCO), making the extracted features more distinguishing. Built upon the boundary-aware GEM, we build our network and test it on benchmarks like ScanNet v2, S3DIS. Results show our methods can significantly improve the baseline and achieve state-of-the-art performance. Code is available at https://github.com/JchenXu/BoundaryAwareGEM.
Analysis on DeepLabV3+ Performance for Automatic Steel Defects Detection
Apr 15, 2020
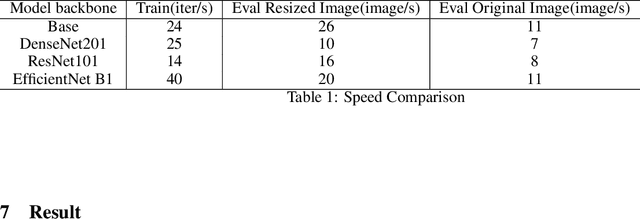
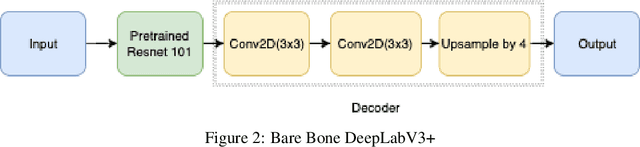
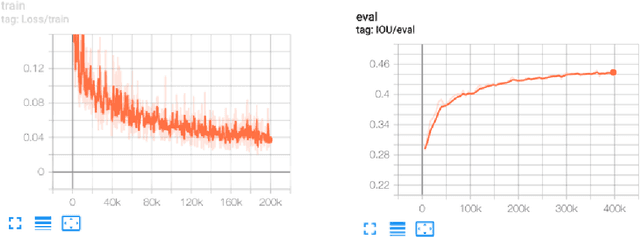
Our works experimented DeepLabV3+ with different backbones on a large volume of steel images aiming to automatically detect different types of steel defects. Our methods applied random weighted augmentation to balance different defects types in the training set. And then applied DeeplabV3+ model three different backbones, ResNet, DenseNet and EfficientNet, on segmenting defection regions on the steel images. Based on experiments, we found that applying ResNet101 or EfficientNet as backbones could reach the best IoU scores on the test set, which is around 0.57, comparing with 0.325 for using DenseNet. Also, DeepLabV3+ model with ResNet101 as backbone has the fewest training time.
SceneEncoder: Scene-Aware Semantic Segmentation of Point Clouds with A Learnable Scene Descriptor
Jan 24, 2020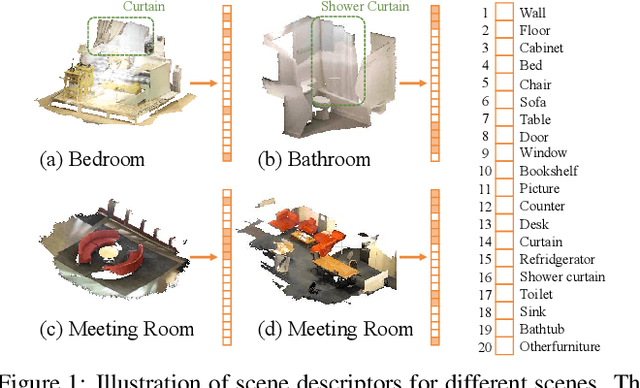
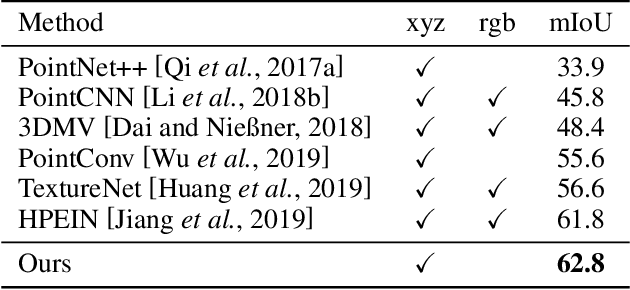
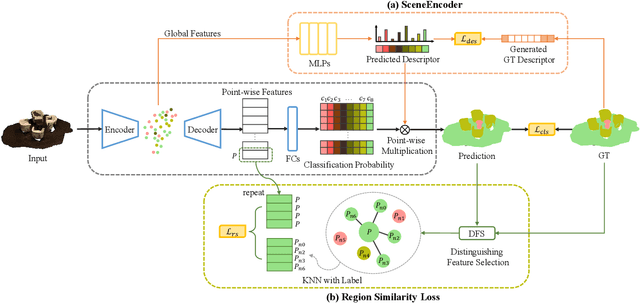
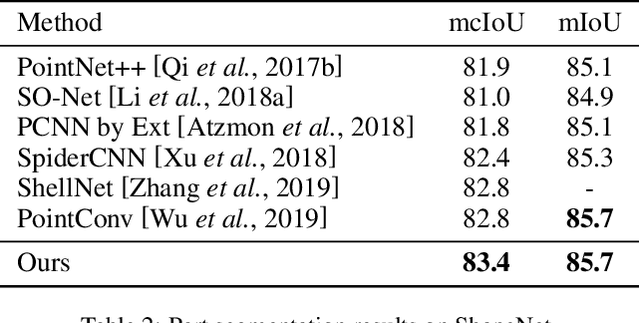
Besides local features, global information plays an essential role in semantic segmentation, while recent works usually fail to explicitly extract the meaningful global information and make full use of it. In this paper, we propose a SceneEncoder module to impose a scene-aware guidance to enhance the effect of global information. The module predicts a scene descriptor, which learns to represent the categories of objects existing in the scene and directly guides the point-level semantic segmentation through filtering out categories not belonging to this scene. Additionally, to alleviate segmentation noise in local region, we design a region similarity loss to propagate distinguishing features to their own neighboring points with the same label, leading to the enhancement of the distinguishing ability of point-wise features. We integrate our methods into several prevailing networks and conduct extensive experiments on benchmark datasets ScanNet and ShapeNet. Results show that our methods greatly improve the performance of baselines and achieve state-of-the-art performance.