 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Representational Invariances for Data-Efficient Action Recognition
Mar 30, 2021

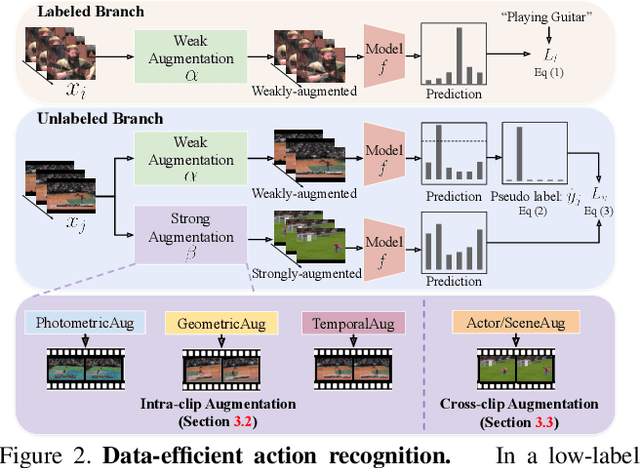
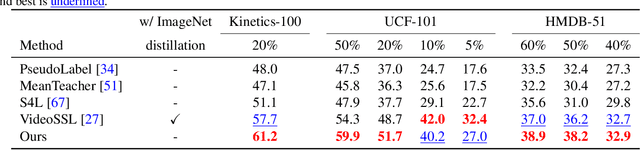
Data augmentation is a ubiquitous technique for improving image classification when labeled data is scarce. Constraining the model predictions to be invariant to diverse data augmentations effectively injects the desired representational invariances to the model (e.g., invariance to photometric variations), leading to improved accuracy. Compared to image data, the appearance variations in videos are far more complex due to the additional temporal dimension. Yet, data augmentation methods for videos remain under-explored. In this paper, we investigate various data augmentation strategies that capture different video invariances, including photometric, geometric, temporal, and actor/scene augmentations. When integrated with existing consistency-based semi-supervised learning frameworks, we show that our data augmentation strategy leads to promising performance on the Kinetics-100, UCF-101, and HMDB-51 datasets in the low-label regime. We also validate our data augmentation strategy in the fully supervised setting and demonstrate improved performance.
Neural Re-rendering for Full-frame Video Stabilization
Feb 12, 2021
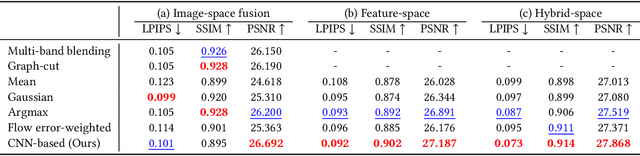
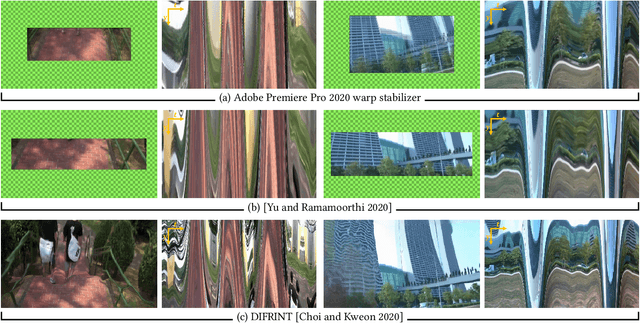
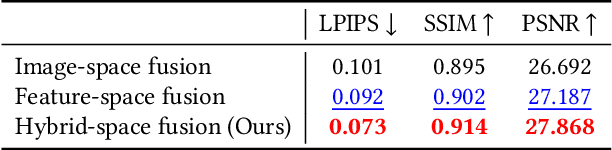
Existing video stabilization methods either require aggressive cropping of frame boundaries or generate distortion artifacts on the stabilized frames. In this work, we present an algorithm for full-frame video stabilization by first estimating dense warp fields. Full-frame stabilized frames can then be synthesized by fusing warped contents from neighboring frames. The core technical novelty lies in our learning-based hybrid-space fusion that alleviates artifacts caused by optical flow inaccuracy and fast-moving objects. We validate the effectiveness of our method on the NUS and selfie video datasets. Extensive experiment results demonstrate the merits of our approach over prior video stabilization methods.
Portrait Neural Radiance Fields from a Single Image
Dec 10, 2020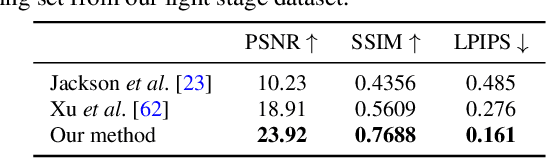
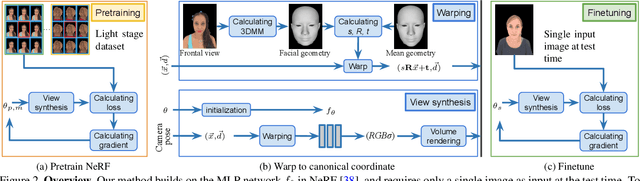
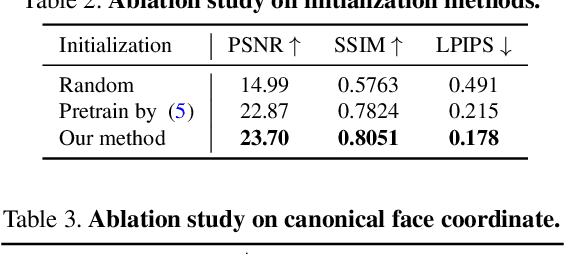
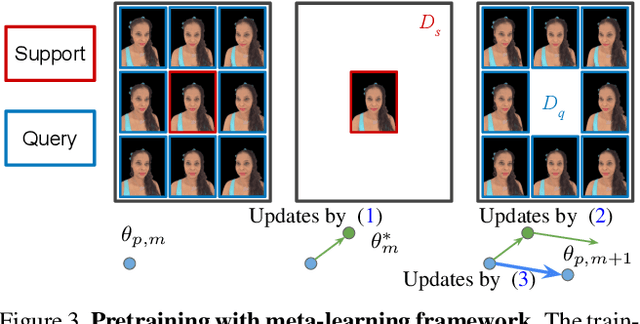
We present a method for estimating Neural Radiance Fields (NeRF) from a single headshot portrait. While NeRF has demonstrated high-quality view synthesis, it requires multiple images of static scenes and thus impractical for casual captures and moving subjects. In this work, we propose to pretrain the weights of a multilayer perceptron (MLP), which implicitly models the volumetric density and colors, with a meta-learning framework using a light stage portrait dataset. To improve the generalization to unseen faces, we train the MLP in the canonical coordinate space approximated by 3D face morphable models. We quantitatively evaluate the method using controlled captures and demonstrate the generalization to real portrait images, showing favorable results against state-of-the-arts.
Robust Consistent Video Depth Estimation
Dec 10, 2020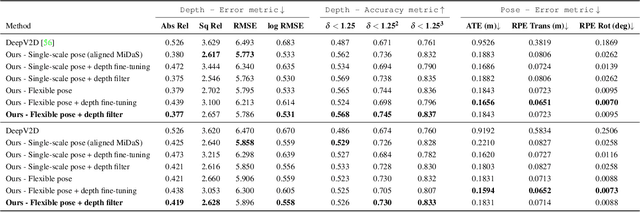
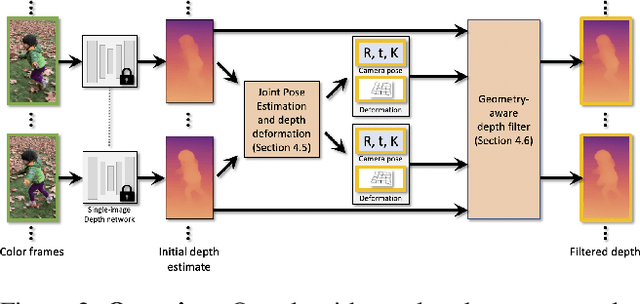
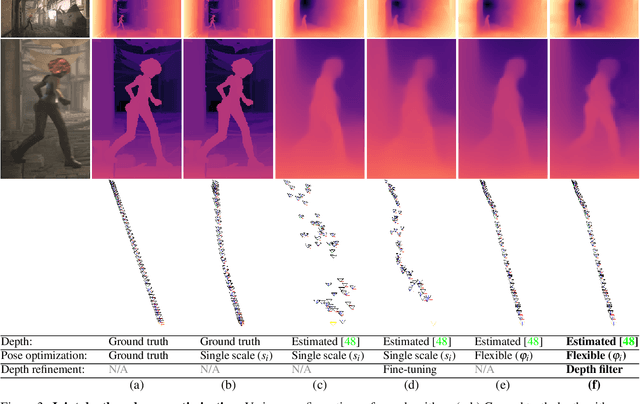
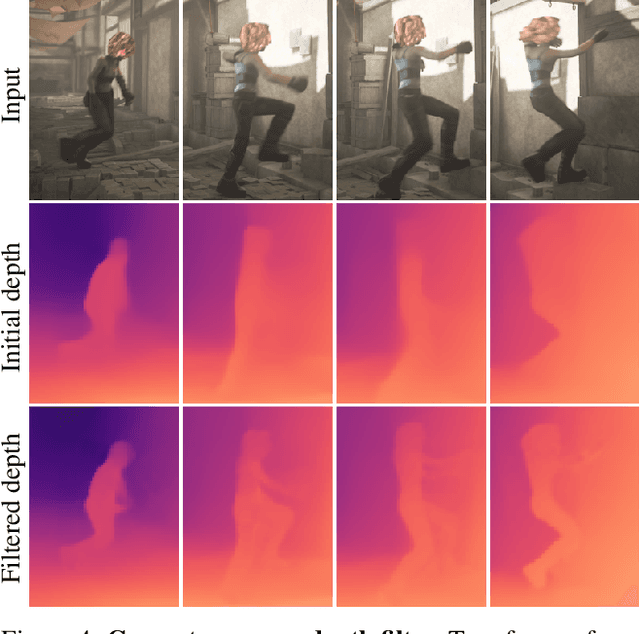
We present an algorithm for estimating consistent dense depth maps and camera poses from a monocular video. We integrate a learning-based depth prior, in the form of a convolutional neural network trained for single-image depth estimation, with geometric optimization, to estimate a smooth camera trajectory as well as detailed and stable depth reconstruction. Our algorithm combines two complementary techniques: (1) flexible deformation-splines for low-frequency large-scale alignment and (2) geometry-aware depth filtering for high-frequency alignment of fine depth details. In contrast to prior approaches, our method does not require camera poses as input and achieves robust reconstruction for challenging hand-held cell phone captures containing a significant amount of noise, shake, motion blur, and rolling shutter deformations. Our method quantitatively outperforms state-of-the-arts on the Sintel benchmark for both depth and pose estimations and attains favorable qualitative results across diverse wild datasets.
Space-time Neural Irradiance Fields for Free-Viewpoint Video
Nov 25, 2020

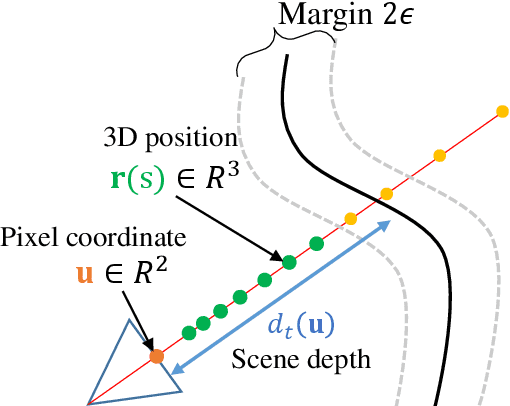

We present a method that learns a spatiotemporal neural irradiance field for dynamic scenes from a single video. Our learned representation enables free-viewpoint rendering of the input video. Our method builds upon recent advances in implicit representations. Learning a spatiotemporal irradiance field from a single video poses significant challenges because the video contains only one observation of the scene at any point in time. The 3D geometry of a scene can be legitimately represented in numerous ways since varying geometry (motion) can be explained with varying appearance and vice versa. We address this ambiguity by constraining the time-varying geometry of our dynamic scene representation using the scene depth estimated from video depth estimation methods, aggregating contents from individual frames into a single global representation. We provide an extensive quantitative evaluation and demonstrate compelling free-viewpoint rendering results.
Continuous and Diverse Image-to-Image Translation via Signed Attribute Vectors
Nov 03, 2020

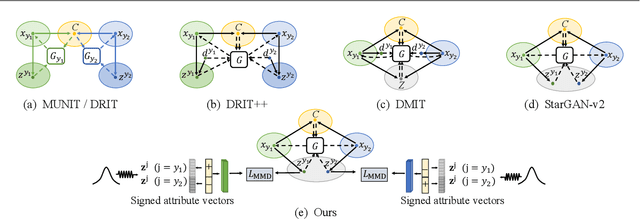
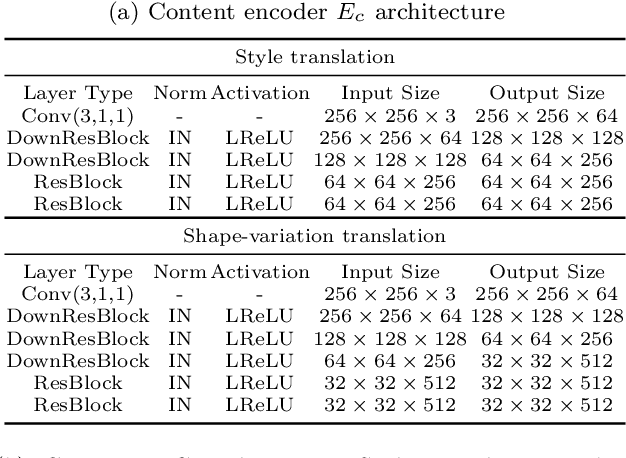
Recent image-to-image (I2I) translation algorithms focus on learning the mapping from a source to a target domain. However, the continuous translation problem that synthesizes intermediate results between the two domains has not been well-studied in the literature. Generating a smooth sequence of intermediate results bridges the gap of two different domains, facilitating the morphing effect across domains. Existing I2I approaches are limited to either intra-domain or deterministic inter-domain continuous translation. In this work, we present an effective signed attribute vector, which enables continuous translation on diverse mapping paths across various domains. In particular, utilizing the sign operation to encode the domain information, we introduce a unified attribute space shared by all domains, thereby allowing the interpolation on attribute vectors of different domains. To enhance the visual quality of continuous translation results, we generate a trajectory between two sign-symmetrical attribute vectors and leverage the domain information of the interpolated results along the trajectory for adversarial training. We evaluate the proposed method on a wide range of I2I translation tasks. Both qualitative and quantitative results demonstrate that the proposed framework generates more high-quality continuous translation results against the state-of-the-art methods.
Few-Shot Adaptation of Generative Adversarial Networks
Oct 22, 2020

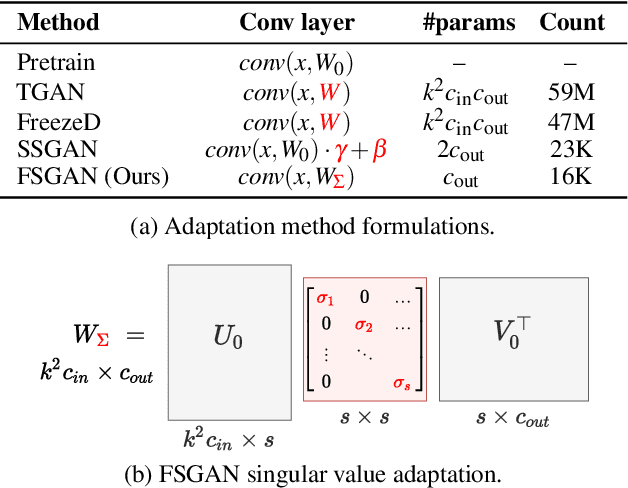

Generative Adversarial Networks (GANs) have shown remarkable performance in image synthesis tasks, but typically require a large number of training samples to achieve high-quality synthesis. This paper proposes a simple and effective method, Few-Shot GAN (FSGAN), for adapting GANs in few-shot settings (less than 100 images). FSGAN repurposes component analysis techniques and learns to adapt the singular values of the pre-trained weights while freezing the corresponding singular vectors. This provides a highly expressive parameter space for adaptation while constraining changes to the pretrained weights. We validate our method in a challenging few-shot setting of 5-100 images in the target domain. We show that our method has significant visual quality gains compared with existing GAN adaptation methods. We report qualitative and quantitative results showing the effectiveness of our method. We additionally highlight a problem for few-shot synthesis in the standard quantitative metric used by data-efficient image synthesis works. Code and additional results are available at http://e-271.github.io/few-shot-gan.
PseudoSeg: Designing Pseudo Labels for Semantic Segmentation
Oct 19, 2020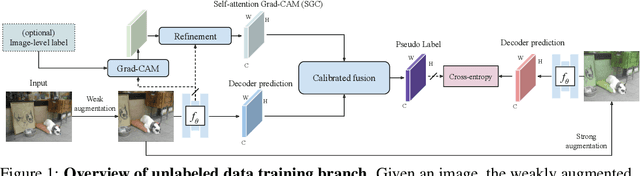
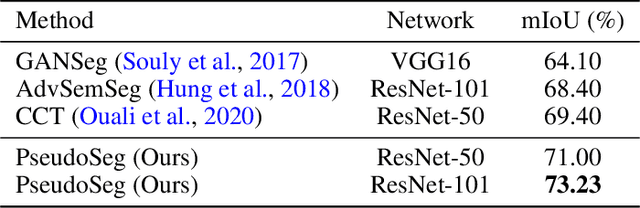

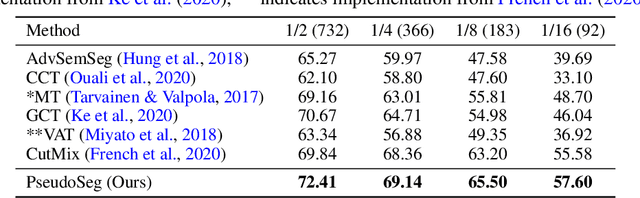
Recent advances in semi-supervised learning (SSL) demonstrate that a combination of consistency regularization and pseudo-labeling can effectively improve image classification accuracy in the low-data regime. Compared to classification, semantic segmentation tasks require much more intensive labeling costs. Thus, these tasks greatly benefit from data-efficient training methods. However, structured outputs in segmentation render particular difficulties (e.g., designing pseudo-labeling and augmentation) to apply existing SSL strategies. To address this problem, we present a simple and novel re-design of pseudo-labeling to generate well-calibrated structured pseudo labels for training with unlabeled or weakly-labeled data. Our proposed pseudo-labeling strategy is network structure agnostic to apply in a one-stage consistency training framework. We demonstrate the effectiveness of the proposed pseudo-labeling strategy in both low-data and high-data regimes. Extensive experiments have validated that pseudo labels generated from wisely fusing diverse sources and strong data augmentation are crucial to consistency training for segmentation. The source code is available at https://github.com/googleinterns/wss.
Flow-edge Guided Video Completion
Sep 03, 2020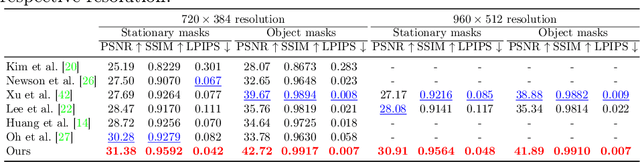
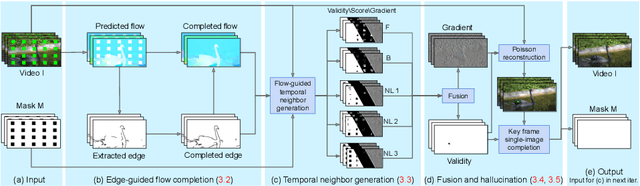
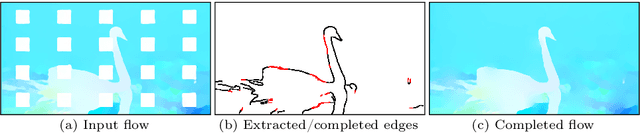

We present a new flow-based video completion algorithm. Previous flow completion methods are often unable to retain the sharpness of motion boundaries. Our method first extracts and completes motion edges, and then uses them to guide piecewise-smooth flow completion with sharp edges. Existing methods propagate colors among local flow connections between adjacent frames. However, not all missing regions in a video can be reached in this way because the motion boundaries form impenetrable barriers. Our method alleviates this problem by introducing non-local flow connections to temporally distant frames, enabling propagating video content over motion boundaries. We validate our approach on the DAVIS dataset. Both visual and quantitative results show that our method compares favorably against the state-of-the-art algorithms.
DRG: Dual Relation Graph for Human-Object Interaction Detection
Aug 26, 2020

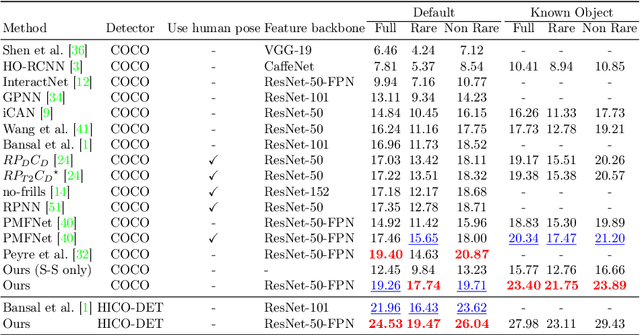
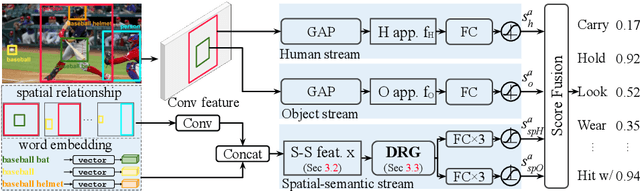
We tackle the challenging problem of human-object interaction (HOI) detection. Existing methods either recognize the interaction of each human-object pair in isolation or perform joint inference based on complex appearance-based features. In this paper, we leverage an abstract spatial-semantic representation to describe each human-object pair and aggregate the contextual information of the scene via a dual relation graph (one human-centric and one object-centric). Our proposed dual relation graph effectively captures discriminative cues from the scene to resolve ambiguity from local predictions. Our model is conceptually simple and leads to favorable results compared to the state-of-the-art HOI detection algorithms on two large-scale benchmark datasets.