 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImprovements to Target-Based 3D LiDAR to Camera Calibration
Oct 07, 2019



The homogeneous transformation between a LiDAR and monocular camera is required for sensor fusion tasks, such as SLAM. While determining such a transformation is not considered glamorous in any sense of the word, it is nonetheless crucial for many modern autonomous systems. Indeed, an error of a few degrees in rotation or a few percent in translation can lead to 20 cm translation errors at a distance of 5 m when overlaying a LiDAR image on a camera image. The biggest impediments to determining the transformation accurately are the relative sparsity of LiDAR point clouds and systematic errors in their distance measurements. This paper proposes (1) the use of targets of known dimension and geometry to ameliorate target pose estimation in face of the quantization and systematic errors inherent in a LiDAR image of a target, and (2) a fitting method for the LiDAR to monocular camera transformation that fundamentally assumes the camera image data is the most accurate information in one's possession.
Adaptive Continuous Visual Odometry from RGB-D Images
Oct 01, 2019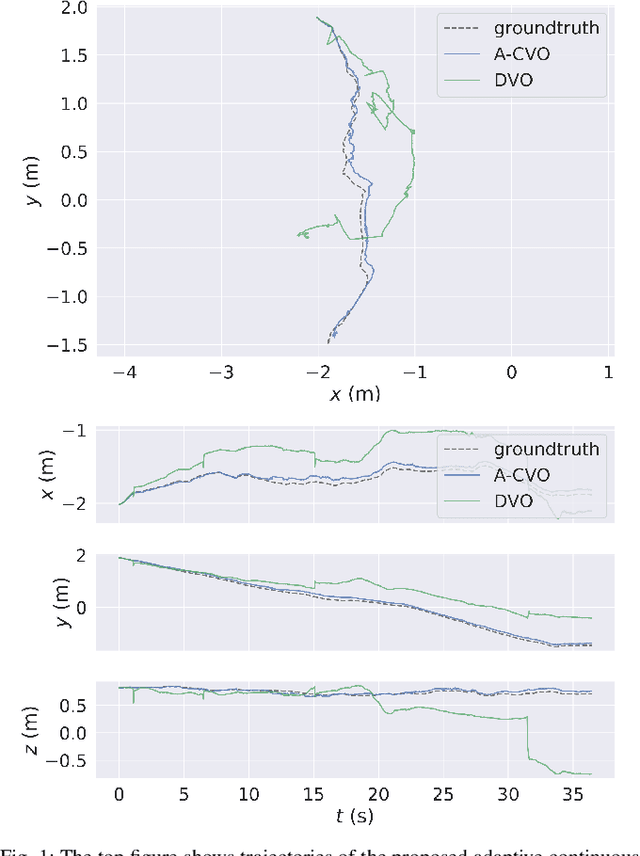
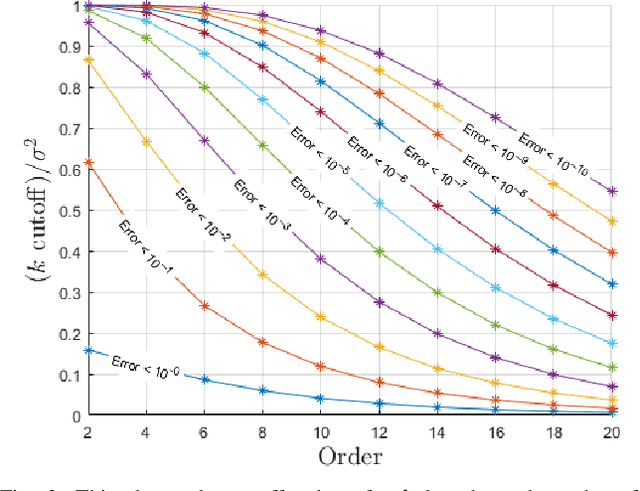

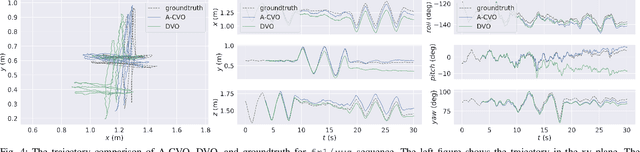
In this paper, we extend the recently developed continuous visual odometry framework for RGB-D cameras to an adaptive framework via online hyperparameter learning. We focus on the case of isotropic kernels with a scalar as the length-scale. In practice and as expected, the length-scale has remarkable impacts on the performance of the original framework. Previously it was handled using a fixed set of conditions within the solver to reduce the length-scale as the algorithm reaches a local minimum. We automate this process by a greedy gradient descent step at each iteration to find the next-best length-scale. Furthermore, to handle failure cases in the gradient descent step where the gradient is not well-behaved, such as the absence of structure or texture in the scene, we use a search interval for the length-scale and guide it gradually toward the smaller values. This latter strategy reverts the adaptive framework to the original setup. The experimental evaluations using publicly available RGB-D benchmarks show the proposed adaptive continuous visual odometry outperforms the original framework and the current state-of-the-art. We also make the software for the developed algorithm publicly available.
Bayesian Spatial Kernel Smoothing for ScalableDense Semantic Mapping
Sep 10, 2019
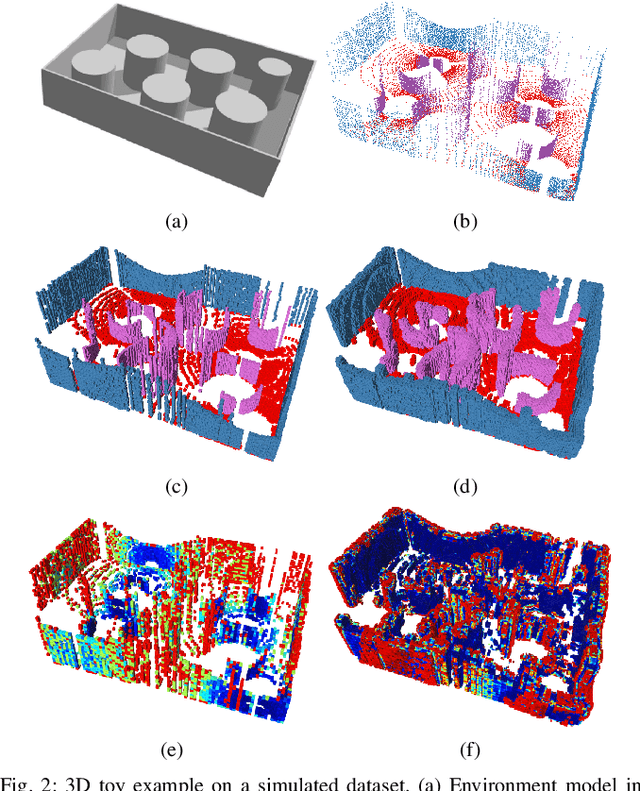


This paper develops a Bayesian continuous 3D semantic occupancy map from noisy point cloud measurements. In particular, we generalize the Bayesian kernel inference model for occupancy (binary) map building to semantic (multi-class) maps. The method nicely reverts to the original occupancy mapping framework when only one occupied class exists in obtained measurements. First, using Categorical likelihood and its conjugate prior distribution, we extend the counting sensor model for binary classification to a multi-class classification problem which results in a unified probabilistic model for both occupancy and semantic probabilities. Secondly, by applying a Bayesian spatial kernel inference to the semantic counting sensor model, we relax the independent grid assumption and bring smoothness and continuity to the map inference. These latter properties enable the method to exploit local correlations present in the environment to predict semantic probabilities in regions unobserved by the sensor while increasing the performance. Lastly, computational efficiency and scalability are achieved by leveraging sparse kernels and a test-data octrees data structure. The evaluations using multiple sequences of stereo camera and LiDAR datasets show that the proposed method consistently outperforms the compared baselines. We also present a qualitative evaluation using data collected by a biped robot platform on the University of Michigan - North Campus.
LiDARTag: A Real-Time Fiducial Tag using Point Clouds
Aug 23, 2019
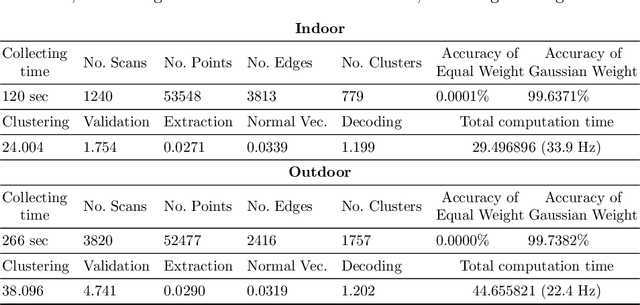

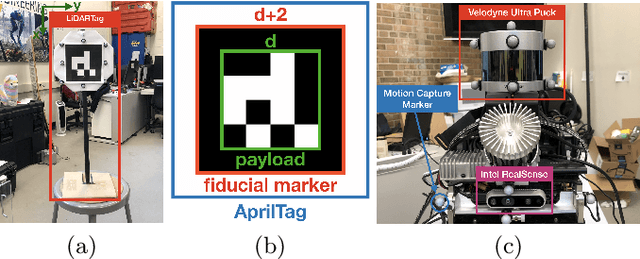
Image-based fiducial markers are widely used in robotics and computer vision problems such as object tracking in cluttered or textureless environments, camera (and multi-sensor) calibration tasks, or vision-based simultaneous localization and mapping (SLAM). The state-of-the-art fiducial marker detection algorithms rely on consistency of the ambient lighting. This paper introduces LiDARTag, a novel fiducial tag design and detection algorithm suitable for light detection and ranging (LiDAR) point clouds. The proposed tag runs in real-time and can process data faster than the currently available LiDAR sensors frequencies. Due to the nature of the LiDAR's sensor, rapidly changing ambient lighting will not affect detection of a LiDARTag; hence, the proposed fiducial marker can operate in a completely dark environment. In addition, the LiDARTag nicely complements available visual fiducial markers as the tag design is compatible with available techniques, such as AprilTags, allowing for efficient multi-sensor fusion and calibration tasks. The experimental results, verified by a motion capture system, confirm the proposed technique can reliably provide a tag's pose and its unique ID code. All implementations are done in C++ and will be available soon at: https://github.com/brucejk/LiDARTag
Continuous Direct Sparse Visual Odometry from RGB-D Images
May 21, 2019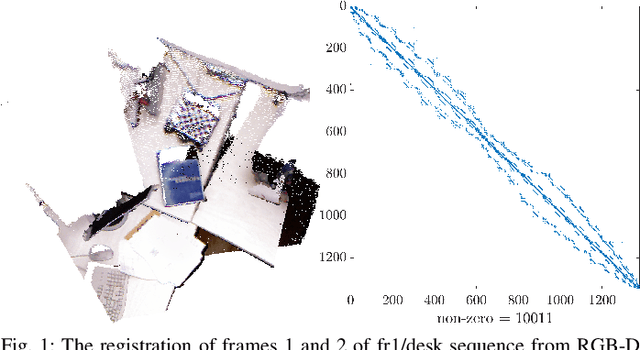
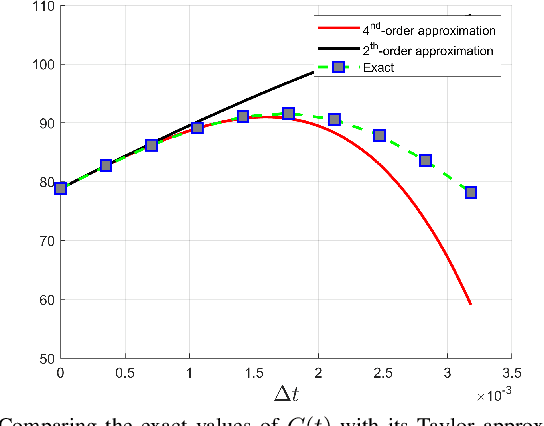
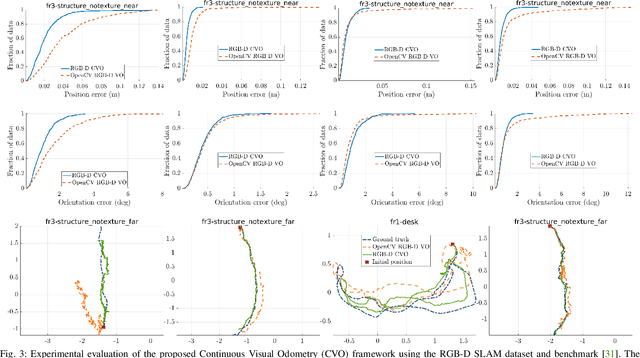

This paper reports on a novel formulation and evaluation of visual odometry from RGB-D images. Assuming a static scene, the developed theoretical framework generalizes the widely used direct energy formulation (photometric error minimization) technique for obtaining a rigid body transformation that aligns two overlapping RGB-D images to a continuous formulation. The continuity is achieved through functional treatment of the problem and representing the process models over RGB-D images in a reproducing kernel Hilbert space; consequently, the registration is not limited to the specific image resolution and the framework is fully analytical with a closed-form derivation of the gradient. We solve the problem by maximizing the inner product between two functions defined over RGB-D images, while the continuous action of the rigid body motion Lie group is captured through the integration of the flow in the corresponding Lie algebra. Energy-based approaches have been extremely successful and the developed framework in this paper shares many of their desired properties such as the parallel structure on both CPUs and GPUs, sparsity, semi-dense tracking, avoiding explicit data association which is computationally expensive, and possible extensions to the simultaneous localization and mapping frameworks. The evaluations on experimental data and comparison with the equivalent energy-based formulation of the problem confirm the effectiveness of the proposed technique, especially, when the lack of structure and texture in the environment is evident.
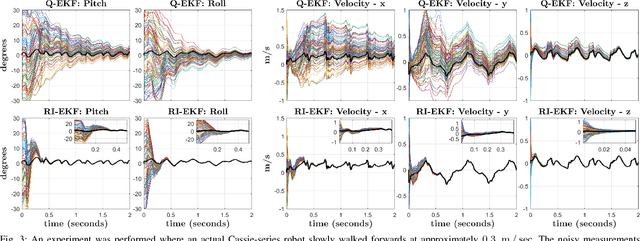
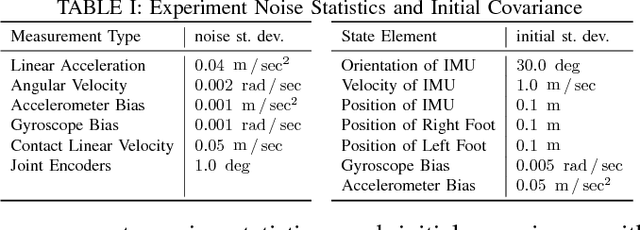
Contact-Aided Invariant Extended Kalman Filtering for Robot State Estimation
Apr 19, 2019
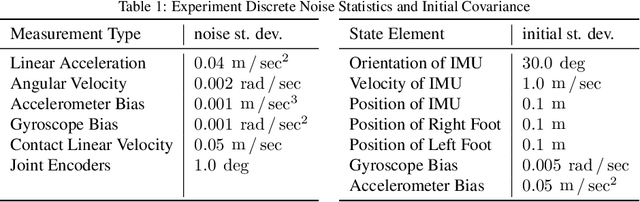
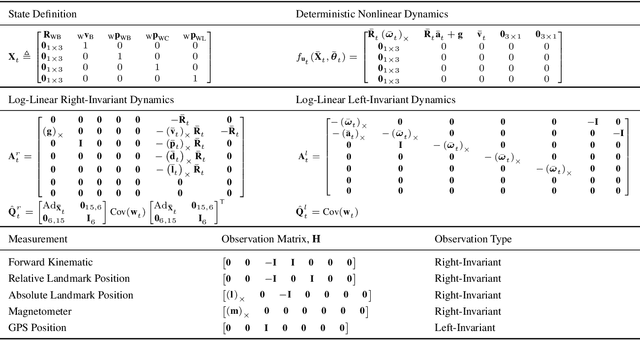
Legged robots require knowledge of pose and velocity in order to maintain stability and execute walking paths. Current solutions either rely on vision data, which is susceptible to environmental and lighting conditions, or fusion of kinematic and contact data with measurements from an inertial measurement unit (IMU). In this work, we develop a contact-aided invariant extended Kalman filter (InEKF) using the theory of Lie groups and invariant observer design. This filter combines contact-inertial dynamics with forward kinematic corrections to estimate pose and velocity along with all current contact points. We show that the error dynamics follows a log-linear autonomous differential equation with several important consequences: (a) the observable state variables can be rendered convergent with a domain of attraction that is independent of the system's trajectory; (b) unlike the standard EKF, neither the linearized error dynamics nor the linearized observation model depend on the current state estimate, which (c) leads to improved convergence properties and (d) a local observability matrix that is consistent with the underlying nonlinear system. Furthermore, we demonstrate how to include IMU biases, add/remove contacts, and formulate both world-centric and robo-centric versions. We compare the convergence of the proposed InEKF with the commonly used quaternion-based EKF though both simulations and experiments on a Cassie-series bipedal robot. Filter accuracy is analyzed using motion capture, while a LiDAR mapping experiment provides a practical use case. Overall, the developed contact-aided InEKF provides better performance in comparison with the quaternion-based EKF as a result of exploiting symmetries present in system.
Rapid Trajectory Optimization Using C-FROST with Illustration on a Cassie-Series Dynamic Walking Biped
Mar 15, 2019
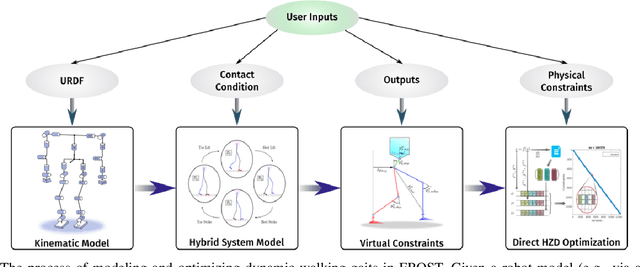
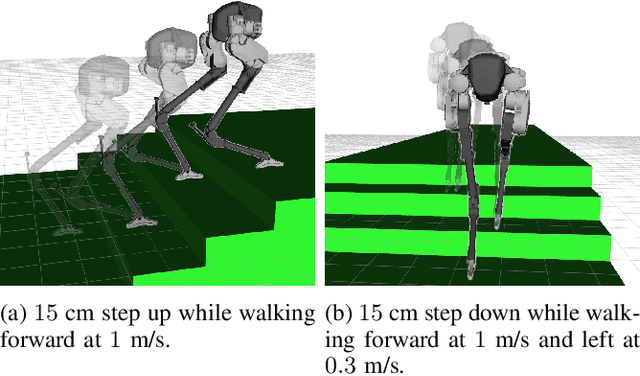
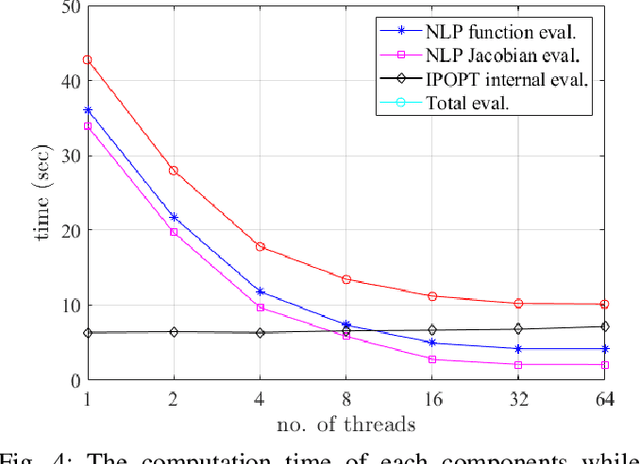
One of the big attractions of low-dimensional models for gait design has been the ability to compute solutions rapidly, whereas one of their drawbacks has been the difficulty in mapping the solutions back to the target robot. This paper presents a set of tools for rapidly determining solutions for ``humanoids'' without removing or lumping degrees of freedom. The main tools are (1) C-FROST, an open-source C++ interface for FROST, a direct collocation optimization tool; and (2) multi-threading. The results will be illustrated on a 20-DoF floating-base model for a Cassie-series bipedal robot through numerical calculations and physical experiments.
Hybrid Contact Preintegration for Visual-Inertial-Contact State Estimation Using Factor Graphs
Oct 02, 2018
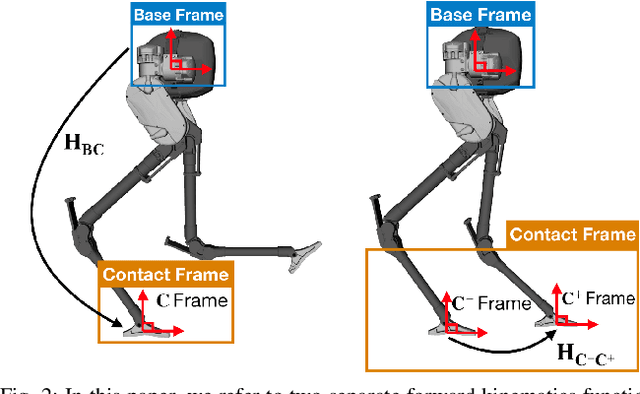
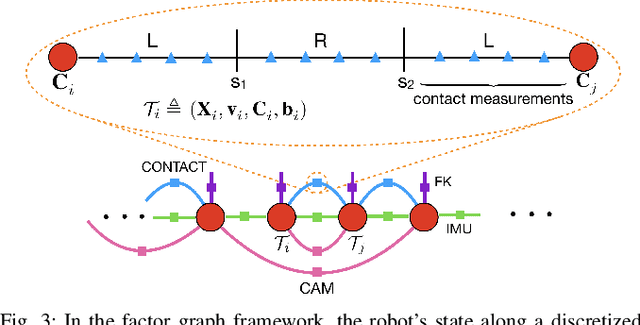
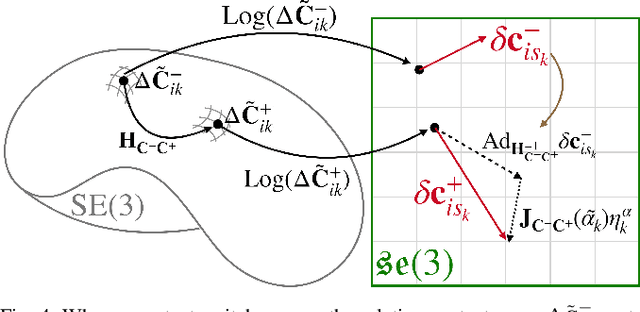
The factor graph framework is a convenient modeling technique for robotic state estimation where states are represented as nodes, and measurements are modeled as factors. When designing a sensor fusion framework for legged robots, one often has access to visual, inertial, joint encoder, and contact sensors. While visual-inertial odometry has been studied extensively in this framework, the addition of a preintegrated contact factor for legged robots has been only recently proposed. This allowed for integration of encoder and contact measurements into existing factor graphs, however, new nodes had to be added to the graph every time contact was made or broken. In this work, to cope with the problem of switching contact frames, we propose a hybrid contact preintegration theory that allows contact information to be integrated through an arbitrary number of contact switches. The proposed hybrid modeling approach reduces the number of required variables in the nonlinear optimization problem by only requiring new states to be added alongside camera or selected keyframes. This method is evaluated using real experimental data collected from a Cassie-series robot where the trajectory of the robot produced by a motion capture system is used as a proxy for ground truth. The evaluation shows that inclusion of the proposed preintegrated hybrid contact factor alongside visual-inertial navigation systems improves estimation accuracy as well as robustness to vision failure, while its generalization makes it more accessible for legged platforms.
Contact-Aided Invariant Extended Kalman Filtering for Legged Robot State Estimation
May 26, 2018
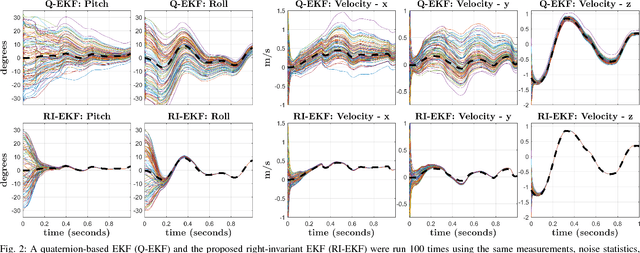
This paper derives a contact-aided inertial navigation observer for a 3D bipedal robot using the theory of invariant observer design. Aided inertial navigation is fundamentally a nonlinear observer design problem; thus, current solutions are based on approximations of the system dynamics, such as an Extended Kalman Filter (EKF), which uses a system's Jacobian linearization along the current best estimate of its trajectory. On the basis of the theory of invariant observer design by Barrau and Bonnabel, and in particular, the Invariant EKF (InEKF), we show that the error dynamics of the point contact-inertial system follows a log-linear autonomous differential equation; hence, the observable state variables can be rendered convergent with a domain of attraction that is independent of the system's trajectory. Due to the log-linear form of the error dynamics, it is not necessary to perform a nonlinear observability analysis to show that when using an Inertial Measurement Unit (IMU) and contact sensors, the absolute position of the robot and a rotation about the gravity vector (yaw) are unobservable. We further augment the state of the developed InEKF with IMU biases, as the online estimation of these parameters has a crucial impact on system performance. We evaluate the convergence of the proposed system with the commonly used quaternion-based EKF observer using a Monte-Carlo simulation. In addition, our experimental evaluation using a Cassie-series bipedal robot shows that the contact-aided InEKF provides better performance in comparison with the quaternion-based EKF as a result of exploiting symmetries present in the system dynamics.
Legged Robot State-Estimation Through Combined Forward Kinematic and Preintegrated Contact Factors
Feb 25, 2018
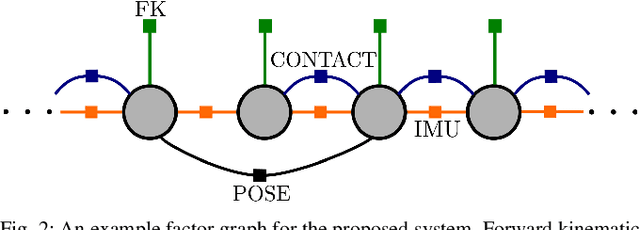
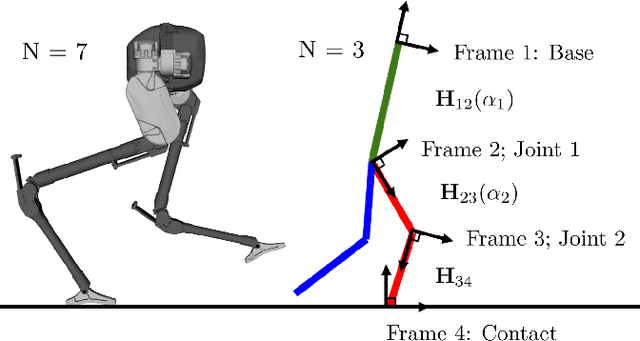
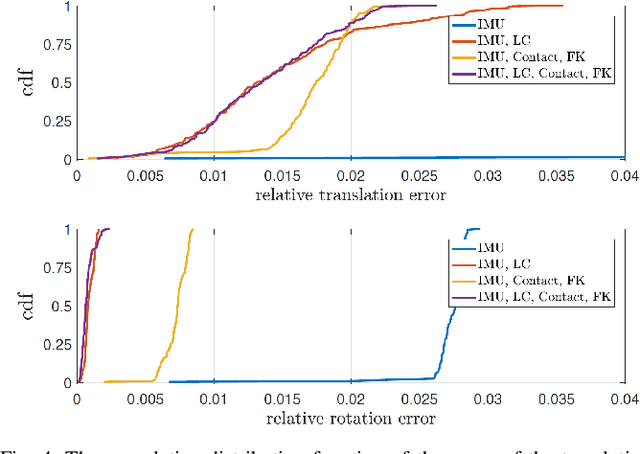
State-of-the-art robotic perception systems have achieved sufficiently good performance using Inertial Measurement Units (IMUs), cameras, and nonlinear optimization techniques, that they are now being deployed as technologies. However, many of these methods rely significantly on vision and often fail when visual tracking is lost due to lighting or scarcity of features. This paper presents a state-estimation technique for legged robots that takes into account the robot's kinematic model as well as its contact with the environment. We introduce forward kinematic factors and preintegrated contact factors into a factor graph framework that can be incrementally solved in real-time. The forward kinematic factor relates the robot's base pose to a contact frame through noisy encoder measurements. The preintegrated contact factor provides odometry measurements of this contact frame while accounting for possible foot slippage. Together, the two developed factors constrain the graph optimization problem allowing the robot's trajectory to be estimated. The paper evaluates the method using simulated and real sensory IMU and kinematic data from experiments with a Cassie-series robot designed by Agility Robotics. These preliminary experiments show that using the proposed method in addition to IMU decreases drift and improves localization accuracy, suggesting that its use can enable successful recovery from a loss of visual tracking.