 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGANSynth: Adversarial Neural Audio Synthesis
Apr 15, 2019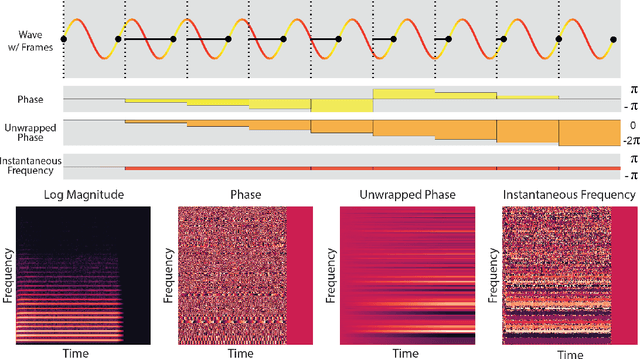
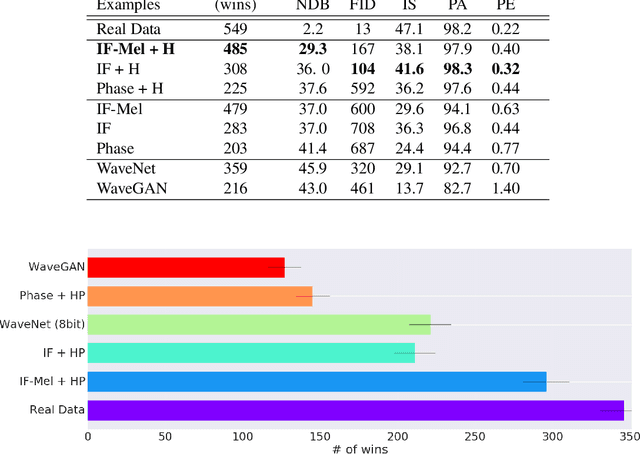
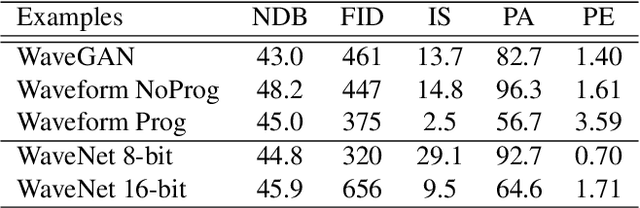
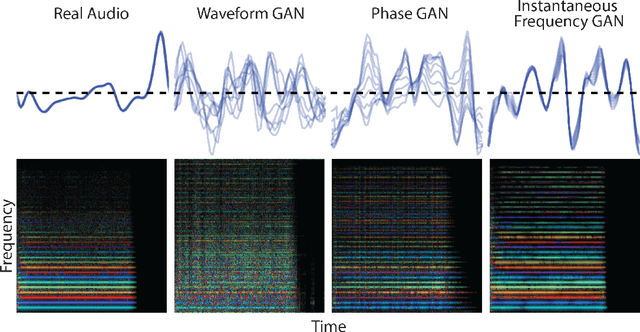
Efficient audio synthesis is an inherently difficult machine learning task, as human perception is sensitive to both global structure and fine-scale waveform coherence. Autoregressive models, such as WaveNet, model local structure at the expense of global latent structure and slow iterative sampling, while Generative Adversarial Networks (GANs), have global latent conditioning and efficient parallel sampling, but struggle to generate locally-coherent audio waveforms. Herein, we demonstrate that GANs can in fact generate high-fidelity and locally-coherent audio by modeling log magnitudes and instantaneous frequencies with sufficient frequency resolution in the spectral domain. Through extensive empirical investigations on the NSynth dataset, we demonstrate that GANs are able to outperform strong WaveNet baselines on automated and human evaluation metrics, and efficiently generate audio several orders of magnitude faster than their autoregressive counterparts.
Latent Translation: Crossing Modalities by Bridging Generative Models
Feb 21, 2019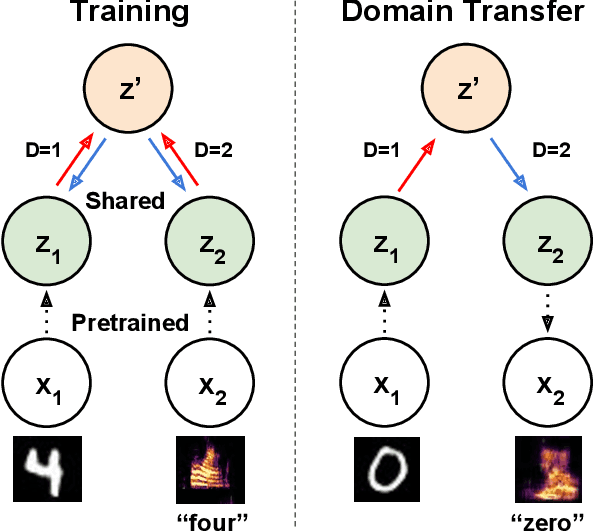
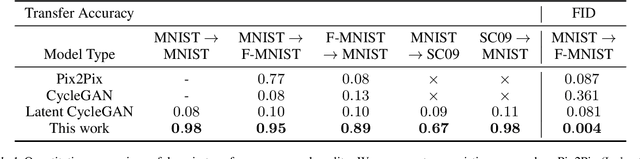

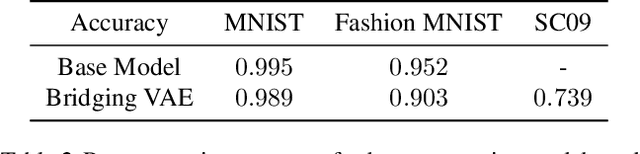
End-to-end optimization has achieved state-of-the-art performance on many specific problems, but there is no straight-forward way to combine pretrained models for new problems. Here, we explore improving modularity by learning a post-hoc interface between two existing models to solve a new task. Specifically, we take inspiration from neural machine translation, and cast the challenging problem of cross-modal domain transfer as unsupervised translation between the latent spaces of pretrained deep generative models. By abstracting away the data representation, we demonstrate that it is possible to transfer across different modalities (e.g., image-to-audio) and even different types of generative models (e.g., VAE-to-GAN). We compare to state-of-the-art techniques and find that a straight-forward variational autoencoder is able to best bridge the two generative models through learning a shared latent space. We can further impose supervised alignment of attributes in both domains with a classifier in the shared latent space. Through qualitative and quantitative evaluations, we demonstrate that locality and semantic alignment are preserved through the transfer process, as indicated by high transfer accuracies and smooth interpolations within a class. Finally, we show this modular structure speeds up training of new interface models by several orders of magnitude by decoupling it from expensive retraining of base generative models.
Enabling Factorized Piano Music Modeling and Generation with the MAESTRO Dataset
Oct 30, 2018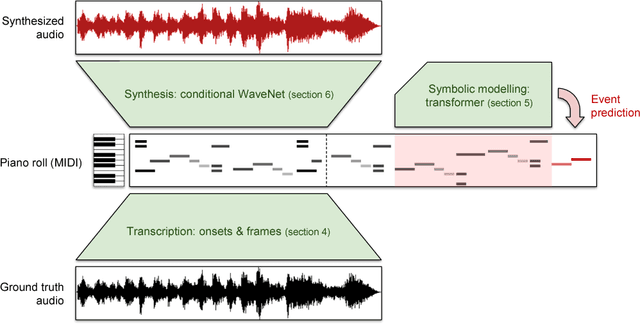

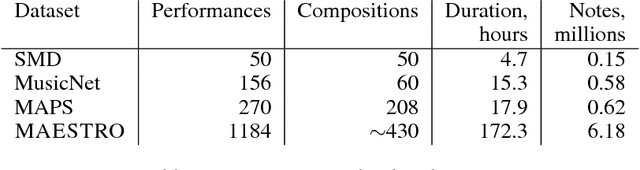
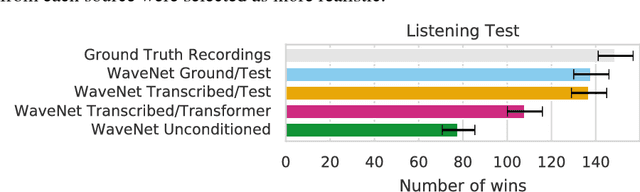
Generating musical audio directly with neural networks is notoriously difficult because it requires coherently modeling structure at many different timescales. Fortunately, most music is also highly structured and can be represented as discrete note events played on musical instruments. Herein, we show that by using notes as an intermediate representation, we can train a suite of models capable of transcribing, composing, and synthesizing audio waveforms with coherent musical structure on timescales spanning six orders of magnitude (~0.1 ms to ~100 s), a process we call Wave2Midi2Wave. This large advance in the state of the art is enabled by our release of the new MAESTRO (MIDI and Audio Edited for Synchronous TRacks and Organization) dataset, composed of over 172 hours of virtuosic piano performances captured with fine alignment (~3 ms) between note labels and audio waveforms. The networks and the dataset together present a promising approach toward creating new expressive and interpretable neural models of music.
Learning via social awareness: Improving a deep generative sketching model with facial feedback
Aug 27, 2018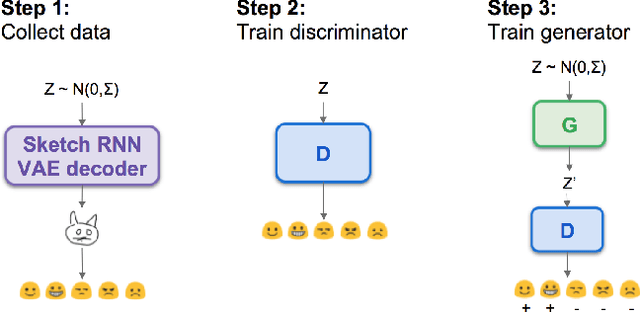
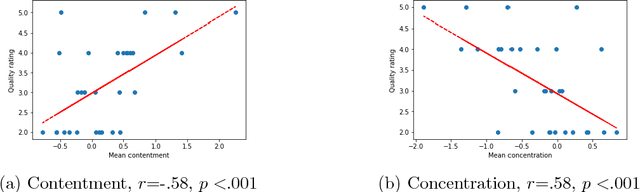
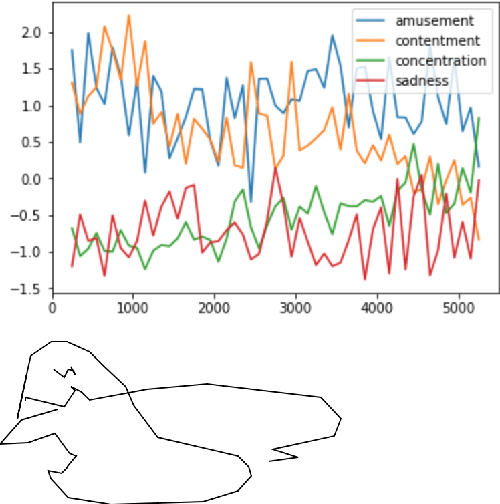
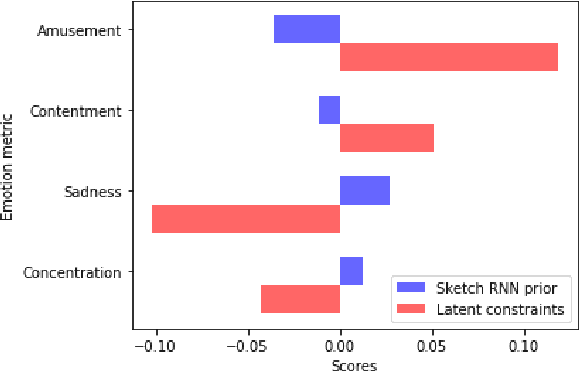
In the quest towards general artificial intelligence (AI), researchers have explored developing loss functions that act as intrinsic motivators in the absence of external rewards. This paper argues that such research has overlooked an important and useful intrinsic motivator: social interaction. We posit that making an AI agent aware of implicit social feedback from humans can allow for faster learning of more generalizable and useful representations, and could potentially impact AI safety. We collect social feedback in the form of facial expression reactions to samples from Sketch RNN, an LSTM-based variational autoencoder (VAE) designed to produce sketch drawings. We use a Latent Constraints GAN (LC-GAN) to learn from the facial feedback of a small group of viewers, by optimizing the model to produce sketches that it predicts will lead to more positive facial expressions. We show in multiple independent evaluations that the model trained with facial feedback produced sketches that are more highly rated, and induce significantly more positive facial expressions. Thus, we establish that implicit social feedback can improve the output of a deep learning model.
A Hierarchical Latent Vector Model for Learning Long-Term Structure in Music
Jul 30, 2018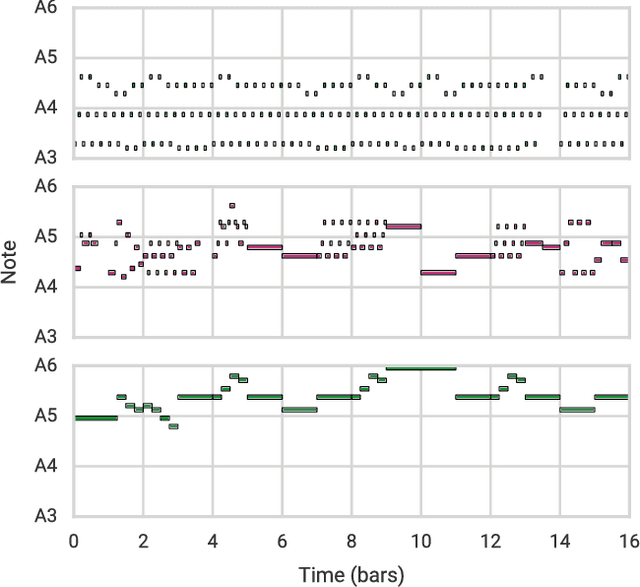
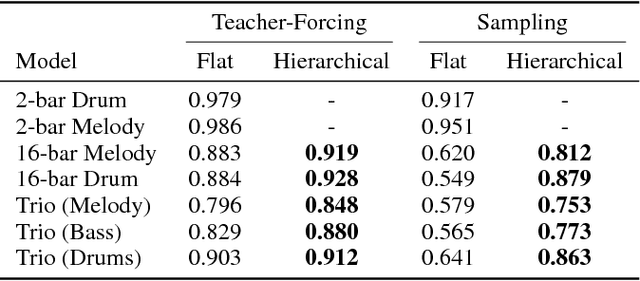
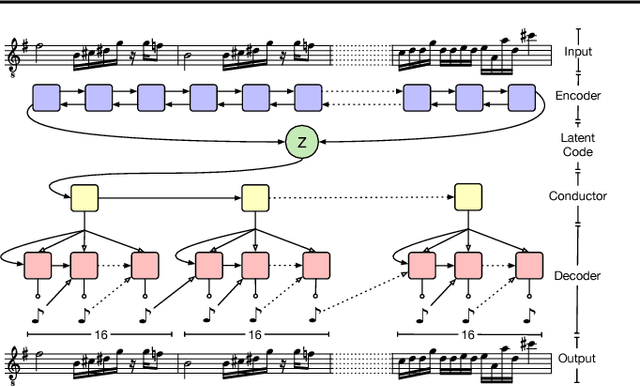
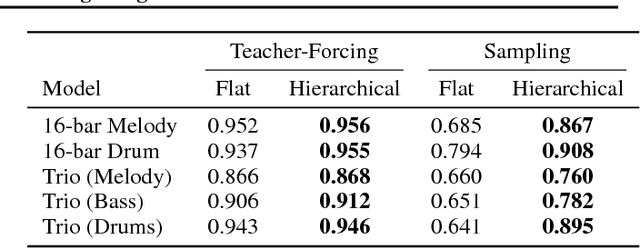
The Variational Autoencoder (VAE) has proven to be an effective model for producing semantically meaningful latent representations for natural data. However, it has thus far seen limited application to sequential data, and, as we demonstrate, existing recurrent VAE models have difficulty modeling sequences with long-term structure. To address this issue, we propose the use of a hierarchical decoder, which first outputs embeddings for subsequences of the input and then uses these embeddings to generate each subsequence independently. This structure encourages the model to utilize its latent code, thereby avoiding the "posterior collapse" problem which remains an issue for recurrent VAEs. We apply this architecture to modeling sequences of musical notes and find that it exhibits dramatically better sampling, interpolation, and reconstruction performance than a "flat" baseline model. An implementation of our "MusicVAE" is available online at http://g.co/magenta/musicvae-code.
* ICML Camera Ready Version
Onsets and Frames: Dual-Objective Piano Transcription
Jun 05, 2018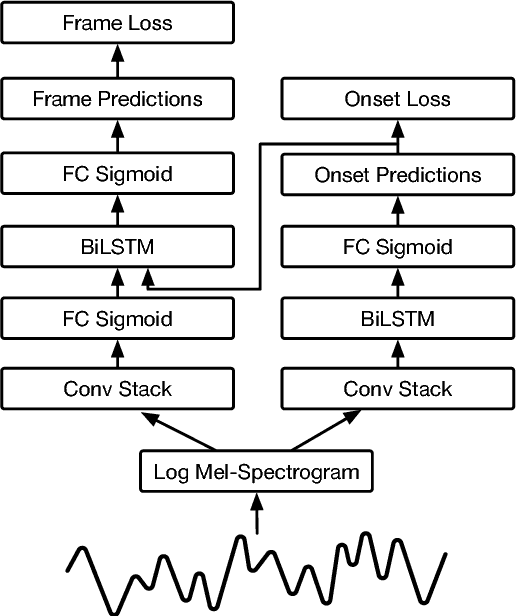

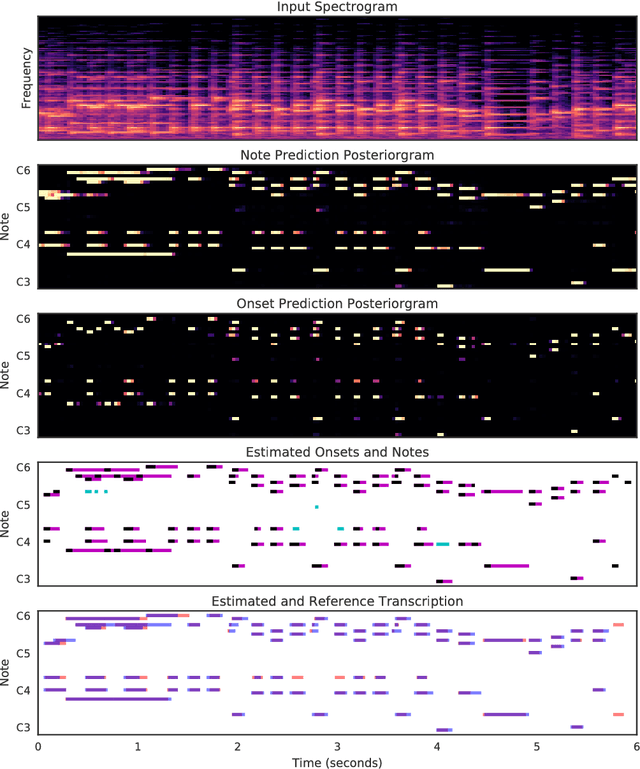
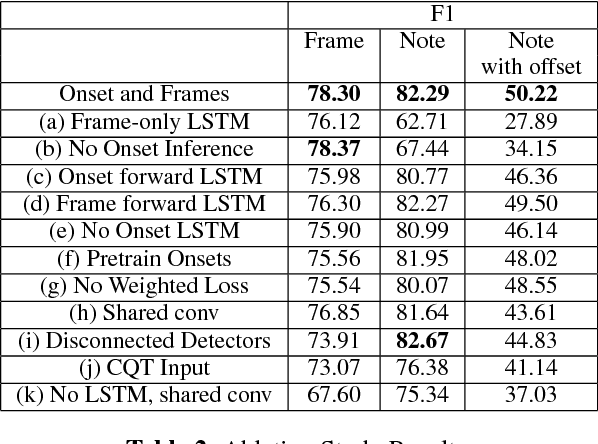
We advance the state of the art in polyphonic piano music transcription by using a deep convolutional and recurrent neural network which is trained to jointly predict onsets and frames. Our model predicts pitch onset events and then uses those predictions to condition framewise pitch predictions. During inference, we restrict the predictions from the framewise detector by not allowing a new note to start unless the onset detector also agrees that an onset for that pitch is present in the frame. We focus on improving onsets and offsets together instead of either in isolation as we believe this correlates better with human musical perception. Our approach results in over a 100% relative improvement in note F1 score (with offsets) on the MAPS dataset. Furthermore, we extend the model to predict relative velocities of normalized audio which results in more natural-sounding transcriptions.
Learning a Latent Space of Multitrack Measures
Jun 01, 2018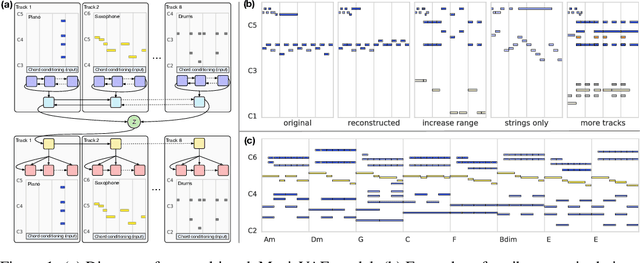
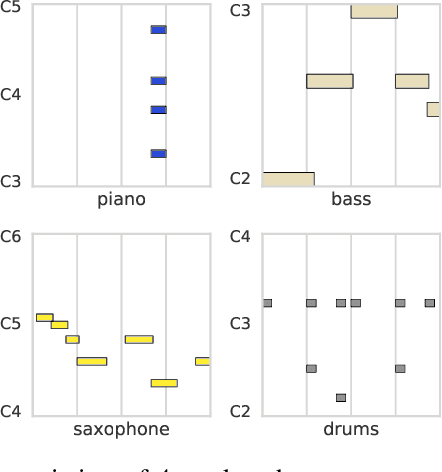
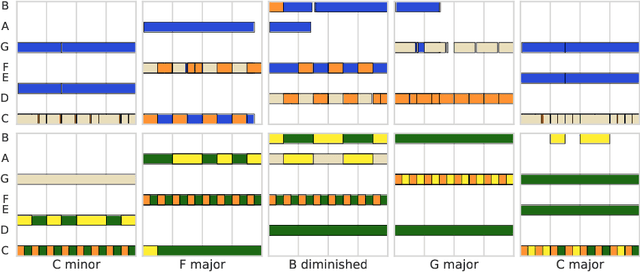
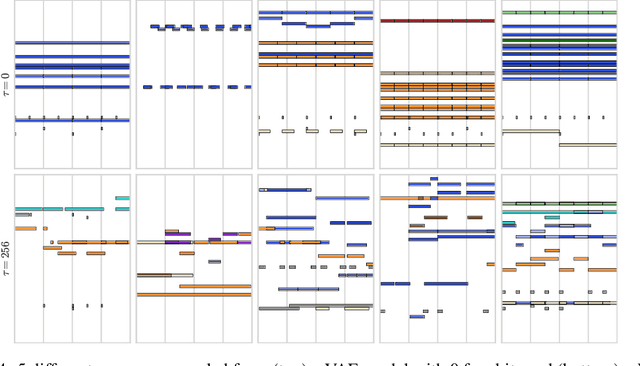
Discovering and exploring the underlying structure of multi-instrumental music using learning-based approaches remains an open problem. We extend the recent MusicVAE model to represent multitrack polyphonic measures as vectors in a latent space. Our approach enables several useful operations such as generating plausible measures from scratch, interpolating between measures in a musically meaningful way, and manipulating specific musical attributes. We also introduce chord conditioning, which allows all of these operations to be performed while keeping harmony fixed, and allows chords to be changed while maintaining musical "style". By generating a sequence of measures over a predefined chord progression, our model can produce music with convincing long-term structure. We demonstrate that our latent space model makes it possible to intuitively control and generate musical sequences with rich instrumentation (see https://goo.gl/s2N7dV for generated audio).
Latent Constraints: Learning to Generate Conditionally from Unconditional Generative Models
Dec 21, 2017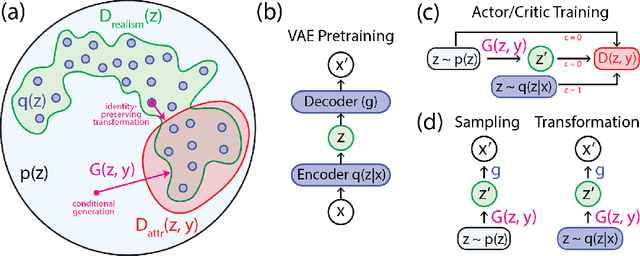
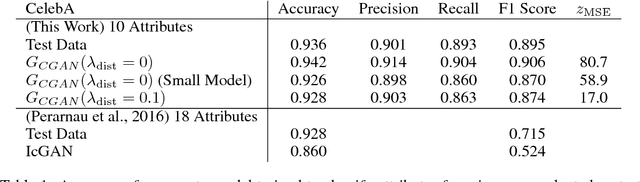

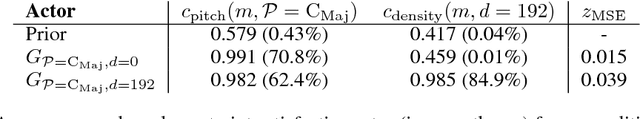
Deep generative neural networks have proven effective at both conditional and unconditional modeling of complex data distributions. Conditional generation enables interactive control, but creating new controls often requires expensive retraining. In this paper, we develop a method to condition generation without retraining the model. By post-hoc learning latent constraints, value functions that identify regions in latent space that generate outputs with desired attributes, we can conditionally sample from these regions with gradient-based optimization or amortized actor functions. Combining attribute constraints with a universal "realism" constraint, which enforces similarity to the data distribution, we generate realistic conditional images from an unconditional variational autoencoder. Further, using gradient-based optimization, we demonstrate identity-preserving transformations that make the minimal adjustment in latent space to modify the attributes of an image. Finally, with discrete sequences of musical notes, we demonstrate zero-shot conditional generation, learning latent constraints in the absence of labeled data or a differentiable reward function. Code with dedicated cloud instance has been made publicly available (https://goo.gl/STGMGx).
Neural Audio Synthesis of Musical Notes with WaveNet Autoencoders
Apr 05, 2017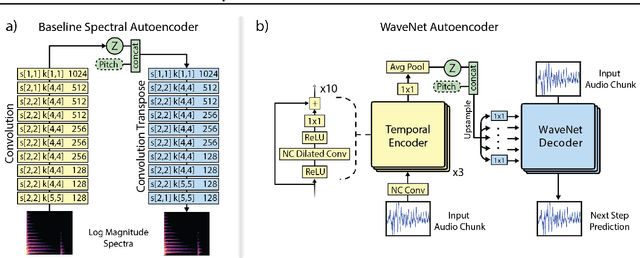
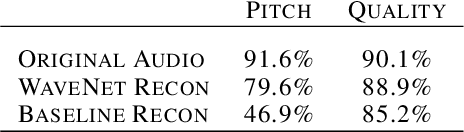

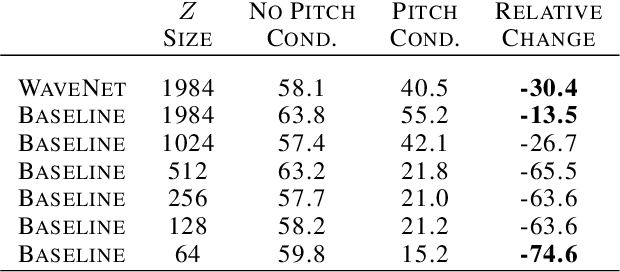
Generative models in vision have seen rapid progress due to algorithmic improvements and the availability of high-quality image datasets. In this paper, we offer contributions in both these areas to enable similar progress in audio modeling. First, we detail a powerful new WaveNet-style autoencoder model that conditions an autoregressive decoder on temporal codes learned from the raw audio waveform. Second, we introduce NSynth, a large-scale and high-quality dataset of musical notes that is an order of magnitude larger than comparable public datasets. Using NSynth, we demonstrate improved qualitative and quantitative performance of the WaveNet autoencoder over a well-tuned spectral autoencoder baseline. Finally, we show that the model learns a manifold of embeddings that allows for morphing between instruments, meaningfully interpolating in timbre to create new types of sounds that are realistic and expressive.
Deep Speech 2: End-to-End Speech Recognition in English and Mandarin
Dec 08, 2015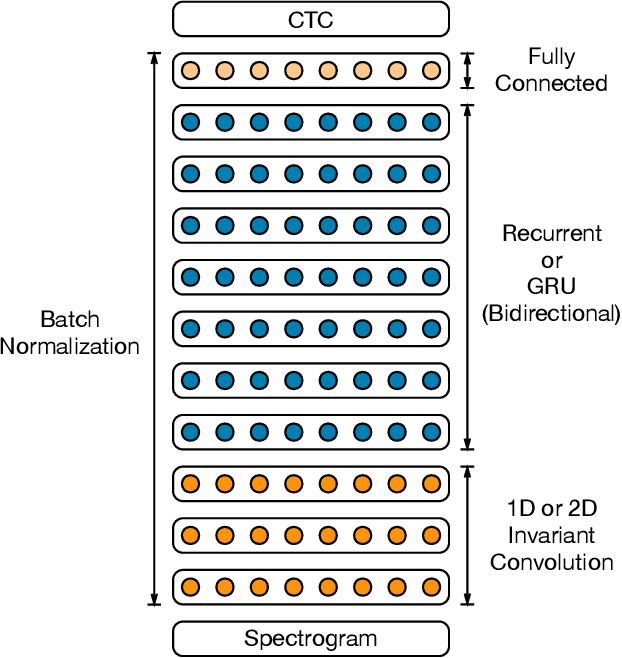
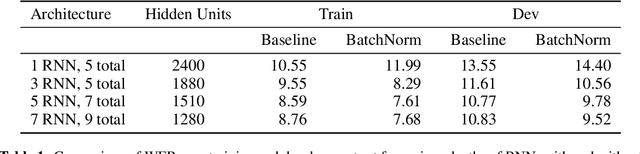
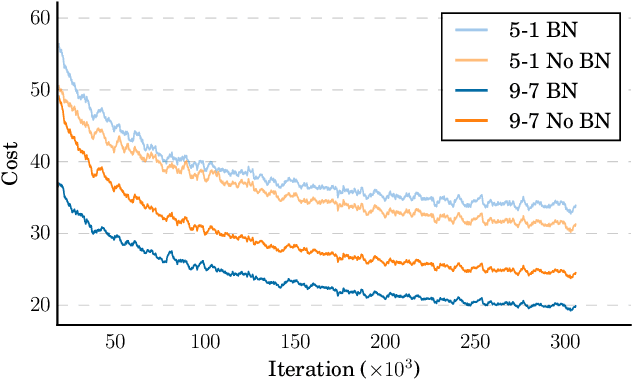
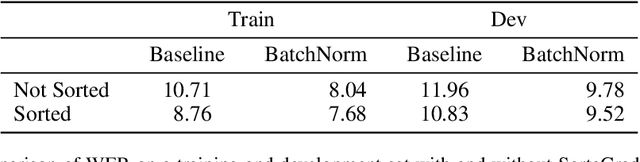
We show that an end-to-end deep learning approach can be used to recognize either English or Mandarin Chinese speech--two vastly different languages. Because it replaces entire pipelines of hand-engineered components with neural networks, end-to-end learning allows us to handle a diverse variety of speech including noisy environments, accents and different languages. Key to our approach is our application of HPC techniques, resulting in a 7x speedup over our previous system. Because of this efficiency, experiments that previously took weeks now run in days. This enables us to iterate more quickly to identify superior architectures and algorithms. As a result, in several cases, our system is competitive with the transcription of human workers when benchmarked on standard datasets. Finally, using a technique called Batch Dispatch with GPUs in the data center, we show that our system can be inexpensively deployed in an online setting, delivering low latency when serving users at scale.