 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeurosymbolic Programming for Science
Oct 10, 2022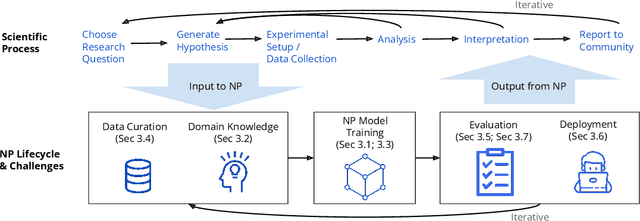
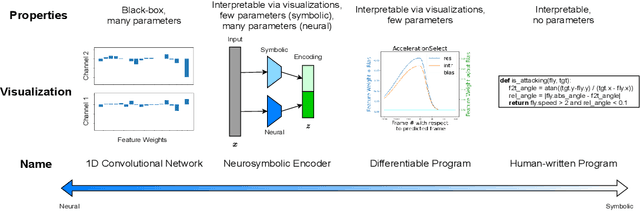
Neurosymbolic Programming (NP) techniques have the potential to accelerate scientific discovery across fields. These models combine neural and symbolic components to learn complex patterns and representations from data, using high-level concepts or known constraints. As a result, NP techniques can interface with symbolic domain knowledge from scientists, such as prior knowledge and experimental context, to produce interpretable outputs. Here, we identify opportunities and challenges between current NP models and scientific workflows, with real-world examples from behavior analysis in science. We define concrete next steps to move the NP for science field forward, to enable its use broadly for workflows across the natural and social sciences.
The MABe22 Benchmarks for Representation Learning of Multi-Agent Behavior
Jul 21, 2022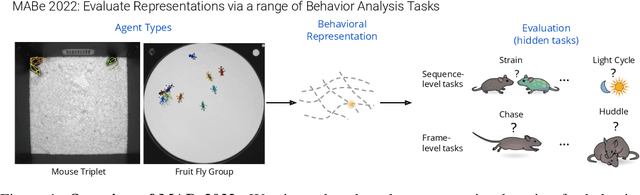
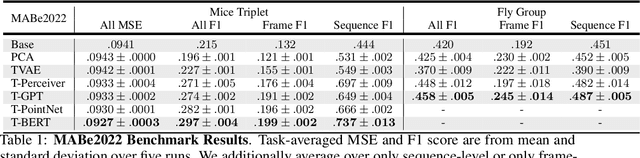
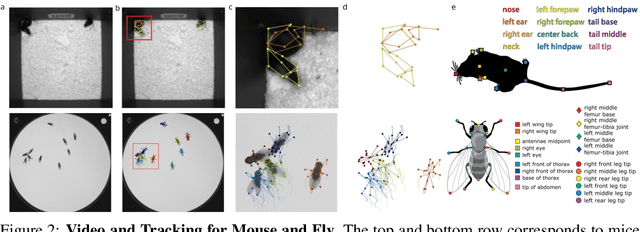
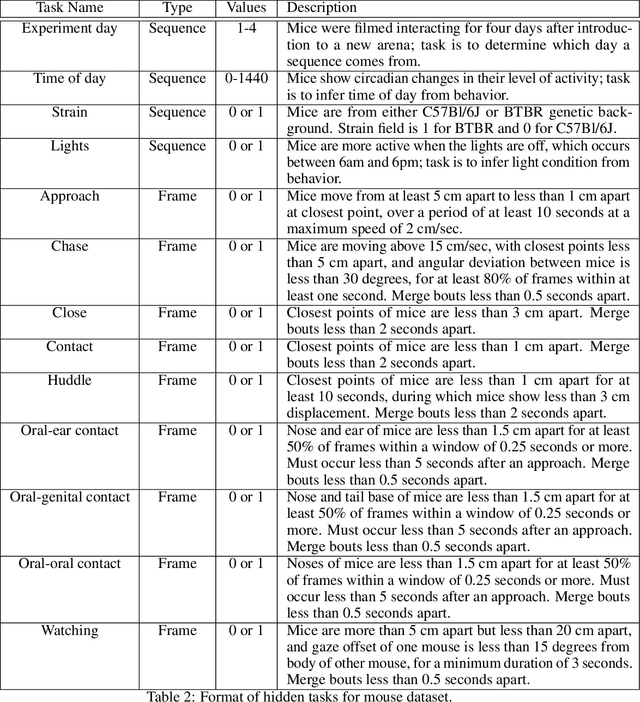
Real-world behavior is often shaped by complex interactions between multiple agents. To scalably study multi-agent behavior, advances in unsupervised and self-supervised learning have enabled a variety of different behavioral representations to be learned from trajectory data. To date, there does not exist a unified set of benchmarks that can enable comparing methods quantitatively and systematically across a broad set of behavior analysis settings. We aim to address this by introducing a large-scale, multi-agent trajectory dataset from real-world behavioral neuroscience experiments that covers a range of behavior analysis tasks. Our dataset consists of trajectory data from common model organisms, with 9.6 million frames of mouse data and 4.4 million frames of fly data, in a variety of experimental settings, such as different strains, lengths of interaction, and optogenetic stimulation. A subset of the frames also consist of expert-annotated behavior labels. Improvements on our dataset corresponds to behavioral representations that work across multiple organisms and is able to capture differences for common behavior analysis tasks.
Deep Neural Imputation: A Framework for Recovering Incomplete Brain Recordings
Jun 16, 2022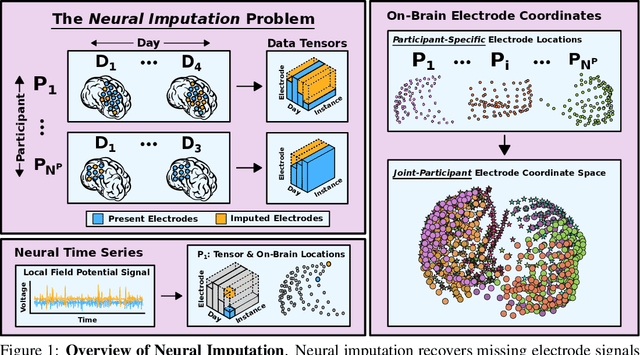
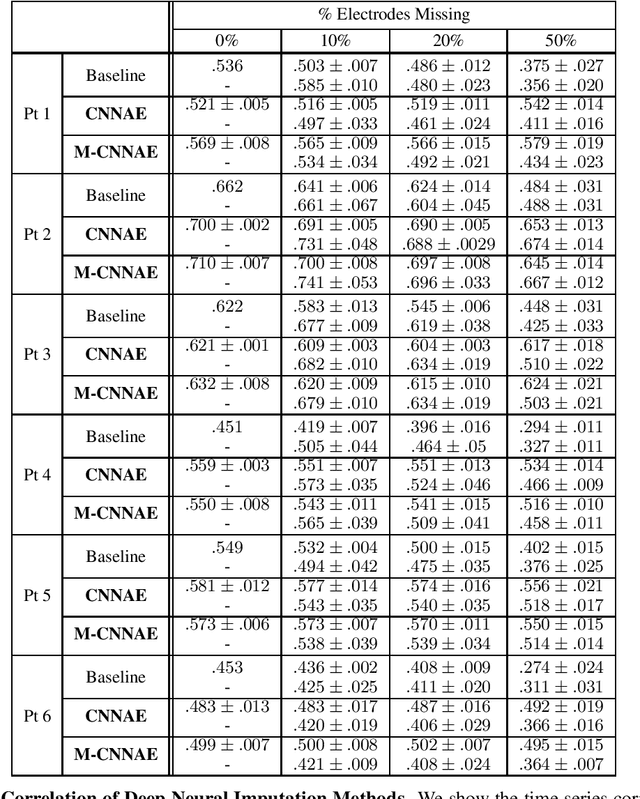
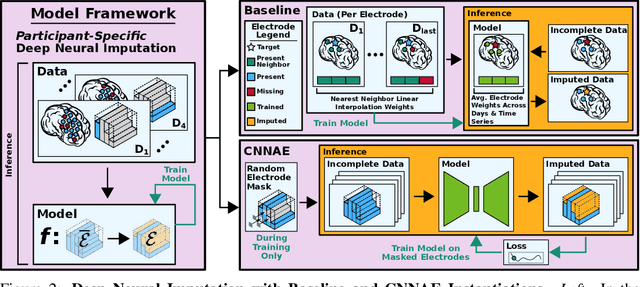
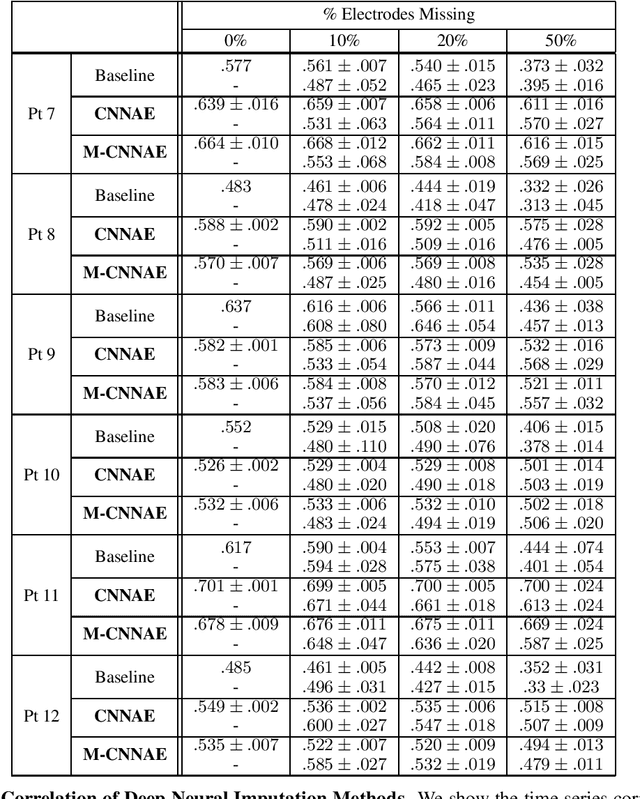
Neuroscientists and neuroengineers have long relied on multielectrode neural recordings to study the brain. However, in a typical experiment, many factors corrupt neural recordings from individual electrodes, including electrical noise, movement artifacts, and faulty manufacturing. Currently, common practice is to discard these corrupted recordings, reducing already limited data that is difficult to collect. To address this challenge, we propose Deep Neural Imputation (DNI), a framework to recover missing values from electrodes by learning from data collected across spatial locations, days, and participants. We explore our framework with a linear nearest-neighbor approach and two deep generative autoencoders, demonstrating DNI's flexibility. One deep autoencoder models participants individually, while the other extends this architecture to model many participants jointly. We evaluate our models across 12 human participants implanted with multielectrode intracranial electrocorticography arrays; participants had no explicit task and behaved naturally across hundreds of recording hours. We show that DNI recovers not only time series but also frequency content, and further establish DNI's practical value by recovering significant performance on a scientifically-relevant downstream neural decoding task.
Open-Source Tools for Behavioral Video Analysis: Setup, Methods, and Development
Apr 06, 2022
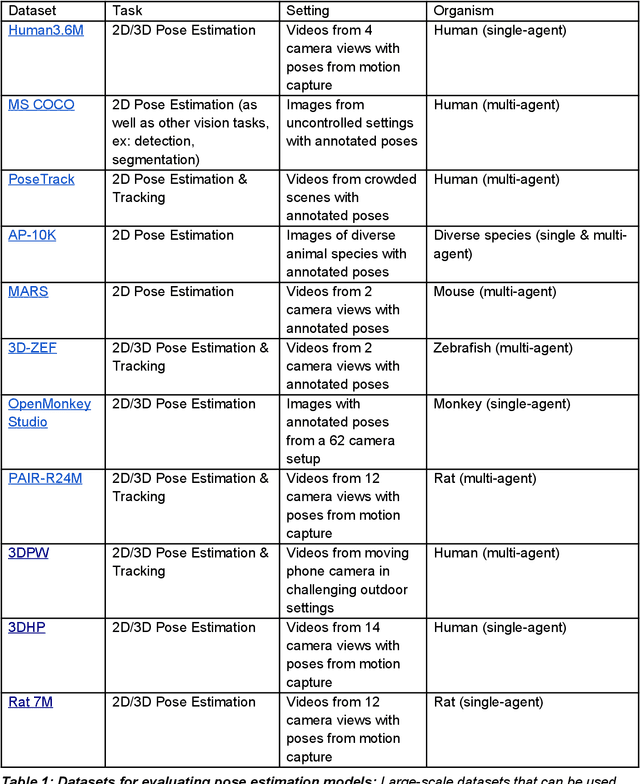
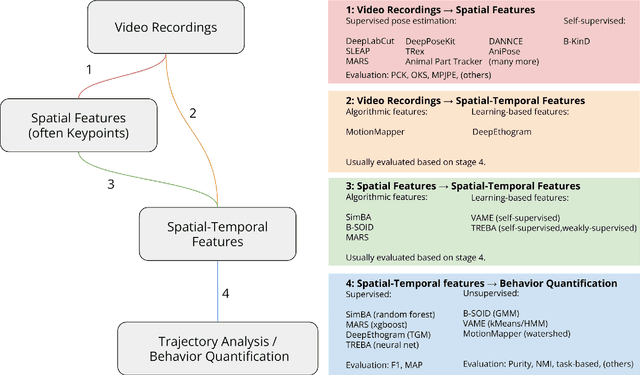
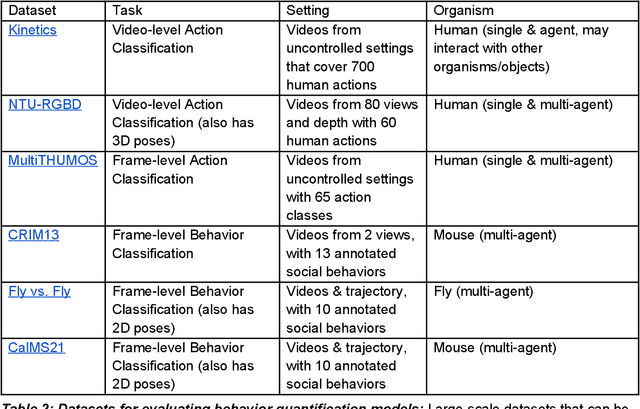
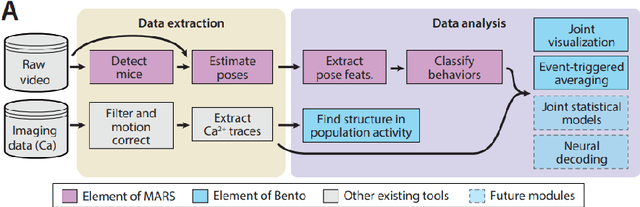
Recently developed methods for video analysis, especially models for pose estimation and behavior classification, are transforming behavioral quantification to be more precise, scalable, and reproducible in fields such as neuroscience and ethology. These tools overcome long-standing limitations of manual scoring of video frames and traditional "center of mass" tracking algorithms to enable video analysis at scale. The expansion of open-source tools for video acquisition and analysis has led to new experimental approaches to understand behavior. Here, we review currently available open source tools for video analysis, how to set them up in a lab that is new to video recording methods, and some issues that should be addressed by developers and advanced users, including the need to openly share datasets and code, how to compare algorithms and their parameters, and the need for documentation and community-wide standards. We hope to encourage more widespread use and continued development of the tools. They have tremendous potential for accelerating scientific progress for understanding the brain and behavior.
Self-Supervised Keypoint Discovery in Behavioral Videos
Dec 09, 2021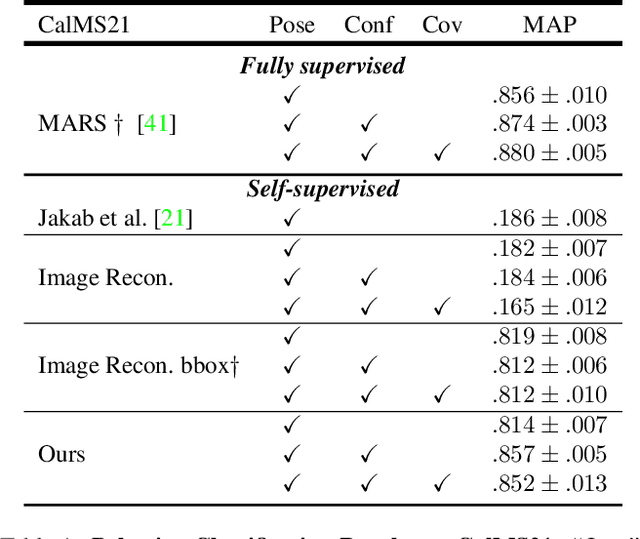
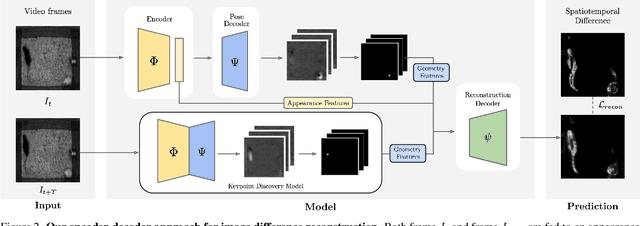

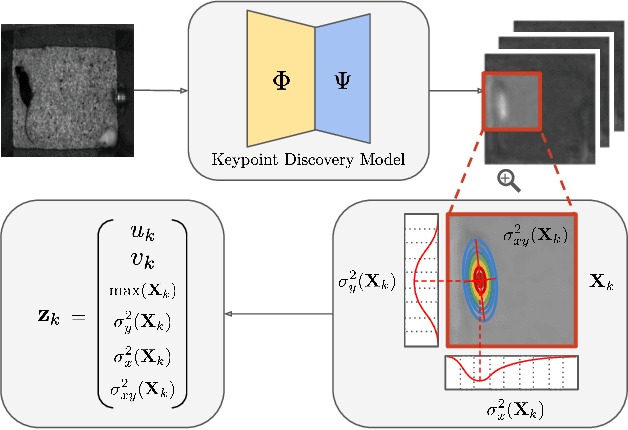
We propose a method for learning the posture and structure of agents from unlabelled behavioral videos. Starting from the observation that behaving agents are generally the main sources of movement in behavioral videos, our method uses an encoder-decoder architecture with a geometric bottleneck to reconstruct the difference between video frames. By focusing only on regions of movement, our approach works directly on input videos without requiring manual annotations, such as keypoints or bounding boxes. Experiments on a variety of agent types (mouse, fly, human, jellyfish, and trees) demonstrate the generality of our approach and reveal that our discovered keypoints represent semantically meaningful body parts, which achieve state-of-the-art performance on keypoint regression among self-supervised methods. Additionally, our discovered keypoints achieve comparable performance to supervised keypoints on downstream tasks, such as behavior classification, suggesting that our method can dramatically reduce the cost of model training vis-a-vis supervised methods.
Automatic Synthesis of Diverse Weak Supervision Sources for Behavior Analysis
Nov 30, 2021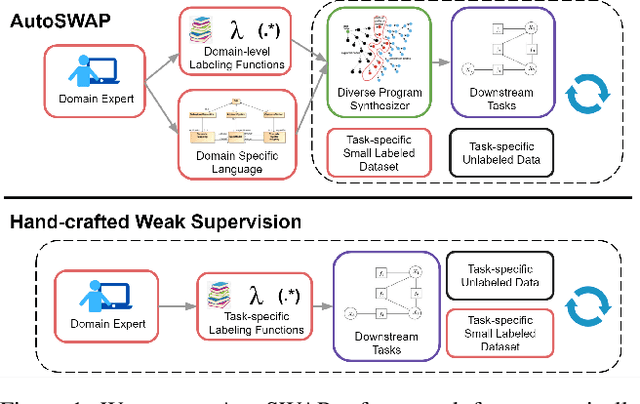



Obtaining annotations for large training sets is expensive, especially in behavior analysis settings where domain knowledge is required for accurate annotations. Weak supervision has been studied to reduce annotation costs by using weak labels from task-level labeling functions to augment ground truth labels. However, domain experts are still needed to hand-craft labeling functions for every studied task. To reduce expert effort, we present AutoSWAP: a framework for automatically synthesizing data-efficient task-level labeling functions. The key to our approach is to efficiently represent expert knowledge in a reusable domain specific language and domain-level labeling functions, with which we use state-of-the-art program synthesis techniques and a small labeled dataset to generate labeling functions. Additionally, we propose a novel structural diversity cost that allows for direct synthesis of diverse sets of labeling functions with minimal overhead, further improving labeling function data efficiency. We evaluate AutoSWAP in three behavior analysis domains and demonstrate that AutoSWAP outperforms existing approaches using only a fraction of the data. Our results suggest that AutoSWAP is an effective way to automatically generate labeling functions that can significantly reduce expert effort for behavior analysis.
Unsupervised Learning of Neurosymbolic Encoders
Jul 28, 2021

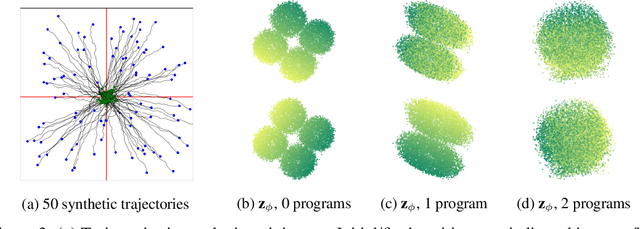
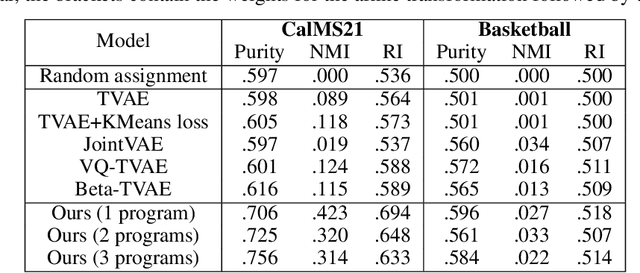
We present a framework for the unsupervised learning of neurosymbolic encoders, i.e., encoders obtained by composing neural networks with symbolic programs from a domain-specific language. Such a framework can naturally incorporate symbolic expert knowledge into the learning process and lead to more interpretable and factorized latent representations than fully neural encoders. Also, models learned this way can have downstream impact, as many analysis workflows can benefit from having clean programmatic descriptions. We ground our learning algorithm in the variational autoencoding (VAE) framework, where we aim to learn a neurosymbolic encoder in conjunction with a standard decoder. Our algorithm integrates standard VAE-style training with modern program synthesis techniques. We evaluate our method on learning latent representations for real-world trajectory data from animal biology and sports analytics. We show that our approach offers significantly better separation than standard VAEs and leads to practical gains on downstream tasks.
Interpreting Expert Annotation Differences in Animal Behavior
Jun 11, 2021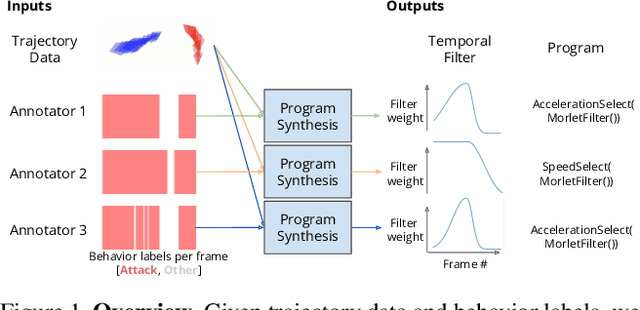
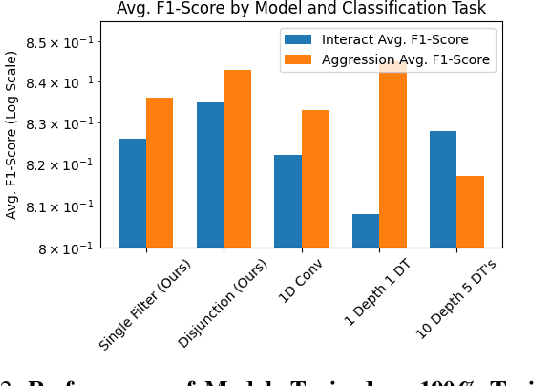
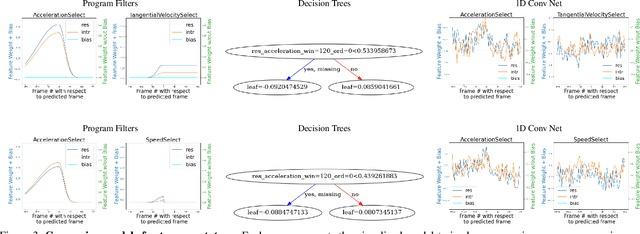
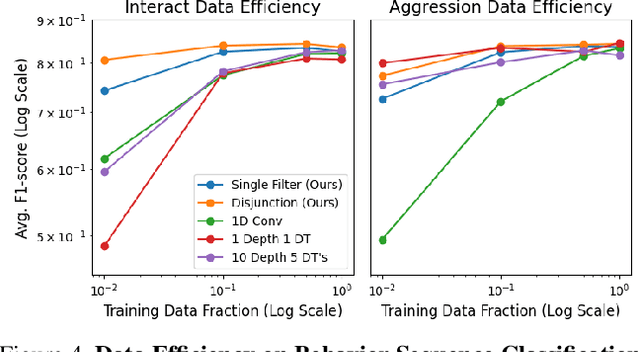
Hand-annotated data can vary due to factors such as subjective differences, intra-rater variability, and differing annotator expertise. We study annotations from different experts who labelled the same behavior classes on a set of animal behavior videos, and observe a variation in annotation styles. We propose a new method using program synthesis to help interpret annotation differences for behavior analysis. Our model selects relevant trajectory features and learns a temporal filter as part of a program, which corresponds to estimated importance an annotator places on that feature at each timestamp. Our experiments on a dataset from behavioral neuroscience demonstrate that compared to baseline approaches, our method is more accurate at capturing annotator labels and learns interpretable temporal filters. We believe that our method can lead to greater reproducibility of behavior annotations used in scientific studies. We plan to release our code.
The Multi-Agent Behavior Dataset: Mouse Dyadic Social Interactions
Apr 07, 2021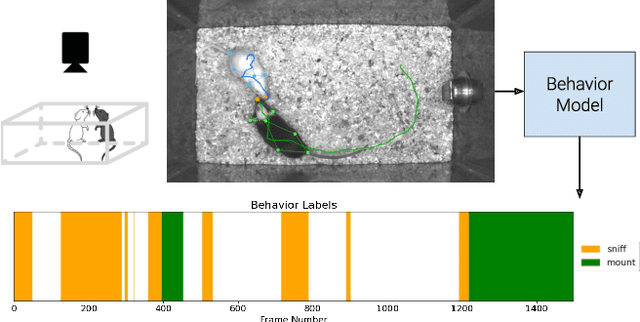
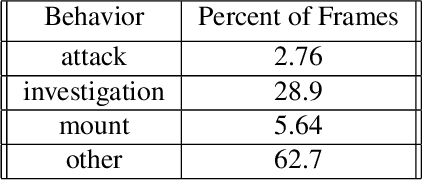
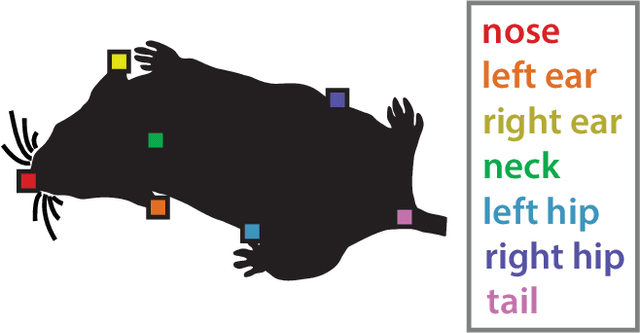
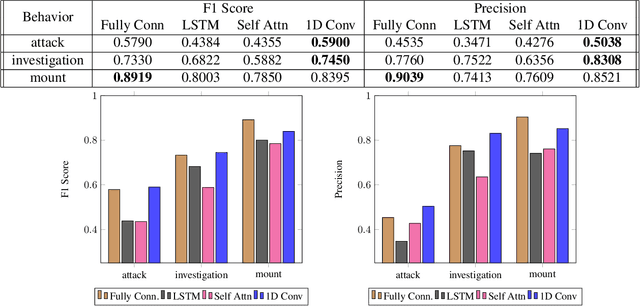
Multi-agent behavior modeling aims to understand the interactions that occur between agents. We present a multi-agent dataset from behavioral neuroscience, the Caltech Mouse Social Interactions (CalMS21) Dataset. Our dataset consists of trajectory data of social interactions, recorded from videos of freely behaving mice in a standard resident-intruder assay. The CalMS21 dataset is part of the Multi-Agent Behavior Challenge 2021 and for our next step, our goal is to incorporate datasets from other domains studying multi-agent behavior. To help accelerate behavioral studies, the CalMS21 dataset provides a benchmark to evaluate the performance of automated behavior classification methods in three settings: (1) for training on large behavioral datasets all annotated by a single annotator, (2) for style transfer to learn inter-annotator differences in behavior definitions, and (3) for learning of new behaviors of interest given limited training data. The dataset consists of 6 million frames of unlabelled tracked poses of interacting mice, as well as over 1 million frames with tracked poses and corresponding frame-level behavior annotations. The challenge of our dataset is to be able to classify behaviors accurately using both labelled and unlabelled tracking data, as well as being able to generalize to new annotators and behaviors.
Learning View-Disentangled Human Pose Representation by Contrastive Cross-View Mutual Information Maximization
Dec 02, 2020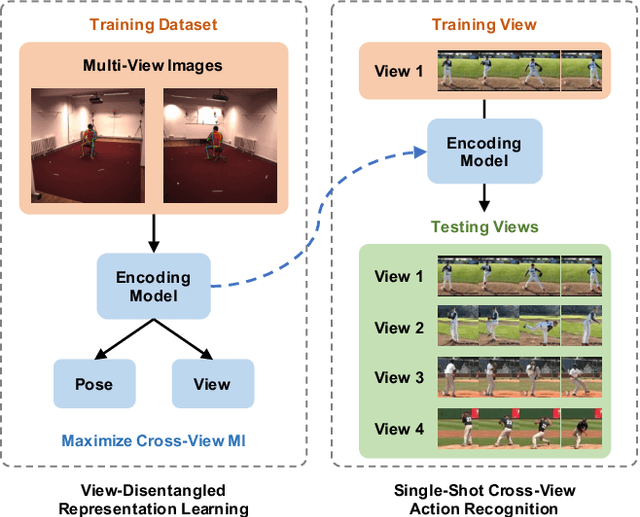
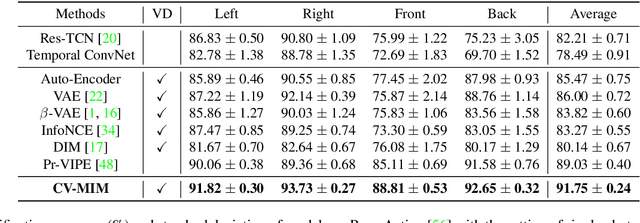
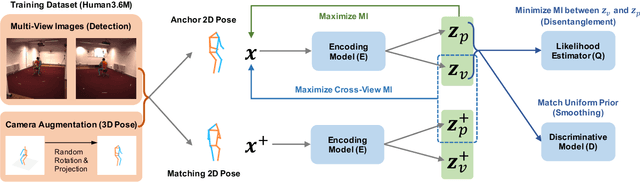
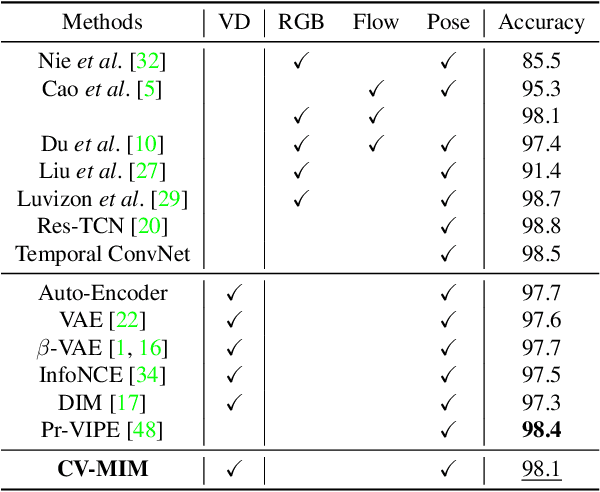
We introduce a novel representation learning method to disentangle pose-dependent as well as view-dependent factors from 2D human poses. The method trains a network using cross-view mutual information maximization (CV-MIM) which maximizes mutual information of the same pose performed from different viewpoints in a contrastive learning manner. We further propose two regularization terms to ensure disentanglement and smoothness of the learned representations. The resulting pose representations can be used for cross-view action recognition. To evaluate the power of the learned representations, in addition to the conventional fully-supervised action recognition settings, we introduce a novel task called single-shot cross-view action recognition. This task trains models with actions from only one single viewpoint while models are evaluated on poses captured from all possible viewpoints. We evaluate the learned representations on standard benchmarks for action recognition, and show that (i) CV-MIM performs competitively compared with the state-of-the-art models in the fully-supervised scenarios; (ii) CV-MIM outperforms other competing methods by a large margin in the single-shot cross-view setting; (iii) and the learned representations can significantly boost the performance when reducing the amount of supervised training data.