 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTD-M(PC)$^2$: Improving Temporal Difference MPC Through Policy Constraint
Feb 05, 2025



Model-based reinforcement learning algorithms that combine model-based planning and learned value/policy prior have gained significant recognition for their high data efficiency and superior performance in continuous control. However, we discover that existing methods that rely on standard SAC-style policy iteration for value learning, directly using data generated by the planner, often result in \emph{persistent value overestimation}. Through theoretical analysis and experiments, we argue that this issue is deeply rooted in the structural policy mismatch between the data generation policy that is always bootstrapped by the planner and the learned policy prior. To mitigate such a mismatch in a minimalist way, we propose a policy regularization term reducing out-of-distribution (OOD) queries, thereby improving value learning. Our method involves minimum changes on top of existing frameworks and requires no additional computation. Extensive experiments demonstrate that the proposed approach improves performance over baselines such as TD-MPC2 by large margins, particularly in 61-DoF humanoid tasks. View qualitative results at https://darthutopian.github.io/tdmpc_square/.
Bayes Adaptive Monte Carlo Tree Search for Offline Model-based Reinforcement Learning
Oct 15, 2024



Offline reinforcement learning (RL) is a powerful approach for data-driven decision-making and control. Compared to model-free methods, offline model-based reinforcement learning (MBRL) explicitly learns world models from a static dataset and uses them as surrogate simulators, improving the data efficiency and enabling the learned policy to potentially generalize beyond the dataset support. However, there could be various MDPs that behave identically on the offline dataset and so dealing with the uncertainty about the true MDP can be challenging. In this paper, we propose modeling offline MBRL as a Bayes Adaptive Markov Decision Process (BAMDP), which is a principled framework for addressing model uncertainty. We further introduce a novel Bayes Adaptive Monte-Carlo planning algorithm capable of solving BAMDPs in continuous state and action spaces with stochastic transitions. This planning process is based on Monte Carlo Tree Search and can be integrated into offline MBRL as a policy improvement operator in policy iteration. Our ``RL + Search" framework follows in the footsteps of superhuman AIs like AlphaZero, improving on current offline MBRL methods by incorporating more computation input. The proposed algorithm significantly outperforms state-of-the-art model-based and model-free offline RL methods on twelve D4RL MuJoCo benchmark tasks and three target tracking tasks in a challenging, stochastic tokamak control simulator.
Decentralized Uncertainty-Aware Active Search with a Team of Aerial Robots
Oct 11, 2024Rapid search and rescue is critical to maximizing survival rates following natural disasters. However, these efforts are challenged by the need to search large disaster zones, lack of reliability in the communications infrastructure, and a priori unknown numbers of objects of interest (OOIs), such as injured survivors. Aerial robots are increasingly being deployed for search and rescue due to their high mobility, but there remains a gap in deploying multi-robot autonomous aerial systems for methodical search of large environments. Prior works have relied on preprogrammed paths from human operators or are evaluated only in simulation. We bridge these gaps in the state of the art by developing and demonstrating a decentralized active search system, which biases its trajectories to take additional views of uncertain OOIs. The methodology leverages stochasticity for rapid coverage in communication denied scenarios. When communications are available, robots share poses, goals, and OOI information to accelerate the rate of search. Extensive simulations and hardware experiments in Bloomingdale, OH, are conducted to validate the approach. The results demonstrate the active search approach outperforms greedy coverage-based planning in communication-denied scenarios while maintaining comparable performance in communication-enabled scenarios.
Measure Preserving Flows for Ergodic Search in Convoluted Environments
Sep 13, 2024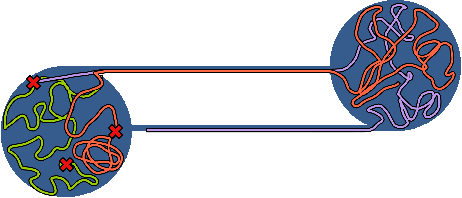
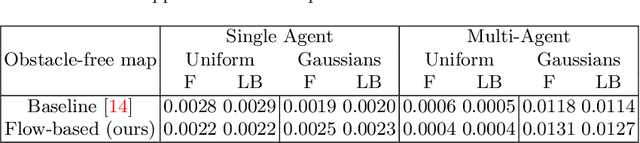
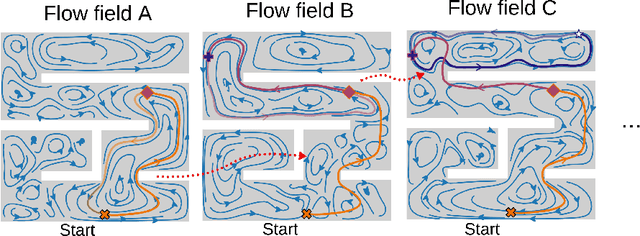
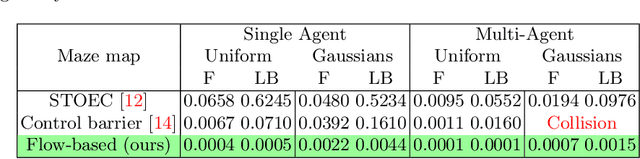
Autonomous robotic search has important applications in robotics, such as the search for signs of life after a disaster. When \emph{a priori} information is available, for example in the form of a distribution, a planner can use that distribution to guide the search. Ergodic search is one method that uses the information distribution to generate a trajectory that minimizes the ergodic metric, in that it encourages the robot to spend more time in regions with high information and proportionally less time in the remaining regions. Unfortunately, prior works in ergodic search do not perform well in complex environments with obstacles such as a building's interior or a maze. To address this, our work presents a modified ergodic metric using the Laplace-Beltrami eigenfunctions to capture map geometry and obstacle locations within the ergodic metric. Further, we introduce an approach to generate trajectories that minimize the ergodic metric while guaranteeing obstacle avoidance using measure-preserving vector fields. Finally, we leverage the divergence-free nature of these vector fields to generate collision-free trajectories for multiple agents. We demonstrate our approach via simulations with single and multi-agent systems on maps representing interior hallways and long corridors with non-uniform information distribution. In particular, we illustrate the generation of feasible trajectories in complex environments where prior methods fail.
Beyond Parameter Count: Implicit Bias in Soft Mixture of Experts
Sep 02, 2024



The traditional viewpoint on Sparse Mixture of Experts (MoE) models is that instead of training a single large expert, which is computationally expensive, we can train many small experts. The hope is that if the total parameter count of the small experts equals that of the singular large expert, then we retain the representation power of the large expert while gaining computational tractability and promoting expert specialization. The recently introduced Soft MoE replaces the Sparse MoE's discrete routing mechanism with a differentiable gating function that smoothly mixes tokens. While this smooth gating function successfully mitigates the various training instabilities associated with Sparse MoE, it is unclear whether it induces implicit biases that affect Soft MoE's representation power or potential for expert specialization. We prove that Soft MoE with a single arbitrarily powerful expert cannot represent simple convex functions. This justifies that Soft MoE's success cannot be explained by the traditional viewpoint of many small experts collectively mimicking the representation power of a single large expert, and that multiple experts are actually necessary to achieve good representation power (even for a fixed total parameter count). Continuing along this line of investigation, we introduce a notion of expert specialization for Soft MoE, and while varying the number of experts yet fixing the total parameter count, we consider the following (computationally intractable) task. Given any input, how can we discover the expert subset that is specialized to predict this input's label? We empirically show that when there are many small experts, the architecture is implicitly biased in a fashion that allows us to efficiently approximate the specialized expert subset. Our method can be easily implemented to potentially reduce computation during inference.
Assigning Credit with Partial Reward Decoupling in Multi-Agent Proximal Policy Optimization
Aug 08, 2024Multi-agent proximal policy optimization (MAPPO) has recently demonstrated state-of-the-art performance on challenging multi-agent reinforcement learning tasks. However, MAPPO still struggles with the credit assignment problem, wherein the sheer difficulty in ascribing credit to individual agents' actions scales poorly with team size. In this paper, we propose a multi-agent reinforcement learning algorithm that adapts recent developments in credit assignment to improve upon MAPPO. Our approach leverages partial reward decoupling (PRD), which uses a learned attention mechanism to estimate which of a particular agent's teammates are relevant to its learning updates. We use this estimate to dynamically decompose large groups of agents into smaller, more manageable subgroups. We empirically demonstrate that our approach, PRD-MAPPO, decouples agents from teammates that do not influence their expected future reward, thereby streamlining credit assignment. We additionally show that PRD-MAPPO yields significantly higher data efficiency and asymptotic performance compared to both MAPPO and other state-of-the-art methods across several multi-agent tasks, including StarCraft II. Finally, we propose a version of PRD-MAPPO that is applicable to \textit{shared} reward settings, where PRD was previously not applicable, and empirically show that this also leads to performance improvements over MAPPO.
Soft-QMIX: Integrating Maximum Entropy For Monotonic Value Function Factorization
Jun 20, 2024



Multi-agent reinforcement learning (MARL) tasks often utilize a centralized training with decentralized execution (CTDE) framework. QMIX is a successful CTDE method that learns a credit assignment function to derive local value functions from a global value function, defining a deterministic local policy. However, QMIX is hindered by its poor exploration strategy. While maximum entropy reinforcement learning (RL) promotes better exploration through stochastic policies, QMIX's process of credit assignment conflicts with the maximum entropy objective and the decentralized execution requirement, making it unsuitable for maximum entropy RL. In this paper, we propose an enhancement to QMIX by incorporating an additional local Q-value learning method within the maximum entropy RL framework. Our approach constrains the local Q-value estimates to maintain the correct ordering of all actions. Due to the monotonicity of the QMIX value function, these updates ensure that locally optimal actions align with globally optimal actions. We theoretically prove the monotonic improvement and convergence of our method to an optimal solution. Experimentally, we validate our algorithm in matrix games, Multi-Agent Particle Environment and demonstrate state-of-the-art performance in SMAC-v2.
Planning with Adaptive World Models for Autonomous Driving
Jun 15, 2024



Motion planning is crucial for safe navigation in complex urban environments. Historically, motion planners (MPs) have been evaluated with procedurally-generated simulators like CARLA. However, such synthetic benchmarks do not capture real-world multi-agent interactions. nuPlan, a recently released MP benchmark, addresses this limitation by augmenting real-world driving logs with closed-loop simulation logic, effectively turning the fixed dataset into a reactive simulator. We analyze the characteristics of nuPlan's recorded logs and find that each city has its own unique driving behaviors, suggesting that robust planners must adapt to different environments. We learn to model such unique behaviors with BehaviorNet, a graph convolutional neural network (GCNN) that predicts reactive agent behaviors using features derived from recently-observed agent histories; intuitively, some aggressive agents may tailgate lead vehicles, while others may not. To model such phenomena, BehaviorNet predicts parameters of an agent's motion controller rather than predicting its spacetime trajectory (as most forecasters do). Finally, we present AdaptiveDriver, a model-predictive control (MPC) based planner that unrolls different world models conditioned on BehaviorNet's predictions. Our extensive experiments demonstrate that AdaptiveDriver achieves state-of-the-art results on the nuPlan closed-loop planning benchmark, reducing test error from 6.4% to 4.6%, even when applied to never-before-seen cities.
What is Your Data Worth to GPT? LLM-Scale Data Valuation with Influence Functions
May 22, 2024



Large language models (LLMs) are trained on a vast amount of human-written data, but data providers often remain uncredited. In response to this issue, data valuation (or data attribution), which quantifies the contribution or value of each data to the model output, has been discussed as a potential solution. Nevertheless, applying existing data valuation methods to recent LLMs and their vast training datasets has been largely limited by prohibitive compute and memory costs. In this work, we focus on influence functions, a popular gradient-based data valuation method, and significantly improve its scalability with an efficient gradient projection strategy called LoGra that leverages the gradient structure in backpropagation. We then provide a theoretical motivation of gradient projection approaches to influence functions to promote trust in the data valuation process. Lastly, we lower the barrier to implementing data valuation systems by introducing LogIX, a software package that can transform existing training code into data valuation code with minimal effort. In our data valuation experiments, LoGra achieves competitive accuracy against more expensive baselines while showing up to 6,500x improvement in throughput and 5x reduction in GPU memory usage when applied to Llama3-8B-Instruct and the 1B-token dataset.
Preference Fine-Tuning of LLMs Should Leverage Suboptimal, On-Policy Data
Apr 23, 2024



Learning from preference labels plays a crucial role in fine-tuning large language models. There are several distinct approaches for preference fine-tuning, including supervised learning, on-policy reinforcement learning (RL), and contrastive learning. Different methods come with different implementation tradeoffs and performance differences, and existing empirical findings present different conclusions, for instance, some results show that online RL is quite important to attain good fine-tuning results, while others find (offline) contrastive or even purely supervised methods sufficient. This raises a natural question: what kind of approaches are important for fine-tuning with preference data and why? In this paper, we answer this question by performing a rigorous analysis of a number of fine-tuning techniques on didactic and full-scale LLM problems. Our main finding is that, in general, approaches that use on-policy sampling or attempt to push down the likelihood on certain responses (i.e., employ a "negative gradient") outperform offline and maximum likelihood objectives. We conceptualize our insights and unify methods that use on-policy sampling or negative gradient under a notion of mode-seeking objectives for categorical distributions. Mode-seeking objectives are able to alter probability mass on specific bins of a categorical distribution at a fast rate compared to maximum likelihood, allowing them to relocate masses across bins more effectively. Our analysis prescribes actionable insights for preference fine-tuning of LLMs and informs how data should be collected for maximal improvement.