 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAugMax: Adversarial Composition of Random Augmentations for Robust Training
Oct 26, 2021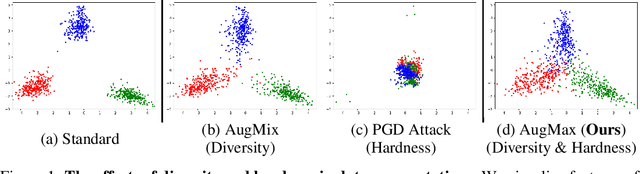
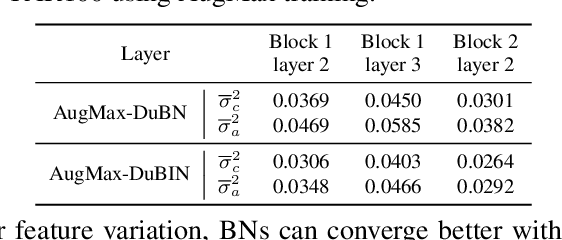
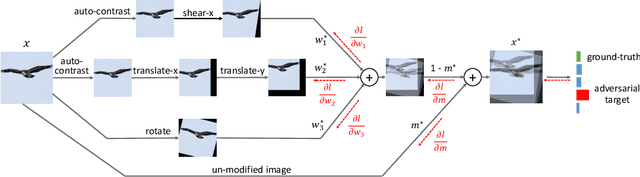
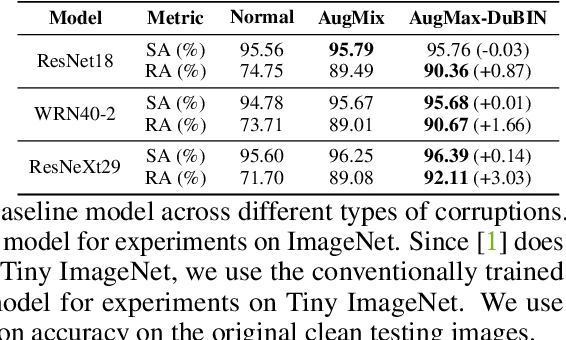
Data augmentation is a simple yet effective way to improve the robustness of deep neural networks (DNNs). Diversity and hardness are two complementary dimensions of data augmentation to achieve robustness. For example, AugMix explores random compositions of a diverse set of augmentations to enhance broader coverage, while adversarial training generates adversarially hard samples to spot the weakness. Motivated by this, we propose a data augmentation framework, termed AugMax, to unify the two aspects of diversity and hardness. AugMax first randomly samples multiple augmentation operators and then learns an adversarial mixture of the selected operators. Being a stronger form of data augmentation, AugMax leads to a significantly augmented input distribution which makes model training more challenging. To solve this problem, we further design a disentangled normalization module, termed DuBIN (Dual-Batch-and-Instance Normalization), that disentangles the instance-wise feature heterogeneity arising from AugMax. Experiments show that AugMax-DuBIN leads to significantly improved out-of-distribution robustness, outperforming prior arts by 3.03%, 3.49%, 1.82% and 0.71% on CIFAR10-C, CIFAR100-C, Tiny ImageNet-C and ImageNet-C. Codes and pretrained models are available: https://github.com/VITA-Group/AugMax.
Tensor Methods in Computer Vision and Deep Learning
Jul 07, 2021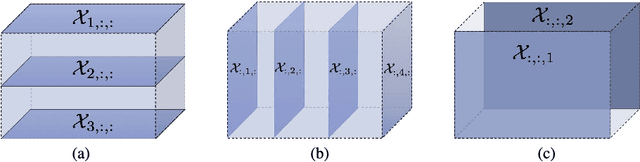
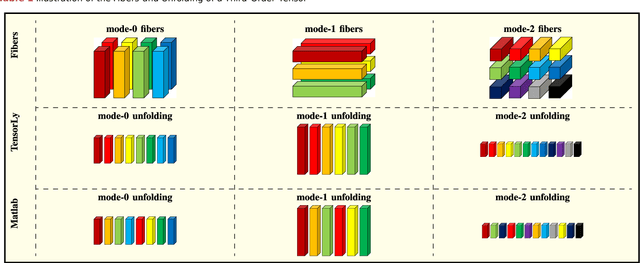
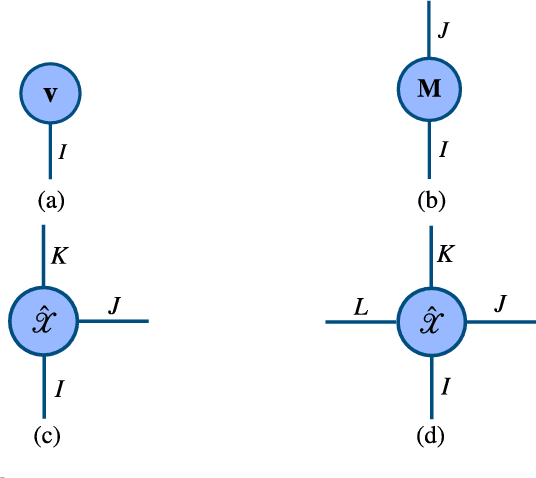
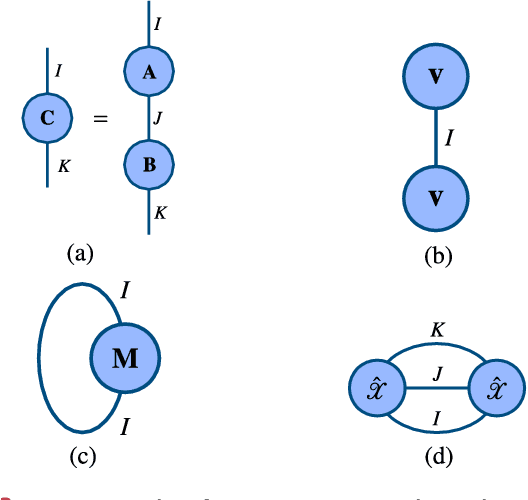
Tensors, or multidimensional arrays, are data structures that can naturally represent visual data of multiple dimensions. Inherently able to efficiently capture structured, latent semantic spaces and high-order interactions, tensors have a long history of applications in a wide span of computer vision problems. With the advent of the deep learning paradigm shift in computer vision, tensors have become even more fundamental. Indeed, essential ingredients in modern deep learning architectures, such as convolutions and attention mechanisms, can readily be considered as tensor mappings. In effect, tensor methods are increasingly finding significant applications in deep learning, including the design of memory and compute efficient network architectures, improving robustness to random noise and adversarial attacks, and aiding the theoretical understanding of deep networks. This article provides an in-depth and practical review of tensors and tensor methods in the context of representation learning and deep learning, with a particular focus on visual data analysis and computer vision applications. Concretely, besides fundamental work in tensor-based visual data analysis methods, we focus on recent developments that have brought on a gradual increase of tensor methods, especially in deep learning architectures, and their implications in computer vision applications. To further enable the newcomer to grasp such concepts quickly, we provide companion Python notebooks, covering key aspects of the paper and implementing them, step-by-step with TensorLy.
Tesseract: Tensorised Actors for Multi-Agent Reinforcement Learning
May 31, 2021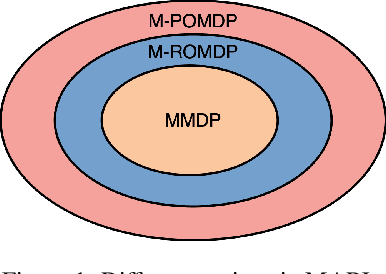
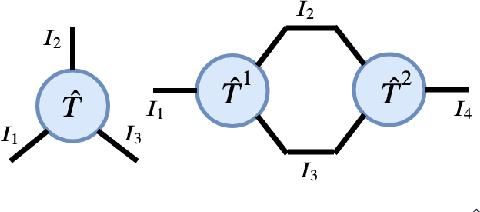
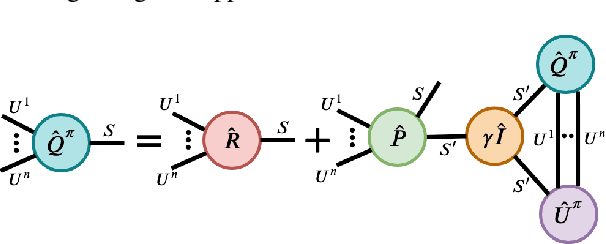
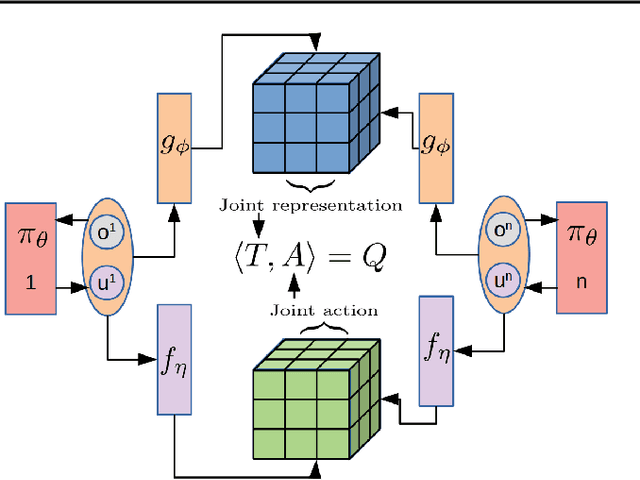
Reinforcement Learning in large action spaces is a challenging problem. Cooperative multi-agent reinforcement learning (MARL) exacerbates matters by imposing various constraints on communication and observability. In this work, we consider the fundamental hurdle affecting both value-based and policy-gradient approaches: an exponential blowup of the action space with the number of agents. For value-based methods, it poses challenges in accurately representing the optimal value function. For policy gradient methods, it makes training the critic difficult and exacerbates the problem of the lagging critic. We show that from a learning theory perspective, both problems can be addressed by accurately representing the associated action-value function with a low-complexity hypothesis class. This requires accurately modelling the agent interactions in a sample efficient way. To this end, we propose a novel tensorised formulation of the Bellman equation. This gives rise to our method Tesseract, which views the Q-function as a tensor whose modes correspond to the action spaces of different agents. Algorithms derived from Tesseract decompose the Q-tensor across agents and utilise low-rank tensor approximations to model agent interactions relevant to the task. We provide PAC analysis for Tesseract-based algorithms and highlight their relevance to the class of rich observation MDPs. Empirical results in different domains confirm Tesseract's gains in sample efficiency predicted by the theory.
Unsupervised Controllable Generation with Self-Training
Jul 17, 2020
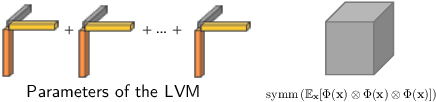

Recent generative adversarial networks (GANs) are able to generate impressive photo-realistic images. However, controllable generation with GANs remains a challenging research problem. Achieving controllable generation requires semantically interpretable and disentangled factors of variation. It is challenging to achieve this goal using simple fixed distributions such as Gaussian distribution. Instead, we propose an unsupervised framework to learn a distribution of latent codes that control the generator through self-training. Self-training provides an iterative feedback in the GAN training, from the discriminator to the generator, and progressively improves the proposal of the latent codes as training proceeds. The latent codes are sampled from a latent variable model that is learned in the feature space of the discriminator. We consider a normalized independent component analysis model and learn its parameters through tensor factorization of the higher-order moments. Our framework exhibits better disentanglement compared to other variants such as the variational autoencoder, and is able to discover semantically meaningful latent codes without any supervision. We demonstrate empirically on both cars and faces datasets that each group of elements in the learned code controls a mode of variation with a semantic meaning, e.g. pose or background change. We also demonstrate with quantitative metrics that our method generates better results compared to other approaches.
Spectral Learning on Matrices and Tensors
Apr 16, 2020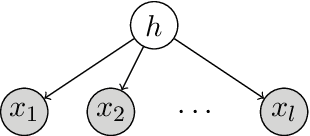
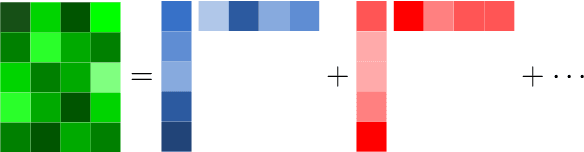

Spectral methods have been the mainstay in several domains such as machine learning and scientific computing. They involve finding a certain kind of spectral decomposition to obtain basis functions that can capture important structures for the problem at hand. The most common spectral method is the principal component analysis (PCA). It utilizes the top eigenvectors of the data covariance matrix, e.g. to carry out dimensionality reduction. This data pre-processing step is often effective in separating signal from noise. PCA and other spectral techniques applied to matrices have several limitations. By limiting to only pairwise moments, they are effectively making a Gaussian approximation on the underlying data and fail on data with hidden variables which lead to non-Gaussianity. However, in most data sets, there are latent effects that cannot be directly observed, e.g., topics in a document corpus, or underlying causes of a disease. By extending the spectral decomposition methods to higher order moments, we demonstrate the ability to learn a wide range of latent variable models efficiently. Higher-order moments can be represented by tensors, and intuitively, they can encode more information than just pairwise moment matrices. More crucially, tensor decomposition can pick up latent effects that are missed by matrix methods, e.g. uniquely identify non-orthogonal components. Exploiting these aspects turns out to be fruitful for provable unsupervised learning of a wide range of latent variable models. We also outline the computational techniques to design efficient tensor decomposition methods. We introduce Tensorly, which has a simple python interface for expressing tensor operations. It has a flexible back-end system supporting NumPy, PyTorch, TensorFlow and MXNet amongst others, allowing multi-GPU and CPU operations and seamless integration with deep-learning functionalities.
Toward fast and accurate human pose estimation via soft-gated skip connections
Feb 25, 2020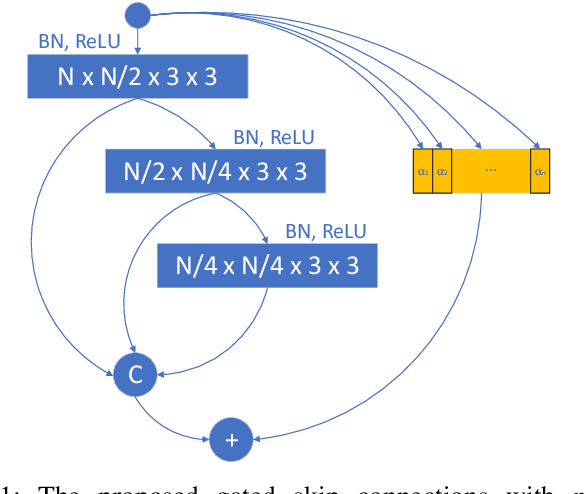
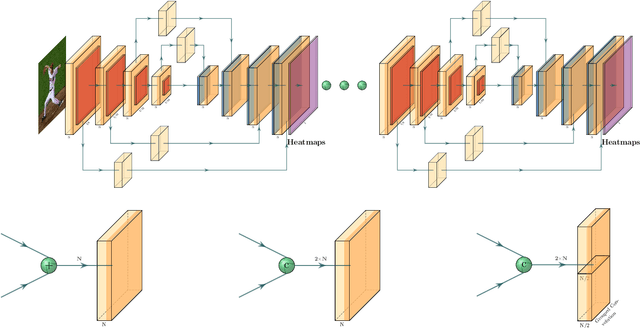

This paper is on highly accurate and highly efficient human pose estimation. Recent works based on Fully Convolutional Networks (FCNs) have demonstrated excellent results for this difficult problem. While residual connections within FCNs have proved to be quintessential for achieving high accuracy, we re-analyze this design choice in the context of improving both the accuracy and the efficiency over the state-of-the-art. In particular, we make the following contributions: (a) We propose gated skip connections with per-channel learnable parameters to control the data flow for each channel within the module within the macro-module. (b) We introduce a hybrid network that combines the HourGlass and U-Net architectures which minimizes the number of identity connections within the network and increases the performance for the same parameter budget. Our model achieves state-of-the-art results on the MPII and LSP datasets. In addition, with a reduction of 3x in model size and complexity, we show no decrease in performance when compared to the original HourGlass network.
Speech-driven facial animation using polynomial fusion of features
Dec 12, 2019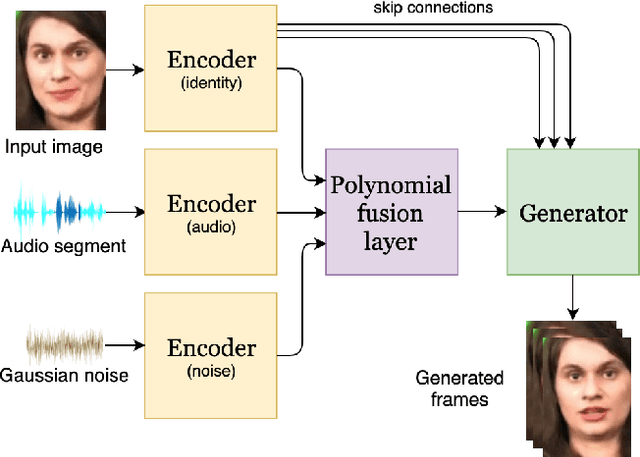
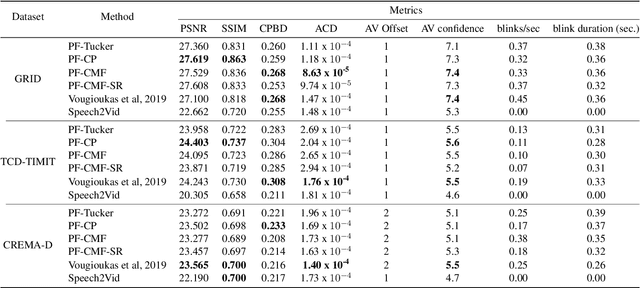
Speech-driven facial animation involves using a speech signal to generate realistic videos of talking faces. Recent deep learning approaches to facial synthesis rely on extracting low-dimensional representations and concatenating them, followed by a decoding step of the concatenated vector. This accounts for only first-order interactions of the features and ignores higher-order interactions. In this paper we propose a polynomial fusion layer that models the joint representation of the encodings by a higher-order polynomial, with the parameters modelled by a tensor decomposition. We demonstrate the the suitability of this approach through experiments on generated videos evaluated on a range of metrics on video quality, audiovisual synchronisation and generation of blinks.
Efficient N-Dimensional Convolutions via Higher-Order Factorization
Jun 14, 2019

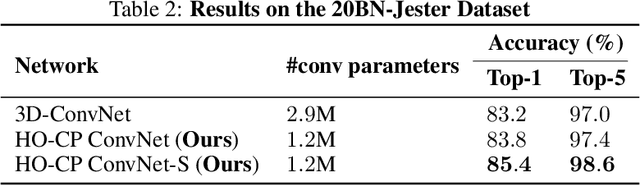
With the unprecedented success of deep convolutional neural networks came the quest for training always deeper networks. However, while deeper neural networks give better performance when trained appropriately, that depth also translates in memory and computation heavy models, typically with tens of millions of parameters. Several methods have been proposed to leverage redundancies in the network to alleviate this complexity. Either a pretrained network is compressed, e.g. using a low-rank tensor decomposition, or the architecture of the network is directly modified to be more effective. In this paper, we study both approaches in a unified framework, under the lens of tensor decompositions. We show how tensor decomposition applied to the convolutional kernel relates to efficient architectures such as MobileNet. Moreover, we propose a tensor-based method for efficient higher order convolutions, which can be used as a plugin replacement for N-dimensional convolutions. We demonstrate their advantageous properties both theoretically and empirically for image classification, for both 2D and 3D convolutional networks.
Matrix and tensor decompositions for training binary neural networks
Apr 16, 2019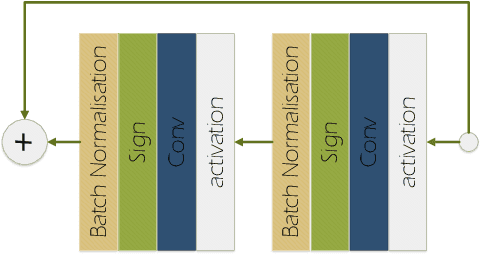
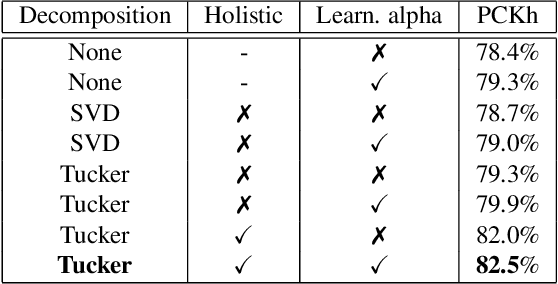
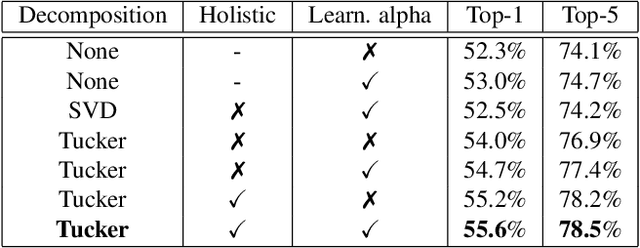
This paper is on improving the training of binary neural networks in which both activations and weights are binary. While prior methods for neural network binarization binarize each filter independently, we propose to instead parametrize the weight tensor of each layer using matrix or tensor decomposition. The binarization process is then performed using this latent parametrization, via a quantization function (e.g. sign function) applied to the reconstructed weights. A key feature of our method is that while the reconstruction is binarized, the computation in the latent factorized space is done in the real domain. This has several advantages: (i) the latent factorization enforces a coupling of the filters before binarization, which significantly improves the accuracy of the trained models. (ii) while at training time, the binary weights of each convolutional layer are parametrized using real-valued matrix or tensor decomposition, during inference we simply use the reconstructed (binary) weights. As a result, our method does not sacrifice any advantage of binary networks in terms of model compression and speeding-up inference. As a further contribution, instead of computing the binary weight scaling factors analytically, as in prior work, we propose to learn them discriminatively via back-propagation. Finally, we show that our approach significantly outperforms existing methods when tested on the challenging tasks of (a) human pose estimation (more than 4% improvements) and (b) ImageNet classification (up to 5% performance gains).
Incremental multi-domain learning with network latent tensor factorization
Apr 12, 2019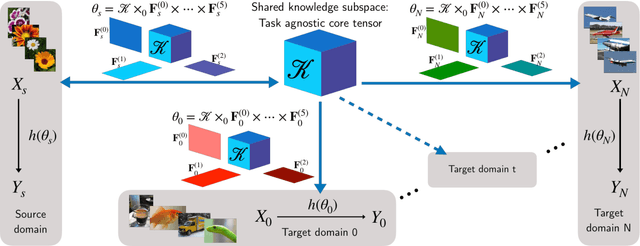
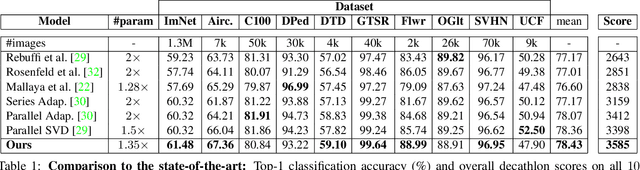

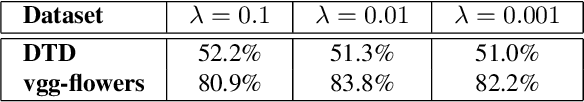
The prominence of deep learning, large amount of annotated data and increasingly powerful hardware made it possible to reach remarkable performance for supervised classification tasks, in many cases saturating the training sets. However, adapting the learned classification to new domains remains a hard problem due to at least three reasons: (1) the domains and the tasks might be drastically different; (2) there might be very limited amount of annotated data on the new domain and (3) full training of a new model for each new task is prohibitive in terms of memory, due to the shear number of parameter of deep networks. Instead, new tasks should be learned incrementally, building on prior knowledge from already learned tasks, and without catastrophic forgetting, i.e. without hurting performance on prior tasks. To our knowledge this paper presents the first method for multi-domain/task learning without catastrophic forgetting using a fully tensorized architecture. Our main contribution is a method for multi-domain learning which models groups of identically structured blocks within a CNN as a high-order tensor. We show that this joint modelling naturally leverages correlations across different layers and results in more compact representations for each new task/domain over previous methods which have focused on adapting each layer separately. We apply the proposed method to 10 datasets of the Visual Decathlon Challenge and show that our method offers on average about 7.5x reduction in number of parameters and superior performance in terms of both classification accuracy and Decathlon score. In particular, our method outperforms all prior work on the Visual Decathlon Challenge.