 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpectral Learning on Matrices and Tensors
Apr 16, 2020

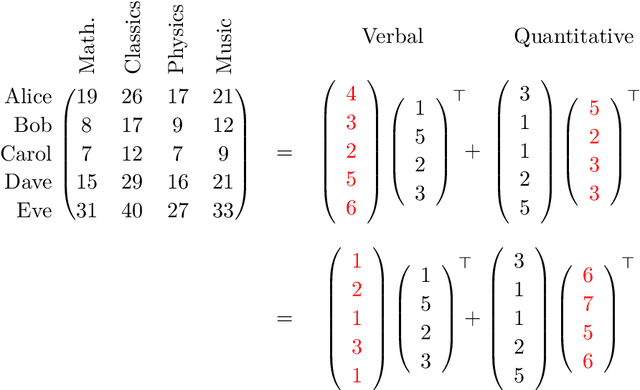
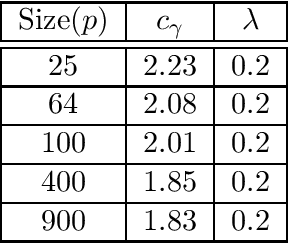
Spectral methods have been the mainstay in several domains such as machine learning and scientific computing. They involve finding a certain kind of spectral decomposition to obtain basis functions that can capture important structures for the problem at hand. The most common spectral method is the principal component analysis (PCA). It utilizes the top eigenvectors of the data covariance matrix, e.g. to carry out dimensionality reduction. This data pre-processing step is often effective in separating signal from noise. PCA and other spectral techniques applied to matrices have several limitations. By limiting to only pairwise moments, they are effectively making a Gaussian approximation on the underlying data and fail on data with hidden variables which lead to non-Gaussianity. However, in most data sets, there are latent effects that cannot be directly observed, e.g., topics in a document corpus, or underlying causes of a disease. By extending the spectral decomposition methods to higher order moments, we demonstrate the ability to learn a wide range of latent variable models efficiently. Higher-order moments can be represented by tensors, and intuitively, they can encode more information than just pairwise moment matrices. More crucially, tensor decomposition can pick up latent effects that are missed by matrix methods, e.g. uniquely identify non-orthogonal components. Exploiting these aspects turns out to be fruitful for provable unsupervised learning of a wide range of latent variable models. We also outline the computational techniques to design efficient tensor decomposition methods. We introduce Tensorly, which has a simple python interface for expressing tensor operations. It has a flexible back-end system supporting NumPy, PyTorch, TensorFlow and MXNet amongst others, allowing multi-GPU and CPU operations and seamless integration with deep-learning functionalities.
Provable Tensor Methods for Learning Mixtures of Generalized Linear Models
Jan 13, 2016We consider the problem of learning mixtures of generalized linear models (GLM) which arise in classification and regression problems. Typical learning approaches such as expectation maximization (EM) or variational Bayes can get stuck in spurious local optima. In contrast, we present a tensor decomposition method which is guaranteed to correctly recover the parameters. The key insight is to employ certain feature transformations of the input, which depend on the input generative model. Specifically, we employ score function tensors of the input and compute their cross-correlation with the response variable. We establish that the decomposition of this tensor consistently recovers the parameters, under mild non-degeneracy conditions. We demonstrate that the computational and sample complexity of our method is a low order polynomial of the input and the latent dimensions.
Beating the Perils of Non-Convexity: Guaranteed Training of Neural Networks using Tensor Methods
Jan 12, 2016

Training neural networks is a challenging non-convex optimization problem, and backpropagation or gradient descent can get stuck in spurious local optima. We propose a novel algorithm based on tensor decomposition for guaranteed training of two-layer neural networks. We provide risk bounds for our proposed method, with a polynomial sample complexity in the relevant parameters, such as input dimension and number of neurons. While learning arbitrary target functions is NP-hard, we provide transparent conditions on the function and the input for learnability. Our training method is based on tensor decomposition, which provably converges to the global optimum, under a set of mild non-degeneracy conditions. It consists of simple embarrassingly parallel linear and multi-linear operations, and is competitive with standard stochastic gradient descent (SGD), in terms of computational complexity. Thus, we propose a computationally efficient method with guaranteed risk bounds for training neural networks with one hidden layer.
Analyzing Tensor Power Method Dynamics in Overcomplete Regime
Sep 14, 2015
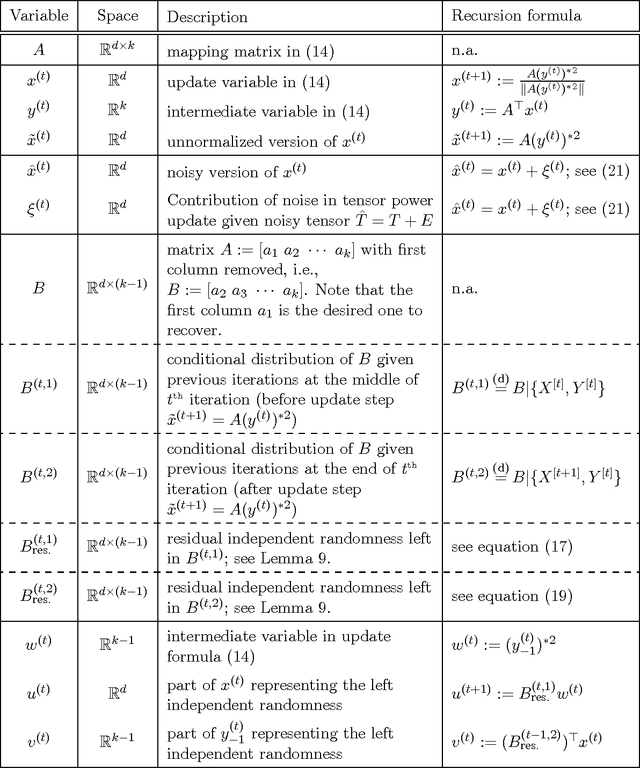
We present a novel analysis of the dynamics of tensor power iterations in the overcomplete regime where the tensor CP rank is larger than the input dimension. Finding the CP decomposition of an overcomplete tensor is NP-hard in general. We consider the case where the tensor components are randomly drawn, and show that the simple power iteration recovers the components with bounded error under mild initialization conditions. We apply our analysis to unsupervised learning of latent variable models, such as multi-view mixture models and spherical Gaussian mixtures. Given the third order moment tensor, we learn the parameters using tensor power iterations. We prove it can correctly learn the model parameters when the number of hidden components $k$ is much larger than the data dimension $d$, up to $k = o(d^{1.5})$. We initialize the power iterations with data samples and prove its success under mild conditions on the signal-to-noise ratio of the samples. Our analysis significantly expands the class of latent variable models where spectral methods are applicable. Our analysis also deals with noise in the input tensor leading to sample complexity result in the application to learning latent variable models.
Score Function Features for Discriminative Learning
Apr 19, 2015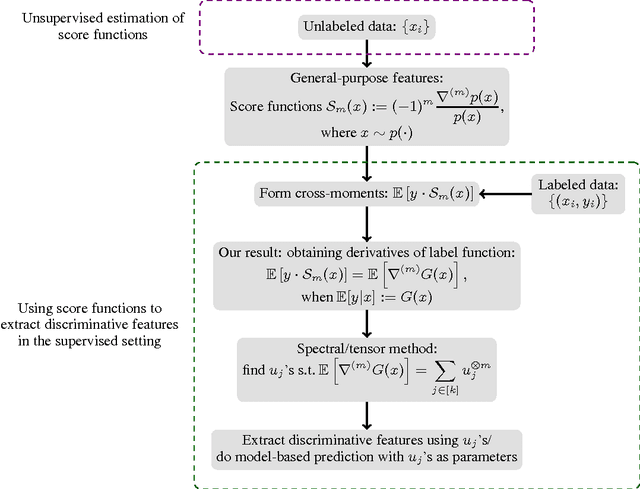
Feature learning forms the cornerstone for tackling challenging learning problems in domains such as speech, computer vision and natural language processing. In this paper, we consider a novel class of matrix and tensor-valued features, which can be pre-trained using unlabeled samples. We present efficient algorithms for extracting discriminative information, given these pre-trained features and labeled samples for any related task. Our class of features are based on higher-order score functions, which capture local variations in the probability density function of the input. We establish a theoretical framework to characterize the nature of discriminative information that can be extracted from score-function features, when used in conjunction with labeled samples. We employ efficient spectral decomposition algorithms (on matrices and tensors) for extracting discriminative components. The advantage of employing tensor-valued features is that we can extract richer discriminative information in the form of an overcomplete representations. Thus, we present a novel framework for employing generative models of the input for discriminative learning.
Guaranteed Non-Orthogonal Tensor Decomposition via Alternating Rank-$1$ Updates
Mar 04, 2015
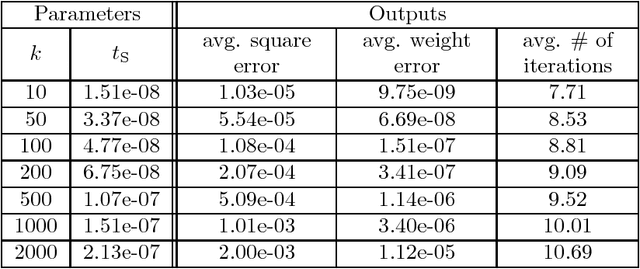
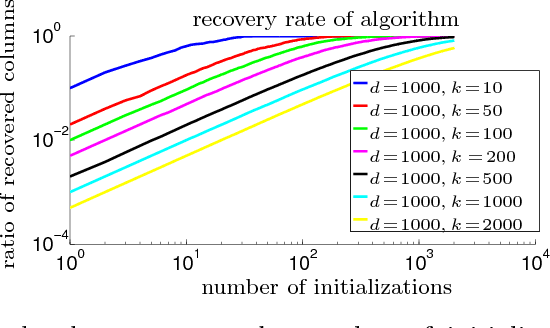
In this paper, we provide local and global convergence guarantees for recovering CP (Candecomp/Parafac) tensor decomposition. The main step of the proposed algorithm is a simple alternating rank-$1$ update which is the alternating version of the tensor power iteration adapted for asymmetric tensors. Local convergence guarantees are established for third order tensors of rank $k$ in $d$ dimensions, when $k=o \bigl( d^{1.5} \bigr)$ and the tensor components are incoherent. Thus, we can recover overcomplete tensor decomposition. We also strengthen the results to global convergence guarantees under stricter rank condition $k \le \beta d$ (for arbitrary constant $\beta > 1$) through a simple initialization procedure where the algorithm is initialized by top singular vectors of random tensor slices. Furthermore, the approximate local convergence guarantees for $p$-th order tensors are also provided under rank condition $k=o \bigl( d^{p/2} \bigr)$. The guarantees also include tight perturbation analysis given noisy tensor.
Sample Complexity Analysis for Learning Overcomplete Latent Variable Models through Tensor Methods
Dec 16, 2014
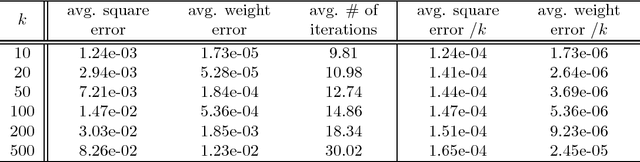
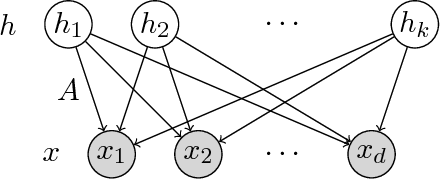
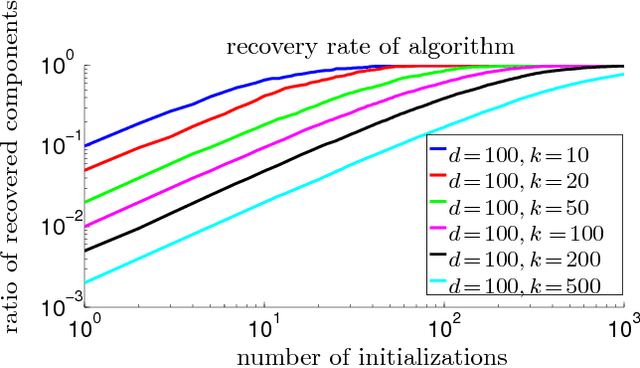
We provide guarantees for learning latent variable models emphasizing on the overcomplete regime, where the dimensionality of the latent space can exceed the observed dimensionality. In particular, we consider multiview mixtures, spherical Gaussian mixtures, ICA, and sparse coding models. We provide tight concentration bounds for empirical moments through novel covering arguments. We analyze parameter recovery through a simple tensor power update algorithm. In the semi-supervised setting, we exploit the label or prior information to get a rough estimate of the model parameters, and then refine it using the tensor method on unlabeled samples. We establish that learning is possible when the number of components scales as $k=o(d^{p/2})$, where $d$ is the observed dimension, and $p$ is the order of the observed moment employed in the tensor method. Our concentration bound analysis also leads to minimax sample complexity for semi-supervised learning of spherical Gaussian mixtures. In the unsupervised setting, we use a simple initialization algorithm based on SVD of the tensor slices, and provide guarantees under the stricter condition that $k\le \beta d$ (where constant $\beta$ can be larger than $1$), where the tensor method recovers the components under a polynomial running time (and exponential in $\beta$). Our analysis establishes that a wide range of overcomplete latent variable models can be learned efficiently with low computational and sample complexity through tensor decomposition methods.
Score Function Features for Discriminative Learning: Matrix and Tensor Framework
Dec 11, 2014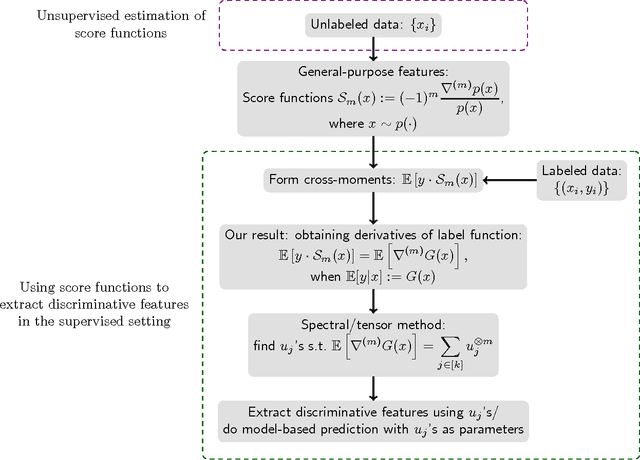
Feature learning forms the cornerstone for tackling challenging learning problems in domains such as speech, computer vision and natural language processing. In this paper, we consider a novel class of matrix and tensor-valued features, which can be pre-trained using unlabeled samples. We present efficient algorithms for extracting discriminative information, given these pre-trained features and labeled samples for any related task. Our class of features are based on higher-order score functions, which capture local variations in the probability density function of the input. We establish a theoretical framework to characterize the nature of discriminative information that can be extracted from score-function features, when used in conjunction with labeled samples. We employ efficient spectral decomposition algorithms (on matrices and tensors) for extracting discriminative components. The advantage of employing tensor-valued features is that we can extract richer discriminative information in the form of an overcomplete representations. Thus, we present a novel framework for employing generative models of the input for discriminative learning.
High-Dimensional Covariance Decomposition into Sparse Markov and Independence Models
Dec 14, 2013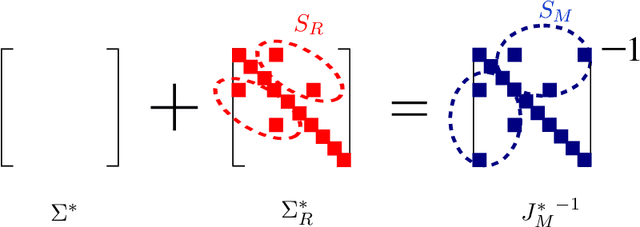
Fitting high-dimensional data involves a delicate tradeoff between faithful representation and the use of sparse models. Too often, sparsity assumptions on the fitted model are too restrictive to provide a faithful representation of the observed data. In this paper, we present a novel framework incorporating sparsity in different domains.We decompose the observed covariance matrix into a sparse Gaussian Markov model (with a sparse precision matrix) and a sparse independence model (with a sparse covariance matrix). Our framework incorporates sparse covariance and sparse precision estimation as special cases and thus introduces a richer class of high-dimensional models. We characterize sufficient conditions for identifiability of the two models, \viz Markov and independence models. We propose an efficient decomposition method based on a modification of the popular $\ell_1$-penalized maximum-likelihood estimator ($\ell_1$-MLE). We establish that our estimator is consistent in both the domains, i.e., it successfully recovers the supports of both Markov and independence models, when the number of samples $n$ scales as $n = \Omega(d^2 \log p)$, where $p$ is the number of variables and $d$ is the maximum node degree in the Markov model. Our experiments validate these results and also demonstrate that our models have better inference accuracy under simple algorithms such as loopy belief propagation.
When are Overcomplete Topic Models Identifiable? Uniqueness of Tensor Tucker Decompositions with Structured Sparsity
Aug 13, 2013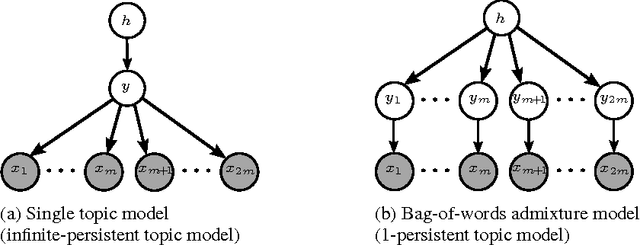
Overcomplete latent representations have been very popular for unsupervised feature learning in recent years. In this paper, we specify which overcomplete models can be identified given observable moments of a certain order. We consider probabilistic admixture or topic models in the overcomplete regime, where the number of latent topics can greatly exceed the size of the observed word vocabulary. While general overcomplete topic models are not identifiable, we establish generic identifiability under a constraint, referred to as topic persistence. Our sufficient conditions for identifiability involve a novel set of "higher order" expansion conditions on the topic-word matrix or the population structure of the model. This set of higher-order expansion conditions allow for overcomplete models, and require the existence of a perfect matching from latent topics to higher order observed words. We establish that random structured topic models are identifiable w.h.p. in the overcomplete regime. Our identifiability results allows for general (non-degenerate) distributions for modeling the topic proportions, and thus, we can handle arbitrarily correlated topics in our framework. Our identifiability results imply uniqueness of a class of tensor decompositions with structured sparsity which is contained in the class of Tucker decompositions, but is more general than the Candecomp/Parafac (CP) decomposition.