 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Reason and Memorize with Self-Notes
May 01, 2023



Large language models have been shown to struggle with limited context memory and multi-step reasoning. We propose a simple method for solving both of these problems by allowing the model to take Self-Notes. Unlike recent scratchpad approaches, the model can deviate from the input context at any time to explicitly think. This allows the model to recall information and perform reasoning on the fly as it reads the context, thus extending its memory and enabling multi-step reasoning. Our experiments on multiple tasks demonstrate that our method can successfully generalize to longer and more complicated instances from their training setup by taking Self-Notes at inference time.
Multi-Party Chat: Conversational Agents in Group Settings with Humans and Models
Apr 26, 2023



Current dialogue research primarily studies pairwise (two-party) conversations, and does not address the everyday setting where more than two speakers converse together. In this work, we both collect and evaluate multi-party conversations to study this more general case. We use the LIGHT environment to construct grounded conversations, where each participant has an assigned character to role-play. We thus evaluate the ability of language models to act as one or more characters in such conversations. Models require two skills that pairwise-trained models appear to lack: (1) being able to decide when to talk; (2) producing coherent utterances grounded on multiple characters. We compare models trained on our new dataset to existing pairwise-trained dialogue models, as well as large language models with few-shot prompting. We find that our new dataset, MultiLIGHT, which we will publicly release, can help bring significant improvements in the group setting.
The Stable Entropy Hypothesis and Entropy-Aware Decoding: An Analysis and Algorithm for Robust Natural Language Generation
Feb 14, 2023



State-of-the-art language generation models can degenerate when applied to open-ended generation problems such as text completion, story generation, or dialog modeling. This degeneration usually shows up in the form of incoherence, lack of vocabulary diversity, and self-repetition or copying from the context. In this paper, we postulate that ``human-like'' generations usually lie in a narrow and nearly flat entropy band, and violation of these entropy bounds correlates with degenerate behavior. Our experiments show that this stable narrow entropy zone exists across models, tasks, and domains and confirm the hypothesis that violations of this zone correlate with degeneration. We then use this insight to propose an entropy-aware decoding algorithm that respects these entropy bounds resulting in less degenerate, more contextual, and "human-like" language generation in open-ended text generation settings.
Infusing Commonsense World Models with Graph Knowledge
Jan 13, 2023While language models have become more capable of producing compelling language, we find there are still gaps in maintaining consistency, especially when describing events in a dynamically changing world. We study the setting of generating narratives in an open world text adventure game, where a graph representation of the underlying game state can be used to train models that consume and output both grounded graph representations and natural language descriptions and actions. We build a large set of tasks by combining crowdsourced and simulated gameplays with a novel dataset of complex actions in order to to construct such models. We find it is possible to improve the consistency of action narration models by training on graph contexts and targets, even if graphs are not present at test time. This is shown both in automatic metrics and human evaluations. We plan to release our code, the new set of tasks, and best performing models.
The CRINGE Loss: Learning what language not to model
Nov 10, 2022Standard language model training employs gold human documents or human-human interaction data, and treats all training data as positive examples. Growing evidence shows that even with very large amounts of positive training data, issues remain that can be alleviated with relatively small amounts of negative data -- examples of what the model should not do. In this work, we propose a novel procedure to train with such data called the CRINGE loss (ContRastive Iterative Negative GEneration). We show the effectiveness of this approach across three different experiments on the tasks of safe generation, contradiction avoidance, and open-domain dialogue. Our models outperform multiple strong baselines and are conceptually simple, easy to train and implement.
When Life Gives You Lemons, Make Cherryade: Converting Feedback from Bad Responses into Good Labels
Oct 28, 2022Deployed dialogue agents have the potential to integrate human feedback to continuously improve themselves. However, humans may not always provide explicit signals when the chatbot makes mistakes during interactions. In this work, we propose Juicer, a framework to make use of both binary and free-form textual human feedback. It works by: (i) extending sparse binary feedback by training a satisfaction classifier to label the unlabeled data; and (ii) training a reply corrector to map the bad replies to good ones. We find that augmenting training with model-corrected replies improves the final dialogue model, and we can further improve performance by using both positive and negative replies through the recently proposed Director model.
Learning New Skills after Deployment: Improving open-domain internet-driven dialogue with human feedback
Aug 16, 2022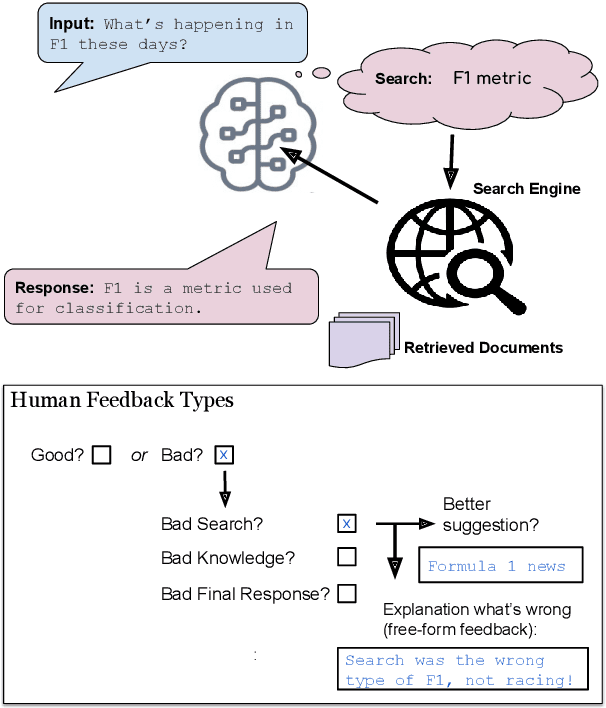
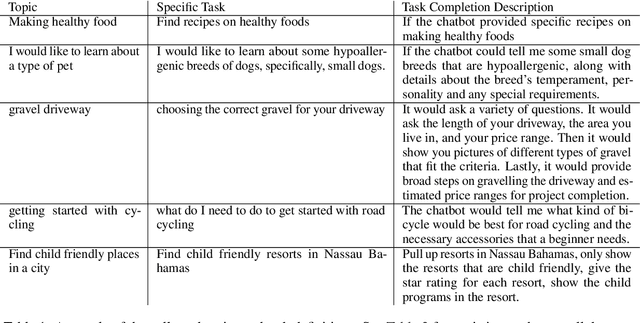
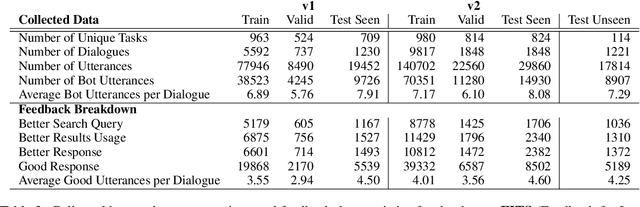
Frozen models trained to mimic static datasets can never improve their performance. Models that can employ internet-retrieval for up-to-date information and obtain feedback from humans during deployment provide the promise of both adapting to new information, and improving their performance. In this work we study how to improve internet-driven conversational skills in such a learning framework. We collect deployment data, which we make publicly available, of human interactions, and collect various types of human feedback -- including binary quality measurements, free-form text feedback, and fine-grained reasons for failure. We then study various algorithms for improving from such feedback, including standard supervised learning, rejection sampling, model-guiding and reward-based learning, in order to make recommendations on which type of feedback and algorithms work best. We find the recently introduced Director model (Arora et al., '22) shows significant improvements over other existing approaches.
BlenderBot 3: a deployed conversational agent that continually learns to responsibly engage
Aug 10, 2022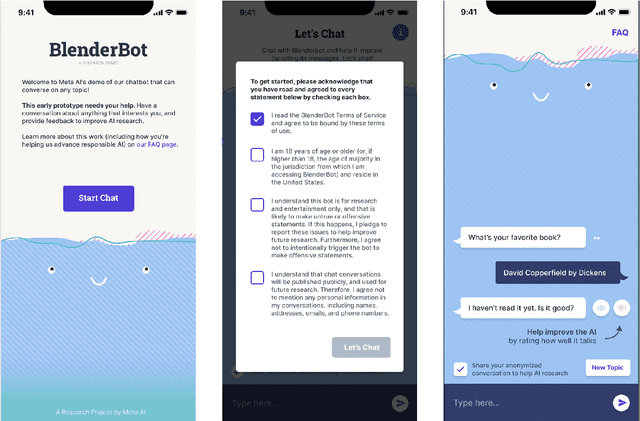
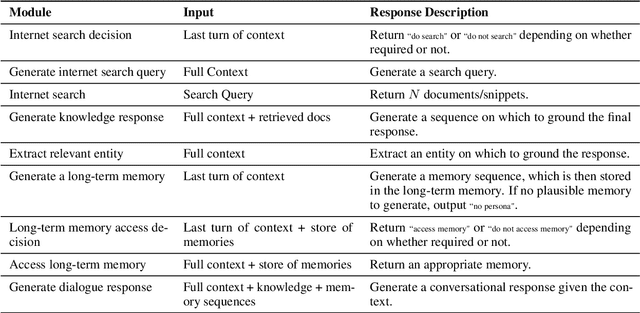
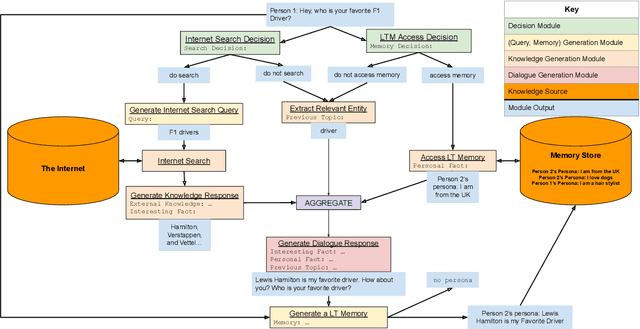
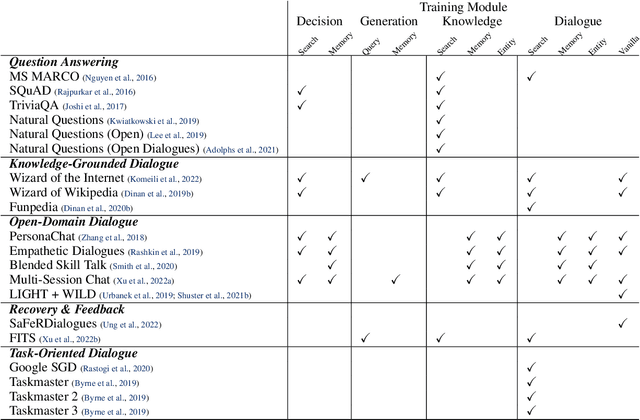
We present BlenderBot 3, a 175B parameter dialogue model capable of open-domain conversation with access to the internet and a long-term memory, and having been trained on a large number of user defined tasks. We release both the model weights and code, and have also deployed the model on a public web page to interact with organic users. This technical report describes how the model was built (architecture, model and training scheme), and details of its deployment, including safety mechanisms. Human evaluations show its superiority to existing open-domain dialogue agents, including its predecessors (Roller et al., 2021; Komeili et al., 2022). Finally, we detail our plan for continual learning using the data collected from deployment, which will also be publicly released. The goal of this research program is thus to enable the community to study ever-improving responsible agents that learn through interaction.
Learning from data in the mixed adversarial non-adversarial case: Finding the helpers and ignoring the trolls
Aug 05, 2022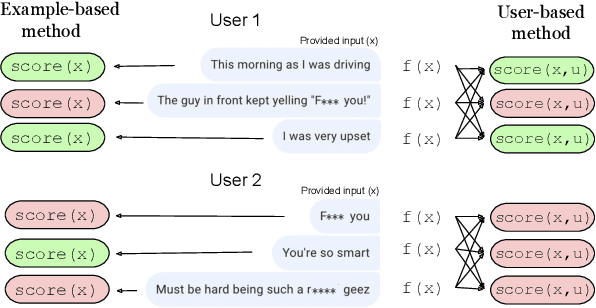
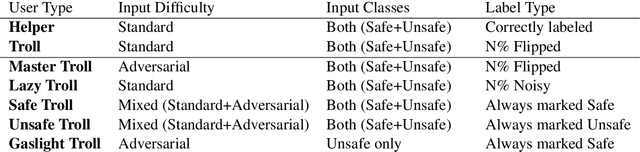
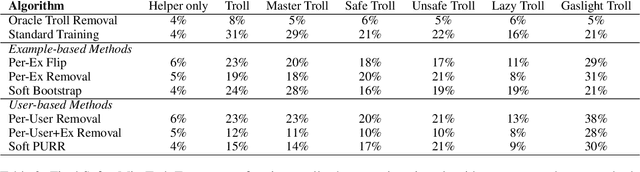
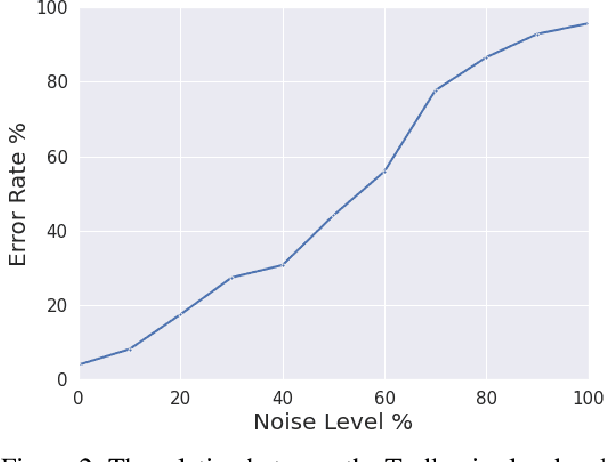
The promise of interaction between intelligent conversational agents and humans is that models can learn from such feedback in order to improve. Unfortunately, such exchanges in the wild will not always involve human utterances that are benign or of high quality, and will include a mixture of engaged (helpers) and unengaged or even malicious users (trolls). In this work we study how to perform robust learning in such an environment. We introduce a benchmark evaluation, SafetyMix, which can evaluate methods that learn safe vs. toxic language in a variety of adversarial settings to test their robustness. We propose and analyze several mitigating learning algorithms that identify trolls either at the example or at the user level. Our main finding is that user-based methods, that take into account that troll users will exhibit adversarial behavior across multiple examples, work best in a variety of settings on our benchmark. We then test these methods in a further real-life setting of conversations collected during deployment, with similar results.
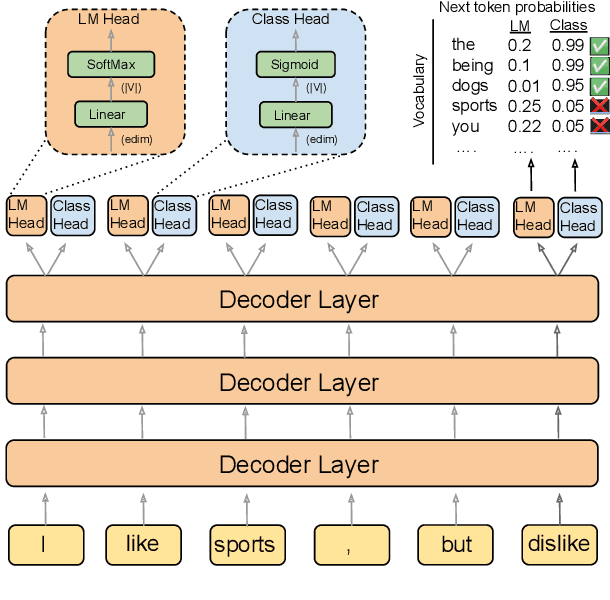
DIRECTOR: Generator-Classifiers For Supervised Language Modeling
Jun 15, 2022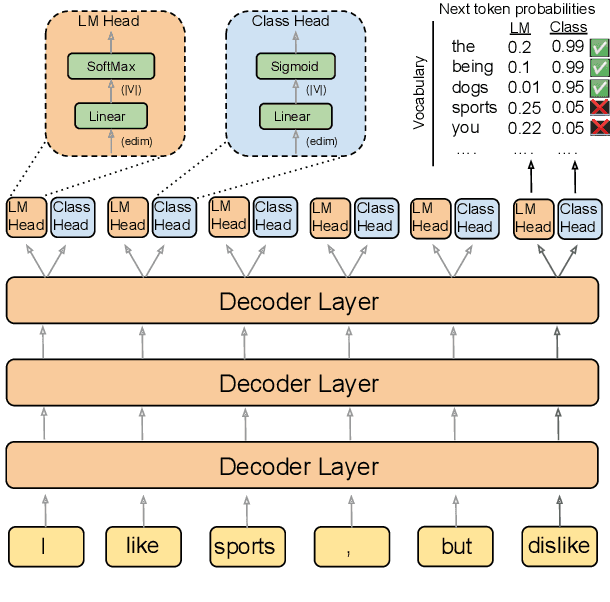
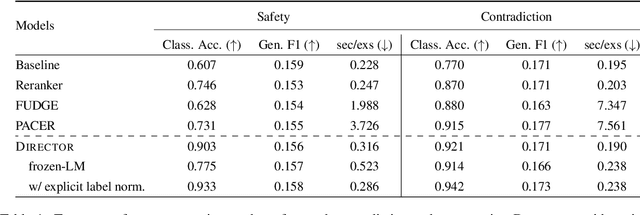
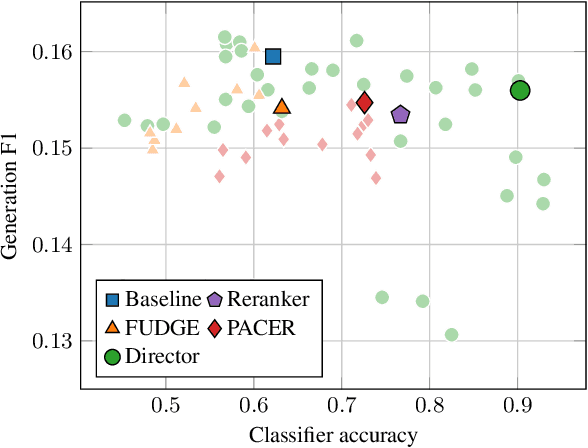
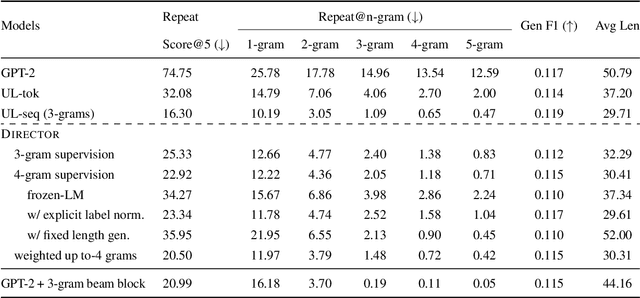
Current language models achieve low perplexity but their resulting generations still suffer from toxic responses, repetitiveness and contradictions. The standard language modeling setup fails to address these issues. In this paper, we introduce a new architecture, {\sc Director}, that consists of a unified generator-classifier with both a language modeling and a classification head for each output token. Training is conducted jointly using both standard language modeling data, and data labeled with desirable and undesirable sequences. Experiments in several settings show that the model has competitive training and decoding speed compared to standard language models while yielding superior results, alleviating known issues while maintaining generation quality. It also outperforms existing model guiding approaches in terms of both accuracy and efficiency.