 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFastNeRF: High-Fidelity Neural Rendering at 200FPS
Apr 15, 2021
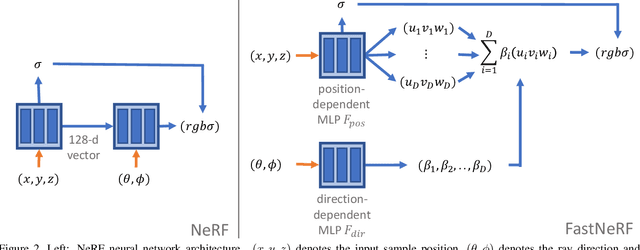
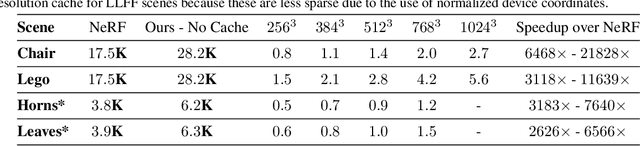
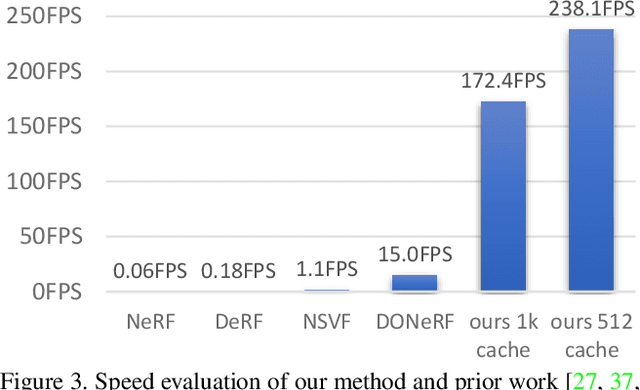
Recent work on Neural Radiance Fields (NeRF) showed how neural networks can be used to encode complex 3D environments that can be rendered photorealistically from novel viewpoints. Rendering these images is very computationally demanding and recent improvements are still a long way from enabling interactive rates, even on high-end hardware. Motivated by scenarios on mobile and mixed reality devices, we propose FastNeRF, the first NeRF-based system capable of rendering high fidelity photorealistic images at 200Hz on a high-end consumer GPU. The core of our method is a graphics-inspired factorization that allows for (i) compactly caching a deep radiance map at each position in space, (ii) efficiently querying that map using ray directions to estimate the pixel values in the rendered image. Extensive experiments show that the proposed method is 3000 times faster than the original NeRF algorithm and at least an order of magnitude faster than existing work on accelerating NeRF, while maintaining visual quality and extensibility.
A high fidelity synthetic face framework for computer vision
Jul 16, 2020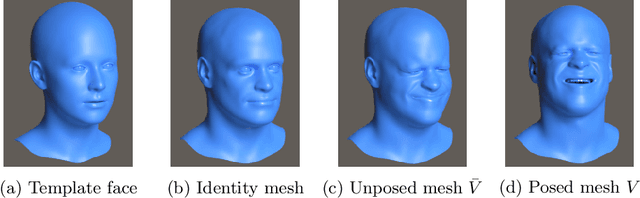

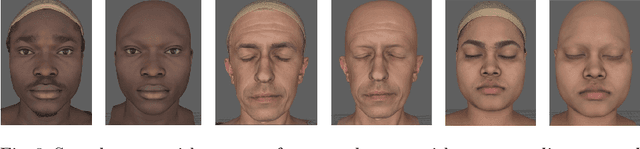

Analysis of faces is one of the core applications of computer vision, with tasks ranging from landmark alignment, head pose estimation, expression recognition, and face recognition among others. However, building reliable methods requires time-consuming data collection and often even more time-consuming manual annotation, which can be unreliable. In our work we propose synthesizing such facial data, including ground truth annotations that would be almost impossible to acquire through manual annotation at the consistency and scale possible through use of synthetic data. We use a parametric face model together with hand crafted assets which enable us to generate training data with unprecedented quality and diversity (varying shape, texture, expression, pose, lighting, and hair).
The Phong Surface: Efficient 3D Model Fitting using Lifted Optimization
Jul 09, 2020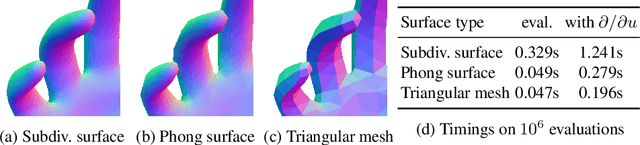
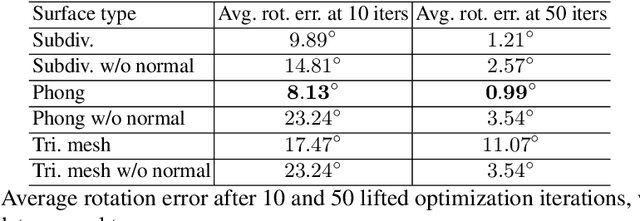
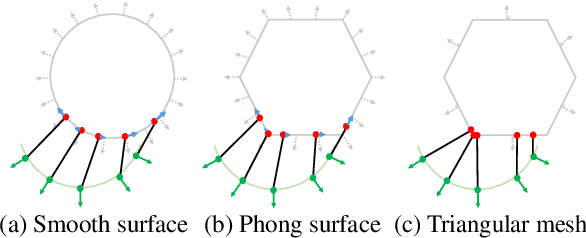
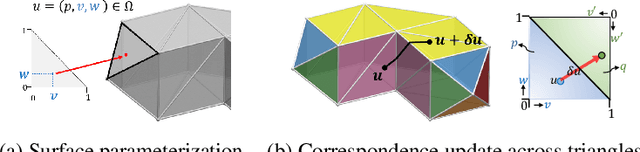
Realtime perceptual and interaction capabilities in mixed reality require a range of 3D tracking problems to be solved at low latency on resource-constrained hardware such as head-mounted devices. Indeed, for devices such as HoloLens 2 where the CPU and GPU are left available for applications, multiple tracking subsystems are required to run on a continuous, real-time basis while sharing a single Digital Signal Processor. To solve model-fitting problems for HoloLens 2 hand tracking, where the computational budget is approximately 100 times smaller than an iPhone 7, we introduce a new surface model: the `Phong surface'. Using ideas from computer graphics, the Phong surface describes the same 3D shape as a triangulated mesh model, but with continuous surface normals which enable the use of lifting-based optimization, providing significant efficiency gains over ICP-based methods. We show that Phong surfaces retain the convergence benefits of smoother surface models, while triangle meshes do not.
High Resolution Zero-Shot Domain Adaptation of Synthetically Rendered Face Images
Jun 26, 2020



Generating photorealistic images of human faces at scale remains a prohibitively difficult task using computer graphics approaches. This is because these require the simulation of light to be photorealistic, which in turn requires physically accurate modelling of geometry, materials, and light sources, for both the head and the surrounding scene. Non-photorealistic renders however are increasingly easy to produce. In contrast to computer graphics approaches, generative models learned from more readily available 2D image data have been shown to produce samples of human faces that are hard to distinguish from real data. The process of learning usually corresponds to a loss of control over the shape and appearance of the generated images. For instance, even simple disentangling tasks such as modifying the hair independently of the face, which is trivial to accomplish in a computer graphics approach, remains an open research question. In this work, we propose an algorithm that matches a non-photorealistic, synthetically generated image to a latent vector of a pretrained StyleGAN2 model which, in turn, maps the vector to a photorealistic image of a person of the same pose, expression, hair, and lighting. In contrast to most previous work, we require no synthetic training data. To the best of our knowledge, this is the first algorithm of its kind to work at a resolution of 1K and represents a significant leap forward in visual realism.
CONFIG: Controllable Neural Face Image Generation
May 12, 2020
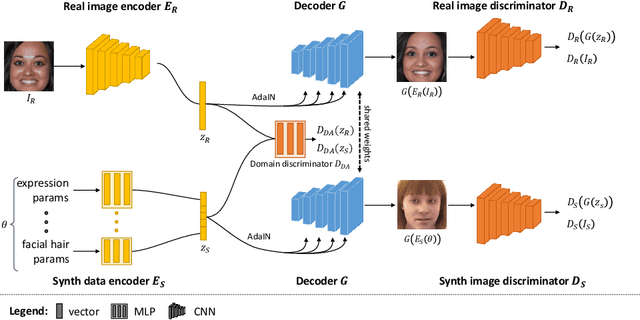


Our ability to sample realistic natural images, particularly faces, has advanced by leaps and bounds in recent years, yet our ability to exert fine-tuned control over the generative process has lagged behind. If this new technology is to find practical uses, we need to achieve a level of control over generative networks which, without sacrificing realism, is on par with that seen in computer graphics and character animation. To this end we propose ConfigNet, a neural face model that allows for controlling individual aspects of output images in semantically meaningful ways and that is a significant step on the path towards finely-controllable neural rendering. ConfigNet is trained on real face images as well as synthetic face renders. Our novel method uses synthetic data to factorize the latent space into elements that correspond to the inputs of a traditional rendering pipeline, separating aspects such as head pose, facial expression, hair style, illumination, and many others which are very hard to annotate in real data. The real images, which are presented to the network without labels, extend the variety of the generated images and encourage realism. Finally, we propose an evaluation criterion using an attribute detection network combined with a user study and demonstrate state-of-the-art individual control over attributes in the output images.
DSAC - Differentiable RANSAC for Camera Localization
Mar 21, 2018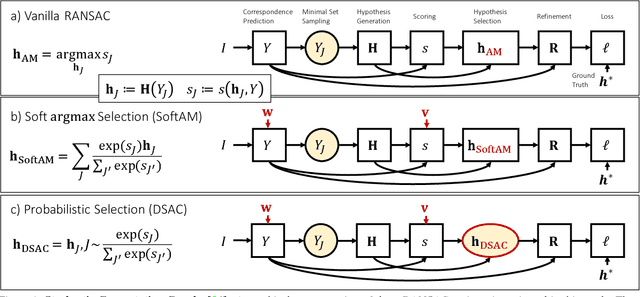
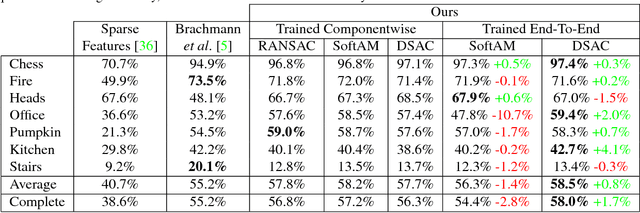

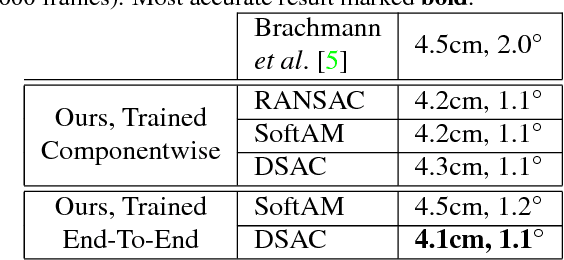
RANSAC is an important algorithm in robust optimization and a central building block for many computer vision applications. In recent years, traditionally hand-crafted pipelines have been replaced by deep learning pipelines, which can be trained in an end-to-end fashion. However, RANSAC has so far not been used as part of such deep learning pipelines, because its hypothesis selection procedure is non-differentiable. In this work, we present two different ways to overcome this limitation. The most promising approach is inspired by reinforcement learning, namely to replace the deterministic hypothesis selection by a probabilistic selection for which we can derive the expected loss w.r.t. to all learnable parameters. We call this approach DSAC, the differentiable counterpart of RANSAC. We apply DSAC to the problem of camera localization, where deep learning has so far failed to improve on traditional approaches. We demonstrate that by directly minimizing the expected loss of the output camera poses, robustly estimated by RANSAC, we achieve an increase in accuracy. In the future, any deep learning pipeline can use DSAC as a robust optimization component.
PoseAgent: Budget-Constrained 6D Object Pose Estimation via Reinforcement Learning
Apr 11, 2017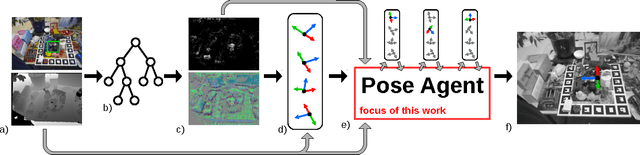
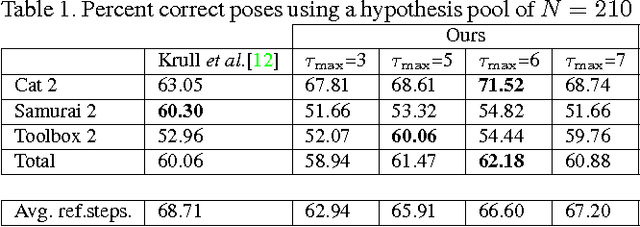
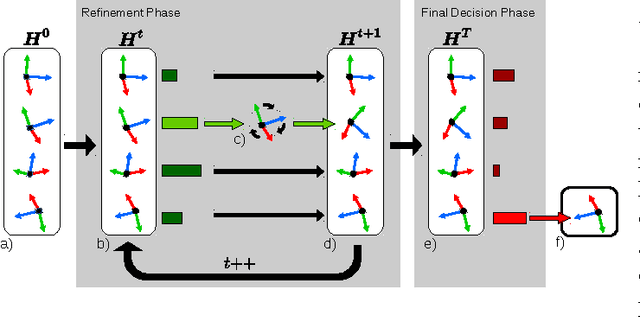
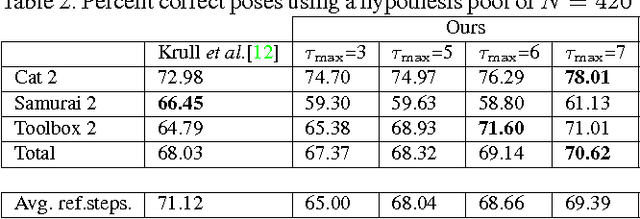
State-of-the-art computer vision algorithms often achieve efficiency by making discrete choices about which hypotheses to explore next. This allows allocation of computational resources to promising candidates, however, such decisions are non-differentiable. As a result, these algorithms are hard to train in an end-to-end fashion. In this work we propose to learn an efficient algorithm for the task of 6D object pose estimation. Our system optimizes the parameters of an existing state-of-the art pose estimation system using reinforcement learning, where the pose estimation system now becomes the stochastic policy, parametrized by a CNN. Additionally, we present an efficient training algorithm that dramatically reduces computation time. We show empirically that our learned pose estimation procedure makes better use of limited resources and improves upon the state-of-the-art on a challenging dataset. Our approach enables differentiable end-to-end training of complex algorithmic pipelines and learns to make optimal use of a given computational budget.
Decision Forests, Convolutional Networks and the Models in-Between
Mar 03, 2016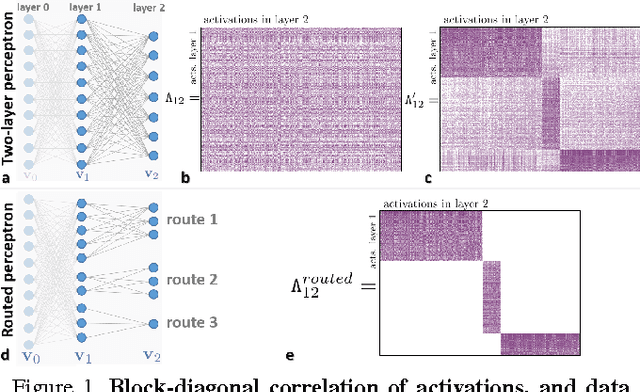
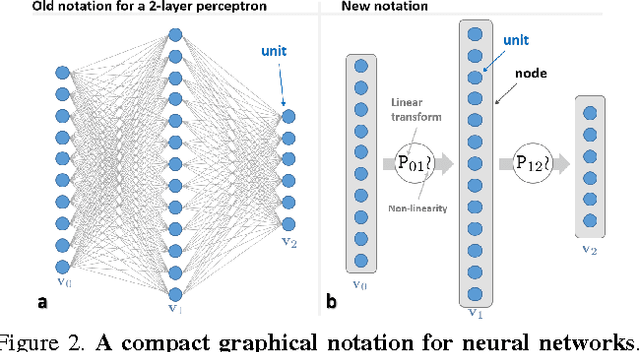
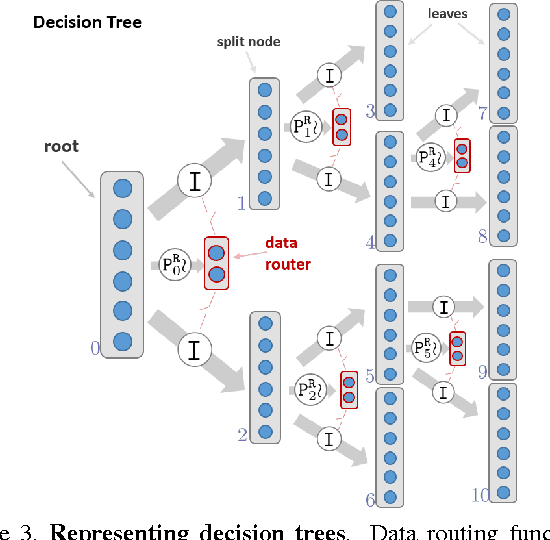
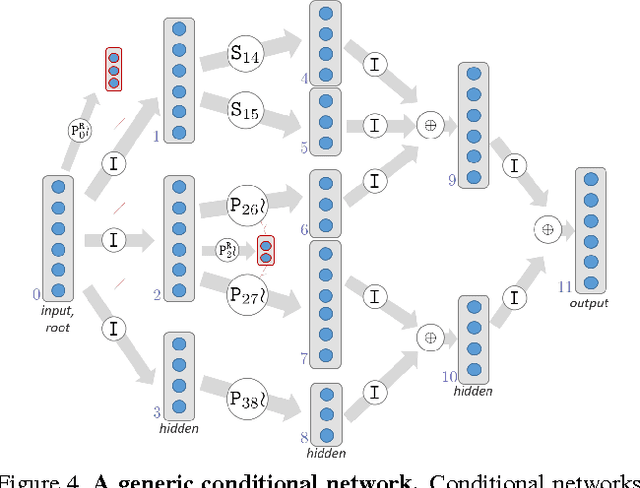
This paper investigates the connections between two state of the art classifiers: decision forests (DFs, including decision jungles) and convolutional neural networks (CNNs). Decision forests are computationally efficient thanks to their conditional computation property (computation is confined to only a small region of the tree, the nodes along a single branch). CNNs achieve state of the art accuracy, thanks to their representation learning capabilities. We present a systematic analysis of how to fuse conditional computation with representation learning and achieve a continuum of hybrid models with different ratios of accuracy vs. efficiency. We call this new family of hybrid models conditional networks. Conditional networks can be thought of as: i) decision trees augmented with data transformation operators, or ii) CNNs, with block-diagonal sparse weight matrices, and explicit data routing functions. Experimental validation is performed on the common task of image classification on both the CIFAR and Imagenet datasets. Compared to state of the art CNNs, our hybrid models yield the same accuracy with a fraction of the compute cost and much smaller number of parameters.
Training CNNs with Low-Rank Filters for Efficient Image Classification
Feb 07, 2016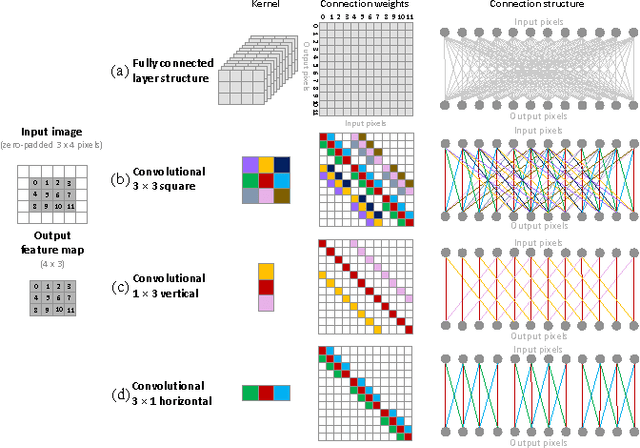
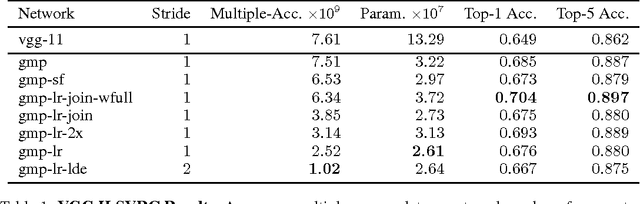
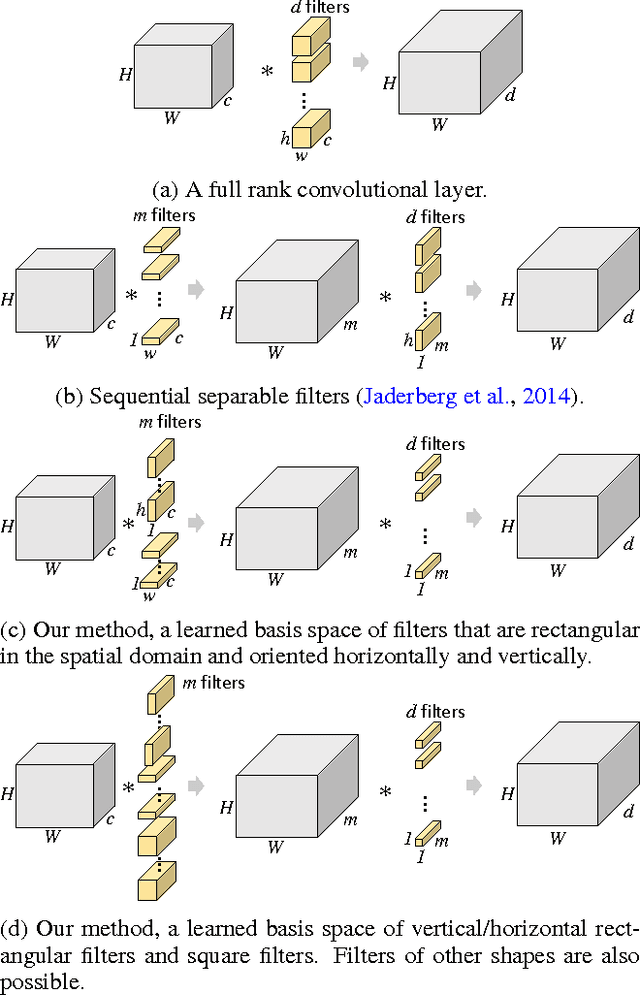
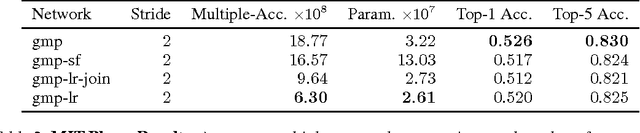
We propose a new method for creating computationally efficient convolutional neural networks (CNNs) by using low-rank representations of convolutional filters. Rather than approximating filters in previously-trained networks with more efficient versions, we learn a set of small basis filters from scratch; during training, the network learns to combine these basis filters into more complex filters that are discriminative for image classification. To train such networks, a novel weight initialization scheme is used. This allows effective initialization of connection weights in convolutional layers composed of groups of differently-shaped filters. We validate our approach by applying it to several existing CNN architectures and training these networks from scratch using the CIFAR, ILSVRC and MIT Places datasets. Our results show similar or higher accuracy than conventional CNNs with much less compute. Applying our method to an improved version of VGG-11 network using global max-pooling, we achieve comparable validation accuracy using 41% less compute and only 24% of the original VGG-11 model parameters; another variant of our method gives a 1 percentage point increase in accuracy over our improved VGG-11 model, giving a top-5 center-crop validation accuracy of 89.7% while reducing computation by 16% relative to the original VGG-11 model. Applying our method to the GoogLeNet architecture for ILSVRC, we achieved comparable accuracy with 26% less compute and 41% fewer model parameters. Applying our method to a near state-of-the-art network for CIFAR, we achieved comparable accuracy with 46% less compute and 55% fewer parameters.
* Published as a conference paper at ICLR 2016. v3: updated ICLR status. v2: Incorporated reviewer's feedback including: Amend Fig. 2 and 5 descriptions to explain that there are no ReLUs within the figures. Fix headings of Table 5 - Fix typo in the sentence at bottom of page 6. Add ref. to Predicting Parameters in Deep Learning. Fix Table 6, GMP-LR and GMP-LR-2x had incorrect numbers of filters
Depth-based hand pose estimation: methods, data, and challenges
May 06, 2015
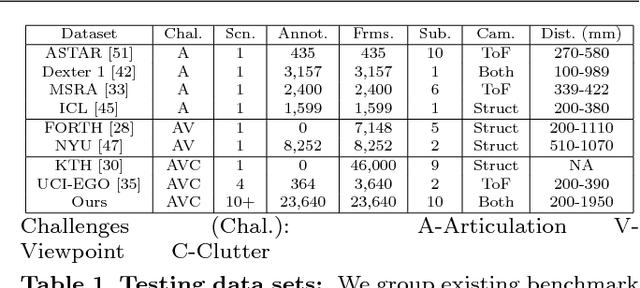


Hand pose estimation has matured rapidly in recent years. The introduction of commodity depth sensors and a multitude of practical applications have spurred new advances. We provide an extensive analysis of the state-of-the-art, focusing on hand pose estimation from a single depth frame. To do so, we have implemented a considerable number of systems, and will release all software and evaluation code. We summarize important conclusions here: (1) Pose estimation appears roughly solved for scenes with isolated hands. However, methods still struggle to analyze cluttered scenes where hands may be interacting with nearby objects and surfaces. To spur further progress we introduce a challenging new dataset with diverse, cluttered scenes. (2) Many methods evaluate themselves with disparate criteria, making comparisons difficult. We define a consistent evaluation criteria, rigorously motivated by human experiments. (3) We introduce a simple nearest-neighbor baseline that outperforms most existing systems. This implies that most systems do not generalize beyond their training sets. This also reinforces the under-appreciated point that training data is as important as the model itself. We conclude with directions for future progress.