 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Roots: Improving CNN Efficiency with Hierarchical Filter Groups
Nov 30, 2016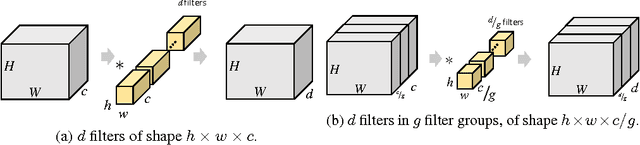

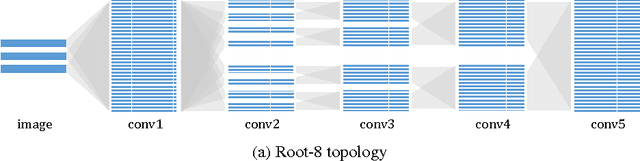
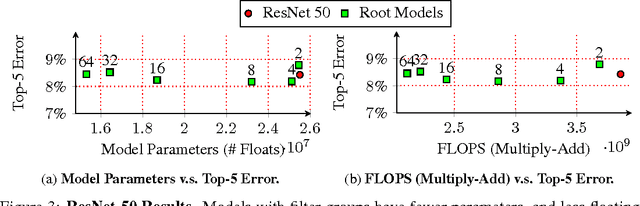
We propose a new method for creating computationally efficient and compact convolutional neural networks (CNNs) using a novel sparse connection structure that resembles a tree root. This allows a significant reduction in computational cost and number of parameters compared to state-of-the-art deep CNNs, without compromising accuracy, by exploiting the sparsity of inter-layer filter dependencies. We validate our approach by using it to train more efficient variants of state-of-the-art CNN architectures, evaluated on the CIFAR10 and ILSVRC datasets. Our results show similar or higher accuracy than the baseline architectures with much less computation, as measured by CPU and GPU timings. For example, for ResNet 50, our model has 40% fewer parameters, 45% fewer floating point operations, and is 31% (12%) faster on a CPU (GPU). For the deeper ResNet 200 our model has 25% fewer floating point operations and 44% fewer parameters, while maintaining state-of-the-art accuracy. For GoogLeNet, our model has 7% fewer parameters and is 21% (16%) faster on a CPU (GPU).
Refining Architectures of Deep Convolutional Neural Networks
Apr 22, 2016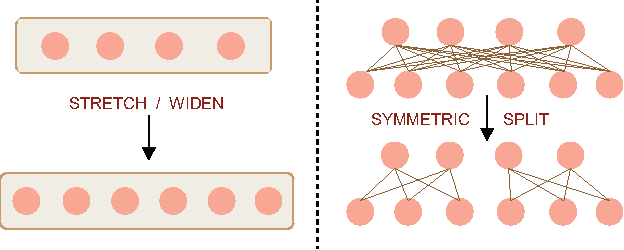
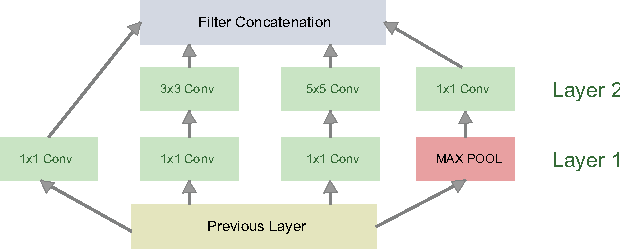

Deep Convolutional Neural Networks (CNNs) have recently evinced immense success for various image recognition tasks. However, a question of paramount importance is somewhat unanswered in deep learning research - is the selected CNN optimal for the dataset in terms of accuracy and model size? In this paper, we intend to answer this question and introduce a novel strategy that alters the architecture of a given CNN for a specified dataset, to potentially enhance the original accuracy while possibly reducing the model size. We use two operations for architecture refinement, viz. stretching and symmetrical splitting. Our procedure starts with a pre-trained CNN for a given dataset, and optimally decides the stretch and split factors across the network to refine the architecture. We empirically demonstrate the necessity of the two operations. We evaluate our approach on two natural scenes attributes datasets, SUN Attributes and CAMIT-NSAD, with architectures of GoogleNet and VGG-11, that are quite contrasting in their construction. We justify our choice of datasets, and show that they are interestingly distinct from each other, and together pose a challenge to our architectural refinement algorithm. Our results substantiate the usefulness of the proposed method.
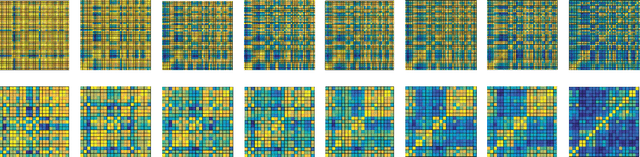
Decision Forests, Convolutional Networks and the Models in-Between
Mar 03, 2016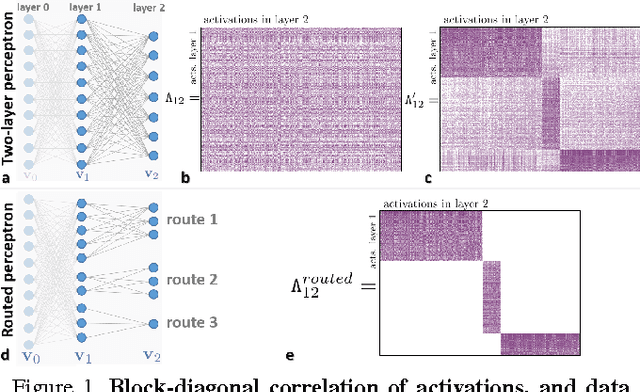
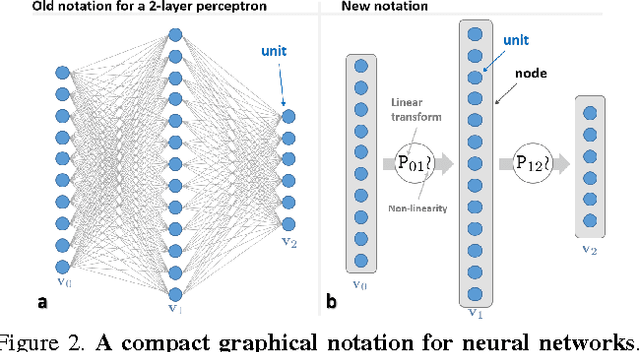
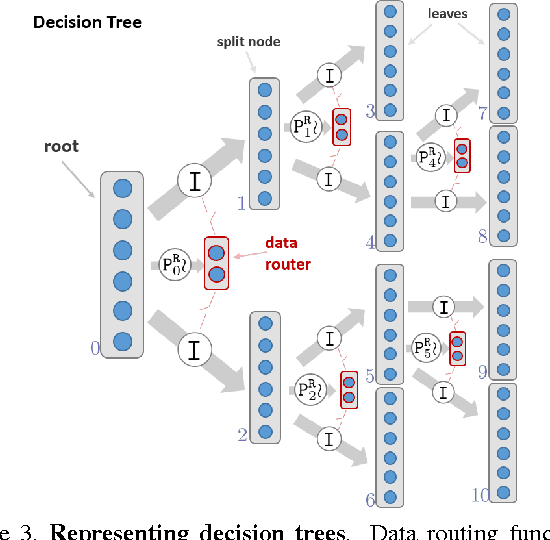
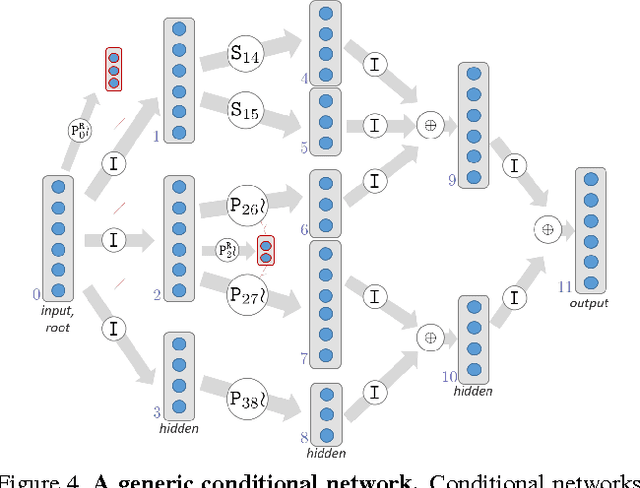
This paper investigates the connections between two state of the art classifiers: decision forests (DFs, including decision jungles) and convolutional neural networks (CNNs). Decision forests are computationally efficient thanks to their conditional computation property (computation is confined to only a small region of the tree, the nodes along a single branch). CNNs achieve state of the art accuracy, thanks to their representation learning capabilities. We present a systematic analysis of how to fuse conditional computation with representation learning and achieve a continuum of hybrid models with different ratios of accuracy vs. efficiency. We call this new family of hybrid models conditional networks. Conditional networks can be thought of as: i) decision trees augmented with data transformation operators, or ii) CNNs, with block-diagonal sparse weight matrices, and explicit data routing functions. Experimental validation is performed on the common task of image classification on both the CIFAR and Imagenet datasets. Compared to state of the art CNNs, our hybrid models yield the same accuracy with a fraction of the compute cost and much smaller number of parameters.
Training CNNs with Low-Rank Filters for Efficient Image Classification
Feb 07, 2016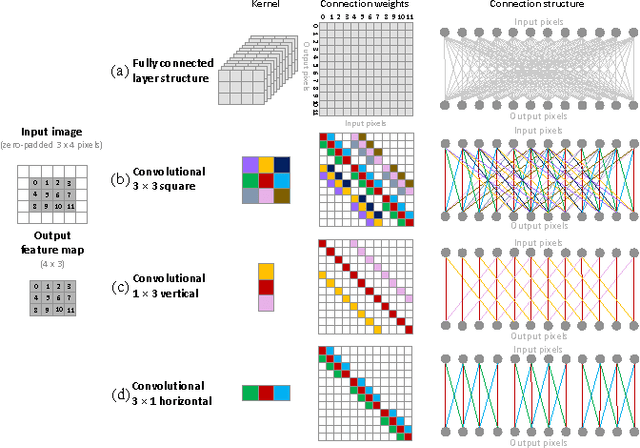
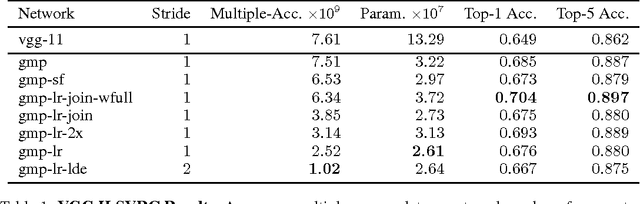
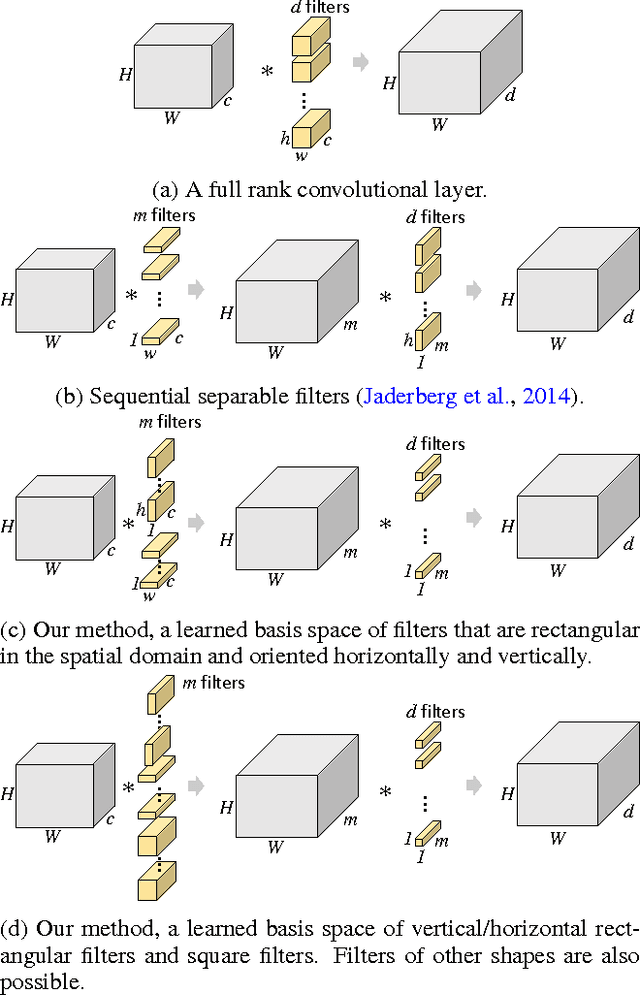
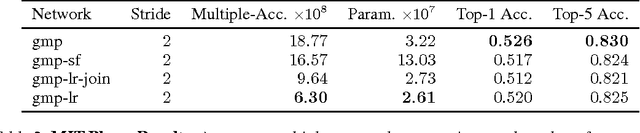
We propose a new method for creating computationally efficient convolutional neural networks (CNNs) by using low-rank representations of convolutional filters. Rather than approximating filters in previously-trained networks with more efficient versions, we learn a set of small basis filters from scratch; during training, the network learns to combine these basis filters into more complex filters that are discriminative for image classification. To train such networks, a novel weight initialization scheme is used. This allows effective initialization of connection weights in convolutional layers composed of groups of differently-shaped filters. We validate our approach by applying it to several existing CNN architectures and training these networks from scratch using the CIFAR, ILSVRC and MIT Places datasets. Our results show similar or higher accuracy than conventional CNNs with much less compute. Applying our method to an improved version of VGG-11 network using global max-pooling, we achieve comparable validation accuracy using 41% less compute and only 24% of the original VGG-11 model parameters; another variant of our method gives a 1 percentage point increase in accuracy over our improved VGG-11 model, giving a top-5 center-crop validation accuracy of 89.7% while reducing computation by 16% relative to the original VGG-11 model. Applying our method to the GoogLeNet architecture for ILSVRC, we achieved comparable accuracy with 26% less compute and 41% fewer model parameters. Applying our method to a near state-of-the-art network for CIFAR, we achieved comparable accuracy with 46% less compute and 55% fewer parameters.
* Published as a conference paper at ICLR 2016. v3: updated ICLR status. v2: Incorporated reviewer's feedback including: Amend Fig. 2 and 5 descriptions to explain that there are no ReLUs within the figures. Fix headings of Table 5 - Fix typo in the sentence at bottom of page 6. Add ref. to Predicting Parameters in Deep Learning. Fix Table 6, GMP-LR and GMP-LR-2x had incorrect numbers of filters