 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKernel Deformed Exponential Families for Sparse Continuous Attention
Nov 12, 2021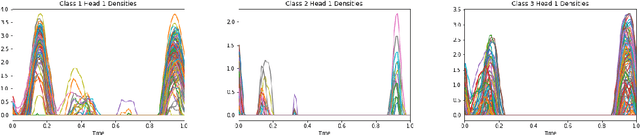
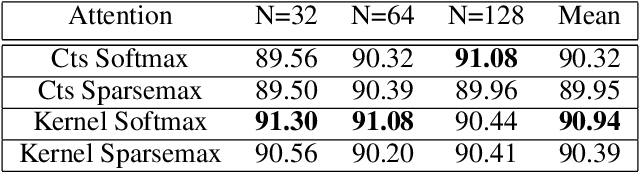
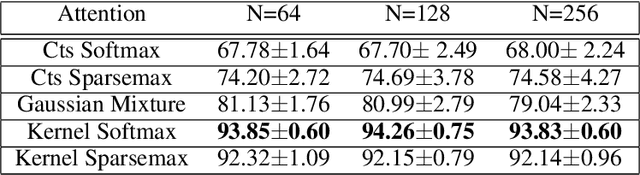
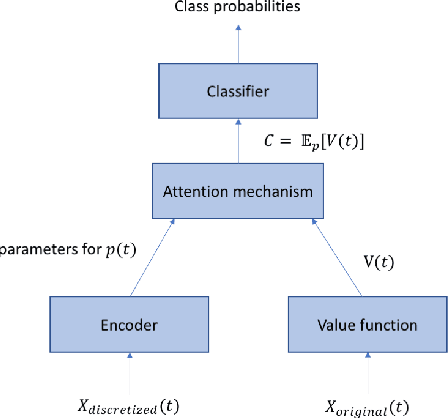
Attention mechanisms take an expectation of a data representation with respect to probability weights. This creates summary statistics that focus on important features. Recently, (Martins et al. 2020, 2021) proposed continuous attention mechanisms, focusing on unimodal attention densities from the exponential and deformed exponential families: the latter has sparse support. (Farinhas et al. 2021) extended this to use Gaussian mixture attention densities, which are a flexible class with dense support. In this paper, we extend this to two general flexible classes: kernel exponential families and our new sparse counterpart kernel deformed exponential families. Theoretically, we show new existence results for both kernel exponential and deformed exponential families, and that the deformed case has similar approximation capabilities to kernel exponential families. Experiments show that kernel deformed exponential families can attend to multiple compact regions of the data domain.
Transformers for prompt-level EMA non-response prediction
Nov 01, 2021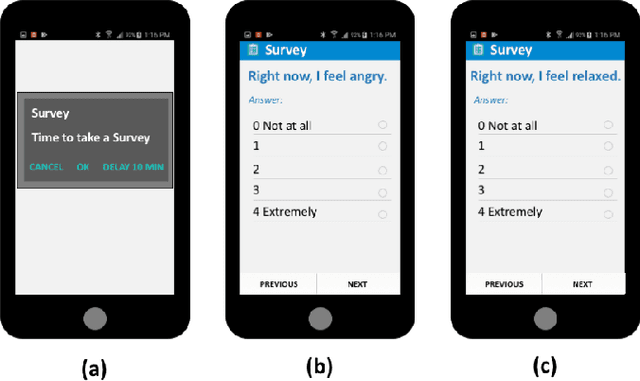
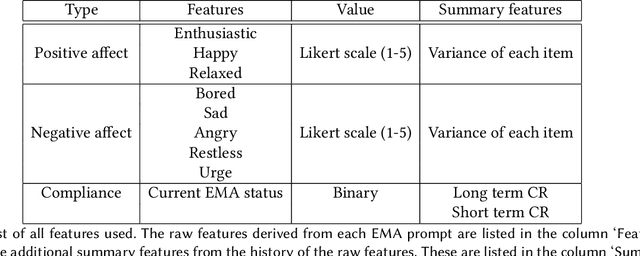
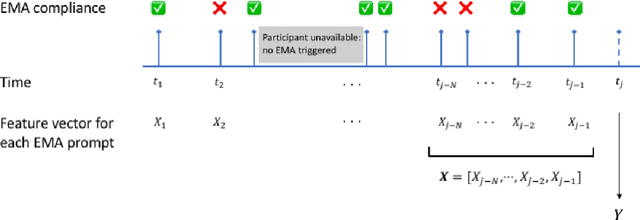

Ecological Momentary Assessments (EMAs) are an important psychological data source for measuring current cognitive states, affect, behavior, and environmental factors from participants in mobile health (mHealth) studies and treatment programs. Non-response, in which participants fail to respond to EMA prompts, is an endemic problem. The ability to accurately predict non-response could be utilized to improve EMA delivery and develop compliance interventions. Prior work has explored classical machine learning models for predicting non-response. However, as increasingly large EMA datasets become available, there is the potential to leverage deep learning models that have been effective in other fields. Recently, transformer models have shown state-of-the-art performance in NLP and other domains. This work is the first to explore the use of transformers for EMA data analysis. We address three key questions in applying transformers to EMA data: 1. Input representation, 2. encoding temporal information, 3. utility of pre-training on improving downstream prediction task performance. The transformer model achieves a non-response prediction AUC of 0.77 and is significantly better than classical ML and LSTM-based deep learning models. We will make our a predictive model trained on a corpus of 40K EMA samples freely-available to the research community, in order to facilitate the development of future transformer-based EMA analysis works.
Efficient Learning and Decoding of the Continuous-Time Hidden Markov Model for Disease Progression Modeling
Oct 26, 2021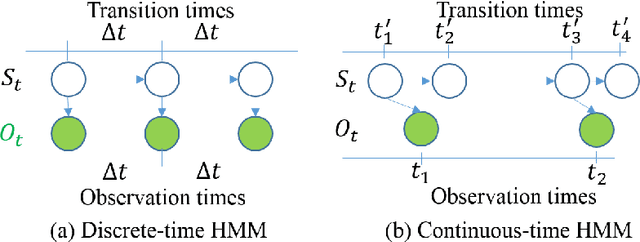

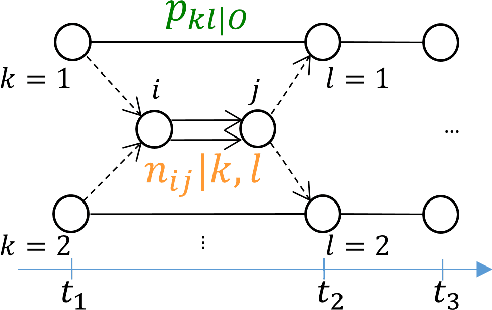
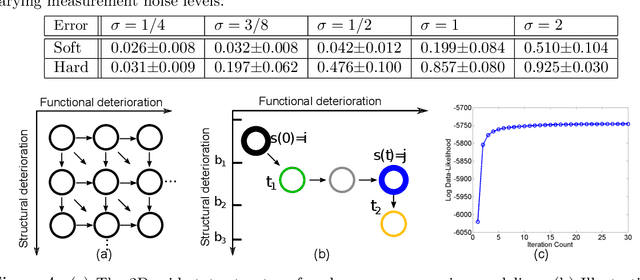
The Continuous-Time Hidden Markov Model (CT-HMM) is an attractive approach to modeling disease progression due to its ability to describe noisy observations arriving irregularly in time. However, the lack of an efficient parameter learning algorithm for CT-HMM restricts its use to very small models or requires unrealistic constraints on the state transitions. In this paper, we present the first complete characterization of efficient EM-based learning methods for CT-HMM models, as well as the first solution to decoding the optimal state transition sequence and the corresponding state dwelling time. We show that EM-based learning consists of two challenges: the estimation of posterior state probabilities and the computation of end-state conditioned statistics. We solve the first challenge by reformulating the estimation problem as an equivalent discrete time-inhomogeneous hidden Markov model. The second challenge is addressed by adapting three distinct approaches from the continuous time Markov chain (CTMC) literature to the CT-HMM domain. Additionally, we further improve the efficiency of the most efficient method by a factor of the number of states. Then, for decoding, we incorporate a state-of-the-art method from the (CTMC) literature, and extend the end-state conditioned optimal state sequence decoding to the CT-HMM case with the computation of the expected state dwelling time. We demonstrate the use of CT-HMMs with more than 100 states to visualize and predict disease progression using a glaucoma dataset and an Alzheimer's disease dataset, and to decode and visualize the most probable state transition trajectory for individuals on the glaucoma dataset, which helps to identify progressing phenotypes in a comprehensive way. Finally, we apply the CT-HMM modeling and decoding strategy to investigate the progression of language acquisition and development.
No RL, No Simulation: Learning to Navigate without Navigating
Oct 22, 2021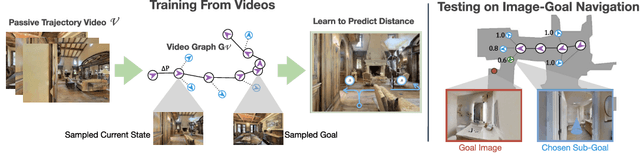
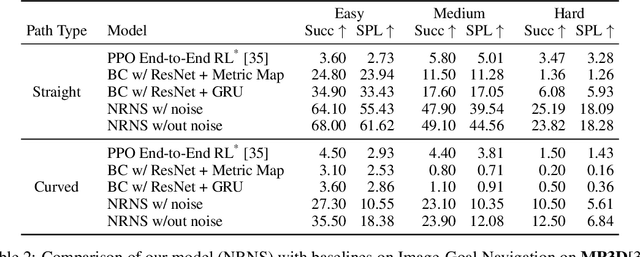
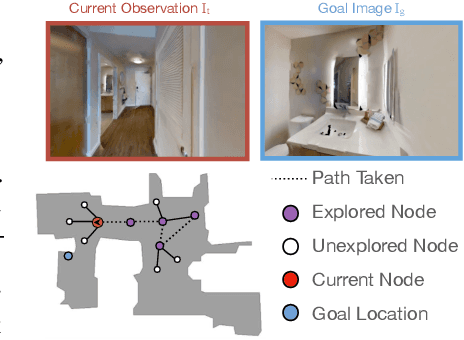
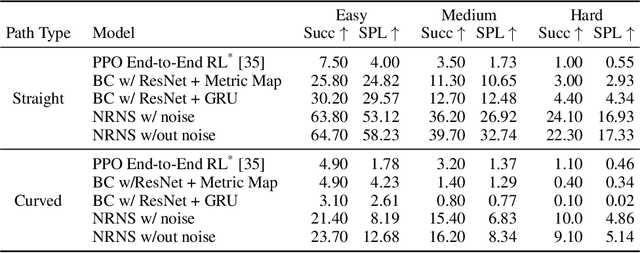
Most prior methods for learning navigation policies require access to simulation environments, as they need online policy interaction and rely on ground-truth maps for rewards. However, building simulators is expensive (requires manual effort for each and every scene) and creates challenges in transferring learned policies to robotic platforms in the real-world, due to the sim-to-real domain gap. In this paper, we pose a simple question: Do we really need active interaction, ground-truth maps or even reinforcement-learning (RL) in order to solve the image-goal navigation task? We propose a self-supervised approach to learn to navigate from only passive videos of roaming. Our approach, No RL, No Simulator (NRNS), is simple and scalable, yet highly effective. NRNS outperforms RL-based formulations by a significant margin. We present NRNS as a strong baseline for any future image-based navigation tasks that use RL or Simulation.
Ego4D: Around the World in 3,000 Hours of Egocentric Video
Oct 13, 2021



We introduce Ego4D, a massive-scale egocentric video dataset and benchmark suite. It offers 3,025 hours of daily-life activity video spanning hundreds of scenarios (household, outdoor, workplace, leisure, etc.) captured by 855 unique camera wearers from 74 worldwide locations and 9 different countries. The approach to collection is designed to uphold rigorous privacy and ethics standards with consenting participants and robust de-identification procedures where relevant. Ego4D dramatically expands the volume of diverse egocentric video footage publicly available to the research community. Portions of the video are accompanied by audio, 3D meshes of the environment, eye gaze, stereo, and/or synchronized videos from multiple egocentric cameras at the same event. Furthermore, we present a host of new benchmark challenges centered around understanding the first-person visual experience in the past (querying an episodic memory), present (analyzing hand-object manipulation, audio-visual conversation, and social interactions), and future (forecasting activities). By publicly sharing this massive annotated dataset and benchmark suite, we aim to push the frontier of first-person perception. Project page: https://ego4d-data.org/
Egocentric Activity Recognition and Localization on a 3D Map
May 27, 2021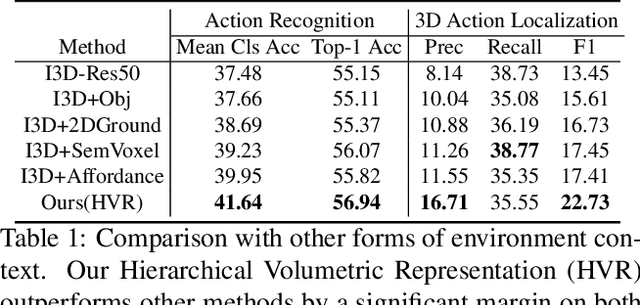
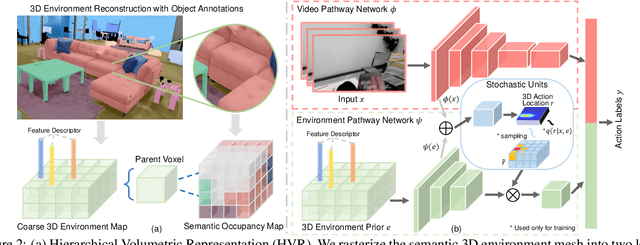
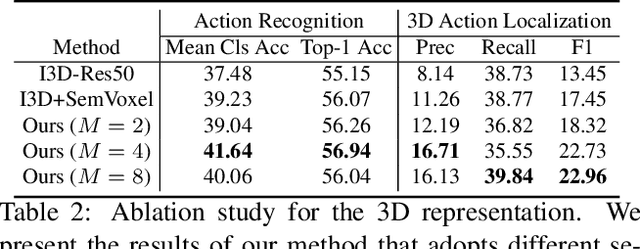
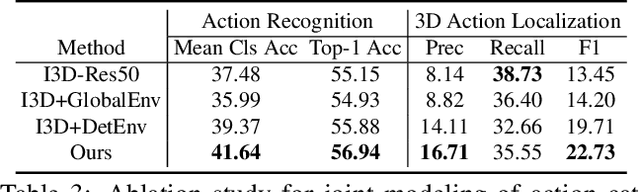
Given a video captured from a first person perspective and recorded in a familiar environment, can we recognize what the person is doing and identify where the action occurs in the 3D space? We address this challenging problem of jointly recognizing and localizing actions of a mobile user on a known 3D map from egocentric videos. To this end, we propose a novel deep probabilistic model. Our model takes the inputs of a Hierarchical Volumetric Representation (HVR) of the environment and an egocentric video, infers the 3D action location as a latent variable, and recognizes the action based on the video and contextual cues surrounding its potential locations. To evaluate our model, we conduct extensive experiments on a newly collected egocentric video dataset, in which both human naturalistic actions and photo-realistic 3D environment reconstructions are captured. Our method demonstrates strong results on both action recognition and 3D action localization across seen and unseen environments. We believe our work points to an exciting research direction in the intersection of egocentric vision, and 3D scene understanding.
Discriminative Appearance Modeling with Multi-track Pooling for Real-time Multi-object Tracking
Jan 28, 2021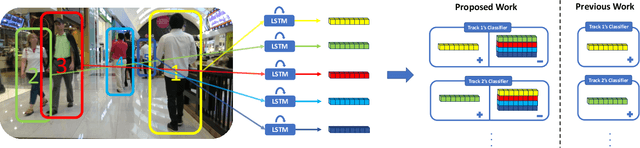

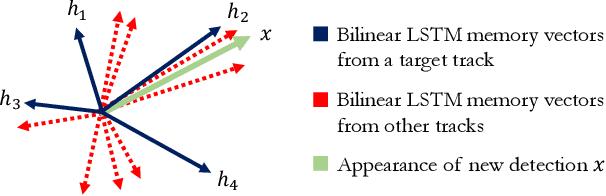

In multi-object tracking, the tracker maintains in its memory the appearance and motion information for each object in the scene. This memory is utilized for finding matches between tracks and detections and is updated based on the matching result. Many approaches model each target in isolation and lack the ability to use all the targets in the scene to jointly update the memory. This can be problematic when there are similar looking objects in the scene. In this paper, we solve the problem of simultaneously considering all tracks during memory updating, with only a small spatial overhead, via a novel multi-track pooling module. We additionally propose a training strategy adapted to multi-track pooling which generates hard tracking episodes online. We show that the combination of these innovations results in a strong discriminative appearance model, enabling the use of greedy data association to achieve online tracking performance. Our experiments demonstrate real-time, state-of-the-art performance on public multi-object tracking (MOT) datasets.
Using Shape to Categorize: Low-Shot Learning with an Explicit Shape Bias
Jan 18, 2021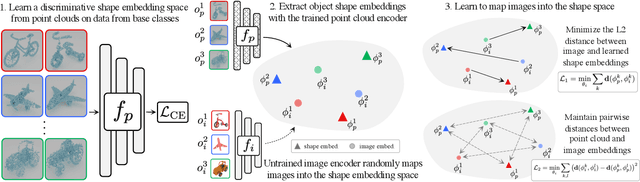
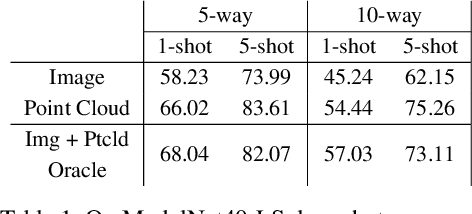
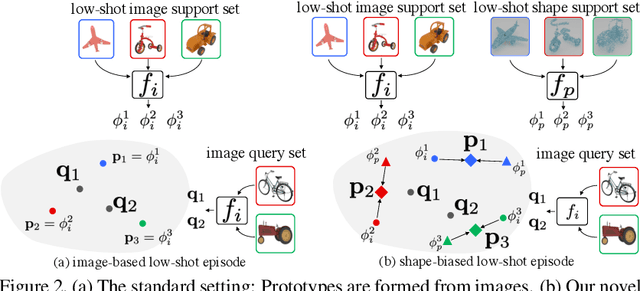
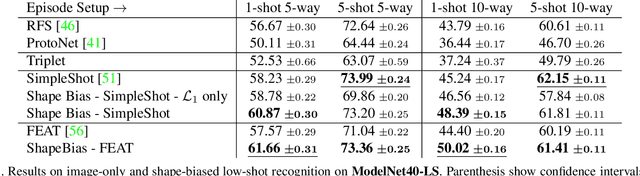
It is widely accepted that reasoning about object shape is important for object recognition. However, the most powerful object recognition methods today do not explicitly make use of object shape during learning. In this work, motivated by recent developments in low-shot learning, findings in developmental psychology, and the increased use of synthetic data in computer vision research, we investigate how reasoning about 3D shape can be used to improve low-shot learning methods' generalization performance. We propose a new way to improve existing low-shot learning approaches by learning a discriminative embedding space using 3D object shape, and utilizing this embedding by learning how to map images into it. Our new approach improves the performance of image-only low-shot learning approaches on multiple datasets. We also develop Toys4K, a new 3D object dataset with the biggest number of object categories that can also support low-shot learning.
Does Continual Learning = Catastrophic Forgetting?
Jan 18, 2021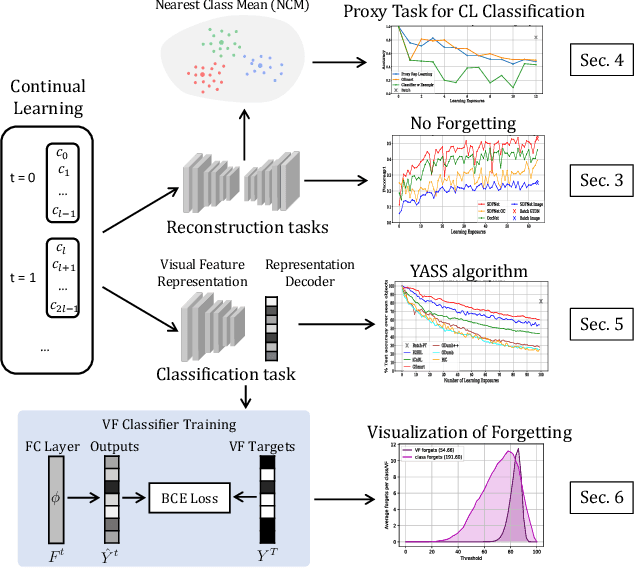
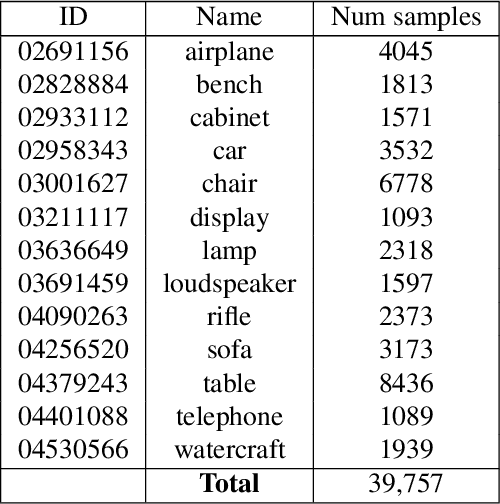
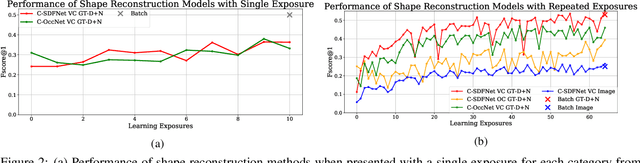
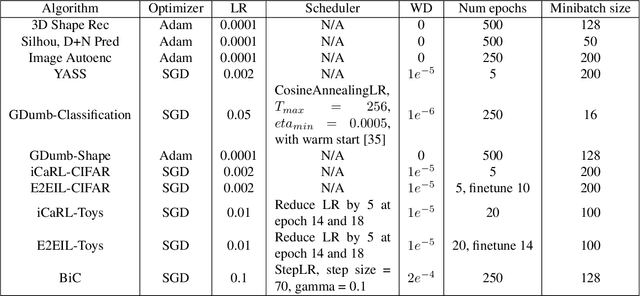
Continual learning is known for suffering from catastrophic forgetting, a phenomenon where earlier learned concepts are forgotten at the expense of more recent samples. In this work, we challenge the assumption that continual learning is inevitably associated with catastrophic forgetting by presenting a set of tasks that surprisingly do not suffer from catastrophic forgetting when learned continually. We attempt to provide an insight into the property of these tasks that make them robust to catastrophic forgetting and the potential of having a proxy representation learning task for continual classification. We further introduce a novel yet simple algorithm, YASS that outperforms state-of-the-art methods in the class-incremental categorization learning task. Finally, we present DyRT, a novel tool for tracking the dynamics of representation learning in continual models. The codebase, dataset and pre-trained models released with this article can be found at https://github.com/ngailapdi/CLRec.
4D Human Body Capture from Egocentric Video via 3D Scene Grounding
Nov 26, 2020


To understand human daily social interaction from egocentric perspective, we introduce a novel task of reconstructing a time series of second-person 3D human body meshes from monocular egocentric videos. The unique viewpoint and rapid embodied camera motion of egocentric videos raise additional technical barriers for human body capture. To address those challenges, we propose a novel optimization-based approach that leverages 2D observations of the entire video sequence and human-scene interaction constraint to estimate second-person human poses, shapes and global motion that are grounded on the 3D environment captured from the egocentric view. We conduct detailed ablation studies to validate our design choice. Moreover, we compare our method with previous state-of-the-art method on human motion capture from monocular video, and show that our method estimates more accurate human-body poses and shapes under the challenging egocentric setting. In addition, we demonstrate that our approach produces more realistic human-scene interaction. Our project page is available at: https://aptx4869lm.github.io/4DEgocentricBodyCapture/