 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat, when, and where? -- Self-Supervised Spatio-Temporal Grounding in Untrimmed Multi-Action Videos from Narrated Instructions
Mar 29, 2023Spatio-temporal grounding describes the task of localizing events in space and time, e.g., in video data, based on verbal descriptions only. Models for this task are usually trained with human-annotated sentences and bounding box supervision. This work addresses this task from a multimodal supervision perspective, proposing a framework for spatio-temporal action grounding trained on loose video and subtitle supervision only, without human annotation. To this end, we combine local representation learning, which focuses on leveraging fine-grained spatial information, with a global representation encoding that captures higher-level representations and incorporates both in a joint approach. To evaluate this challenging task in a real-life setting, a new benchmark dataset is proposed providing dense spatio-temporal grounding annotations in long, untrimmed, multi-action instructional videos for over 5K events. We evaluate the proposed approach and other methods on the proposed and standard downstream tasks showing that our method improves over current baselines in various settings, including spatial, temporal, and untrimmed multi-action spatio-temporal grounding.
Logic Against Bias: Textual Entailment Mitigates Stereotypical Sentence Reasoning
Mar 10, 2023Due to their similarity-based learning objectives, pretrained sentence encoders often internalize stereotypical assumptions that reflect the social biases that exist within their training corpora. In this paper, we describe several kinds of stereotypes concerning different communities that are present in popular sentence representation models, including pretrained next sentence prediction and contrastive sentence representation models. We compare such models to textual entailment models that learn language logic for a variety of downstream language understanding tasks. By comparing strong pretrained models based on text similarity with textual entailment learning, we conclude that the explicit logic learning with textual entailment can significantly reduce bias and improve the recognition of social communities, without an explicit de-biasing process
On the Blind Spots of Model-Based Evaluation Metrics for Text Generation
Dec 20, 2022



In this work, we explore a useful but often neglected methodology for robustness analysis of text generation evaluation metrics: stress tests with synthetic data. Basically, we design and synthesize a wide range of potential errors and check whether they result in a commensurate drop in the metric scores. We examine a range of recently proposed evaluation metrics based on pretrained language models, for the tasks of open-ended generation, translation, and summarization. Our experiments reveal interesting insensitivities, biases, or even loopholes in existing metrics. For example, we find that BERTScore ignores truncation errors in summarization, and MAUVE (built on top of GPT-2) is insensitive to errors at the beginning of generations. Further, we investigate the reasons behind these blind spots and suggest practical workarounds for a more reliable evaluation of text generation.
On Unsupervised Uncertainty-Driven Speech Pseudo-Label Filtering and Model Calibration
Nov 14, 2022



Pseudo-label (PL) filtering forms a crucial part of Self-Training (ST) methods for unsupervised domain adaptation. Dropout-based Uncertainty-driven Self-Training (DUST) proceeds by first training a teacher model on source domain labeled data. Then, the teacher model is used to provide PLs for the unlabeled target domain data. Finally, we train a student on augmented labeled and pseudo-labeled data. The process is iterative, where the student becomes the teacher for the next DUST iteration. A crucial step that precedes the student model training in each DUST iteration is filtering out noisy PLs that could lead the student model astray. In DUST, we proposed a simple, effective, and theoretically sound PL filtering strategy based on the teacher model's uncertainty about its predictions on unlabeled speech utterances. We estimate the model's uncertainty by computing disagreement amongst multiple samples drawn from the teacher model during inference by injecting noise via dropout. In this work, we show that DUST's PL filtering, as initially used, may fail under severe source and target domain mismatch. We suggest several approaches to eliminate or alleviate this issue. Further, we bring insights from the research in neural network model calibration to DUST and show that a well-calibrated model correlates strongly with a positive outcome of the DUST PL filtering step.
PCFG-based Natural Language Interface Improves Generalization for Controlled Text Generation
Oct 14, 2022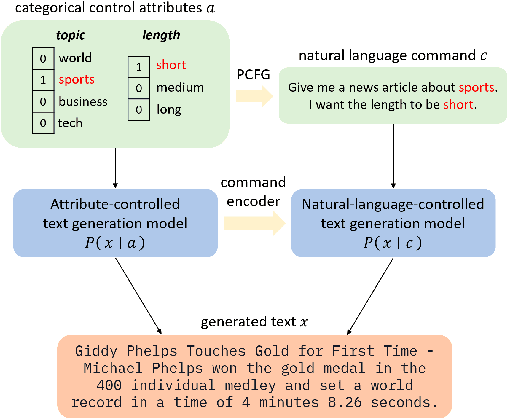

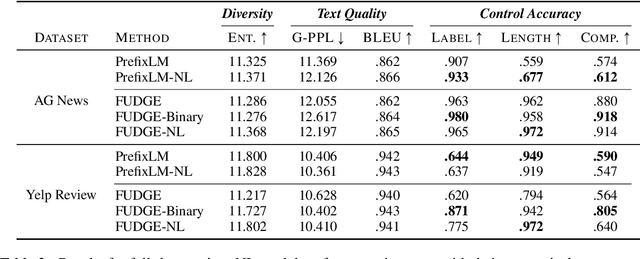
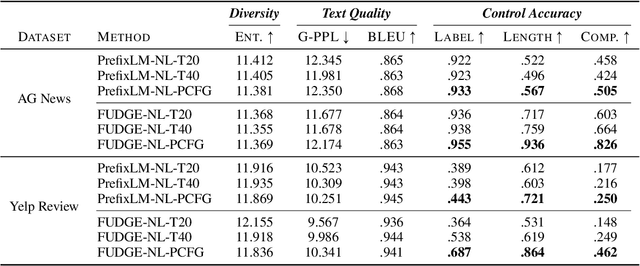
Existing work on controlled text generation (CTG) assumes a control interface of categorical attributes. In this work, we propose a natural language (NL) interface, where we craft a PCFG to embed the control attributes into natural language commands, and propose variants of existing CTG models that take commands as input. In our experiments, we design tailored setups to test model's generalization abilities. We find our PCFG-based command generation approach is effective for handling unseen commands compared to fix-set templates; our proposed NL models can effectively generalize to unseen attributes, a new ability enabled by the NL interface, as well as unseen attribute combinations. Interestingly, we discover that the simple conditional generation approach, enhanced with our proposed NL interface, is a strong baseline in those challenging settings.
C2KD: Cross-Lingual Cross-Modal Knowledge Distillation for Multilingual Text-Video Retrieval
Oct 07, 2022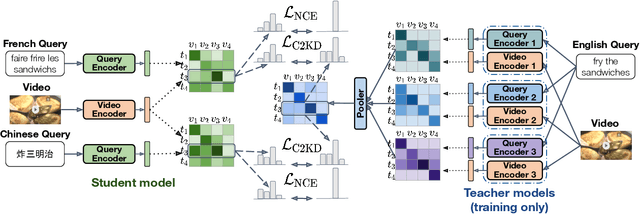
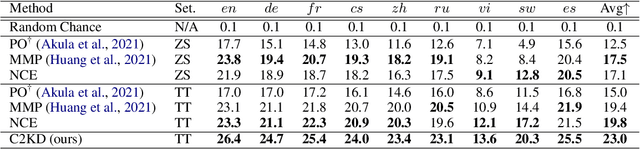

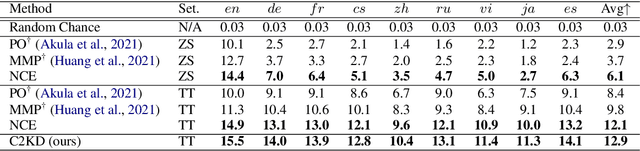
Multilingual text-video retrieval methods have improved significantly in recent years, but the performance for other languages lags behind English. We propose a Cross-Lingual Cross-Modal Knowledge Distillation method to improve multilingual text-video retrieval. Inspired by the fact that English text-video retrieval outperforms other languages, we train a student model using input text in different languages to match the cross-modal predictions from teacher models using input text in English. We propose a cross entropy based objective which forces the distribution over the student's text-video similarity scores to be similar to those of the teacher models. We introduce a new multilingual video dataset, Multi-YouCook2, by translating the English captions in the YouCook2 video dataset to 8 other languages. Our method improves multilingual text-video retrieval performance on Multi-YouCook2 and several other datasets such as Multi-MSRVTT and VATEX. We also conducted an analysis on the effectiveness of different multilingual text models as teachers.
UAVM: A Unified Model for Audio-Visual Learning
Jul 29, 2022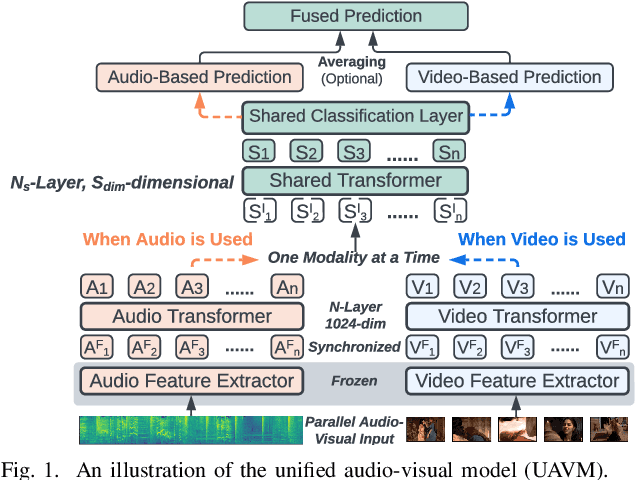
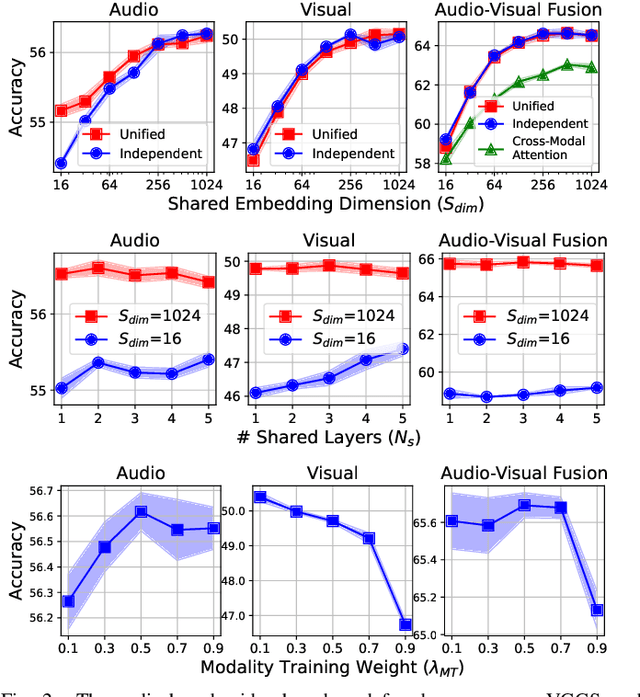
Conventional audio-visual models have independent audio and video branches. We design a unified model for audio and video processing called Unified Audio-Visual Model (UAVM). In this paper, we describe UAVM, report its new state-of-the-art audio-visual event classification accuracy of 65.8% on VGGSound, and describe the intriguing properties of the model.
Developing a Series of AI Challenges for the United States Department of the Air Force
Jul 14, 2022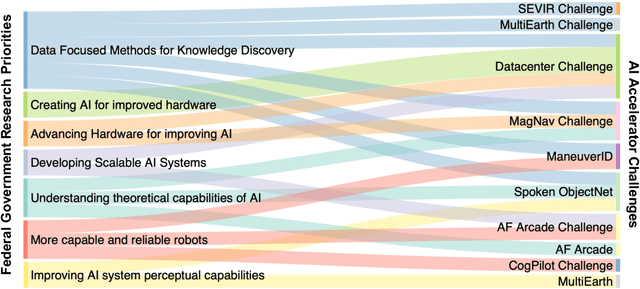

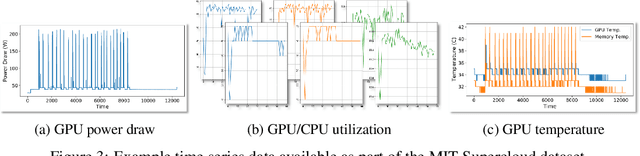
Through a series of federal initiatives and orders, the U.S. Government has been making a concerted effort to ensure American leadership in AI. These broad strategy documents have influenced organizations such as the United States Department of the Air Force (DAF). The DAF-MIT AI Accelerator is an initiative between the DAF and MIT to bridge the gap between AI researchers and DAF mission requirements. Several projects supported by the DAF-MIT AI Accelerator are developing public challenge problems that address numerous Federal AI research priorities. These challenges target priorities by making large, AI-ready datasets publicly available, incentivizing open-source solutions, and creating a demand signal for dual use technologies that can stimulate further research. In this article, we describe these public challenges being developed and how their application contributes to scientific advances.
SAMU-XLSR: Semantically-Aligned Multimodal Utterance-level Cross-Lingual Speech Representation
May 17, 2022
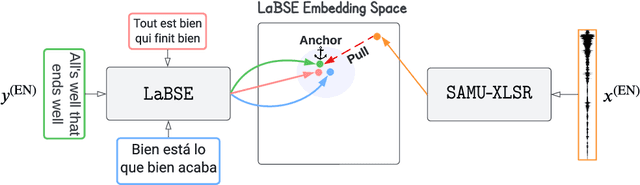
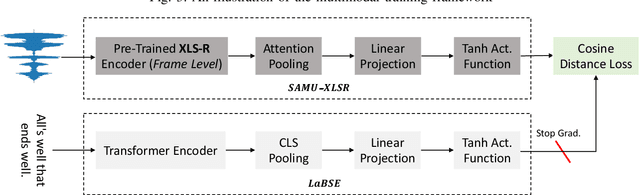
We propose the SAMU-XLSR: Semantically-Aligned Multimodal Utterance-level Cross-Lingual Speech Representation learning framework. Unlike previous works on speech representation learning, which learns multilingual contextual speech embedding at the resolution of an acoustic frame (10-20ms), this work focuses on learning multimodal (speech-text) multilingual speech embedding at the resolution of a sentence (5-10s) such that the embedding vector space is semantically aligned across different languages. We combine state-of-the-art multilingual acoustic frame-level speech representation learning model XLS-R with the Language Agnostic BERT Sentence Embedding (LaBSE) model to create an utterance-level multimodal multilingual speech encoder SAMU-XLSR. Although we train SAMU-XLSR with only multilingual transcribed speech data, cross-lingual speech-text and speech-speech associations emerge in its learned representation space. To substantiate our claims, we use SAMU-XLSR speech encoder in combination with a pre-trained LaBSE text sentence encoder for cross-lingual speech-to-text translation retrieval, and SAMU-XLSR alone for cross-lingual speech-to-speech translation retrieval. We highlight these applications by performing several cross-lingual text and speech translation retrieval tasks across several datasets.
Vocalsound: A Dataset for Improving Human Vocal Sounds Recognition
May 06, 2022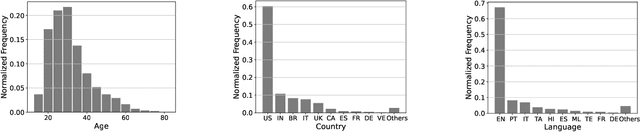
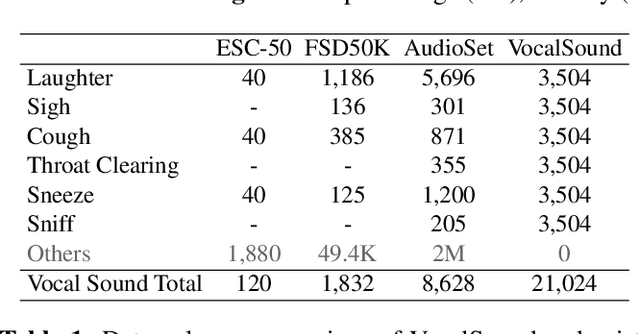
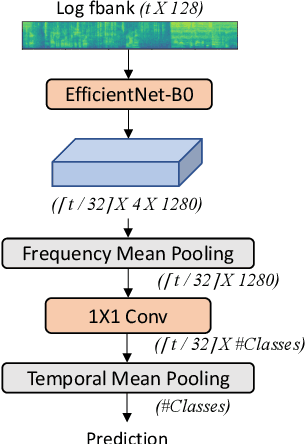
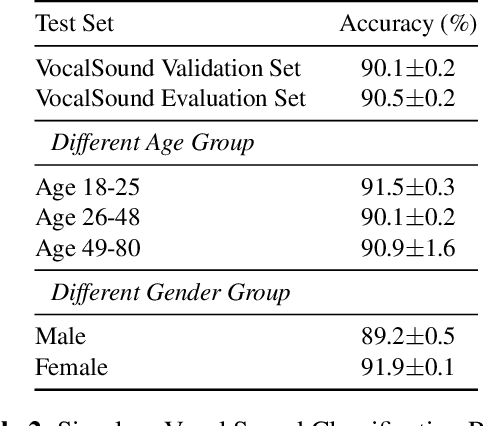
Recognizing human non-speech vocalizations is an important task and has broad applications such as automatic sound transcription and health condition monitoring. However, existing datasets have a relatively small number of vocal sound samples or noisy labels. As a consequence, state-of-the-art audio event classification models may not perform well in detecting human vocal sounds. To support research on building robust and accurate vocal sound recognition, we have created a VocalSound dataset consisting of over 21,000 crowdsourced recordings of laughter, sighs, coughs, throat clearing, sneezes, and sniffs from 3,365 unique subjects. Experiments show that the vocal sound recognition performance of a model can be significantly improved by 41.9% by adding VocalSound dataset to an existing dataset as training material. In addition, different from previous datasets, the VocalSound dataset contains meta information such as speaker age, gender, native language, country, and health condition.