 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReconstructing and grounding narrated instructional videos in 3D
Sep 10, 2021
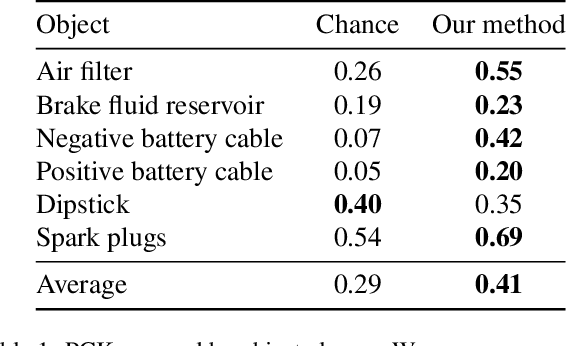
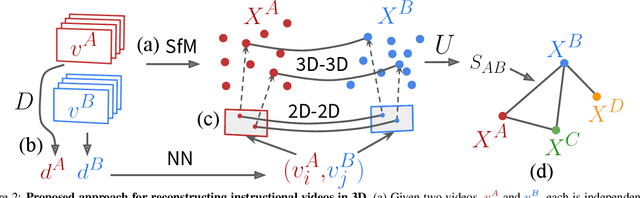

Narrated instructional videos often show and describe manipulations of similar objects, e.g., repairing a particular model of a car or laptop. In this work we aim to reconstruct such objects and to localize associated narrations in 3D. Contrary to the standard scenario of instance-level 3D reconstruction, where identical objects or scenes are present in all views, objects in different instructional videos may have large appearance variations given varying conditions and versions of the same product. Narrations may also have large variation in natural language expressions. We address these challenges by three contributions. First, we propose an approach for correspondence estimation combining learnt local features and dense flow. Second, we design a two-step divide and conquer reconstruction approach where the initial 3D reconstructions of individual videos are combined into a 3D alignment graph. Finally, we propose an unsupervised approach to ground natural language in obtained 3D reconstructions. We demonstrate the effectiveness of our approach for the domain of car maintenance. Given raw instructional videos and no manual supervision, our method successfully reconstructs engines of different car models and associates textual descriptions with corresponding objects in 3D.
Airbert: In-domain Pretraining for Vision-and-Language Navigation
Aug 20, 2021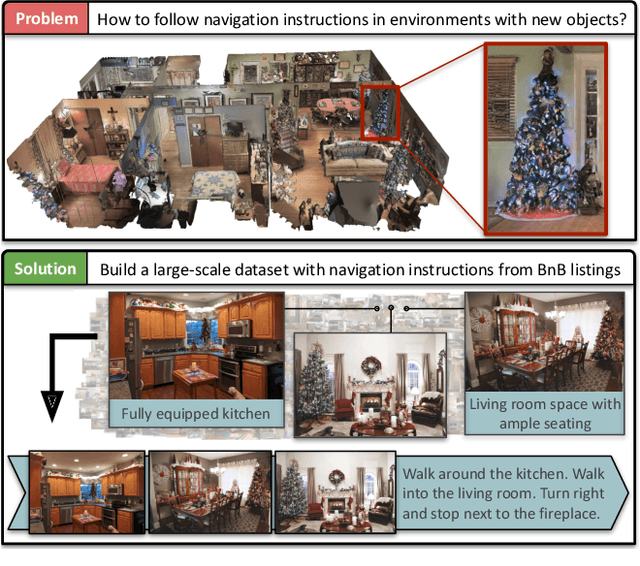
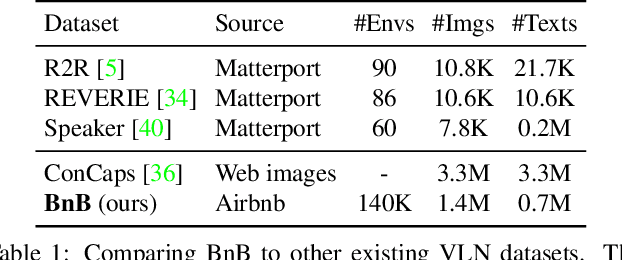

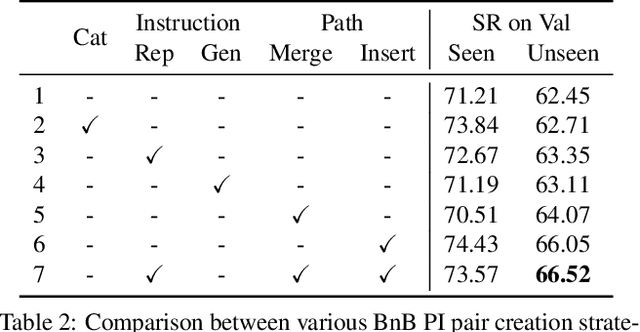
Vision-and-language navigation (VLN) aims to enable embodied agents to navigate in realistic environments using natural language instructions. Given the scarcity of domain-specific training data and the high diversity of image and language inputs, the generalization of VLN agents to unseen environments remains challenging. Recent methods explore pretraining to improve generalization, however, the use of generic image-caption datasets or existing small-scale VLN environments is suboptimal and results in limited improvements. In this work, we introduce BnB, a large-scale and diverse in-domain VLN dataset. We first collect image-caption (IC) pairs from hundreds of thousands of listings from online rental marketplaces. Using IC pairs we next propose automatic strategies to generate millions of VLN path-instruction (PI) pairs. We further propose a shuffling loss that improves the learning of temporal order inside PI pairs. We use BnB pretrain our Airbert model that can be adapted to discriminative and generative settings and show that it outperforms state of the art for Room-to-Room (R2R) navigation and Remote Referring Expression (REVERIE) benchmarks. Moreover, our in-domain pretraining significantly increases performance on a challenging few-shot VLN evaluation, where we train the model only on VLN instructions from a few houses.
Towards unconstrained joint hand-object reconstruction from RGB videos
Aug 16, 2021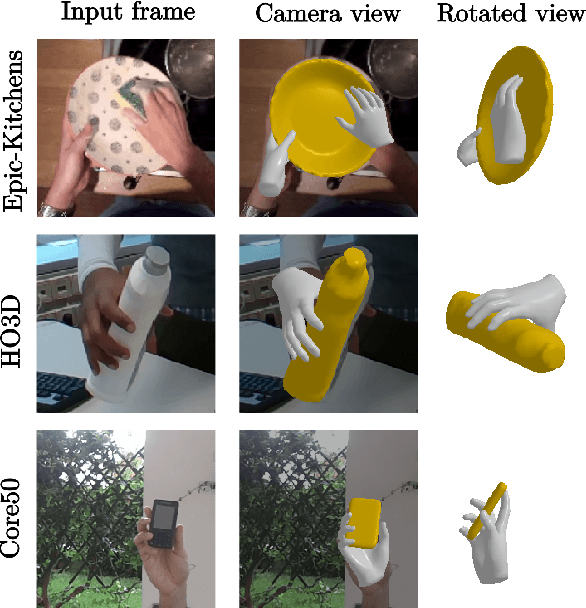
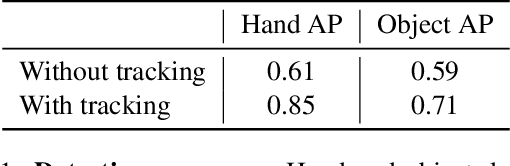

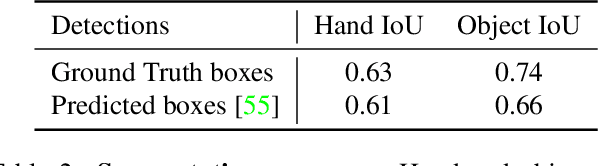
Our work aims to obtain 3D reconstruction of hands and manipulated objects from monocular videos. Reconstructing hand-object manipulations holds a great potential for robotics and learning from human demonstrations. The supervised learning approach to this problem, however, requires 3D supervision and remains limited to constrained laboratory settings and simulators for which 3D ground truth is available. In this paper we first propose a learning-free fitting approach for hand-object reconstruction which can seamlessly handle two-hand object interactions. Our method relies on cues obtained with common methods for object detection, hand pose estimation and instance segmentation. We quantitatively evaluate our approach and show that it can be applied to datasets with varying levels of difficulty for which training data is unavailable.
Goal-Conditioned Reinforcement Learning with Imagined Subgoals
Jul 01, 2021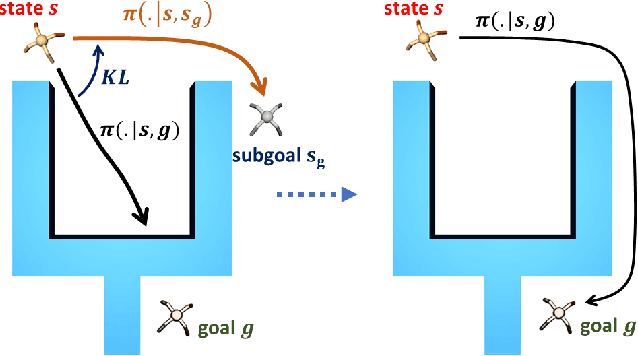
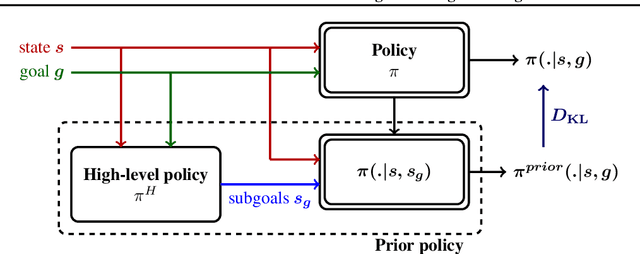

Goal-conditioned reinforcement learning endows an agent with a large variety of skills, but it often struggles to solve tasks that require more temporally extended reasoning. In this work, we propose to incorporate imagined subgoals into policy learning to facilitate learning of complex tasks. Imagined subgoals are predicted by a separate high-level policy, which is trained simultaneously with the policy and its critic. This high-level policy predicts intermediate states halfway to the goal using the value function as a reachability metric. We don't require the policy to reach these subgoals explicitly. Instead, we use them to define a prior policy, and incorporate this prior into a KL-constrained policy iteration scheme to speed up and regularize learning. Imagined subgoals are used during policy learning, but not during test time, where we only apply the learned policy. We evaluate our approach on complex robotic navigation and manipulation tasks and show that it outperforms existing methods by a large margin.
XCiT: Cross-Covariance Image Transformers
Jun 18, 2021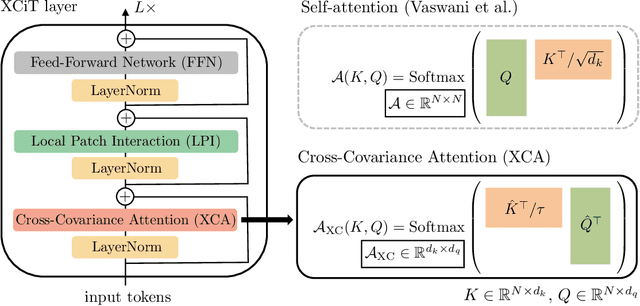
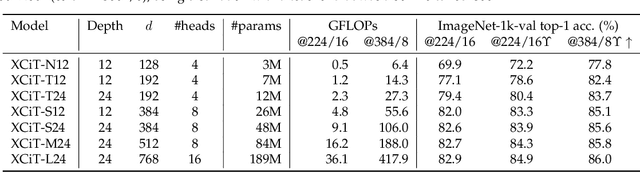
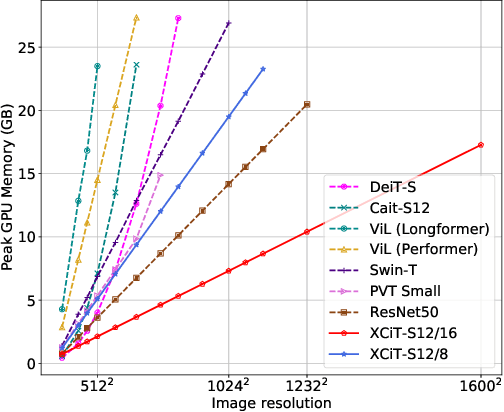
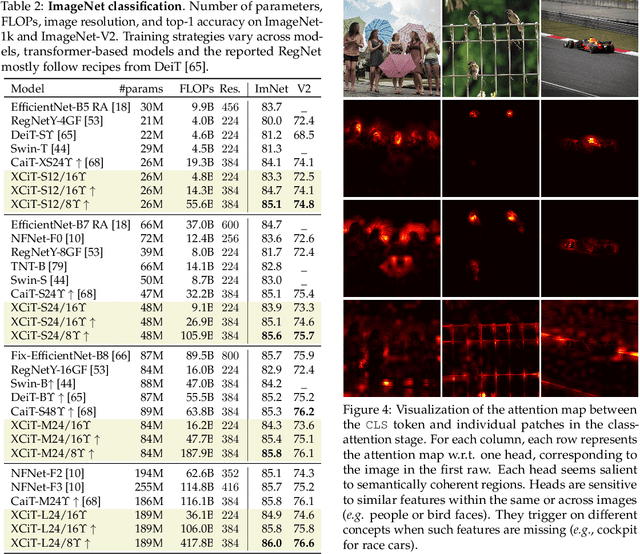
Following their success in natural language processing, transformers have recently shown much promise for computer vision. The self-attention operation underlying transformers yields global interactions between all tokens ,i.e. words or image patches, and enables flexible modelling of image data beyond the local interactions of convolutions. This flexibility, however, comes with a quadratic complexity in time and memory, hindering application to long sequences and high-resolution images. We propose a "transposed" version of self-attention that operates across feature channels rather than tokens, where the interactions are based on the cross-covariance matrix between keys and queries. The resulting cross-covariance attention (XCA) has linear complexity in the number of tokens, and allows efficient processing of high-resolution images. Our cross-covariance image transformer (XCiT) is built upon XCA. It combines the accuracy of conventional transformers with the scalability of convolutional architectures. We validate the effectiveness and generality of XCiT by reporting excellent results on multiple vision benchmarks, including image classification and self-supervised feature learning on ImageNet-1k, object detection and instance segmentation on COCO, and semantic segmentation on ADE20k.
Segmenter: Transformer for Semantic Segmentation
May 12, 2021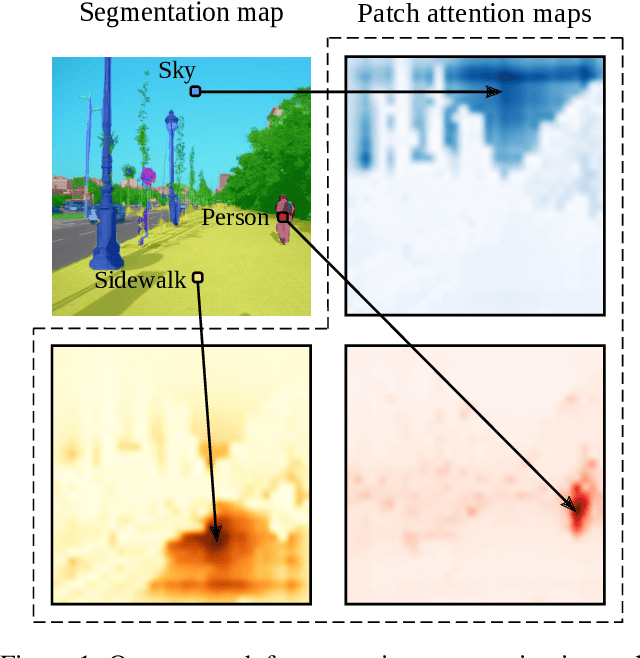
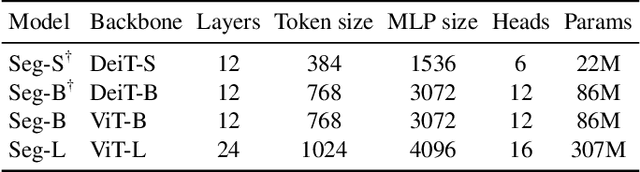
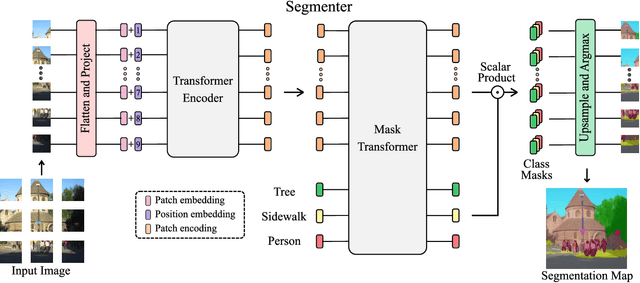
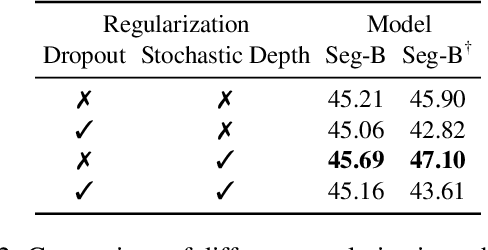
Image segmentation is often ambiguous at the level of individual image patches and requires contextual information to reach label consensus. In this paper we introduce Segmenter, a transformer model for semantic segmentation. In contrast to convolution based approaches, our approach allows to model global context already at the first layer and throughout the network. We build on the recent Vision Transformer (ViT) and extend it to semantic segmentation. To do so, we rely on the output embeddings corresponding to image patches and obtain class labels from these embeddings with a point-wise linear decoder or a mask transformer decoder. We leverage models pre-trained for image classification and show that we can fine-tune them on moderate sized datasets available for semantic segmentation. The linear decoder allows to obtain excellent results already, but the performance can be further improved by a mask transformer generating class masks. We conduct an extensive ablation study to show the impact of the different parameters, in particular the performance is better for large models and small patch sizes. Segmenter attains excellent results for semantic segmentation. It outperforms the state of the art on the challenging ADE20K dataset and performs on-par on Pascal Context and Cityscapes.
Thinking Fast and Slow: Efficient Text-to-Visual Retrieval with Transformers
Mar 30, 2021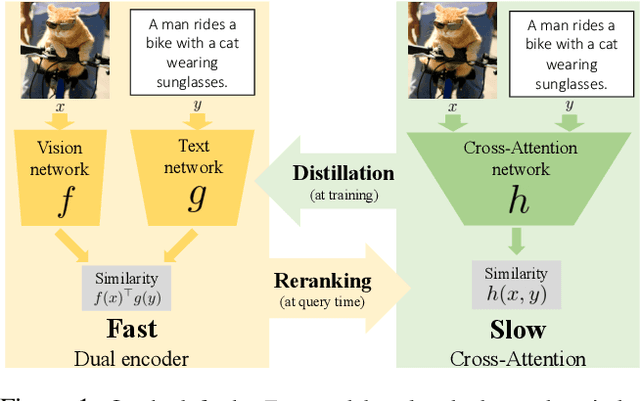
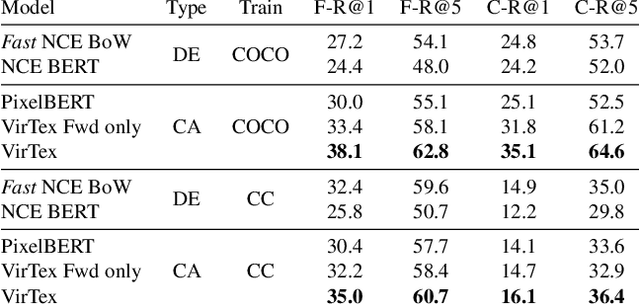
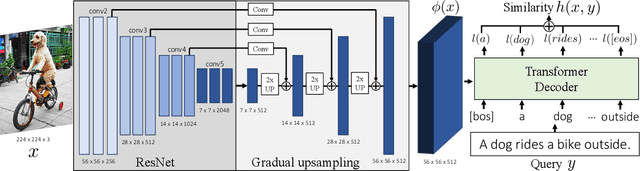
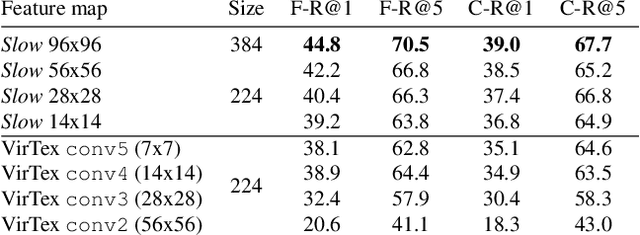
Our objective is language-based search of large-scale image and video datasets. For this task, the approach that consists of independently mapping text and vision to a joint embedding space, a.k.a. dual encoders, is attractive as retrieval scales and is efficient for billions of images using approximate nearest neighbour search. An alternative approach of using vision-text transformers with cross-attention gives considerable improvements in accuracy over the joint embeddings, but is often inapplicable in practice for large-scale retrieval given the cost of the cross-attention mechanisms required for each sample at test time. This work combines the best of both worlds. We make the following three contributions. First, we equip transformer-based models with a new fine-grained cross-attention architecture, providing significant improvements in retrieval accuracy whilst preserving scalability. Second, we introduce a generic approach for combining a Fast dual encoder model with our Slow but accurate transformer-based model via distillation and re-ranking. Finally, we validate our approach on the Flickr30K image dataset where we show an increase in inference speed by several orders of magnitude while having results competitive to the state of the art. We also extend our method to the video domain, improving the state of the art on the VATEX dataset.
Training Vision Transformers for Image Retrieval
Feb 10, 2021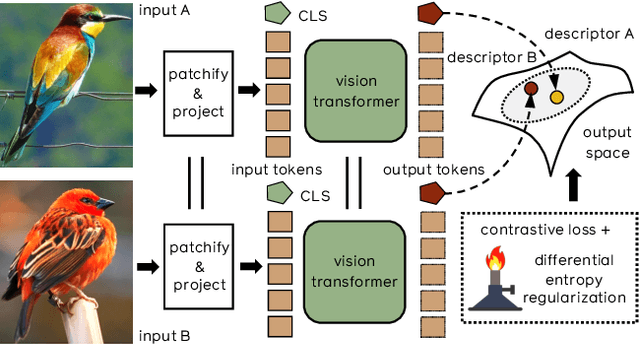
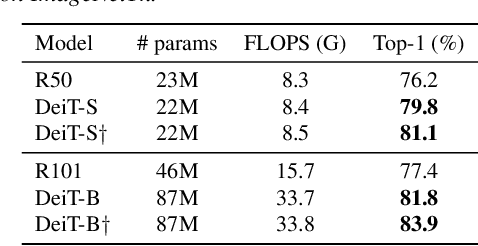
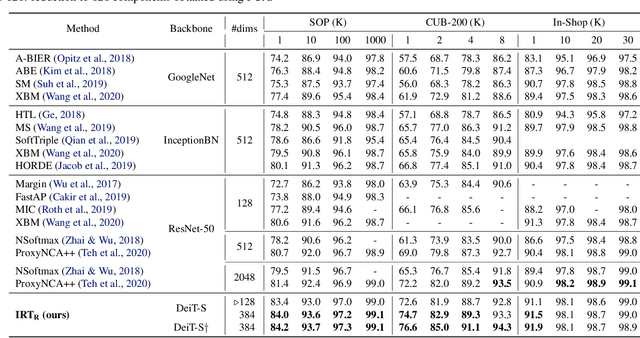
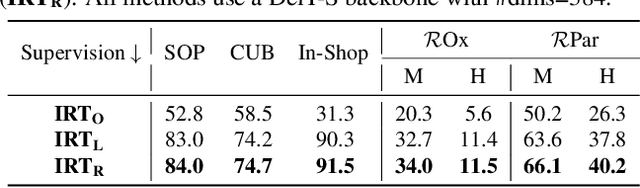
Transformers have shown outstanding results for natural language understanding and, more recently, for image classification. We here extend this work and propose a transformer-based approach for image retrieval: we adopt vision transformers for generating image descriptors and train the resulting model with a metric learning objective, which combines a contrastive loss with a differential entropy regularizer. Our results show consistent and significant improvements of transformers over convolution-based approaches. In particular, our method outperforms the state of the art on several public benchmarks for category-level retrieval, namely Stanford Online Product, In-Shop and CUB-200. Furthermore, our experiments on ROxford and RParis also show that, in comparable settings, transformers are competitive for particular object retrieval, especially in the regime of short vector representations and low-resolution images.
Just Ask: Learning to Answer Questions from Millions of Narrated Videos
Dec 01, 2020
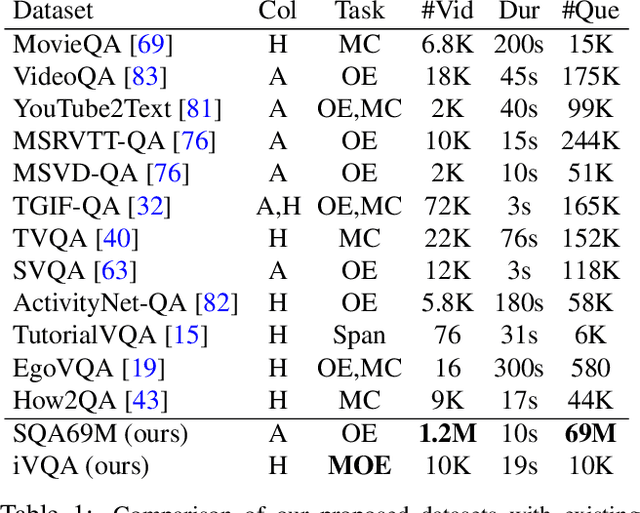


Modern approaches to visual question answering require large annotated datasets for training. Manual annotation of questions and answers for videos, however, is tedious, expensive and prevents scalability. In this work, we propose to avoid manual annotation and to learn video question answering (VideoQA) from millions of readily-available narrated videos. We propose to automatically generate question-answer pairs from transcribed video narrations leveraging a state-of-the-art text transformer pipeline and obtain a new large-scale VideoQA training dataset. To handle the open vocabulary of diverse answers in this dataset, we propose a training procedure based on a contrastive loss between a video-question multi-modal transformer and an answer embedding. We evaluate our model on the zero-shot VideoQA task and show excellent results, in particular for rare answers. Furthermore, we demonstrate that finetuning our model on target datasets significantly outperforms the state of the art on MSRVTT-QA, MSVD-QA and ActivityNet-QA. Finally, for a detailed evaluation we introduce a new manually annotated VideoQA dataset with reduced language biases and high quality annotations. Our code and datasets will be made publicly available at https://www.di.ens.fr/willow/research/just-ask/ .
Learning Object Manipulation Skills via Approximate State Estimation from Real Videos
Nov 13, 2020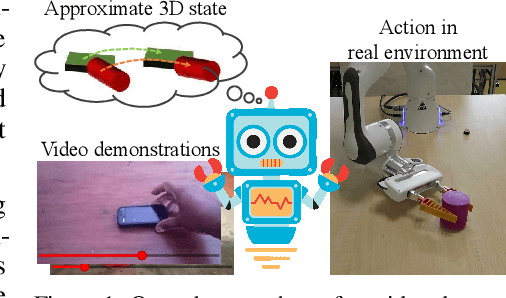
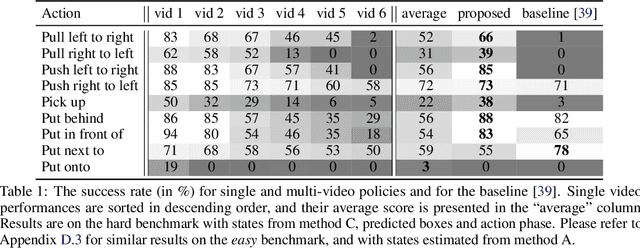
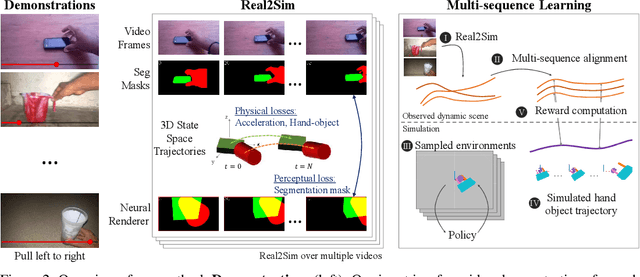

Humans are adept at learning new tasks by watching a few instructional videos. On the other hand, robots that learn new actions either require a lot of effort through trial and error, or use expert demonstrations that are challenging to obtain. In this paper, we explore a method that facilitates learning object manipulation skills directly from videos. Leveraging recent advances in 2D visual recognition and differentiable rendering, we develop an optimization based method to estimate a coarse 3D state representation for the hand and the manipulated object(s) without requiring any supervision. We use these trajectories as dense rewards for an agent that learns to mimic them through reinforcement learning. We evaluate our method on simple single- and two-object actions from the Something-Something dataset. Our approach allows an agent to learn actions from single videos, while watching multiple demonstrations makes the policy more robust. We show that policies learned in a simulated environment can be easily transferred to a real robot.