 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Hierarchical Latent Variable Encoder-Decoder Model for Generating Dialogues
Jun 14, 2016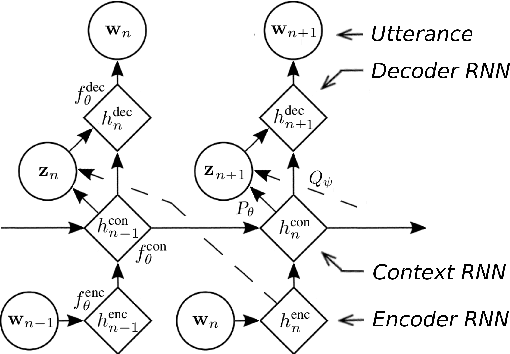
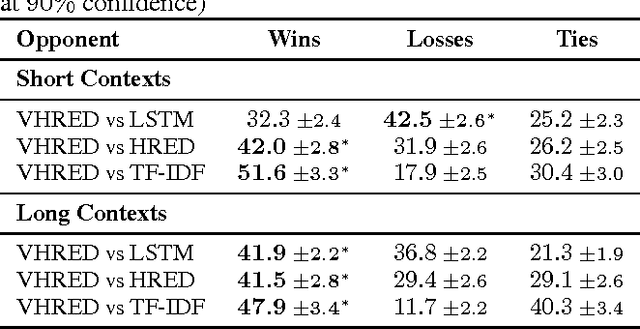

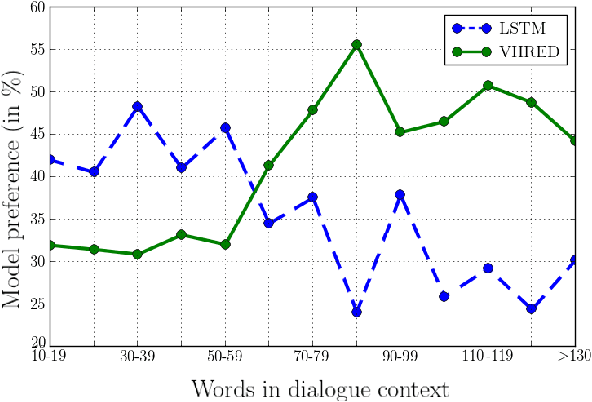
Sequential data often possesses a hierarchical structure with complex dependencies between subsequences, such as found between the utterances in a dialogue. In an effort to model this kind of generative process, we propose a neural network-based generative architecture, with latent stochastic variables that span a variable number of time steps. We apply the proposed model to the task of dialogue response generation and compare it with recent neural network architectures. We evaluate the model performance through automatic evaluation metrics and by carrying out a human evaluation. The experiments demonstrate that our model improves upon recently proposed models and that the latent variables facilitate the generation of long outputs and maintain the context.
Multiresolution Recurrent Neural Networks: An Application to Dialogue Response Generation
Jun 14, 2016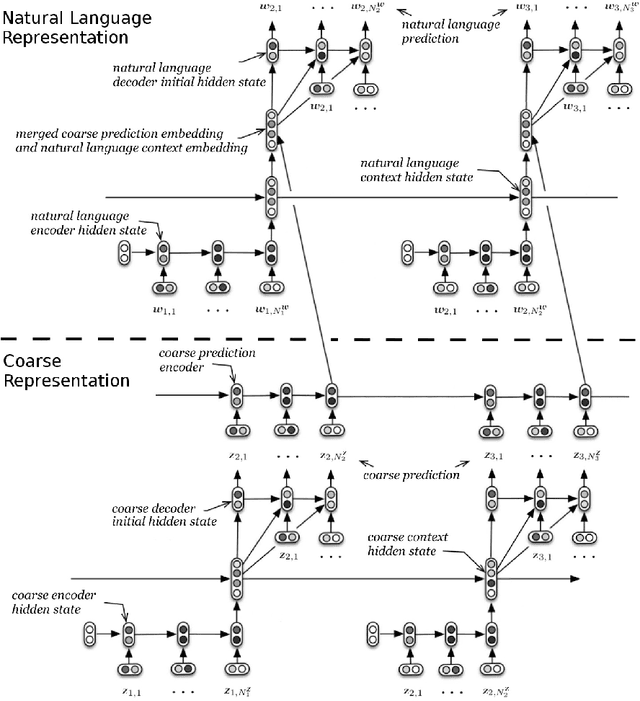
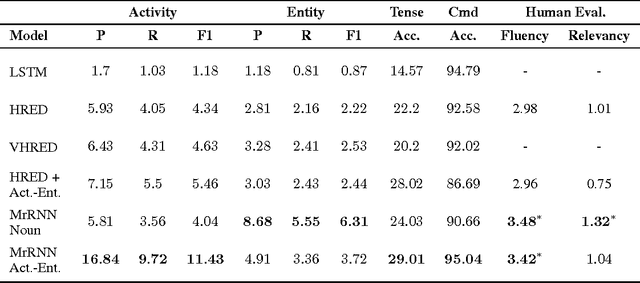

We introduce the multiresolution recurrent neural network, which extends the sequence-to-sequence framework to model natural language generation as two parallel discrete stochastic processes: a sequence of high-level coarse tokens, and a sequence of natural language tokens. There are many ways to estimate or learn the high-level coarse tokens, but we argue that a simple extraction procedure is sufficient to capture a wealth of high-level discourse semantics. Such procedure allows training the multiresolution recurrent neural network by maximizing the exact joint log-likelihood over both sequences. In contrast to the standard log- likelihood objective w.r.t. natural language tokens (word perplexity), optimizing the joint log-likelihood biases the model towards modeling high-level abstractions. We apply the proposed model to the task of dialogue response generation in two challenging domains: the Ubuntu technical support domain, and Twitter conversations. On Ubuntu, the model outperforms competing approaches by a substantial margin, achieving state-of-the-art results according to both automatic evaluation metrics and a human evaluation study. On Twitter, the model appears to generate more relevant and on-topic responses according to automatic evaluation metrics. Finally, our experiments demonstrate that the proposed model is more adept at overcoming the sparsity of natural language and is better able to capture long-term structure.
Generating Factoid Questions With Recurrent Neural Networks: The 30M Factoid Question-Answer Corpus
May 29, 2016
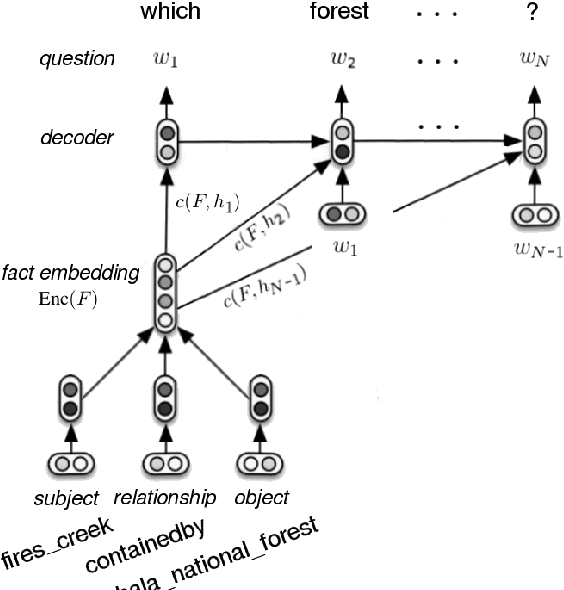
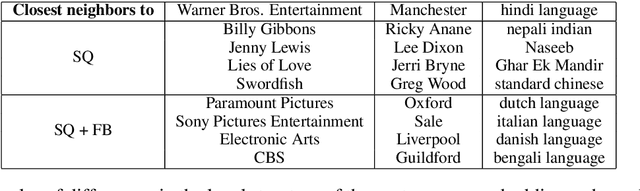
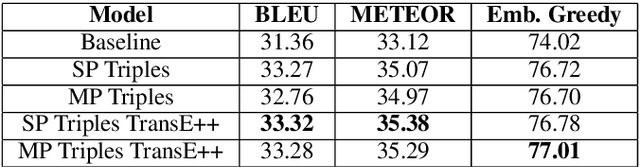
Over the past decade, large-scale supervised learning corpora have enabled machine learning researchers to make substantial advances. However, to this date, there are no large-scale question-answer corpora available. In this paper we present the 30M Factoid Question-Answer Corpus, an enormous question answer pair corpus produced by applying a novel neural network architecture on the knowledge base Freebase to transduce facts into natural language questions. The produced question answer pairs are evaluated both by human evaluators and using automatic evaluation metrics, including well-established machine translation and sentence similarity metrics. Across all evaluation criteria the question-generation model outperforms the competing template-based baseline. Furthermore, when presented to human evaluators, the generated questions appear comparable in quality to real human-generated questions.
Theano: A Python framework for fast computation of mathematical expressions
May 09, 2016



Theano is a Python library that allows to define, optimize, and evaluate mathematical expressions involving multi-dimensional arrays efficiently. Since its introduction, it has been one of the most used CPU and GPU mathematical compilers - especially in the machine learning community - and has shown steady performance improvements. Theano is being actively and continuously developed since 2008, multiple frameworks have been built on top of it and it has been used to produce many state-of-the-art machine learning models. The present article is structured as follows. Section I provides an overview of the Theano software and its community. Section II presents the principal features of Theano and how to use them, and compares them with other similar projects. Section III focuses on recently-introduced functionalities and improvements. Section IV compares the performance of Theano against Torch7 and TensorFlow on several machine learning models. Section V discusses current limitations of Theano and potential ways of improving it.